

SembangGPT topik satu sejarah evolusi keluarga GPT

Garis Masa
Jun 2018
OpenAI mengeluarkan model GPT-1 dengan 110 juta parameter.
November 2018
OpenAI mengeluarkan model GPT-2 dengan 1.5 bilion parameter, tetapi disebabkan kebimbangan tentang penyalahgunaan, semua kod dan data model tidak dibuka kepada orang ramai.
Februari 2019
OpenAI membuka beberapa kod dan data model GPT-2, tetapi akses masih terhad.
10 Jun 2019
OpenAI mengeluarkan model GPT-3 dengan 175 bilion parameter dan menyediakan akses kepada beberapa rakan kongsi.
September 2019
OpenAI membuka semua kod dan data GPT-2 dan mengeluarkan versi yang lebih besar.
Mei 2020
OpenAI mengumumkan pelancaran versi beta model GPT-3, yang mempunyai 175 bilion parameter dan merupakan model pemprosesan bahasa semula jadi terbesar setakat ini.
Mac 2022
OpenAI mengeluarkan InstructGPT, menggunakan Penalaan Arahan
30 November 2022
OpenAI melepasi siri GPT-3.5 bahasa berskala besar. model AI perbualan baharu ChatGPT dikeluarkan secara rasmi selepas memperhalusi model tersebut.
15 Disember 2022
ChatGPT dikemas kini buat kali pertama, meningkatkan prestasi keseluruhan dan menambah ciri baharu untuk menyimpan dan melihat rekod perbualan sejarah.
9 Januari 2023
Kemas kini kedua ChatGPT meningkatkan ketulenan jawapan dan menambah fungsi "penjanaan henti" baharu.
21 Januari 2023
OpenAI mengeluarkan versi berbayar ChatGPT Professional yang terhad kepada sesetengah pengguna.
30 Januari 2023
Kemas kini ketiga ChatGPT bukan sahaja meningkatkan keaslian jawapan, tetapi juga meningkatkan kebolehan matematik.
2 Februari 2023
OpenAI secara rasmi melancarkan perkhidmatan langganan versi berbayar ChatGPT Berbanding dengan versi percuma, versi baharu bertindak balas dengan lebih pantas dan berjalan dengan lebih stabil.
15 Mac 2023
OpenAI secara mengejutkan melancarkan model berbilang mod berskala besar GPT-4, yang bukan sahaja boleh membaca teks, tetapi juga mengenali imej dan menjana hasil teks ChatGPT yang disambungkan terbuka kepada pengguna Plus.
GPT-1: Model pra-latihan berdasarkan Transformer sehala
Sebelum kemunculan GPT, model NLP dilatih terutamanya berdasarkan jumlah data beranotasi yang besar untuk tugasan tertentu. Ini akan membawa kepada beberapa pengehadan:
Data beranotasi berskala besar dan berkualiti tinggi tidak mudah diperolehi
Model terhad kepada latihan yang telah diterima dan mempunyai keupayaan generalisasi yang tidak mencukupi;
Tidak boleh melaksanakan pembangunan Tugas luar kotak mengehadkan aplikasi praktikal model.
Untuk mengatasi masalah ini, OpenAI memulakan laluan pra-latihan model besar. GPT-1 ialah model pra-latihan pertama yang dikeluarkan oleh OpenAI pada 2018. Ia menggunakan model Transformer sehala dan menggunakan lebih daripada 40GB data teks untuk latihan. Ciri utama GPT-1 ialah: pra-latihan generatif (tanpa diawasi) + penalaan halus tugas diskriminatif (diawasi). Pertama, kami menggunakan pra-latihan pembelajaran tanpa pengawasan dan menghabiskan 1 bulan pada 8 GPU untuk meningkatkan keupayaan bahasa sistem AI daripada sejumlah besar data tidak berlabel dan memperoleh sejumlah besar pengetahuan Kemudian kami menjalankan penalaan halus dan diselia membandingkannya dengan set data yang besar Bersepadu untuk meningkatkan prestasi sistem dalam tugasan NLP. GPT-1 menunjukkan prestasi cemerlang dalam penjanaan teks dan tugas pemahaman, menjadi salah satu model pemprosesan bahasa semula jadi yang paling maju pada masa itu.
