
 pembangunan bahagian belakang
Tutorial Python
Analisis contoh operasi biasa ndarray dalam Python Numpy
pembangunan bahagian belakang
Tutorial Python
Analisis contoh operasi biasa ndarray dalam Python Numpy
Analisis contoh operasi biasa ndarray dalam Python Numpy

Kata Pengantar
NumPy (Numerical Python) ialah sambungan pengkomputeran berangka sumber terbuka untuk Python. Alat ini boleh digunakan untuk menyimpan dan memproses matriks besar Ia jauh lebih cekap daripada struktur senarai bersarang Python sendiri (yang juga boleh digunakan untuk mewakili matriks) dan menyokong sejumlah besar operasi tatasusunan dan matriks , selain itu juga menyediakan sejumlah besar perpustakaan fungsi matematik untuk operasi tatasusunan.
Numpy terutamanya menggunakan ndarray untuk memproses tatasusunan N-dimensi Kebanyakan sifat dan kaedah dalam Numpy berkhidmat ndarray, jadi sangat perlu untuk menguasai operasi biasa ndarray dalam Numpy!
0 Asas Numpy
Objek utama NumPy ialah tatasusunan berbilang dimensi isomorfik. Ia ialah senarai elemen (biasanya nombor), semua jenis yang sama, diindeks oleh tuple integer bukan negatif. Dipanggil paksi dalam dimensi NumPy.
Dalam contoh yang ditunjukkan di bawah, tatasusunan mempunyai 2 paksi. Panjang paksi pertama ialah 2 dan panjang paksi kedua ialah 3.
[[ 1., 0., 0.], [ 0., 1., 2.]]
1 Sifat ndarray
1.1 Sifat biasa output ndarray
ndarray.ndim: Paksi (dimensi) bagi tatasusunan ) nombor. Dalam dunia Python, bilangan dimensi dipanggil pangkat.
ndarray.shape: Dimensi tatasusunan. Ini ialah tuple integer yang mewakili saiz tatasusunan dalam setiap dimensi. Untuk matriks dengan n baris dan m lajur, bentuknya ialah (n,m). Oleh itu, panjang tuple bentuk ialah pangkat atau bilangan dimensi ndim.
ndarray.size: Jumlah bilangan elemen tatasusunan. Ini adalah sama dengan produk unsur-unsur bentuk.
ndarray.dtype: Objek yang menerangkan jenis unsur dalam tatasusunan. Dtype boleh dibuat atau ditentukan menggunakan jenis Python standard. Selain itu NumPy menyediakan jenisnya sendiri. Contohnya numpy.int32, numpy.int16 dan numpy.float64.
ndarray.itemsize : Saiz bait setiap elemen dalam tatasusunan. Sebagai contoh, tatasusunan dengan elemen jenis float64 mempunyai saiz item 8 (=64/8), manakala tatasusunan jenis kompleks32 mempunyai saiz item 4 (=32/8). Ia sama dengan ndarray.dtype.itemsize.
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int64'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
<type 'numpy.ndarray'>2 Jenis data ndarray
Dalam ndarray yang sama, jenis data yang sama disimpan termasuk:
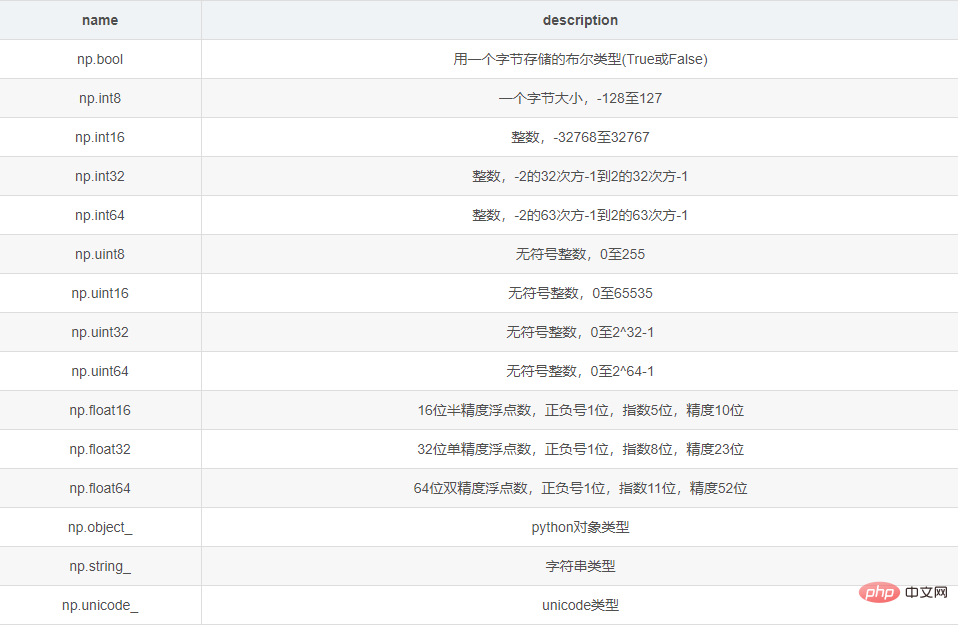
3 Ubah suai bentuk dan jenis data ndarray
3.1 Lihat dan ubah suai bentuk ndarray
## ndarray reshape操作 array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.shape) array_a_1 = array_a.reshape((3, 2)) print(array_a_1, array_a_1.shape) # note: reshape不能改变ndarray中元素的个数,例如reshape之前为(2,3),reshape之后为(3,2)/(1,6)... ## ndarray转置 array_a_2 = array_a.T print(array_a_2, array_a_2.shape) ## ndarray ravel操作:将ndarray展平 a.ravel() # returns the array, flattened array([ 1, 2, 3, 4, 5, 6 ]) 输出: [[1 2 3] [4 5 6]] (2, 3) [[1 2] [3 4] [5 6]] (3, 2) [[1 4] [2 5] [3 6]] (3, 2)
3.2 Lihat dan ubah suai bentuk ndarray Jenis data
astype(dtype[, order, casting, subok, copy]): Ubah suai jenis data dalam ndarray. Masukkan jenis data yang perlu diubah suai dan parameter kata kunci lain boleh diabaikan.
