
 Peranti teknologi
AI
Kaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.
Peranti teknologi
AI
Kaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.
Kaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.

Terdapat kaedah latihan teras sedemikian dalam ChatGPT yang dipanggil "Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF)".
Ia boleh menjadikan model lebih selamat dan hasil keluarannya lebih konsisten dengan niat manusia.
Kini, penyelidik dari Google Research dan UC Berkeley telah mendapati bahawa menggunakan kaedah ini pada lukisan AI boleh "merawat" situasi di mana imej tidak betul-betul sepadan dengan input, dan kesannya sangat baik -
Sehingga 47% peningkatan boleh dicapai.

△ Kiri adalah Stable Diffusion, kanan ialah kesan yang lebih baik
Pada masa ini, dua model popular dalam bidang AIGC nampaknya telah menemui "resonans" tertentu.
Bagaimana untuk menggunakan RLHF untuk lukisan AI?
RLHF, nama penuh "Pembelajaran Pengukuhan daripada Maklum Balas Manusia", ialah teknologi pembelajaran pengukuhan yang dibangunkan bersama oleh OpenAI dan DeepMind pada 2017.
Seperti namanya, RLHF menggunakan penilaian manusia terhadap hasil keluaran model (iaitu maklum balas) untuk terus mengoptimumkan model Dalam LLM, ia boleh menjadikan "nilai model" lebih konsisten dengan nilai manusia.
Dalam model penjanaan imej AI, ia boleh menjajarkan sepenuhnya imej yang dijana dengan gesaan teks.
Khususnya, pertama, kumpulkan data maklum balas manusia.
Di sini, penyelidik menjana sejumlah lebih daripada 27,000 "pasangan imej teks" dan kemudian meminta beberapa manusia untuk menjaringkannya.
Demi kesederhanaan, gesaan teks hanya termasuk empat kategori berikut, berkaitan dengan kuantiti, warna, latar belakang dan pilihan pengadunan hanya dibahagikan kepada "baik", "buruk" dan "jangan tahu (langkau)" ".

Kedua, pelajari fungsi ganjaran.
Langkah ini adalah untuk menggunakan set data yang terdiri daripada penilaian manusia yang baru diperolehi untuk melatih fungsi ganjaran, dan kemudian menggunakan fungsi ini untuk meramalkan kepuasan manusia dengan output model (bahagian merah formula).
Dengan cara ini, model mengetahui sejauh mana hasilnya sepadan dengan teks.
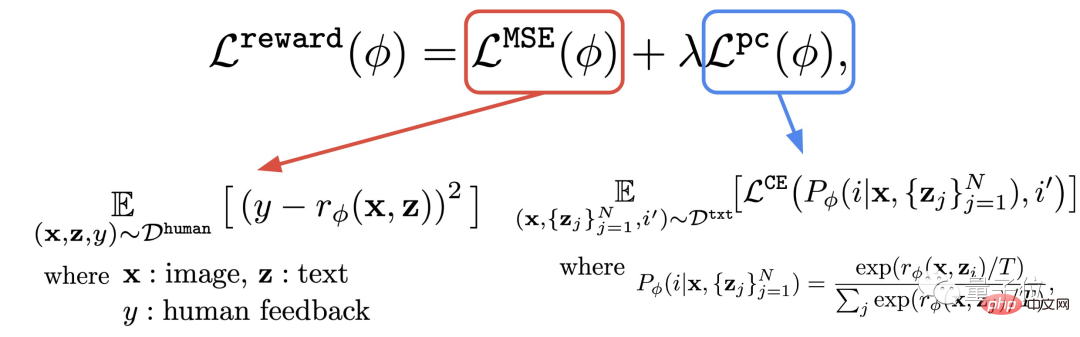
Selain fungsi ganjaran, penulis juga mencadangkan tugas tambahan (bahagian biru formula).
Iaitu, selepas penjanaan imej selesai, model akan memberikan sekumpulan teks, tetapi hanya satu daripadanya ialah teks asal, dan biarkan model ganjaran "menyemak dengan sendirinya" sama ada imej itu sepadan dengan teks.
Operasi terbalik ini boleh menjadikan kesan "insurans berganda" (ia boleh membantu pemahaman langkah 2 dalam gambar di bawah).
