

Tadbir urus perkhidmatan mikro algoritma NLP WeChat


1. Gambaran Keseluruhan
Musk memperoleh Twitter, tetapi tidak berpuas hati dengan teknologinya. Fikirkan halaman utama terlalu perlahan kerana terdapat lebih 1000 RPC. Tanpa mengulas sama ada alasan Musk katakan adalah betul, dapat dilihat bahawa perkhidmatan lengkap yang diberikan kepada pengguna di Internet akan mempunyai sejumlah besar panggilan perkhidmatan mikro di belakangnya.
Mengambil saranan pembacaan WeChat sebagai contoh, ia dibahagikan kepada dua peringkat: mengingat dan menyusun.
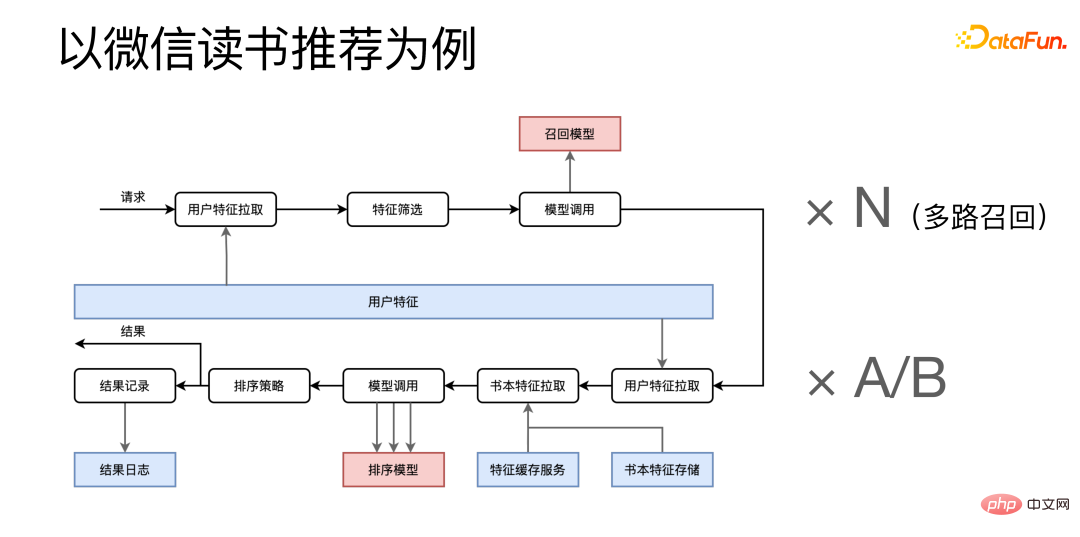
Selepas permintaan tiba, ia akan mula menarik ciri daripada perkhidmatan mikro ciri pengguna dan letakkan ciri Gabungkan mereka untuk melakukan penyaringan ciri, dan kemudian panggil perkhidmatan mikro yang berkaitan dengan panggilan semula Proses ini juga perlu didarab dengan N kerana kami mempunyai panggilan balik berbilang saluran dan akan terdapat banyak proses penarikan balik yang serupa yang dijalankan pada masa yang sama. masa. Berikut ialah peringkat pengisihan, yang menarik ciri yang berkaitan daripada berbilang perkhidmatan mikro ciri dan memanggil perkhidmatan model pengisihan beberapa kali selepas menggabungkannya. Selepas mendapat keputusan akhir, dalam satu pihak, hasil akhir dikembalikan kepada pemanggil, dan sebaliknya, beberapa log proses dihantar ke sistem log untuk pengarkiban.
Syor membaca hanyalah sebahagian kecil daripada keseluruhan APP Pembacaan WeChat Dapat dilihat bahawa perkhidmatan yang agak kecil akan mempunyai sejumlah besar perkhidmatan mikro di belakangnya. Jika anda melihat dengan lebih dekat, anda boleh menjangkakan bahawa keseluruhan sistem Pembacaan WeChat akan mempunyai sejumlah besar panggilan perkhidmatan mikro.
Apakah masalah yang dibawa oleh sejumlah besar perkhidmatan mikro?
