

"Kami tidak mempunyai parit, dan OpenAI juga tidak mempunyai dokumen yang bocor baru-baru ini, seorang penyelidik dalam Google menyatakan pandangan ini.
Penyelidik percaya bahawa walaupun OpenAI dan Google kelihatan mengejar satu sama lain pada model AI yang besar, pemenang sebenar mungkin tidak muncul daripada kedua-dua ini kerana yang pertama Pasukan tiga pihak secara senyap-senyap meningkat.
Kuasa ini dipanggil "Sumber Terbuka". Memfokuskan pada model sumber terbuka seperti LLaMA Meta, seluruh komuniti dengan pantas membina model dengan keupayaan serupa dengan OpenAI dan model besar Google Selain itu, model sumber terbuka lebih pantas, lebih disesuaikan dan lebih peribadi... "Apabila ia percuma , Orang ramai tidak akan membayar untuk model terhad apabila alternatif yang tidak terhad mempunyai kualiti yang sama,” tulis penulis.
Dokumen ini pada asalnya dikongsi oleh orang tanpa nama pada pelayan Discord awam, sebuah media industri yang diberi kuasa untuk mencetak semula, menyatakan bahawa mereka telah mengesahkan kesahihan dokumen ini.
Artikel ini telah banyak dimajukan pada platform sosial seperti Twitter. Antaranya, Alex Dimakis, seorang profesor di Universiti Texas di Austin, menyatakan pandangan berikut:
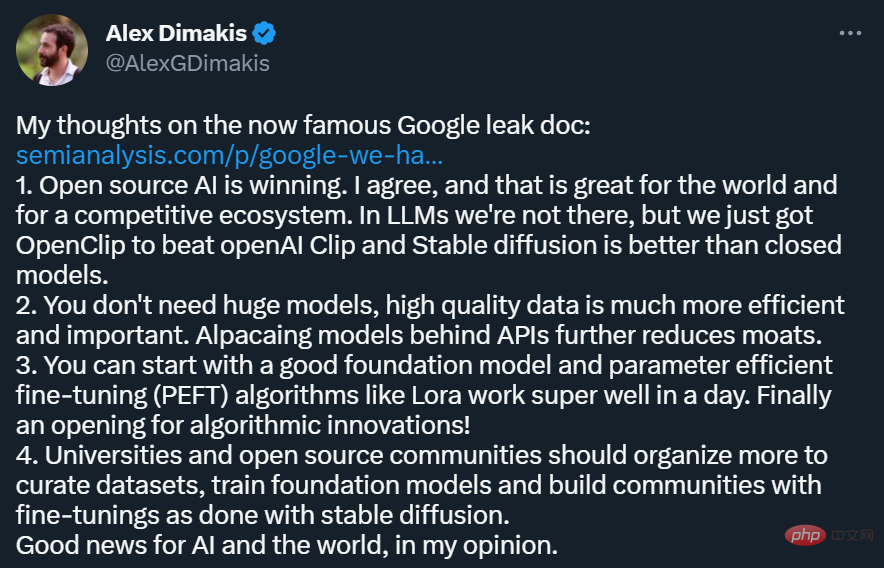
Sudah tentu, tidak semua penyelidik bersetuju dengan pandangan dalam artikel tersebut. Sesetengah orang ragu-ragu sama ada model sumber terbuka benar-benar boleh mempunyai kuasa dan serba boleh model besar yang setanding dengan OpenAI.
