
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk menggunakan Python untuk xpath, JsonPath, dan bs4?
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk menggunakan Python untuk xpath, JsonPath, dan bs4?
Bagaimana untuk menggunakan Python untuk xpath, JsonPath, dan bs4?

1.xpath
1.1 penggunaan xpath
Google memasang pemalam xpath terlebih dahulu, tekan ctrl + shift + x dan kotak hitam kecil akan muncul
Pasang perpustakaan lxml
pip install lxml ‐i https://pypi.douban.com/simpleImport lxml.etree
from lxml import etreeetree .parse() untuk menghuraikan fail setempat
html_tree = etree.parse('XX.html')etree.HTML() fail respons pelayan
html_tree = etree.HTML(response.read().decode('utf‐8').html_tree.xpath (laluan xpath)
1.2 Sintaks asas xpath
1 Pertanyaan Laluan
Cari semua nod keturunan, tanpa mengira hubungan hierarki
Cari nod anak langsung
2 pertanyaan predikat
//div[@id] //div[@id="maincontent"]
3 🎜>4. Pertanyaan kabur
//@class
5. Pertanyaan kandungan
//div[contains(@id, "he")] //div[starts‐with(@id, "he")]
6. 🎜>
//div/h2/text()
//div[@id="head" and @class="s_down"] //title | //price
1.4
Merangkak nilai butang carian Baidu
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="class1">北京</li>
<li id="l2" class="class2">上海</li>
<li id="d1">广州</li>
<li>深圳</li>
</ul>
</body>
</html>1.5 Merangkak gambar bahan webmaster
from lxml import etree
# xpath解析
# 本地文件: etree.parse
# 服务器相应的数据 response.read().decode('utf-8') etree.HTML()
tree = etree.parse('xpath.html')
# 查找url下边的li
li_list = tree.xpath('//body/ul/li')
print(len(li_list)) # 4
# 获取标签中的内容
li_list = tree.xpath('//body/ul/li/text()')
print(li_list) # ['北京', '上海', '广州', '深圳']
# 获取带id属性的li
li_list = tree.xpath('//ul/li[@id]')
print(len(li_list)) # 3
# 获取id为l1的标签内容
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list) # ['北京']
# 获取id为l1的class属性值
c1 = tree.xpath('//ul/li[@id="l1"]/@class')
print(c1) # ['class1']
# 获取id中包含l的标签
li_list = tree.xpath('//ul/li[contains(@id, "l")]/text()')
print(li_list) # ['北京', '上海']
# 获取id以d开头的标签
li_list = tree.xpath('//ul/li[starts-with(@id,"d")]/text()')
print(li_list) # ['广州']
# 获取id为l2并且class为class2的标签
li_list = tree.xpath('//ul/li[@id="l2" and @class="class2"]/text()')
print(li_list) # ['上海']
# 获取id为l2或id为d1的标签
li_list = tree.xpath('//ul/li[@id="l2"]/text() | //ul/li[@id="d1"]/text()')
print(li_list) # ['上海', '广州']
Salin selepas log masuk2. JsonPath
Pemasangan 2.1 pipfrom lxml import etree # xpath解析 # 本地文件: etree.parse # 服务器相应的数据 response.read().decode('utf-8') etree.HTML() tree = etree.parse('xpath.html') # 查找url下边的li li_list = tree.xpath('//body/ul/li') print(len(li_list)) # 4 # 获取标签中的内容 li_list = tree.xpath('//body/ul/li/text()') print(li_list) # ['北京', '上海', '广州', '深圳'] # 获取带id属性的li li_list = tree.xpath('//ul/li[@id]') print(len(li_list)) # 3 # 获取id为l1的标签内容 li_list = tree.xpath('//ul/li[@id="l1"]/text()') print(li_list) # ['北京'] # 获取id为l1的class属性值 c1 = tree.xpath('//ul/li[@id="l1"]/@class') print(c1) # ['class1'] # 