GPT-2: Model pra-latihan pelbagai tugas
Disebabkan kekurangan generalisasi model tugasan tunggal dan keperluan untuk sejumlah besar latihan berkesan berpasangan untuk pembelajaran berbilang tugas, GPT-2 ialah Ia telah dikembangkan dan dioptimumkan berdasarkan GPT-1, mengalih keluar pembelajaran diselia dan hanya mengekalkan pembelajaran tanpa pengawasan. GPT-2 menggunakan data teks yang lebih besar dan sumber pengkomputeran yang lebih berkuasa untuk latihan, dan saiz parameter mencapai 150 juta, jauh melebihi 110 juta parameter GPT-1. Selain menggunakan set data yang lebih besar dan model yang lebih besar untuk belajar, GPT-2 juga mencadangkan tugas baharu dan lebih sukar: pembelajaran sifar pukulan (sifar pukulan), iaitu menggunakan model pra-latihan secara langsung kepada banyak Tugas hiliran. GPT-2 telah menunjukkan prestasi cemerlang pada pelbagai tugas pemprosesan bahasa semula jadi, termasuk penjanaan teks, klasifikasi teks, pemahaman bahasa, dsb.

GPT-3: Mencipta penjanaan bahasa semula jadi baharu dan keupayaan pemahaman
GPT-3 ialah yang terbaru dalam siri GPT bagi model Model yang menggunakan skala parameter yang lebih besar dan data latihan yang lebih kaya. Skala parameter GPT-3 mencapai 1.75 trilion, iaitu lebih daripada 100 kali ganda GPT-2. GPT-3 telah menunjukkan keupayaan luar biasa dalam penjanaan bahasa semula jadi, penjanaan dialog dan tugas pemprosesan bahasa lain Dalam sesetengah tugas, ia juga boleh mencipta bentuk ekspresi bahasa baharu.
GPT-3 mencadangkan konsep yang sangat penting: Pembelajaran dalam konteks Kandungan khusus akan diterangkan dalam tweet seterusnya.
InstructGPT & ChatGPT
Latihan InstructGPT/ChatGPT dibahagikan kepada 3 langkah, dan data yang diperlukan untuk setiap langkah adalah berbeza sedikit .
Bermula daripada model bahasa yang telah dilatih, gunakan tiga langkah berikut.
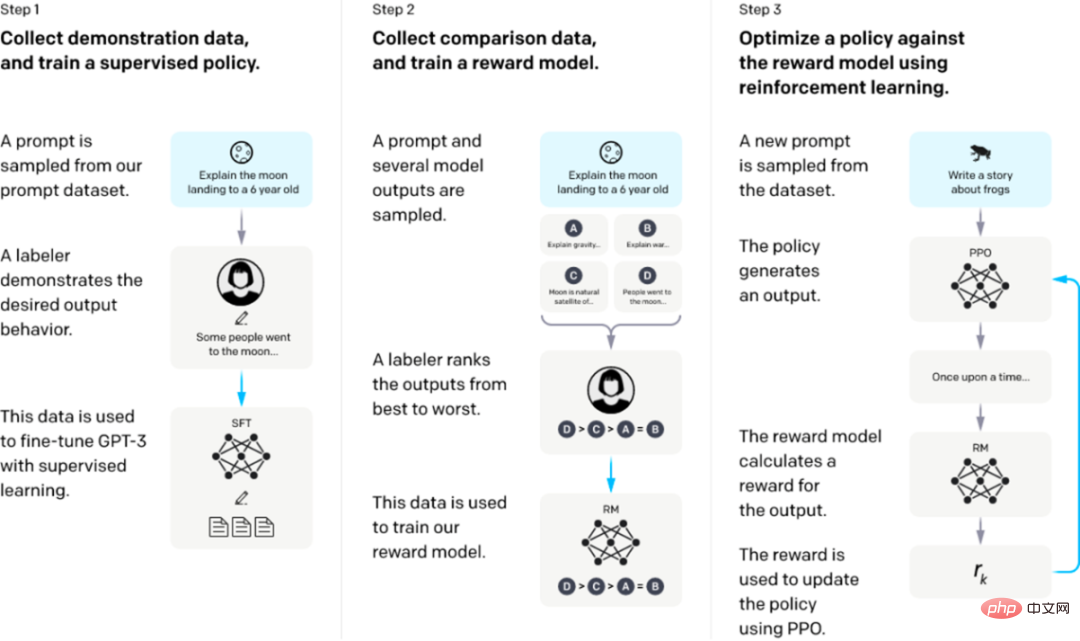
Langkah 1: SFT penalaan halus yang diawasi: kumpulkan data demonstrasi dan latih dasar yang diawasi. Penanda kami menyediakan demonstrasi tingkah laku yang diingini pada pengedaran gesaan input. Kami kemudian menggunakan pembelajaran terselia untuk memperhalusi model GPT-3 yang telah dilatih pada data ini.