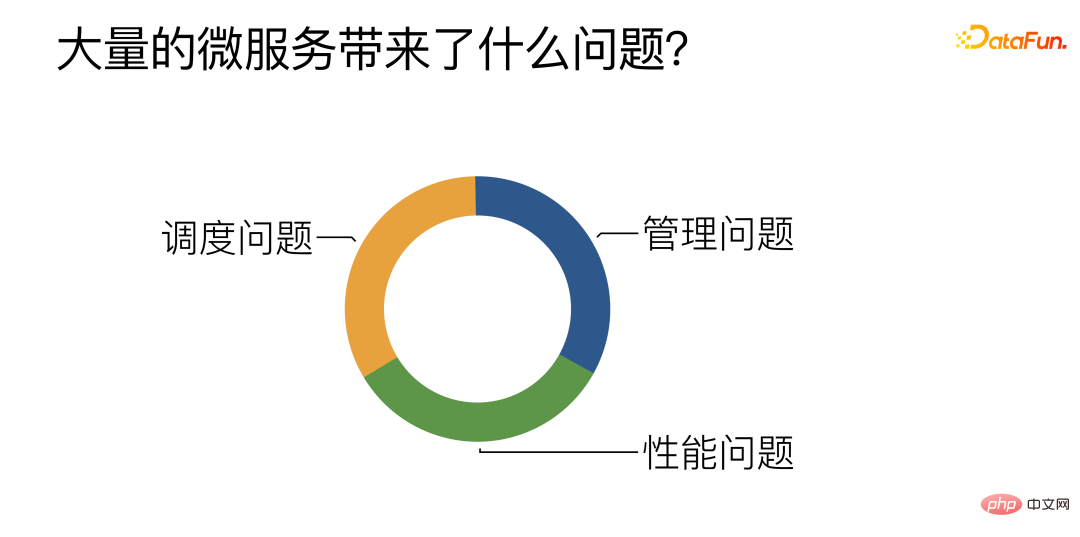
Menurut ringkasan kerja harian, terdapat terutamanya tiga cabaran:
① Pengurusan: Terutamanya mengenai cara mengurus, membangun dan menggunakan sejumlah besar perkhidmatan mikro algoritma dengan cekap.
② Prestasi: Cuba tingkatkan prestasi perkhidmatan mikro, terutamanya perkhidmatan mikro algoritma.
③ Penjadualan: Cara untuk mencapai pengimbangan beban yang cekap dan munasabah antara pelbagai perkhidmatan mikro algoritma serupa.
2. Isu pengurusan yang dihadapi oleh perkhidmatan mikro
1 🎜>
Perkara pertama ialah kami menyediakan beberapa saluran paip pembungkusan dan penggunaan automatik untuk mengurangkan tekanan pelajar algoritma untuk membangunkan perkhidmatan mikro algoritma Anda sahaja perlu menulis fungsi Python, dan saluran paip akan secara automatik menarik satu siri templat perkhidmatan mikro pra-tulis dan mengisi fungsi yang dibangunkan oleh pelajar algoritma untuk membina perkhidmatan mikro dengan cepat.
2. Pengembangan dan penguncupan kapasiti: pengembangan dan penguncupan automatik berdasarkan kesedaran tunggakan tugas
Perkara kedua ialah tentang perkhidmatan mikro Untuk pengembangan dan pengecutan automatik, kami menggunakan penyelesaian maklum balas tugasan . Kami akan secara aktif mengesan tahap tunggakan atau kemalasan bagi jenis tugasan tertentu Apabila tunggakan melebihi ambang tertentu, operasi pengembangan akan dicetuskan secara automatik Apabila kemalasan mencapai ambang tertentu, pengurangan bilangan proses perkhidmatan mikro akan juga akan dicetuskan.
3. Organisasi perkhidmatan mikro: Turing melengkapkan DAG / DSL / ujian tekanan automatik / penggunaan automatik
Titik ketiga ialah cara meletakkan besar bilangan Perkhidmatan Mikro dianjurkan bersama untuk membina perkhidmatan lapisan atas yang lengkap. Perkhidmatan lapisan atas kami diwakili oleh DAG Setiap nod DAG mewakili panggilan ke perkhidmatan mikro, dan setiap tepi mewakili pemindahan data antara perkhidmatan. Untuk DAG, DSL (bahasa khusus domain) juga telah dibangunkan khas untuk menerangkan dan menstruktur DAG dengan lebih baik. Dan kami telah membangunkan satu siri alatan berasaskan web di sekitar DSL, yang boleh membina secara visual, menguji tekanan dan menggunakan perkhidmatan lapisan atas secara langsung dalam penyemak imbas.
4. Pemantauan prestasi: Sistem jejak
Mata keempatPemantauan prestasi, apabila Apabila terdapat masalah dengan perkhidmatan lapisan atas, kami perlu mencari masalah Kami membina sistem Trace kami sendiri. Untuk setiap permintaan luaran, terdapat set penjejakan yang lengkap, yang boleh menyemak penggunaan masa permintaan dalam setiap perkhidmatan mikro, dengan itu menemui kesesakan prestasi sistem.
3. Isu prestasi yang dihadapi oleh perkhidmatan mikro
Secara umumnya, masa prestasi algoritma adalah Berkenaan dengan pembelajaran mendalam model, sebahagian besar tumpuan mengoptimumkan prestasi perkhidmatan mikro algoritma ialah mengoptimumkan prestasi inferen model pembelajaran mendalam. Anda boleh memilih rangka kerja kesimpulan khusus, atau mencuba penyusun pembelajaran mendalam, pengoptimuman kernel, dsb. Untuk penyelesaian ini, kami percaya bahawa penyelesaian tersebut tidak diperlukan sepenuhnya. Dalam banyak kes, kami terus menggunakan skrip Python untuk pergi ke dalam talian, dan kami masih boleh mencapai prestasi yang setanding dengan C++. Sebab mengapa
tidak diperlukan sepenuhnya ialah penyelesaian ini sememangnya boleh membawa prestasi yang lebih baik, tetapi prestasi yang baik bukanlah satu-satunya keperluan untuk perkhidmatan. Terdapat peraturan 80/20 yang terkenal, diterangkan dari segi orang dan sumber, iaitu, 20% orang akan menjana 80% daripada sumber Dalam erti kata lain, 20% orang akan memberikan 80% daripada sumbangan . Ini juga terpakai kepada perkhidmatan mikro.