获取id中包含l的标签 li_list = tree.xpath('//ul/li[contains(@id, "l")]/text()') print(li_list) # ['北京', '上海'] # 获取id以d开头的标签 li_list = tree.xpath('//ul/li[starts-with(@id,"d")]/text()') print(li_list) # ['广州'] # 获取id为l2并且class为class2的标签 li_list = tree.xpath('//ul/li[@id="l2" and @class="class2"]/text()') print(li_list) # ['上海'] # 获取id为l2或id为d1的标签 li_list = tree.xpath('//ul/li[@id="l2"]/text() | //ul/li[@id="d1"]/text()') print(li_list) # ['上海', '广州']
import urllib.request
from lxml import etree
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
value = tree.xpath('//input[@id="su"]/@value')
print(value)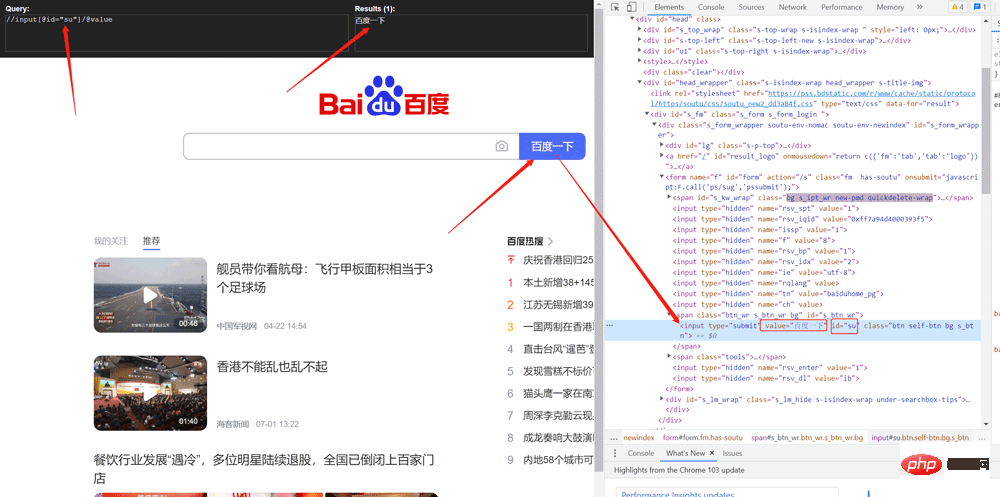 2.2 Penggunaan jsonpath
2.2 Penggunaan jsonpath# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):
if (page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
print(src_list)
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url, filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page + 1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)Contoh:
jsonpath.json
pip install jsonpath
obj = json.load(open('json文件', 'r', encoding='utf‐8')) ret = jsonpath.jsonpath(obj, 'jsonpath语法')
3.1 Pengenalan asas1. Pasang
pip pasang bs4
2 bs4 import BeautifulSoup
3 Cipta objek
Sup objek penjanaan fail tempatan = BeautifulSoup(open('1.html'), 'lxml')Sup objek penjanaan fail respons pelayan = BeautifulSoup(response.read().decode(), 'lxml'. )
Nota:
- Lalai Format pengekodan fail terbuka ialah gbk, jadi anda perlu menentukan format pengekodan pembukaan utf-8
- 3.2 Pemasangan dan penciptaan
- 3.3 Kedudukan nod3.5 Maklumat nod
import json import jsonpath obj = json.load(open('jsonpath.json', 'r', encoding='utf-8')) # 书店所有书的作者 author_list = jsonpath.jsonpath(obj, '$.store.book[*].author') print(author_list) # ['六道', '天蚕土豆', '唐家三少', '南派三叔'] # 所有的作者 author_list = jsonpath.jsonpath(obj, '$..author') print(author_list) # ['六道', '天蚕土豆', '唐家三少', '南派三叔', '老马'] # store下面的所有的元素 tag_list = jsonpath.jsonpath(obj, '$.store.*') print( tag_list) # [[{'category': '修真', 'author': '六道', 'title': '坏蛋是怎样练成的', 'price': 8.95}, {'category': '修真', 'author': '天蚕土豆', 'title': '斗破苍穹', 'price': 12.99}, {'category': '修真', 'author': '唐家三少', 'title': '斗罗大陆', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}], {'author': '老马', 'color': '黑色', 'price': 19.95}] # store里面所有东西的price price_list = jsonpath.jsonpath(obj, '$.store..price') print(price_list) # [8.95, 12.99, 8.99, 22.99, 19.95] # 第三个书 book = jsonpath.jsonpath(obj, '$..book[2]') print(book) # [{'category': '修真', 'author': '唐家三少', 'title': '斗罗大陆', 'isbn': '0-553-21311-3', 'price': 8.99}] # 最后一本书 book = jsonpath.jsonpath(obj, '$..book[(@.length-1)]') print(book) # [{'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}] # 前面的两本书 book_list = jsonpath.jsonpath(obj, '$..book[0,1]') # book_list = jsonpath.jsonpath(obj,'$..book[:2]') print( book_list) # [{'category': '修真', 'author': '六道', 'title': '坏蛋是怎样练成的', 'price': 8.95}, {'category': '修真', 'author': '天蚕土豆', 'title': '斗破苍穹', 'price': 12.99}] # 条件过滤需要在()的前面添加一个? # 过滤出所有的包含isbn的书。 