Langkah 2: Latihan Model Ganjaran. Kumpul data perbandingan dan latih model ganjaran. Kami mengumpul set data perbandingan antara output model, di mana pelabel menunjukkan output yang mereka lebih suka untuk input yang diberikan. Kami kemudian melatih model ganjaran untuk meramalkan output pilihan manusia.
Langkah 3: Pembelajaran pengukuhan melalui pengoptimuman dasar proksimal (PPO) pada model ganjaran: gunakan output RM sebagai ganjaran skalar. Kami menggunakan algoritma PPO untuk memperhalusi strategi penyeliaan untuk mengoptimumkan ganjaran ini.
Langkah 2 dan 3 boleh diulang secara berterusan; lebih banyak data perbandingan dikumpulkan pada strategi optimum semasa, yang digunakan untuk melatih RM baharu, dan kemudian strategi baharu.
Gesaan untuk dua langkah pertama datang daripada data penggunaan pengguna pada API dalam talian OpenAI dan ditulis tangan oleh anotasi yang diupah. Langkah terakhir adalah semua sampel daripada data API Data khusus InstructGPT:
1 set data SFT
Set data SFT digunakan untuk melatih langkah pertama. Model yang diselia menggunakan data baharu yang dikumpul untuk memperhalusi GPT-3 mengikut kaedah latihan GPT-3. Oleh kerana GPT-3 ialah model generatif berdasarkan pembelajaran segera, set data SFT juga merupakan sampel yang terdiri daripada pasangan balasan segera. Sebahagian daripada data SFT datang daripada pengguna OpenAI's PlayGround, dan sebahagian lagi datang daripada 40 pelabel yang digunakan oleh OpenAI. Dan mereka melatih pelabel itu. Dalam set data ini, tugas annotator adalah untuk menulis arahan sendiri berdasarkan kandungan.
2. Set data RM
Set data RM digunakan untuk melatih model ganjaran dalam langkah 2. Kita juga perlu menetapkan sasaran ganjaran untuk latihan ArahanGPT/ChatGPT. Matlamat ganjaran ini tidak semestinya boleh dibezakan, tetapi ia mesti diselaraskan secara menyeluruh dan realistik yang mungkin dengan perkara yang kita perlukan model untuk jana. Sememangnya, kami boleh memberikan ganjaran ini melalui anotasi manual Melalui gandingan buatan, kami boleh memberikan skor yang lebih rendah kepada kandungan yang dijana yang melibatkan berat sebelah untuk menggalakkan model tidak menjana kandungan yang tidak disukai manusia. Pendekatan InstructGPT/ChatGPT adalah dengan terlebih dahulu membiarkan model menjana sekumpulan teks calon, dan kemudian menggunakan pelabel untuk mengisih kandungan yang dijana mengikut kualiti data yang dijana.
3. Set data PPO
Data PPO InstructGPT tidak diberi anotasi dan ia datang daripada pengguna API GPT-3. Terdapat pelbagai jenis tugas penjanaan yang disediakan oleh pengguna yang berbeza, dengan perkadaran tertinggi termasuk tugas penjanaan (45.6%), QA (12.4%), sumbangsaran (11.2%), dialog (8.4%), dsb.