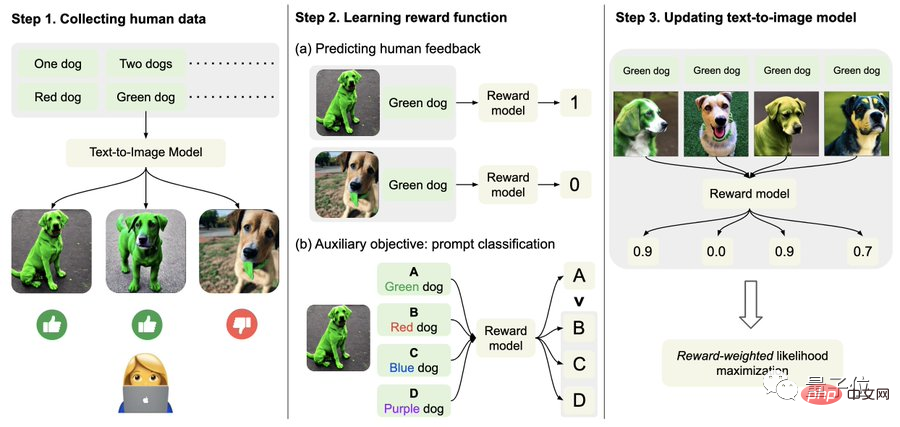
Akhir sekali, ia diperhalusi.
Iaitu, model penjanaan imej teks dikemas kini melalui pemaksimuman kemungkinan wajaran ganjaran (istilah pertama formula di bawah).
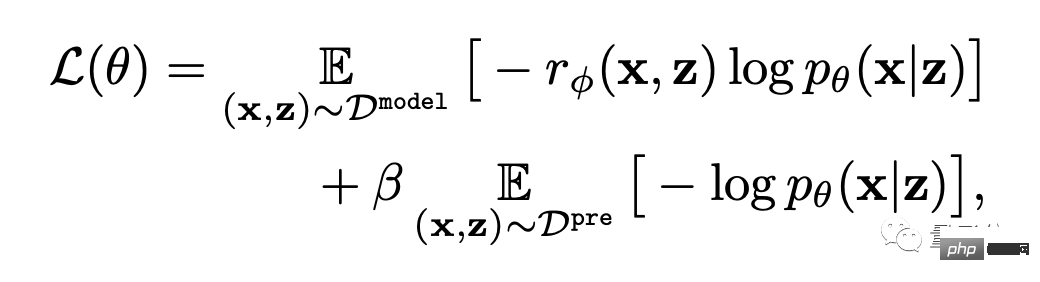
Untuk mengelakkan overfitting, penulis meminimumkan nilai NLL (istilah kedua formula) pada set data pra-latihan. Pendekatan ini serupa dengan InstructionGPT ("pendahulu langsung" ChatGPT).
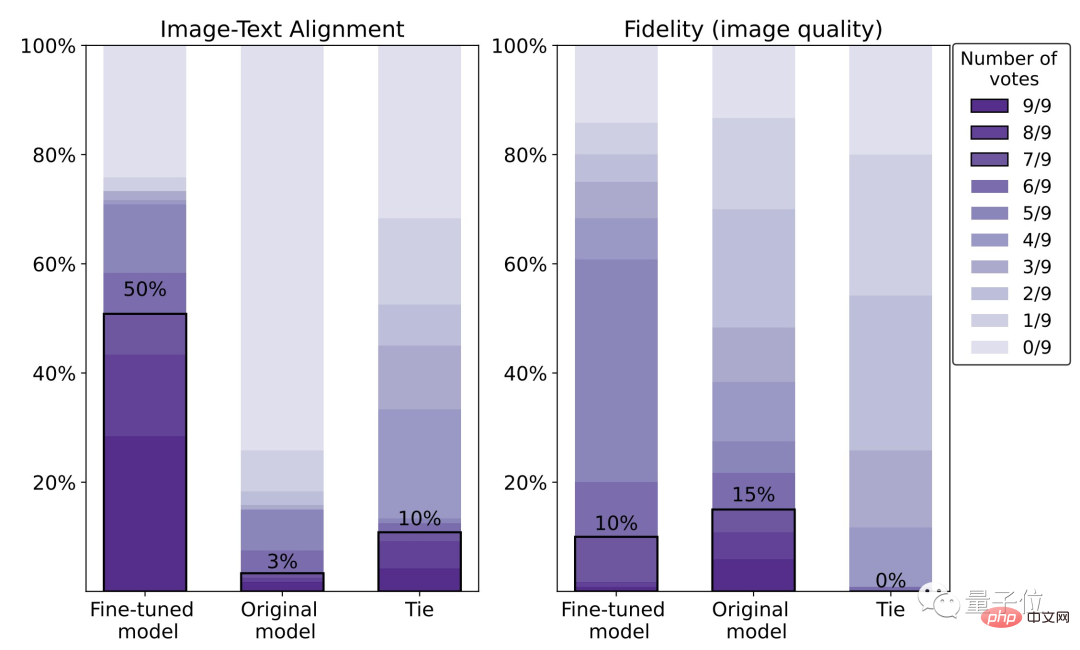
Kesan meningkat sebanyak 47%, tetapi kejelasan menurun sebanyak 5%
Seperti yang ditunjukkan dalam siri kesan berikut, berbanding dengan Stable Diffusion asal, model yang diperhalusi dengan RLHF boleh :
(1) Dapatkan "dua" dan "hijau" dalam teks dengan lebih betul; abaikan "laut" Sebagai keperluan latar belakang;
(3) Jika anda mahukan harimau merah, ia boleh memberikan hasil yang "lebih merah".