Kami boleh membahagikan perkhidmatan mikro kepada dua kategori Pertama, perkhidmatan matang dan stabil tidak banyak dan mungkin hanya menduduki 20%, tetapi menanggung 80% trafik. Kategori lain ialah beberapa perkhidmatan atau perkhidmatan percubaan yang masih dalam pembangunan dan lelaran Terdapat banyak daripada mereka, menyumbang 80%, tetapi mereka hanya menyumbang 20% daripada trafik lelaran, jadi Terdapat juga permintaan yang kuat untuk pembangunan dan pelancaran pesat.
Kaedah yang dinyatakan sebelum ini, seperti rangka kerja Infer, pengoptimuman Kernel, dsb., sudah pasti memerlukan kos pembangunan tambahan. Perkhidmatan matang dan stabil masih sangat sesuai untuk kaedah jenis ini, kerana terdapat sedikit perubahan dan ia boleh digunakan untuk masa yang lama selepas satu pengoptimuman. Sebaliknya, perkhidmatan ini menanggung jumlah trafik yang besar, dan peningkatan prestasi yang kecil mungkin mempunyai kesan yang besar, jadi ia berbaloi untuk melabur dalam kos.
Tetapi kaedah ini tidak begitu sesuai untuk perkhidmatan percubaan, kerana perkhidmatan percubaan akan dikemas kini dengan kerap dan kami tidak boleh membuat pengoptimuman baharu untuk setiap model baharu. Untuk perkhidmatan percubaan, kami membangunkan penterjemah Python yang dibangunkan sendiri - PyInter untuk senario penggunaan hibrid GPU. Ia adalah mungkin untuk pergi ke dalam talian terus menggunakan skrip Python tanpa mengubah suai sebarang kod, dan pada masa yang sama, prestasi boleh hampir atau bahkan melebihi C++.
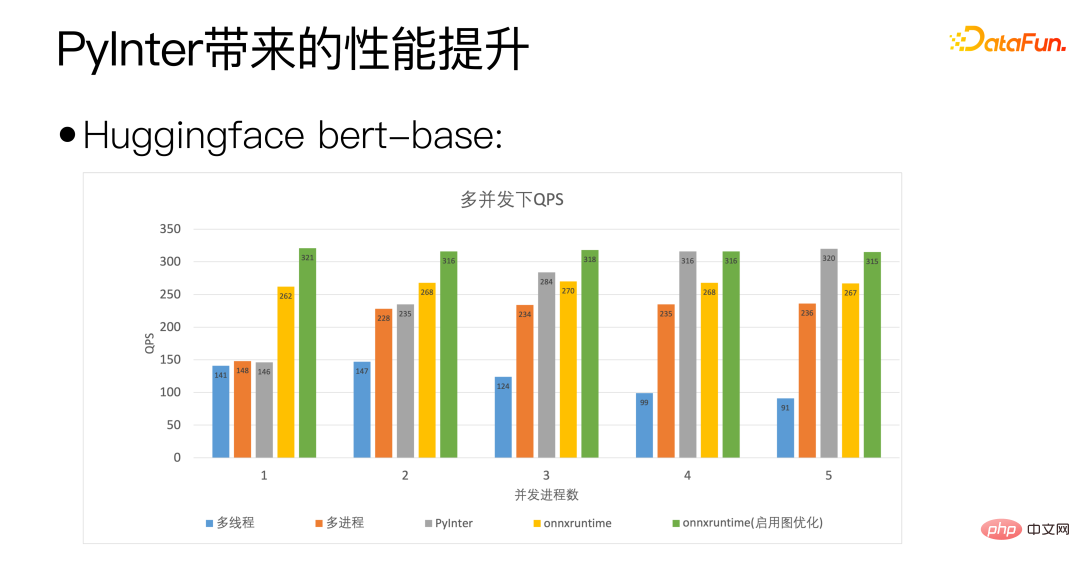
Kami menggunakan tapak bert Huggingface sebagai piawaian paksi mendatar rajah di atas adalah concurrency. Bilangan proses mewakili bilangan salinan model yang kami gunakan. Ia boleh dilihat bahawa QPS PyInter kami bahkan melebihi onnxruntime apabila bilangan salinan model adalah besar.