book_list = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]') print( book_list) # [{'category': '修真', 'author': '唐家三少', 'title': '斗罗大陆', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}] # 哪本书超过了10块钱 book_list = jsonpath.jsonpath(obj, '$..book[?(@.price>10)]') print( book_list) # [{'category': '修真', 'author': '天蚕土豆', 'title': '斗破苍穹', 'price': 12.99}, {'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}]Salin selepas log masuk
{ "store": {
"book": [
{ "category": "修真",
"author": "六道",
"title": "坏蛋是怎样练成的",
"price": 8.95
},
{ "category": "修真",
"author": "天蚕土豆",
"title": "斗破苍穹",
"price": 12.99
},
{ "category": "修真",
"author": "唐家三少",
"title": "斗罗大陆",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "修真",
"author": "南派三叔",
"title": "星辰变",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author": "老马",
"color": "黑色",
"price": 19.95
}
}
}1.根据标签名查找节点 soup.a 【注】只能找到第一个a soup.a.name soup.a.attrs 2.函数 (1).find(返回一个对象) find('a'):只找到第一个a标签 find('a', title='名字') find('a', class_='名字') (2).find_all(返回一个列表) find_all('a') 查找到所有的a find_all(['a', 'span']) 返回所有的a和span find_all('a', limit=2) 只找前两个a (3).select(根据选择器得到节点对象)【推荐】 1.element eg:p 2..class eg:.firstname 3.#id eg:#firstname 4.属性选择器 [attribute] eg:li = soup.select('li[class]') [attribute=value] eg:li = soup.select('li[class="hengheng1"]') 5.层级选择器 element element div p element>element div>p element,element div,p eg:soup = soup.select('a,span')
1.根据标签名查找节点 soup.a 【注】只能找到第一个a soup.a.name soup.a.attrs 2.函数 (1).find(返回一个对象) find('a'):只找到第一个a标签 find('a', title='名字') find('a', class_='名字') (2).find_all(返回一个列表) find_all('a') 查找到所有的a find_all(['a', 'span']) 返回所有的a和span find_all('a', limit=2) 只找前两个a (3).select(根据选择器得到节点对象)【推荐】 1.element eg:p 2..class eg:.firstname 3.#id eg:#firstname 4.属性选择器 [attribute] eg:li = soup.select('li[class]') [attribute=value] eg:li = soup.select('li[class="hengheng1"]') 5.层级选择器 element element div p element>element div>p element,element div,p eg:soup = soup.select('a,span')
nama produkbs4.html
(1).获取节点内容:适用于标签中嵌套标签的结构 obj.string obj.get_text()【推荐】 (2).节点的属性 tag.name 获取标签名 eg:tag = find('li) print(tag.name) tag.attrs将属性值作为一个字典返回 (3).获取节点属性 obj.attrs.get('title')【常用】 obj.get('title') obj['title']Salin selepas log masukSalin selepas log masuk(1).获取节点内容:适用于标签中嵌套标签的结构 obj.string obj.get_text()【推荐】 (2).节点的属性 tag.name 获取标签名 eg:tag = find('li) print(tag.name) tag.attrs将属性值作为一个字典返回 (3).获取节点属性 obj.attrs.get('title')【常用】 obj.get('title') obj['title']Salin selepas log masukSalin selepas log masuk
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<a href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" " class="a1">google</a>
<span>嘿嘿嘿</span>
</ul>
</div>
<a href="" title=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" a2">百度</a>
<div id="d1">
<span>
哈哈哈
</span>