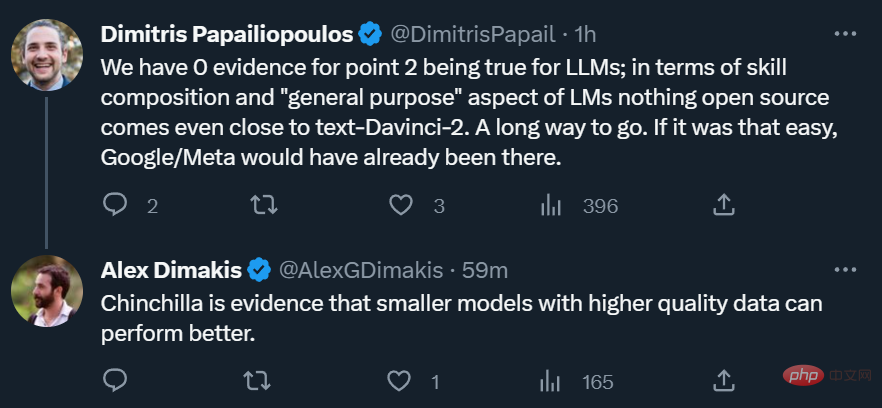
Walau bagaimanapun, bagi ahli akademik, kebangkitan kuasa sumber terbuka sentiasa sesuatu yang baik, yang bermakna walaupun tanpa 1,000 blok Dengan GPU, penyelidik masih mempunyai sesuatu untuk dilakukan.
Berikut ialah teks asal dokumen:
Kami tidak mempunyai parit, dan begitu juga OpenAI.
Kami telah memberi perhatian kepada dinamik dan pembangunan OpenAI. Siapa yang akan melepasi pencapaian seterusnya? Apa seterusnya?
Tetapi hakikat yang tidak selesa ialah kami tidak bersedia untuk memenangi perlumbaan senjata ini, begitu juga OpenAI. Semasa kita bertelagah, puak ketiga telah mendapat faedah.
Puak ini ialah "puak sumber terbuka". Terus terang, mereka mengatasi kita. Apa yang kami anggap sebagai "masalah penting untuk diselesaikan" kini telah diselesaikan dan kini berada di tangan orang ramai.
Biar saya berikan anda beberapa contoh:
Walaupun model kami masih mengekalkan sedikit kelebihan dalam kualiti, jurang itu semakin rapat pada kadar yang membimbangkan. Model sumber terbuka lebih pantas, lebih boleh disesuaikan, lebih peribadi dan lebih berkuasa di bawah keadaan yang sama. Mereka melakukan sesuatu dengan parameter $100 dan $13 bilion yang kami sukar lakukan dengan parameter $10 juta dan $54 bilion. Dan mereka boleh melakukannya dalam beberapa minggu, bukan bulan. Ini mempunyai akibat yang mendalam untuk kami:
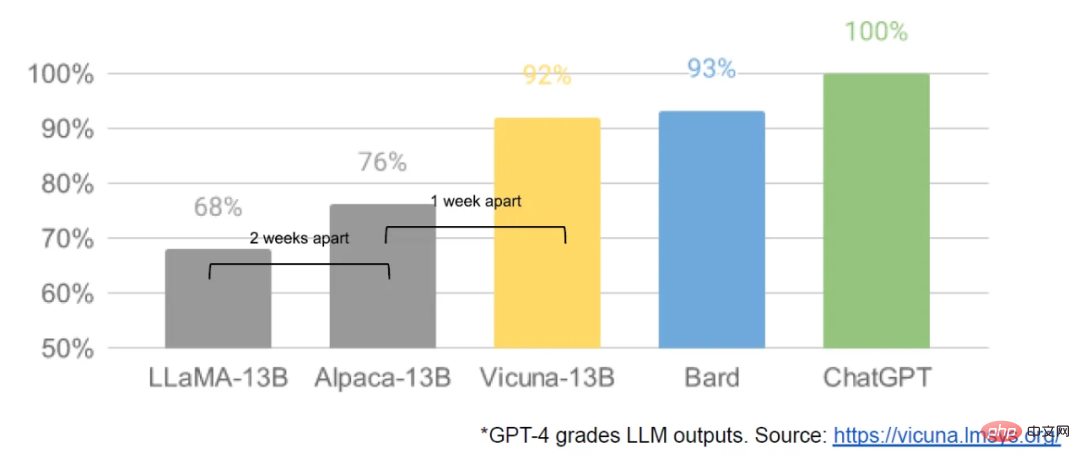
Pada awal Mac, dengan LLaMA Meta model Dibocorkan kepada umum, komuniti sumber terbuka mendapat model asas pertama yang benar-benar berguna. Model ini tidak mempunyai arahan atau pelarasan dialog, dan tiada RLHF. Walau bagaimanapun, komuniti sumber terbuka segera memahami kepentingan LLaMA.