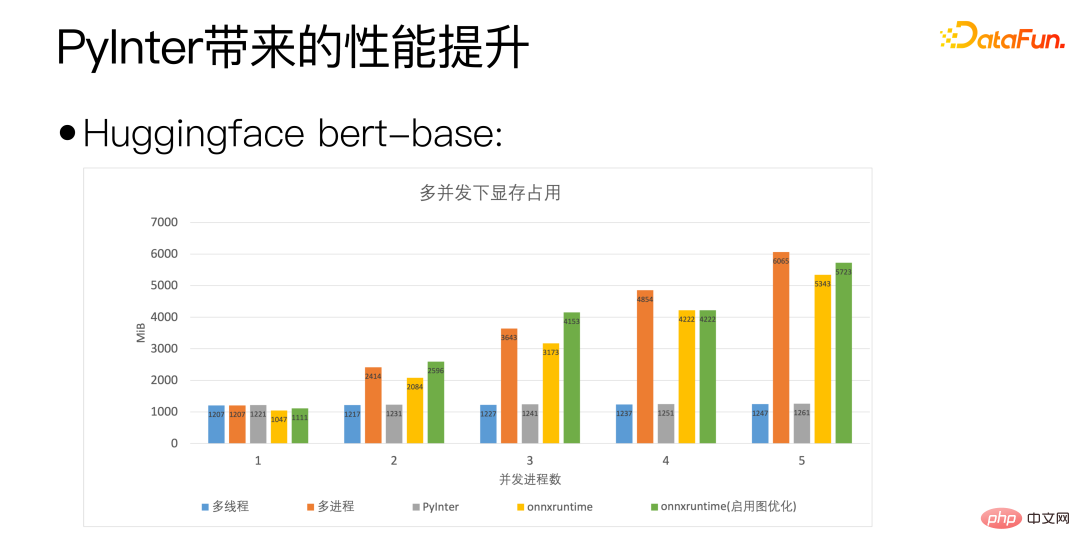
Melalui rajah di atas, anda boleh melihat bahawa PyInter berprestasi baik apabila bilangan model salinan adalah besar Berbanding dengan pelbagai proses dan ONNXRuntime, penggunaan memori video dikurangkan hampir 80%, dan sila ambil perhatian bahawa tanpa mengira bilangan salinan model, penggunaan memori video PyInter kekal tidak berubah.
Mari kita kembali kepada soalan yang lebih asas: Adakah Python benar-benar lambat?
Ya, Python benar-benar lambat, tetapi pengiraan saintifik dalam Python tidak perlahan, kerana pengiraan sebenar tidak dilakukan dalam Python, tetapi dalam perpustakaan pengiraan khusus seperti MKL atau cuBLAS.
Jadi di manakah kesesakan prestasi utama Python? Terutamanya disebabkan oleh GIL (Global Interpreter Lock) di bawah multi-threading, yang menyebabkan hanya satu thread berfungsi pada masa yang sama di bawah multi-threading. Bentuk multithreading ini mungkin berguna untuk tugas intensif IO, tetapi ia tidak masuk akal untuk penggunaan model, yang sangat intensif dari segi pengiraan.
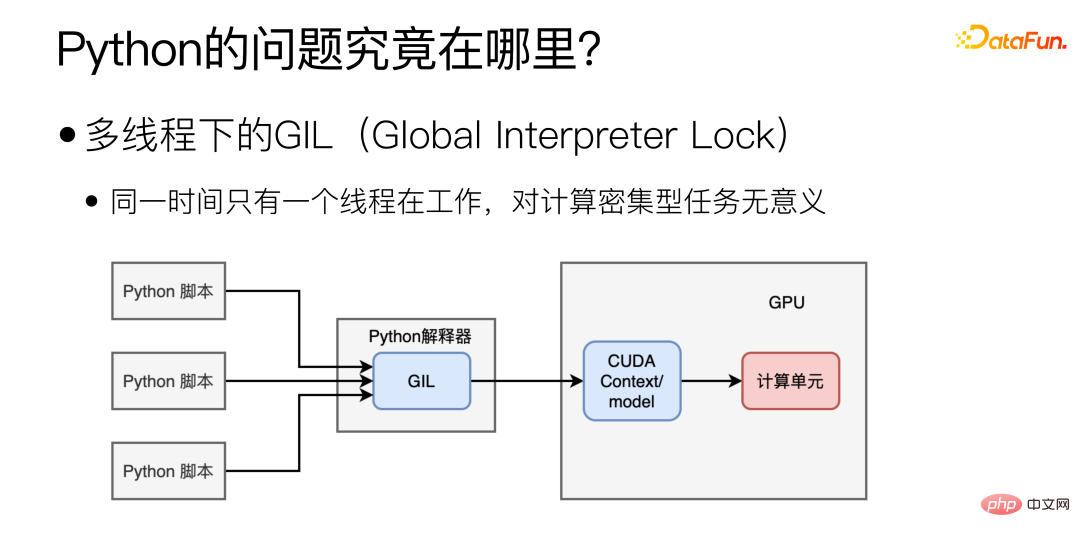
Adakah penukaran kepada berbilang proses menyelesaikan masalah?