</div>
<p id="p1" class="p1">呵呵呵</p>
</body>
</html>from bs4 import BeautifulSoup
# 通过解析本地文件 来将bs4的基础语法进行讲解
# 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
soup = BeautifulSoup(open('bs4.html', encoding='utf-8'), 'lxml')
# 根据标签名查找节点
# 找到的是第一个符合条件的数据
print(soup.a) # <a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>
# 获取标签的属性和属性值
print(soup.a.attrs) # {'href': '', 'id': '', 'class': ['a1']}
# bs4的一些函数
# (1)find
# 返回的是第一个符合条件的数据
print(soup.find('a')) # <a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>
# 根据title的值来找到对应的标签对象
print(soup.find('a', title="a2")) # <a href="" title=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" a2">百度</a>
# 根据class的值来找到对应的标签对象 注意的是class需要添加下划线
print(soup.find('a', class_="a1")) # <a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>
# (2)find_all 返回的是一个列表 并且返回了所有的a标签
print(soup.find_all('a')) # [<a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>, <a href="" title=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" a2">百度</a>]
# 如果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据
print(soup.find_all(['a','span'])) # [<a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>, <span>嘿嘿嘿</span>, <a href="" title=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" a2">百</a><spa哈</span>]
# limit的作用是查找前几个数据
print(soup.find_all('li', limit=2)) # [<li id="l1">张三</li>, <li id="l2">李四</li>]
# (3)select(推荐)
# select方法返回的是一个列表 并且会返回多个数据
print(soup.select('a')) # [<a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>, <a href="" title=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" a2">百度</a>]
# 可以通过.代表class 我们把这种操作叫做类选择器
print(soup.select('.a1')) # [<a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>]
print(soup.select('#l1')) # [<li id="l1">张三</li>]
# 属性选择器---通过属性来寻找对应的标签
# 查找到li标签中有id的标签
print(soup.select('li[id]')) # [<li id="l1">张三</li>, <li id="l2">李四</li>]
# 查找到li标签中id为l2的标签
print(soup.select('li[id="l2"]')) # [<li id="l2">李四</li>]
# 层级选择器
# 后代选择器
# 找到的是div下面的li
print(soup.select('div li')) # [<li id="l1">张三</li>, <li id="l2">李四</li>, <li>王五</li>]
# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中 如果不加空格不会输出内容 但是在bs4中 不会报错 会显示内容
print(soup.select('div > ul > li')) # [<li id="l1">张三</li>, <li id="l2">李四</li>, <li>王五</li>]
# 找到a标签和li标签的所有的对象
print(soup.select(
'a,li')) # [<li id="l1">张三</li>, <li id="l2">李四</li>, <li>王五</li>, <a class="a1" href="" id=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ">google</a>, <a href="" title=" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" a2">百度</a>]
# 节点信息
# 获取节点内容
obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
print(obj.string) # None
print(obj.get_text()) # 哈哈哈
# 节点的属性
obj = soup.select('#p1')[0]
# name是标签的名字
print(obj.name) # p
# 将属性值左右一个字典返回
print(obj.attrs) # {'id': 'p1', 'class': ['p1']}
# 获取节点的属性
obj = soup.select('#p1')[0]
#
print(obj.attrs.get('class')) # ['p1']
print(obj.get('class')) # ['p1']
print(obj['class']) # ['p1']3.9cks Starbucks