Apa yang diikuti ialah aliran inovasi yang berterusan, dengan kemajuan besar muncul hanya selang beberapa hari (seperti menjalankan model LLaMA pada Raspberry Pi 4B dan memperhalusi arahan LLaMA pada komputer riba), menjalankan LLaMA pada MacBook, dll.). Hanya sebulan kemudian, varian seperti penalaan halus arahan, kuantisasi, peningkatan kualiti, pelbagai mod, RLHF, dsb. semuanya muncul, kebanyakannya dibina pada satu sama lain.
Paling penting, mereka telah menyelesaikan masalah penskalaan, yang bermaksud sesiapa sahaja boleh mengubah suai dan mengoptimumkan model ini secara bebas. Banyak idea baru datang dari orang biasa. Ambang untuk latihan dan percubaan telah beralih daripada institusi penyelidikan utama kepada satu orang, satu petang, dan komputer riba yang berkuasa.
Dalam banyak cara, ini tidak sepatutnya mengejutkan sesiapa pun. Kebangkitan semasa dalam LLM sumber terbuka datang selepas kebangkitan semula dalam penjanaan imej, dengan ramai yang menggelar detik Resapan Stabil LLM ini.
Dalam kedua-dua kes, penyertaan awam kos rendah dicapai melalui mekanisme penyesuaian peringkat rendah (LoRA) yang lebih murah, digabungkan dengan kejayaan besar dalam skala. Ketersediaan mudah model berkualiti tinggi telah membantu individu dan institusi di seluruh dunia menginkubasi saluran idea dan membolehkan mereka mengulanginya dan dengan cepat mengatasi perusahaan besar.
Sumbangan ini amat penting dalam bidang penjanaan imej dan menetapkan Stable Diffusion pada laluan yang berbeza daripada Dall-E. Mempunyai model terbuka membolehkan integrasi produk, pasaran, antara muka pengguna dan inovasi yang tidak terdapat di Dall-E.
Kesannya jelas: Kesan budaya Stable Diffusion cepat berkuat kuasa berbanding dengan penyelesaian OpenAI. Sama ada LLM akan melihat perkembangan serupa masih belum dapat dilihat, tetapi elemen struktur yang luas adalah sama.
Projek sumber terbuka menggunakan kaedah atau teknologi inovatif yang secara langsung menyelesaikan masalah yang masih kita hadapi. Memberi perhatian kepada usaha sumber terbuka boleh membantu kita mengelak daripada melakukan kesilapan yang sama. Antaranya, LoRA ialah teknologi yang sangat berkuasa dan kita harus memberi lebih perhatian kepadanya.
LoRA mempersembahkan kemas kini model sebagai pemfaktoran peringkat rendah, yang boleh mengurangkan saiz matriks kemas kini sebanyak beribu-ribu kali. Dengan cara ini, penalaan halus model hanya memerlukan kos dan masa yang kecil. Mengurangkan masa untuk penalaan diperibadikan model bahasa kepada beberapa jam pada perkakasan gred pengguna adalah penting, terutamanya bagi mereka yang mempunyai visi untuk menyepadukan pengetahuan baharu dan pelbagai dalam hampir masa nyata. Walaupun teknologi mempunyai kesan yang besar pada beberapa projek yang ingin kami capai, ia kurang digunakan dalam Google.
Satu sebab mengapa LoRA begitu cekap ialah ini: seperti bentuk penalaan halus yang lain, ia bertindan. Kita boleh menggunakan penambahbaikan seperti perintah penalaan halus untuk membantu tugasan seperti dialog dan penaakulan. Walaupun lagu halus individu berpangkat rendah, manakala jumlahnya tidak, LoRA membenarkan kemas kini peringkat penuh pada model terkumpul dari semasa ke semasa.
Ini bermakna apabila set data dan ujian yang lebih baharu dan lebih baik tersedia, model boleh dikemas kini dengan murah tanpa perlu membayar kos operasi penuh.