Lampiran:
Pelbagai sumber keupayaan ChatGPT:
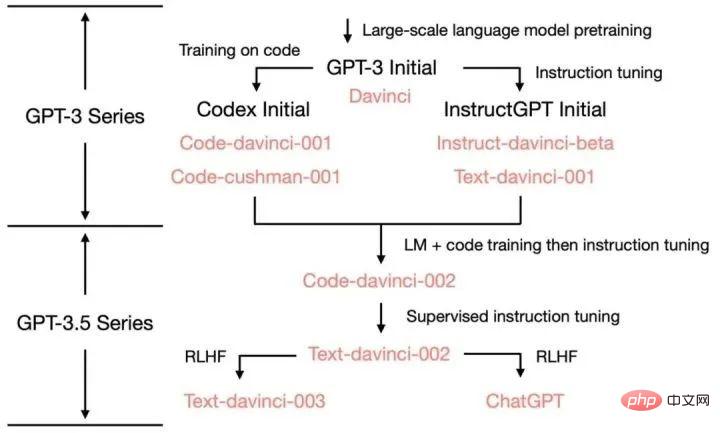
GPT -3 hingga ChatGPT dan keupayaan serta kaedah latihan versi lelaran di antara:

Rujukan
1. 3.5 keupayaan: https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
2. Garis masa paling lengkap bagi keseluruhan rangkaian! Dari masa lalu dan semasa ChatGPT kepada landskap kompetitif semasa dalam bidang AI https://www.bilibili.com/read/cv22541079
3 -Latihan, OpenAI.
4 kertas GPT-2: Model Bahasa ialah Pelajar Berbilang Tugas Tanpa Diawasi.
5.
6. Jason W, Maarten B, Vincent Y, et al adakah GPT "dilatih syaitan"? ——Tafsiran kertas InstructGPT https://cloud.tencent.com/developer/news/979148
Atas ialah kandungan terperinci SembangGPT topik satu sejarah evolusi keluarga GPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
Kaedah pembelajaran mendalam hari ini memberi tumpuan kepada mereka bentuk fungsi objektif yang paling sesuai supaya keputusan ramalan model paling hampir dengan situasi sebenar. Pada masa yang sama, seni bina yang sesuai mesti direka bentuk untuk mendapatkan maklumat yang mencukupi untuk ramalan. Kaedah sedia ada mengabaikan fakta bahawa apabila data input mengalami pengekstrakan ciri lapisan demi lapisan dan transformasi spatial, sejumlah besar maklumat akan hilang. Artikel ini akan menyelidiki isu penting apabila menghantar data melalui rangkaian dalam, iaitu kesesakan maklumat dan fungsi boleh balik. Berdasarkan ini, konsep maklumat kecerunan boleh atur cara (PGI) dicadangkan untuk menghadapi pelbagai perubahan yang diperlukan oleh rangkaian dalam untuk mencapai pelbagai objektif. PGI boleh menyediakan maklumat input lengkap untuk tugas sasaran untuk mengira fungsi objektif, dengan itu mendapatkan maklumat kecerunan yang boleh dipercayai untuk mengemas kini berat rangkaian. Di samping itu, rangka kerja rangkaian ringan baharu direka bentuk
 Gabungan sempurna ChatGPT dan Python: mencipta chatbot perkhidmatan pelanggan yang pintar
Oct 27, 2023 pm 06:00 PM
Gabungan sempurna ChatGPT dan Python: mencipta chatbot perkhidmatan pelanggan yang pintar
Oct 27, 2023 pm 06:00 PM
Gabungan sempurna ChatGPT dan Python: Mencipta Perkhidmatan Pelanggan Pintar Chatbot Pengenalan: Dalam era maklumat hari ini, sistem perkhidmatan pelanggan pintar telah menjadi alat komunikasi yang penting antara perusahaan dan pelanggan. Untuk memberikan pengalaman perkhidmatan pelanggan yang lebih baik, banyak syarikat telah mula beralih kepada chatbots untuk menyelesaikan tugas seperti perundingan pelanggan dan menjawab soalan. Dalam artikel ini, kami akan memperkenalkan cara menggunakan bahasa ChatGPT dan Python model OpenAI yang berkuasa untuk mencipta bot sembang perkhidmatan pelanggan yang pintar untuk meningkatkan
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
 Pemahaman mendalam tentang format partition Win10: perbandingan GPT dan MBR
Dec 22, 2023 am 11:58 AM
Pemahaman mendalam tentang format partition Win10: perbandingan GPT dan MBR
Dec 22, 2023 am 11:58 AM
Apabila membahagikan sistem mereka sendiri, disebabkan oleh pemacu keras yang berbeza yang digunakan oleh pengguna, ramai pengguna tidak mengetahui format partition win10 gpt atau mbr Atas sebab ini, kami telah membawakan anda pengenalan terperinci untuk membantu anda memahami perbezaan antara keduanya. Format partition Win10 gpt atau mbr: Jawapan: Jika anda menggunakan cakera keras melebihi 3 TB, anda boleh menggunakan gpt. gpt lebih maju daripada mbr, tetapi mbr masih lebih baik dari segi keserasian. Sudah tentu, ini juga boleh dipilih mengikut keutamaan pengguna. Perbezaan antara gpt dan mbr: 1. Bilangan partition yang disokong: 1. MBR menyokong sehingga 4 partition primer. 2. GPT tidak dihadkan oleh bilangan partition. 2. Saiz cakera keras yang disokong: 1. MBR hanya menyokong sehingga 2TB
 Sekiranya saya memilih MBR atau GPT sebagai format cakera keras untuk win7?