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
# 一般先用xpath方式通过google插件写好解析的表达式
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())Atas ialah kandungan terperinci Bagaimana untuk menggunakan Python untuk xpath, JsonPath, dan bs4?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Menggunakan Log Debian Apache Untuk Meningkatkan Prestasi Laman Web
Apr 12, 2025 pm 11:36 PM
Cara Menggunakan Log Debian Apache Untuk Meningkatkan Prestasi Laman Web
Apr 12, 2025 pm 11:36 PM
Artikel ini akan menerangkan bagaimana untuk meningkatkan prestasi laman web dengan menganalisis log Apache di bawah sistem Debian. 1. Asas Analisis Log Apache Log merekodkan maklumat terperinci semua permintaan HTTP, termasuk alamat IP, timestamp, url permintaan, kaedah HTTP dan kod tindak balas. Dalam sistem Debian, log ini biasanya terletak di direktori/var/log/apache2/access.log dan /var/log/apache2/error.log. Memahami struktur log adalah langkah pertama dalam analisis yang berkesan. 2. Alat Analisis Log Anda boleh menggunakan pelbagai alat untuk menganalisis log Apache: Alat baris arahan: grep, awk, sed dan alat baris arahan lain.
 Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Peranan Sniffer Debian dalam Pengesanan Serangan DDOS
Apr 12, 2025 pm 10:42 PM
Peranan Sniffer Debian dalam Pengesanan Serangan DDOS
Apr 12, 2025 pm 10:42 PM
Artikel ini membincangkan kaedah pengesanan serangan DDoS. Walaupun tiada kes permohonan langsung "debiansniffer" ditemui, kaedah berikut boleh digunakan untuk pengesanan serangan DDOS: Teknologi Pengesanan Serangan DDo Sebagai contoh, skrip Python yang digabungkan dengan perpustakaan Pyshark dan Colorama boleh memantau trafik rangkaian dalam masa nyata dan mengeluarkan makluman. Pengesanan berdasarkan analisis statistik: dengan menganalisis ciri statistik trafik rangkaian, seperti data
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Artikel ini akan membimbing anda tentang cara mengemas kini sijil NginxSSL anda pada sistem Debian anda. Langkah 1: Pasang Certbot terlebih dahulu, pastikan sistem anda mempunyai pakej CertBot dan Python3-CertBot-Nginx yang dipasang. Jika tidak dipasang, sila laksanakan arahan berikut: sudoapt-getupdateudoapt-getinstallcertbotpython3-certbot-nginx Langkah 2: Dapatkan dan konfigurasikan sijil Gunakan perintah certbot untuk mendapatkan sijil let'Sencrypt dan konfigurasikan nginx: sudoCertBot-ninx ikuti
 Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Mengkonfigurasi pelayan HTTPS pada sistem Debian melibatkan beberapa langkah, termasuk memasang perisian yang diperlukan, menghasilkan sijil SSL, dan mengkonfigurasi pelayan web (seperti Apache atau Nginx) untuk menggunakan sijil SSL. Berikut adalah panduan asas, dengan mengandaikan anda menggunakan pelayan Apacheweb. 1. Pasang perisian yang diperlukan terlebih dahulu, pastikan sistem anda terkini dan pasang Apache dan OpenSSL: sudoaptDateSudoaptgradesudoaptinsta
