
 pembangunan bahagian belakang
Tutorial Python
Dalam Python, bagaimana untuk memisahkan rentetan yang mengandungi berbilang pembatas?
pembangunan bahagian belakang
Tutorial Python
Dalam Python, bagaimana untuk memisahkan rentetan yang mengandungi berbilang pembatas?
Dalam Python, bagaimana untuk memisahkan rentetan yang mengandungi berbilang pembatas?

Untuk memisahkan rentetan menggunakan berbilang pembatas:
Gunakan kaedah re.split(), contohnya re.split(r',|-', my_str). Kaedah
re.split() akan memisahkan rentetan pada semua kejadian salah satu pembatas. Kaedah
import re # ????️ 用 2 个分隔符拆分字符串 my_str = 'fql,jiyik-dot,com' my_list = re.split(r',|-', my_str) # ????️ 以逗号或连字符分隔 print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com']
re.split menerima corak dan rentetan dan membelah rentetan setiap kali corak itu berlaku.
Watak paip |. Padanan A atau B.
Contoh ini membelah rentetan menggunakan 2 pembatas (koma dan sempang).
# ????️ 用 3 个分隔符拆分字符串 my_str = 'fql,jiyik-dot:com' my_list = re.split(r',|-|:', my_str) # ????️ comma, hyphen or colon print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com']
Berikut ialah contoh membelah rentetan menggunakan 3 pembatas (koma, sempang dan bertindih).
Kita boleh menggunakan seberapa banyak | aksara yang diperlukan dalam ungkapan biasa.
Gunakan kurungan segi empat sama [] untuk membelah rentetan berdasarkan berbilang pembatas
Sebagai alternatif, kita boleh menggunakan kurungan segi empat sama [] untuk menunjukkan sekumpulan aksara.
import re my_str = 'fql,jiyik-dot,com' my_list = re.split(r'[,-]', my_str) print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com']
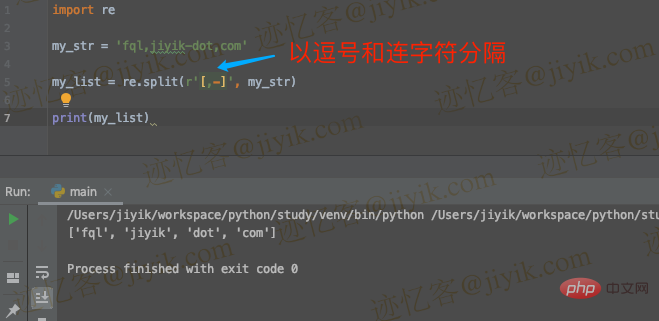
Pastikan anda menambah semua pemisah antara kurungan segi empat sama.
import re # ????️ 用 3 个分隔符拆分字符串 my_str = 'fql,jiyik-dot:com' my_list = re.split(r'[,-:]', my_str) # 以逗号、连字符、冒号分割 print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com']
Jika rentetan bermula atau berakhir dengan salah satu pembatas ini, kita mungkin mendapat nilai rentetan kosong dalam senarai output.
Mengendalikan pembatas di hadapan atau di belakang
Kami boleh menggunakan pemahaman senarai untuk mengalih keluar sebarang rentetan kosong daripada senarai.
import re
# ????️ 用 3 个分隔符拆分字符串
my_str = ',fql,jiyik-dot:com:'
my_list = [
item for item in re.split(r'[,-:]', my_str)
if item
]
print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com']Pemahaman senarai bertanggungjawab untuk mengalih keluar rentetan kosong daripada senarai.
Kefahaman senarai digunakan untuk melaksanakan operasi tertentu pada setiap elemen atau untuk memilih subset elemen yang memenuhi syarat.
Cara lain ialah menggunakan kaedah str.replace().
Pisah rentetan dengan berbilang pembatas menggunakan str.replace()
Untuk membelah rentetan dengan berbilang pembatas:
-
Ganti pembatas pertama dengan pembatas kedua menggunakan kaedah
str.replace(). Pisah rentetan dengan pembatas kedua menggunakan kaedah
str.split().
my_str = 'fql_jiyik!dot_com' my_list = my_str.replace('_', '!').split('!') print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com']
Kaedah ini hanya sesuai apabila terdapat beberapa pembatas yang anda ingin belah, seperti 2.
Pertama, kami Gantikan setiap kejadian daripada pembatas pertama dengan pembatas kedua, dan kemudian kita pecahkan pembatas kedua. Kaedah
str.replace mengembalikan salinan rentetan dengan semua kejadian subrentetan digantikan dengan penggantian yang disediakan.
Kaedah ini mengambil parameter berikut:
lama Subrentetan yang ingin kami gantikan dalam rentetan
-
baharu Gantikan setiap kejadian lama
kira Gantikan hanya kejadian pertama kiraan (pilihan)
Sila ambil perhatian bahawa kaedah ini tidak mengubah rentetan asal. Rentetan tidak boleh diubah dalam Python.
Ini satu lagi contoh.
my_str = 'fql jiyik, dot # com. abc'
my_list = my_str.replace(
',', '').replace(
'#', '').replace('.', '').split()
print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com', 'abc']Kami menggunakan kaedah str.replace() untuk mengalih keluar tanda baca sebelum membelah rentetan pada aksara ruang putih.
Kami menggunakan rentetan kosong untuk penggantian kerana kami ingin mengalih keluar aksara yang ditentukan.
Kami boleh merantai seberapa banyak panggilan ke kaedah str.replace() mengikut keperluan.
Langkah terakhir ialah membelah rentetan kepada senarai perkataan menggunakan kaedah str.split(). Kaedah
str.split() membahagikan rentetan kepada senarai subrentetan menggunakan pembatas.
