

Penapis Bloom telah dicadangkan oleh Bloom pada tahun 1970. Ia sebenarnya terdiri daripada tatasusunan binari yang sangat panjang + satu siri fungsi pemetaan algoritma cincang, yang digunakan untuk menentukan sama ada unsur wujud dalam set.
Penapis Bloom boleh digunakan untuk mendapatkan semula sama ada elemen berada dalam koleksi. Kelebihannya ialah kecekapan ruang dan masa pertanyaan jauh lebih baik daripada algoritma biasa. Kelemahannya ialah ia mempunyai kadar salah pengiktirafan tertentu dan kesukaran dalam pemadaman.
Andaikan terdapat 1 bilion nombor telefon mudah alih, dan kemudian tentukan sama ada nombor telefon mudah alih tertentu ada dalam senarai?
Adakah mysql okey?
Dalam keadaan biasa, jika jumlah data tidak besar, kita boleh mempertimbangkan untuk menggunakan storan mysql. Simpan semua data dalam pangkalan data, dan kemudian tanya pangkalan data setiap kali untuk menentukan sama ada ia wujud. Walau bagaimanapun, jika jumlah data terlalu besar, melebihi berpuluh juta, kecekapan pertanyaan MySQL akan menjadi sangat rendah, yang terutamanya akan menggunakan prestasi.
Bolehkah HashSet digunakan?
Kami boleh meletakkan data ke dalam HashSet dan menggunakan deduplikasi semula jadi HashSet Pertanyaan hanya perlu memanggil kaedah mengandungi, tetapi set cincang disimpan dalam memori Jika jumlah data terlalu besar, ingatan akan terus oom.
Sisipan dan pertanyaan adalah cekap dan mengambil sedikit ruang, tetapi hasil yang dikembalikan tidak pasti.
Jika sesuatu unsur dinilai wujud, ia mungkin sebenarnya tidak wujud. Tetapi jika dinilai bahawa unsur itu tidak wujud, maka ia mesti tidak wujud.
Penapis Bloom boleh menambah elemen, tetapi tidak boleh memadamkan elemen , yang akan meningkatkan kadar positif palsu.
Penapis Bloom sebenarnya ialah tatasusunan BIT, yang memetakan cincangan yang sepadan melalui satu siri algoritma cincangan, dan kemudian memetakan cincangan yang sepadan kedudukan subskrip tatasusunan ditukar kepada 1. Apabila membuat pertanyaan, satu siri algoritma cincang dilakukan pada data untuk mendapatkan subskrip Data diambil daripada tatasusunan BIT, seperti , ini bermakna data itu mungkin wujud. ini bermakna ia pasti tidak wujud
Kami tahu bahawa penapis Bloom sebenarnya mencincang data, jadi tidak kira apa algoritma yang digunakan, ia adalah kemungkinan cincang yang dijana oleh dua data yang berbeza sememangnya sama, iaitu, kami Lazimnya dirujuk sebagai konflik cincang.
Mula-mula masukkan sekeping data: Pelajari teknologi dengan baik
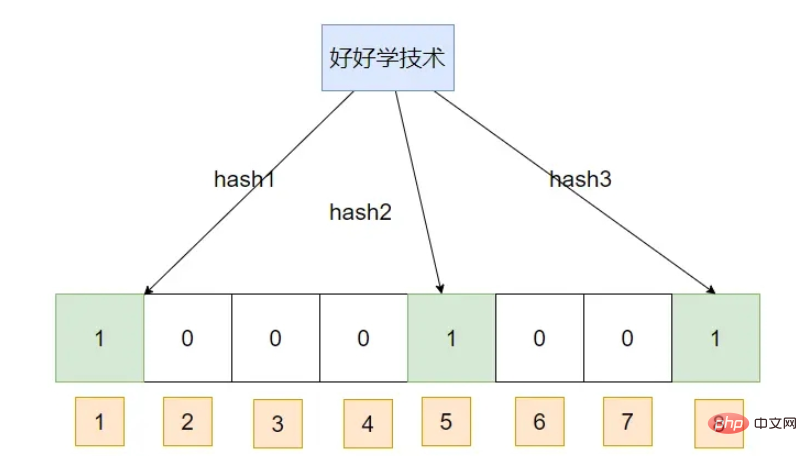
Masukkan sekeping data:
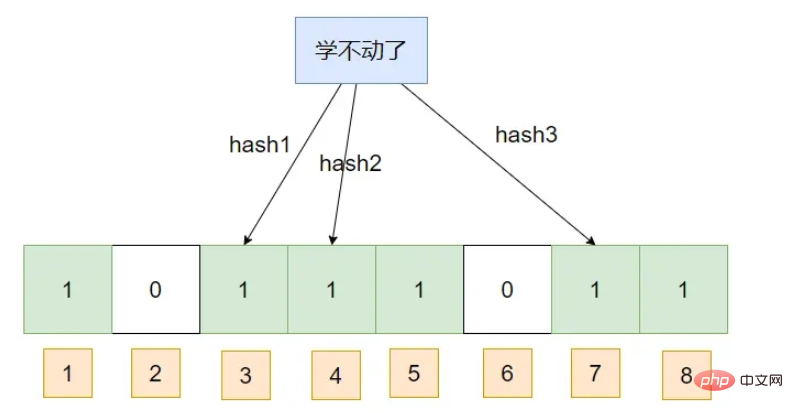
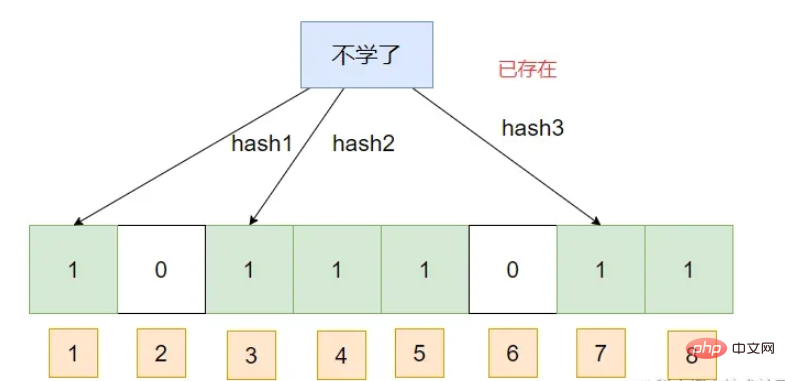
Ini Jika anda menanyakan sekeping data, dengan mengandaikan bahawa subskrip cincangnya sudah ditandakan sebagai 1, maka penapis Bloom akan berfikir bahawa ia wujud
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*
* @author fandongfeng
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>package com.fandf.test.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author fandongfeng
*/
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("好好学技术");
System.out.println(bloomFilter.mightContain("不好好学技术"));
System.out.println(bloomFilter.mightContain("好好学技术"));
}
}<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.3</version>
</dependency>Atas ialah kandungan terperinci Bagaimana untuk melaksanakan penapis mekar di Jawa?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