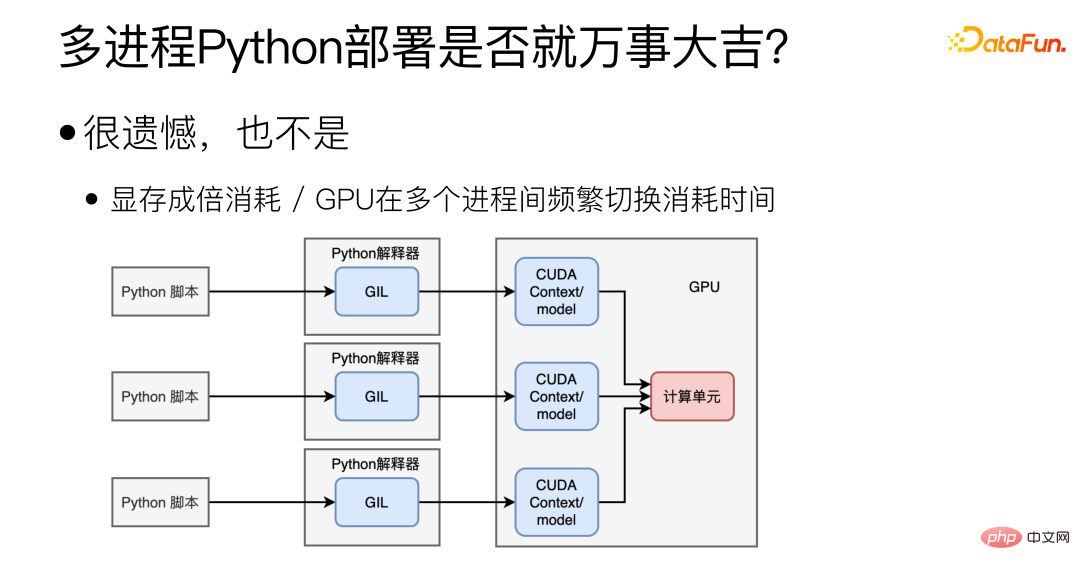
Sebenarnya tidak, pelbagai proses memang boleh menyelesaikan masalah GIL, tetapi ia akan juga membawa soalan baru Lain. Pertama sekali, adalah sukar untuk berkongsi Konteks/model CUDA antara pelbagai proses, yang akan menyebabkan banyak pembaziran memori video Dalam kes ini, beberapa model tidak boleh digunakan pada satu kad grafik. Yang kedua ialah masalah GPU GPU hanya boleh melaksanakan tugas satu proses pada masa yang sama, dan penukaran GPU yang kerap antara pelbagai proses juga memakan masa.
Untuk senario Python, mod ideal adalah seperti yang ditunjukkan di bawah:
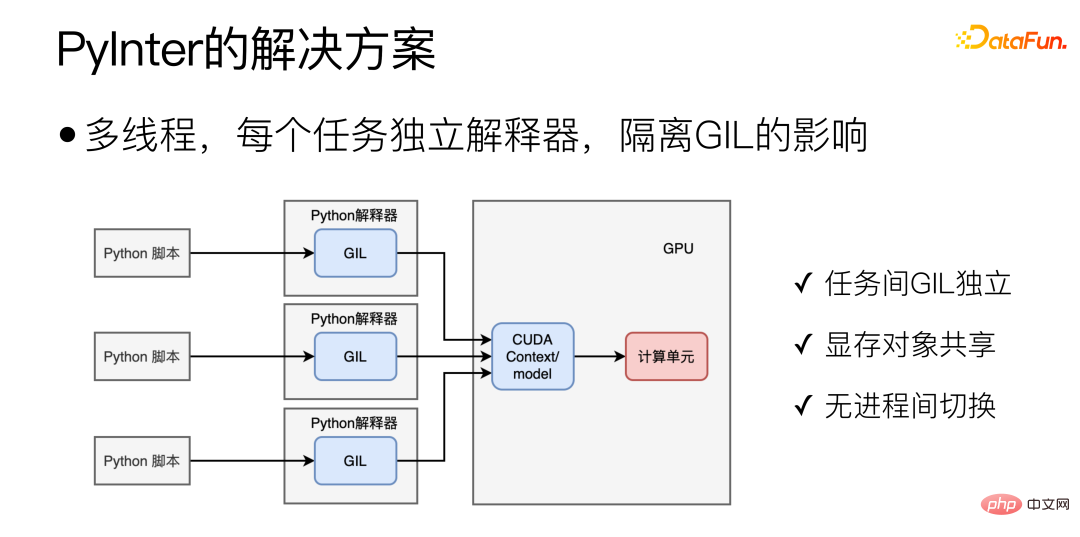
Sebarkan melalui multi-threading dan buang pengaruh GIL Ini juga merupakan idea reka bentuk utama PyInter, meletakkan salinan berbilang model dalam berbilang thread untuk dilaksanakan. , dan cipta penterjemah Python yang berasingan dan terpencil untuk setiap tugas Python, supaya GIL berbilang tugas tidak akan mengganggu satu sama lain. Ini menggabungkan kelebihan berbilang proses dan berbilang benang Di satu pihak, GIL adalah bebas antara satu sama lain Sebaliknya, ia pada dasarnya adalah mod berbilang benang satu proses, jadi objek memori video boleh dikongsi. dan tiada proses GPU menukar overhed.
Kunci kepada pelaksanaan PyInter ialah pengasingan perpustakaan dinamik dalam proses Pengasingan penterjemah pada dasarnya adalah pengasingan perpustakaan dinamik pemuat perpustakaan dinamik, serupa dengan dlopen, tetapi Menyokong dua kaedah pemuatan perpustakaan dinamik: "terpencil" dan "berkongsi".