Sebaliknya, melatih model besar dari awal bukan sahaja membuang pra-latihan, tetapi juga membuang semua lelaran dan penambahbaikan sebelumnya. Dalam dunia sumber terbuka, penambahbaikan ini cepat menjadi berleluasa, menjadikan latihan semula penuh menjadi mahal.
Kita harus mempertimbangkan dengan serius sama ada setiap aplikasi atau idea baharu benar-benar memerlukan model baharu sepenuhnya. Jika kita mempunyai penambahbaikan seni bina yang ketara yang menghalang penggunaan semula berat model secara langsung, maka kita harus komited kepada pendekatan yang lebih agresif untuk penyulingan yang mengekalkan kefungsian generasi sebelumnya sebanyak mungkin.
Kemas kini LoRA adalah kos yang sangat rendah (sekitar $100) untuk saiz model yang paling popular. Ini bermakna hampir sesiapa sahaja yang mempunyai idea boleh menjana dan mengedarkannya. Pada kelajuan biasa di mana latihan mengambil masa kurang daripada sehari, kesan kumulatif penalaan halus dengan cepat mengatasi kelemahan saiz awal. Malah, model ini bertambah baik jauh lebih pantas daripada yang boleh dilakukan oleh varian terbesar kami dari segi masa jurutera. Dan model terbaik sudah tidak dapat dibezakan daripada ChatGPT. Oleh itu, memberi tumpuan kepada mengekalkan beberapa model terbesar sebenarnya meletakkan kami pada kelemahan.
Kebanyakan projek ini menjimatkan masa dengan melatih set data kecil yang dipilih susun tinggi. Ini menunjukkan fleksibiliti dalam peraturan penskalaan data. Set data ini wujud daripada idea daripada Data Tidak Melakukan Apa yang Anda Fikirkan dan dengan cepat menjadi cara standard untuk melatih tanpa Google. Set data ini dibuat menggunakan kaedah sintetik (seperti menapis pantulan terbaik daripada model sedia ada) dan dikikis daripada projek lain, yang kedua-duanya tidak biasa digunakan di Google. Nasib baik, set data berkualiti tinggi ini adalah sumber terbuka, jadi ia tersedia secara percuma.
Perkembangan terbaru ini mempunyai kesan yang sangat langsung terhadap strategi perniagaan. Siapa yang akan membayar untuk produk Google dengan sekatan penggunaan apabila terdapat alternatif percuma dan berkualiti tinggi tanpa sekatan penggunaan? Selain itu, kita tidak seharusnya mengharapkan untuk mengejar ketinggalan. Internet moden berjalan pada sumber terbuka kerana sumber terbuka mempunyai beberapa kelebihan penting yang tidak dapat kami tiru.
Menyimpan rahsia teknologi kami sentiasa menjadi cadangan yang rapuh. Penyelidik Google kerap pergi ke syarikat lain untuk belajar, jadi boleh diandaikan bahawa mereka tahu semua yang kita tahu. Dan mereka akan terus berbuat demikian selagi saluran paip ini dibuka.
Tetapi apabila penyelidikan termaju dalam bidang LLM menjadi mampu milik, semakin sukar untuk mengekalkan kelebihan daya saing teknologi. Institusi penyelidikan di seluruh dunia sedang belajar daripada satu sama lain untuk meneroka ruang penyelesaian dalam pendekatan yang luas didahulukan yang jauh di luar kemampuan kita sendiri. Kita boleh bekerja keras untuk memegang rahsia kita sendiri, tetapi inovasi luaran mencairkan nilainya, jadi cuba belajar daripada satu sama lain.
Kebanyakan inovasi dibina di atas berat model Meta yang bocor. Ini pasti akan berubah apabila model yang benar-benar terbuka menjadi lebih baik dan lebih baik, tetapi perkara utamanya ialah mereka tidak perlu menunggu. Perlindungan undang-undang yang disediakan oleh "penggunaan peribadi" dan ketidakpraktisan pendakwaan individu bermakna individu boleh menggunakan teknologi ini semasa ia panas.