Jan 03, 2024 pm 08:09 PM
Sekiranya saya memilih MBR atau GPT sebagai format cakera keras untuk win7?
Jan 03, 2024 pm 08:09 PM
Apabila kami menggunakan sistem pengendalian win7, kadangkala kami mungkin menghadapi situasi di mana kami perlu memasang semula sistem dan membahagikan cakera keras. Mengenai isu sama ada format cakera keras win7 memerlukan mbr atau gpt, editor berpendapat bahawa anda masih perlu membuat pilihan berdasarkan butiran konfigurasi sistem dan perkakasan anda sendiri. Dari segi keserasian, sebaiknya pilih format mbr. Untuk butiran, mari kita lihat apa yang dilakukan oleh editor~ Format cakera keras win7 memerlukan mbr atau gpt1 Jika sistem dipasang dengan Win7, adalah disyorkan untuk menggunakan MBR, yang mempunyai keserasian yang baik. 2. Jika melebihi 3T atau pasang win8, anda boleh menggunakan GPT. 3. Walaupun GPT sememangnya lebih maju daripada MBR, MBR pastinya tidak dapat dikalahkan dari segi keserasian. Kawasan GPT dan MBR
 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
Alamat kertas: https://arxiv.org/abs/2307.09283 Alamat kod: https://github.com/THU-MIG/RepViTRepViT berprestasi baik dalam seni bina ViT mudah alih dan menunjukkan kelebihan yang ketara. Seterusnya, kami meneroka sumbangan kajian ini. Disebutkan dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala (MSHA) mereka yang membolehkan model mempelajari perwakilan global. Walau bagaimanapun, perbezaan seni bina antara ViT ringan dan CNN ringan belum dikaji sepenuhnya. Dalam kajian ini, penulis menyepadukan ViT ringan ke dalam yang berkesan
 Senjata muktamad untuk penyahpepijatan Kubernetes: K8sGPT
Feb 26, 2024 am 11:40 AM
Senjata muktamad untuk penyahpepijatan Kubernetes: K8sGPT
Feb 26, 2024 am 11:40 AM
Apabila teknologi kecerdasan buatan dan pembelajaran mesin terus berkembang, syarikat dan organisasi telah mula meneroka secara aktif strategi inovatif untuk memanfaatkan teknologi ini untuk meningkatkan daya saing. K8sGPT[2] ialah salah satu alat yang paling berkuasa dalam bidang ini Ia adalah model GPT berdasarkan k8s, yang menggabungkan kelebihan orkestrasi k8s dengan keupayaan pemprosesan bahasa semula jadi yang sangat baik bagi model GPT. Apakah K8sGPT? Mari lihat contoh dahulu: Menurut laman web rasmi K8sGPT: K8sgpt ialah alat yang direka untuk mengimbas, mendiagnosis dan mengklasifikasikan masalah kelompok kubernetes Ia menyepadukan pengalaman SRE ke dalam enjin analisisnya untuk memberikan maklumat yang paling relevan. Melalui aplikasi teknologi kecerdasan buatan, K8sgpt terus memperkaya kandungannya dan membantu pengguna memahami dengan lebih cepat dan tepat.