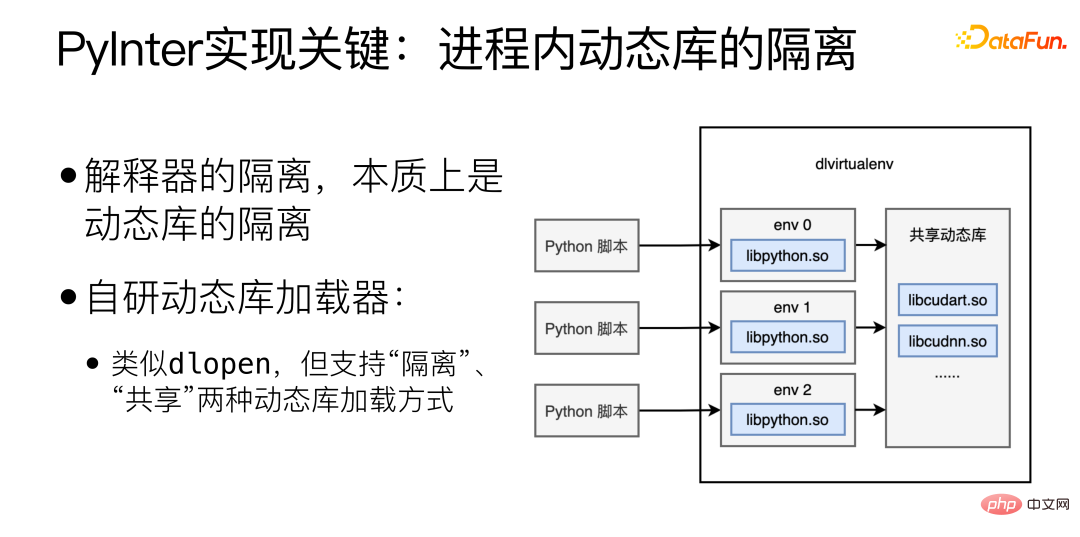
Memuatkan perpustakaan dinamik dalam mod "terpencil" akan memuatkan perpustakaan dinamik ke dalam ruang Maya yang berbeza, ruang maya yang berbeza tidak dapat melihat satu sama lain. Jika pustaka dinamik dimuatkan dalam mod "kongsi", pustaka dinamik boleh dilihat dan digunakan di mana-mana dalam proses, termasuk di dalam setiap ruang maya.
Muatkan perpustakaan berkaitan penterjemah Python dalam mod "terpencil", dan kemudian muatkan perpustakaan berkaitan cuda dalam mod "kongsi", dengan itu mencapai pemproses tafsiran terpencil sambil berkongsi sumber memori video.
4 Isu penjadualan yang dihadapi oleh perkhidmatan mikro
Berbilang perkhidmatan mikro memainkan kepentingan yang sama dan Kesan yang sama, maka bagaimanakah untuk mencapai pengimbangan beban dinamik antara pelbagai perkhidmatan mikro. Pengimbangan beban dinamik adalah penting, tetapi hampir mustahil untuk dilakukan dengan sempurna.
Mengapakah pengimbangan beban dinamik penting? Sebabnya adalah seperti berikut:
(1) Perbezaan perkakasan mesin (CPU / GPU); >(2) Permintaan perbezaan panjang (2 perkataan diterjemahkan / 200 perkataan diterjemahkan); jelas:
① Perbezaan antara P99/P50 boleh sehingga 10 kali ganda; sehingga 20 kali ganda.
(4) Untuk perkhidmatan mikro, ekor panjang adalah kunci untuk menentukan kelajuan keseluruhan.
Masa yang diambil untuk memproses permintaan sangat berbeza-beza, dan perbezaan dalam kuasa pengkomputeran, panjang permintaan, dll. semuanya akan menjejaskan masa yang diambil. Apabila bilangan perkhidmatan mikro meningkat, akan sentiasa terdapat beberapa perkhidmatan mikro yang mencapai ekor panjang, yang akan menjejaskan masa tindak balas keseluruhan sistem.
Mengapakah pengimbangan beban dinamik sukar untuk disempurnakan?
Pilihan 1: Jalankan Penanda Aras pada semua mesin.
Penyelesaian ini tidak "dinamik" dan tidak dapat menampung perbezaan dalam panjang Permintaan. Dan tiada penanda aras sempurna yang boleh mencerminkan prestasi Mesin yang berbeza akan bertindak balas secara berbeza kepada model yang berbeza.
Pilihan 2: Dapatkan status setiap mesin dalam masa nyata dan hantar tugasan kepada mesin yang mempunyai beban paling ringan.
Penyelesaian ini lebih intuitif, tetapi masalahnya ialah tiada "masa nyata" sebenar dalam sistem yang diedarkan, maklumat dihantar dari satu mesin ke mesin lain Ia pasti akan mengambil masa, dan pada masa ini, status mesin boleh berubah. Sebagai contoh, pada masa tertentu, mesin Pekerja tertentu adalah yang paling melahu, dan beberapa mesin Induk yang bertanggungjawab untuk pengagihan tugas semua merasakannya, jadi mereka semua memberikan tugas kepada Pekerja yang paling terbiar ini, dan Pekerja yang paling terbiar ini serta-merta menjadi Ini adalah kesan pasang surut yang terkenal dalam pengimbangan beban.