Kaedah ini mengambil 2 parameter berikut:
pemisah Pisahkan rentetan kepada subrentetan setiap kali pemisah muncul
< . lebih banyak aksara ruang putih. my_str = 'fql jiyik com' print(my_str.split()) # ????️ ['fql', 'jiyik', 'com']
Salin selepas log masukJika pembatas tidak ditemui dalam rentetan, mengembalikan senarai yang mengandungi hanya 1 elemen. Pisah rentetan berdasarkan berbilang pembatas menggunakan fungsi boleh guna semula
Jika kita perlu kerap membelah rentetan berdasarkan berbilang pembatas, tentukan fungsi boleh guna semula. Fungsi
import re
def split_multiple(string, delimiters):
pattern = '|'.join(map(re.escape, delimiters))
return re.split(pattern, string)
my_str = 'fql,jiyik-dot:com'
print(split_multiple(my_str, [',', '-', ':']))str.split() menerima rentetan dan senarai pembatas dan membahagi rentetan berdasarkan pembatas. Kaedah
. Pembahagi.
# ????️ ,|-|: print('|'.join([',', '-', ':']))
Ini akan mencipta corak ungkapan biasa yang boleh kita gunakan untuk memisahkan rentetan berdasarkan pembatas yang ditentukan.
Jika kita perlu membahagikan rentetan kepada senarai perkataan dengan berbilang pembatas, kita juga boleh menggunakan kaedah split_multiple.
Pisah rentetan kepada senarai perkataan menggunakan re.findall() str.join()|Gunakan kaedah
akan membelah rentetan setiap kali perkataan berlaku dan mengembalikan senarai yang mengandungi perkataan itu. Kaedah re.findall()
import re # ✅ 将字符串拆分为具有多个分隔符的单词列表 my_str = 'fql jiyik, dot # com. abc' my_list = re.findall(r'[\w]+', my_str) print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com', 'abc']
mengambil corak dan rentetan sebagai parameter dan mengembalikan senarai rentetan yang mengandungi semua kejadian tidak bertindih bagi corak dalam rentetan.
我们传递给 re.findall() 方法的第一个参数是一个正则表达式。
import re my_str = 'fql jiyik, dot # com. abc' my_list = re.findall(r'[\w]+', my_str) print(my_list) # ????️ ['fql', 'jiyik', 'dot', 'com', 'abc']
方括号 [] 用于表示一组字符。
\w字符与 Unicode 单词字符匹配,并且包括可以作为任何语言的单词一部分的大多数字符。
加号 + 使正则表达式匹配前面字符(Unicode 字符)的 1 次或多次重复。
re.findall() 方法返回一个包含字符串中单词的列表。
Atas ialah kandungan terperinci Dalam Python, bagaimana untuk memisahkan rentetan yang mengandungi berbilang pembatas?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1677
1677
 14
1430
52
1333
25
1278
29
1257
24
14
1430
52
1333
25
1278
29
1257
24

 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Cara menjalankan Python Kod Sublime
Apr 16, 2025 am 08:48 AM
Cara menjalankan Python Kod Sublime
Apr 16, 2025 am 08:48 AM
Untuk menjalankan kod python dalam teks luhur, anda perlu memasang plug-in python terlebih dahulu, kemudian buat fail .py dan tulis kod itu, dan akhirnya tekan Ctrl B untuk menjalankan kod, dan output akan dipaparkan dalam konsol.
 PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP berasal pada tahun 1994 dan dibangunkan oleh Rasmuslerdorf. Ia pada asalnya digunakan untuk mengesan pelawat laman web dan secara beransur-ansur berkembang menjadi bahasa skrip sisi pelayan dan digunakan secara meluas dalam pembangunan web. Python telah dibangunkan oleh Guidovan Rossum pada akhir 1980 -an dan pertama kali dikeluarkan pada tahun 1991. Ia menekankan kebolehbacaan dan kesederhanaan kod, dan sesuai untuk pengkomputeran saintifik, analisis data dan bidang lain.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Golang vs Python: Prestasi dan Skala
Apr 19, 2025 am 12:18 AM
Golang vs Python: Prestasi dan Skala
Apr 19, 2025 am 12:18 AM
Golang lebih baik daripada Python dari segi prestasi dan skalabiliti. 1) Ciri-ciri jenis kompilasi Golang dan model konkurensi yang cekap menjadikannya berfungsi dengan baik dalam senario konvensional yang tinggi. 2) Python, sebagai bahasa yang ditafsirkan, melaksanakan perlahan -lahan, tetapi dapat mengoptimumkan prestasi melalui alat seperti Cython.
 Di mana untuk menulis kod di vscode
Apr 15, 2025 pm 09:54 PM
Di mana untuk menulis kod di vscode
Apr 15, 2025 pm 09:54 PM
Kod penulisan dalam Kod Visual Studio (VSCode) adalah mudah dan mudah digunakan. Hanya pasang VSCode, buat projek, pilih bahasa, buat fail, tulis kod, simpan dan jalankannya. Kelebihan vscode termasuk sumber lintas platform, bebas dan terbuka, ciri-ciri yang kuat, sambungan yang kaya, dan ringan dan cepat.
 Cara menjalankan python dengan notepad
Apr 16, 2025 pm 07:33 PM
Cara menjalankan python dengan notepad
Apr 16, 2025 pm 07:33 PM
Running Python Code di Notepad memerlukan Python Executable dan NPPExec plug-in untuk dipasang. Selepas memasang Python dan menambahkan laluannya, konfigurasikan perintah "python" dan parameter "{current_directory} {file_name}" dalam plug-in nppexec untuk menjalankan kod python melalui kunci pintasan "f6" dalam notepad.