Secara paradoks, hanya ada satu pemenang dalam semua ini, dan itu ialah Meta, selepas semua model yang bocor adalah milik mereka. Memandangkan kebanyakan inovasi sumber terbuka adalah berdasarkan seni bina mereka, tiada apa yang menghalang mereka daripada disepadukan secara langsung ke dalam produk mereka sendiri.
Seperti yang anda lihat, nilai mempunyai ekosistem tidak boleh dilebih-lebihkan. Google sendiri sudah pun menggunakan paradigma ini dalam produk sumber terbuka seperti Chrome dan Android. Dengan mencipta platform untuk menginkubasi kerja inovatif, Google telah mengukuhkan kedudukannya sebagai peneraju pemikiran dan penentu arah, memperoleh keupayaan untuk membentuk idea yang lebih besar daripada dirinya sendiri.
Semakin ketat kami mengawal model kami, semakin menarik untuk membuat alternatif terbuka Kedua-dua Google dan OpenAI cenderung mempunyai model keluaran defensif yang membolehkan mereka mengawal dengan ketat Cara menggunakan model. Walau bagaimanapun, kawalan ini tidak realistik. Sesiapa sahaja yang ingin menggunakan LLM untuk tujuan yang tidak diluluskan boleh memilih daripada model yang tersedia secara percuma.
Oleh itu, Google harus meletakkan dirinya sebagai peneraju dalam komuniti sumber terbuka dan memimpin dengan bekerjasama dalam dialog yang lebih luas dan bukannya mengabaikannya. Ini mungkin bermakna mengambil beberapa langkah yang tidak selesa, seperti melepaskan pemberat model untuk varian ULM yang kecil. Ini juga semestinya bermakna melepaskan beberapa kawalan ke atas model anda sendiri, tetapi kompromi ini tidak dapat dielakkan. Kami tidak boleh berharap untuk memacu inovasi dan mengawalnya.
Memandangkan dasar tertutup semasa OpenAI, semua perbincangan sumber terbuka ini berasa tidak adil. Jika mereka tidak bersedia untuk berkongsi teknologi, mengapa kita perlu berkongsinya? Tetapi hakikatnya kami telah berkongsi segala-galanya dengan mereka dengan terus memburu penyelidik kanan di OpenAI. Sehingga kita membendung arus, kerahsiaan akan kekal sebagai isu yang dipertikaikan.
Akhir sekali, OpenAI tidak penting. Mereka melakukan kesilapan yang sama seperti yang kita lakukan dengan pendirian sumber terbuka mereka, dan keupayaan mereka untuk mengekalkan kelebihan mereka pasti akan dipersoalkan. Melainkan OpenAI mengubah pendiriannya, alternatif sumber terbuka boleh dan akhirnya akan mengatasinya. Sekurang-kurangnya dalam hal ini, kita boleh mengambil langkah ini.
Atas ialah kandungan terperinci Dokumen dalaman Google yang bocor menunjukkan bahawa Google dan OpenAI tidak mempunyai mekanisme perlindungan yang berkesan, jadi ambang untuk model besar terus diturunkan oleh komuniti sumber terbuka.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah maksud sisi c dan sisi b?
Apakah maksud sisi c dan sisi b?
 Platform manakah yang lebih baik untuk perdagangan mata wang maya?
Platform manakah yang lebih baik untuk perdagangan mata wang maya?
 penggunaan velocitytracker
penggunaan velocitytracker
 Alat muat turun dan pemasangan Linux biasa
Alat muat turun dan pemasangan Linux biasa
 harga syiling fil hari ini
harga syiling fil hari ini
 Windows tidak boleh mengakses laluan peranti atau penyelesaian fail yang ditentukan
Windows tidak boleh mengakses laluan peranti atau penyelesaian fail yang ditentukan
 Pengenalan kepada kaedah sarang pengulang
Pengenalan kepada kaedah sarang pengulang
 Cara membuat gambar ppt muncul satu persatu
Cara membuat gambar ppt muncul satu persatu








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