Pilihan 3: Mengekalkan baris gilir tugasan yang unik di peringkat global Semua Guru yang bertanggungjawab untuk pengagihan tugas menghantar tugas ke baris gilir, dan semua Pekerja mengambil tugas dari baris gilir .
Dalam penyelesaian ini, baris gilir tugas itu sendiri mungkin menjadi satu titik kesesakan, menjadikannya sukar untuk menskala secara mendatar.
Sebab asas mengapa pengimbangan beban dinamik sukar untuk disempurnakan ialah penghantaran maklumat memerlukan masa Apabila keadaan diperhatikan, negeri ini mesti Ia "lalu". Ada video di Youtube yang saya syorkan kepada semua, "Load Balancing is Impossible" https://www.youtube.com/watch?v=kpvbOzHUakA.
Mengenai algoritma pengimbangan beban dinamik, algoritma Power of 2 Choices secara rawak memilih dua pekerja dan memberikan tugasan kepada yang lebih terbiar. Algoritma ini ialah asas untuk algoritma penyamaan dinamik yang kami gunakan pada masa ini. Walau bagaimanapun, terdapat dua masalah utama dengan algoritma Kuasa 2 Pilihan: Pertama, sebelum setiap tugasan diberikan, status terbiar Pekerja perlu disoal, yang menambah satu lagi RTT sebagai tambahan, kemungkinan kedua-duanya secara rawak; pekerja terpilih kebetulan sangat sibuk. Untuk menyelesaikan masalah ini, kami telah membuat penambahbaikan.
Algoritma yang dipertingkatkan bagi 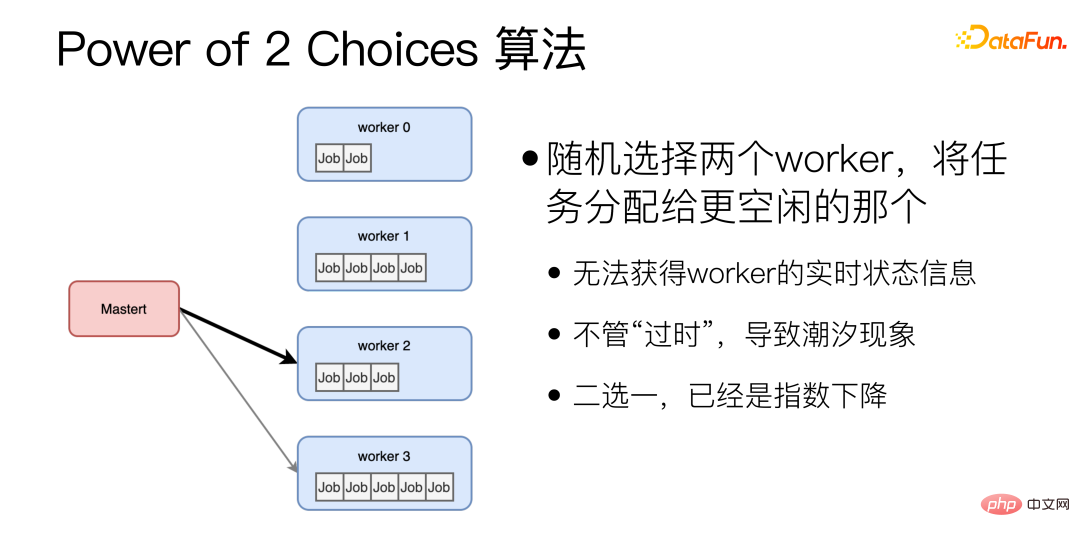
Kami telah menambah dua bahagian pada mesin Master, Idle-Queue dan Amnesia. Idle-Queue digunakan untuk merekod Pekerja yang sedang melahu. Amnesia merekodkan yang Pekerja telah menghantar paket degupan jantung kepada dirinya sendiri dalam tempoh baru-baru ini Jika Pekerja tidak menghantar paket degupan jantung untuk masa yang lama, Amnesia akan melupakannya secara beransur-ansur. Setiap Pekerja melaporkan secara berkala sama ada Pekerja terbiar memilih Master untuk melaporkan IdIenessnya dan melaporkan nombor yang boleh diproses. Pekerja juga menggunakan algoritma Kuasa 2 Pilihan apabila memilih Sarjana Untuk Sarjana lain, Pekerja melaporkan paket degupan jantung. 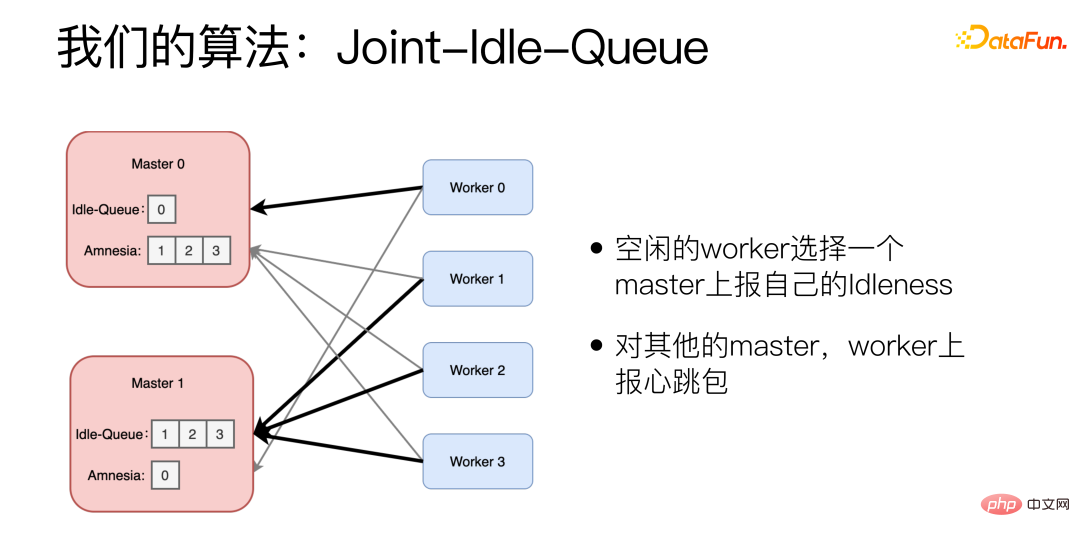
Apabila tugasan baharu tiba, Guru secara rawak memilih dua daripada Baris Terbiar dan memilih tugasan yang mempunyai kependaman sejarah yang lebih rendah. Jika Baris Terbiar kosong, Amnesia akan dilihat. Pilih dua secara rawak daripada Amnesia dan pilih satu dengan kependaman sejarah yang lebih rendah.
Dalam kesan sebenar, menggunakan algoritma ini, P99/P50 boleh dimampatkan kepada 1.5 kali, iaitu 10 kali lebih baik daripada algoritma Rawak.
5 Ringkasan
Dalam amalan servis model, kami telah menghadapi tiga cabaran: <.> prosedur.