 Daripada data khusus, kepuasan manusia terhadap model yang diperhalusi ialah 50%, iaitu peningkatan sebanyak 47% berbanding model asal (3%).
Daripada data khusus, kepuasan manusia terhadap model yang diperhalusi ialah 50%, iaitu peningkatan sebanyak 47% berbanding model asal (3%).
Kita juga boleh melihat dengan jelas dari gambar di bawah bahawa serigala di sebelah kanan jelas lebih kabur daripada yang di sebelah kiri:
Ya Oleh itu, penulis mencadangkan bahawa keadaan boleh diperbaiki menggunakan set data penilaian manusia yang lebih besar dan kaedah pengoptimuman (RL) yang lebih baik.
 Mengenai pengarang
Mengenai pengarang

Memandangkan saintis penyelidikan Google AI Kimin Lee, Ph.D dari Institut Sains dan Teknologi Korea, penyelidikan pasca doktoral telah dijalankan di UC Berkeley.

Tiga pengarang Cina:
Liu Hao, pelajar kedoktoran di UC Berkeley, yang minat penyelidikan utamanya ialah rangkaian saraf maklum balas.
Du Yuqing ialah pelajar PhD di UC Berkeley Halatuju penyelidikan utamanya ialah kaedah pembelajaran pengukuhan tanpa pengawasan.
Shixiang Shane Gu (Gu Shixiang), pengarang yang sepadan, belajar di bawah Hinton, salah satu daripada tiga gergasi, untuk ijazah sarjana mudanya, dan lulus dari Universiti Cambridge dengan ijazah kedoktorannya.

△ Gu Shixiang
Perlu dinyatakan bahawa semasa menulis artikel ini, dia masih seorang Googler, dan kini dia telah beralih kepada OpenAI, di mana dia terus melaporkan kepada Laporan daripada orang yang bertanggungjawab ke atas ChatGPT.
Alamat kertas:
https://arxiv.org/abs/2302.12192
Pautan rujukan: [1]https://www.php .cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2]https://openai.com/blog/instruction-following/
Atas ialah kandungan terperinci Kaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Untuk membuat pangkalan data Oracle, kaedah biasa adalah menggunakan alat grafik DBCA. Langkah -langkah adalah seperti berikut: 1. Gunakan alat DBCA untuk menetapkan DBName untuk menentukan nama pangkalan data; 2. Tetapkan SYSPASSWORD dan SYSTEMPASSWORD kepada kata laluan yang kuat; 3. Tetapkan aksara dan NationalCharacterset ke Al32utf8; 4. Tetapkan MemorySize dan Tablespacesize untuk menyesuaikan mengikut keperluan sebenar; 5. Tentukan laluan logfile. Kaedah lanjutan dibuat secara manual menggunakan arahan SQL, tetapi lebih kompleks dan terdedah kepada kesilapan. Perhatikan kekuatan kata laluan, pemilihan set aksara, saiz dan memori meja makan
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Mewujudkan pangkalan data Oracle tidak mudah, anda perlu memahami mekanisme asas. 1. Anda perlu memahami konsep pangkalan data dan Oracle DBMS; 2. Menguasai konsep teras seperti SID, CDB (pangkalan data kontena), PDB (pangkalan data pluggable); 3. Gunakan SQL*Plus untuk membuat CDB, dan kemudian buat PDB, anda perlu menentukan parameter seperti saiz, bilangan fail data, dan laluan; 4. Aplikasi lanjutan perlu menyesuaikan set aksara, memori dan parameter lain, dan melakukan penalaan prestasi; 5. Beri perhatian kepada ruang cakera, keizinan dan parameter, dan terus memantau dan mengoptimumkan prestasi pangkalan data. Hanya dengan menguasai ia dengan mahir memerlukan amalan yang berterusan, anda boleh benar -benar memahami penciptaan dan pengurusan pangkalan data Oracle.
 Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Inti dari pernyataan Oracle SQL adalah pilih, masukkan, mengemas kini dan memadam, serta aplikasi fleksibel dari pelbagai klausa. Adalah penting untuk memahami mekanisme pelaksanaan di sebalik pernyataan, seperti pengoptimuman indeks. Penggunaan lanjutan termasuk subqueries, pertanyaan sambungan, fungsi analisis, dan PL/SQL. Kesilapan umum termasuk kesilapan sintaks, isu prestasi, dan isu konsistensi data. Amalan terbaik pengoptimuman prestasi melibatkan menggunakan indeks yang sesuai, mengelakkan pilih *, mengoptimumkan di mana klausa, dan menggunakan pembolehubah terikat. Menguasai Oracle SQL memerlukan amalan, termasuk penulisan kod, debugging, berfikir dan memahami mekanisme asas.
 Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Panduan Operasi Lapangan di MySQL: Tambah, mengubah suai, dan memadam medan. Tambahkan medan: alter table table_name tambah column_name data_type [not null] [default default_value] [primary kekunci] [AUTO_INCREMENT] Modify Field: Alter Table Table_Name Ubah suai column_name data_type [not null] [default default_value] [Kunci Utama]
 Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Kekangan integriti pangkalan data Oracle dapat memastikan ketepatan data, termasuk: tidak null: nilai null dilarang; Unik: Keunikan menjamin, membolehkan nilai null tunggal; Kunci utama: kekangan utama utama, menguatkan unik, dan melarang nilai null; Kunci asing: Mengekalkan hubungan antara jadual, kunci asing merujuk kepada kunci utama jadual utama; Semak: Hadkan nilai lajur mengikut syarat.
 Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Pertanyaan bersarang adalah cara untuk memasukkan pertanyaan lain dalam satu pertanyaan. Mereka digunakan terutamanya untuk mendapatkan data yang memenuhi syarat kompleks, mengaitkan pelbagai jadual, dan mengira nilai ringkasan atau maklumat statistik. Contohnya termasuk mencari pekerja di atas gaji purata, mencari pesanan untuk kategori tertentu, dan mengira jumlah jumlah pesanan bagi setiap produk. Apabila menulis pertanyaan bersarang, anda perlu mengikuti: Tulis subqueries, tulis hasilnya kepada pertanyaan luar (dirujuk dengan alias atau sebagai klausa), dan mengoptimumkan prestasi pertanyaan (menggunakan indeks).
 Apa yang dilakukan Oracle
Apr 11, 2025 pm 06:06 PM
Apa yang dilakukan Oracle
Apr 11, 2025 pm 06:06 PM
Oracle adalah syarikat perisian Sistem Pengurusan Pangkalan Data (DBMS) terbesar di dunia. Produk utamanya termasuk fungsi berikut: Sistem Pengurusan Pengurusan Pangkalan Data Relasi (Oracle Database) Alat Pembangunan (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle SOA Suite) Analisis Awan (Oracle Cloud Infrastructure)
 Cara Mengkonfigurasi Format Log Debian Apache
Apr 12, 2025 pm 11:30 PM
Cara Mengkonfigurasi Format Log Debian Apache
Apr 12, 2025 pm 11:30 PM
Artikel ini menerangkan cara menyesuaikan format log Apache pada sistem Debian. Langkah -langkah berikut akan membimbing anda melalui proses konfigurasi: Langkah 1: Akses fail konfigurasi Apache Fail konfigurasi Apache utama sistem Debian biasanya terletak di /etc/apache2/apache2.conf atau /etc/apache2/httpd.conf. Buka fail konfigurasi dengan kebenaran root menggunakan arahan berikut: Sudonano/etc/Apache2/Apache2.conf atau Sudonano/etc/Apache2/httpd.conf Langkah 2: Tentukan format log tersuai untuk mencari atau