Yang kedua ialah pengoptimuman prestasi model Cara menjadikan perkhidmatan mikro model pembelajaran mendalam berjalan dengan lebih cekap ialah bermula daripada keperluan sebenar model dan menyesuaikan perkhidmatan yang agak stabil dan mempunyai trafik yang besar , PyInter digunakan untuk perkhidmatan percubaan Secara langsung menggunakan skrip Python untuk melancarkan perkhidmatan juga boleh mencapai prestasi C++.
Masalah ketiga ialah penjadualan tugasan Cara mencapai pengimbangan beban dinamik
Penyelesaian kami adalah berdasarkan Kuasa 2 PilihanMembangunkan algoritma JIQ masalah ekor panjang perkhidmatan yang memakan masa.
Atas ialah kandungan terperinci Tadbir urus perkhidmatan mikro algoritma NLP WeChat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Pengekodan Vibe membentuk semula dunia pembangunan perisian dengan membiarkan kami membuat aplikasi menggunakan bahasa semulajadi dan bukannya kod yang tidak berkesudahan. Diilhamkan oleh penglihatan seperti Andrej Karpathy, pendekatan inovatif ini membolehkan Dev
 Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Februari 2025 telah menjadi satu lagi bulan yang berubah-ubah untuk AI generatif, membawa kita beberapa peningkatan model yang paling dinanti-nantikan dan ciri-ciri baru yang hebat. Dari Xai's Grok 3 dan Anthropic's Claude 3.7 Sonnet, ke Openai's G
 Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Yolo (anda hanya melihat sekali) telah menjadi kerangka pengesanan objek masa nyata yang terkemuka, dengan setiap lelaran bertambah baik pada versi sebelumnya. Versi terbaru Yolo V12 memperkenalkan kemajuan yang meningkatkan ketepatan
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast: AI Revolusioner untuk Peramalan Cuaca Peramalan cuaca telah menjalani transformasi dramatik, bergerak dari pemerhatian asas kepada ramalan berkuasa AI yang canggih. Google Deepmind's Gencast, tanah air
 AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
Artikel ini membincangkan model AI yang melampaui chatgpt, seperti Lamda, Llama, dan Grok, menonjolkan kelebihan mereka dalam ketepatan, pemahaman, dan kesan industri. (159 aksara)
 O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
Openai's O1: Hadiah 12 Hari Bermula dengan model mereka yang paling berkuasa Ketibaan Disember membawa kelembapan global, kepingan salji di beberapa bahagian dunia, tetapi Openai baru sahaja bermula. Sam Altman dan pasukannya melancarkan mantan hadiah 12 hari
 Cara Menggunakan Mistral OCR untuk Model RAG Seterusnya
Mar 21, 2025 am 11:11 AM
Cara Menggunakan Mistral OCR untuk Model RAG Seterusnya
Mar 21, 2025 am 11:11 AM
Mistral OCR: Merevolusi Generasi Pengambilan Pengambilan semula dengan Pemahaman Dokumen Multimodal Sistem Generasi Pengambilan Retrieval (RAG) mempunyai keupayaan AI yang ketara, membolehkan akses ke kedai data yang luas untuk mendapatkan respons yang lebih tepat