array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.dtype) array_a_1 = array_a.astype(np.int64) print(array_a_1, array_a_1.dtype) 输出: [[1 2 3] [4 5 6]] int32 [[1 2 3] [4 5 6]] int64
4 penciptaan tatasusunan ndarray
NumPy terutamanya mencipta tatasusunan ndarray melalui fungsi np.array().
>>> import numpy as np >>> a = np.array([2,3,4]) >>> a array([2, 3, 4]) >>> a.dtype dtype('int64') >>> b = np.array([1.2, 3.5, 5.1]) >>> b.dtype dtype('float64')
Anda juga boleh menyatakan secara eksplisit jenis tatasusunan semasa mencipta:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])Anda juga boleh mencipta tatasusunan ndarray rawak dengan menggunakan fungsi np.random.random.
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])Biasanya, elemen tatasusunan pada mulanya tidak diketahui, tetapi saiznya diketahui. Oleh itu, NumPy menyediakan beberapa fungsi untuk mencipta tatasusunan dengan kandungan pemegang tempat awal. Ini mengurangkan keperluan untuk pertumbuhan tatasusunan, yang merupakan operasi yang mahal.
Fungsi zeros mencipta tatasusunan 0s, fungsi ones mencipta tatasusunan lengkap dan fungsi empty mencipta tatasusunan yang kandungan awalnya rawak dan bergantung pada keadaan ingatan. Secara lalai, dtype tatasusunan yang dicipta ialah float64.
>>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # uninitialized, output may vary
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])Untuk mencipta tatasusunan nombor, NumPy menyediakan fungsi yang serupa dengan range, yang mengembalikan tatasusunan dan bukannya senarai.
>>> np.arange( 10, 30, 5 ) array([10, 15, 20, 25]) >>> np.arange( 0, 2, 0.3 ) # it accepts float arguments array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
5 Operasi biasa pada tatasusunan ndarray
Tidak seperti kebanyakan bahasa matriks, pengendali produk * beroperasi mengikut elemen pada tatasusunan NumPy. Produk matriks boleh dilakukan menggunakan operator @ (dalam python> = 3.5) atau fungsi atau kaedah dot:
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]]) Sesetengah operasi, seperti += dan *=, berubah secara langsung Tatasusunan matriks yang dimanipulasi tidak menghasilkan tatasusunan matriks baharu.
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'Apabila beroperasi dengan tatasusunan pelbagai jenis, jenis tatasusunan yang terhasil sepadan dengan tatasusunan yang lebih umum atau tepat (tingkah laku yang dipanggil upcasting).
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'Banyak operasi unari, seperti mengira jumlah semua elemen dalam tatasusunan, dilaksanakan sebagai kaedah kelas ndarray.
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum()
2.5718191614547998
>>> a.min()
0.1862602113776709
>>> a.max()
0.6852195003967595Secara lalai, operasi ini berfungsi pada tatasusunan seolah-olah ia adalah senarai nombor, tanpa mengira bentuknya. Walau bagaimanapun, dengan menentukan parameter paksi, anda boleh menggunakan operasi sepanjang paksi tatasusunan yang ditentukan:
>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 计算每一列的和
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 计算每一行的和
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
解释:以第一行为例,0=0,1=1+0,3=2+1+0,6=3+2+1+06 Pengindeksan, penghirisan dan lelaran tatasusunan ndarray
Satu Dimensi Tatasusunan boleh diindeks, dihiris dan diulang sama seperti senarai dan jenis jujukan Python yang lain.
>>> a = np.arange(10)**3 >>> a array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]) >>> a[2] 8 >>> a[2:5] array([ 8, 27, 64]) >>> a[:6:2] = -1000 # 等价于 a[0:6:2] = -1000; 从0到6的位置, 每隔一个设置为-1000 >>> a array([-1000, 1, -1000, 27, -1000, 125, fan 216, 343, 512, 729]) >>> a[ : :-1] # 将a反转 array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
Tatasusunan berbilang dimensi boleh mempunyai satu indeks setiap paksi. Indeks ini diberikan sebagai tuple yang dipisahkan koma:
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])7 ndarray数组的堆叠、拆分
几个数组可以沿不同的轴堆叠在一起,例如:np.vstack()函数和np.hstack()函数
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])column_stack()函数将1D数组作为列堆叠到2D数组中。
>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])使用hsplit(),可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
同理,使用vsplit(),可以沿数组的垂直轴拆分数组,方法同上。
################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]Atas ialah kandungan terperinci Analisis contoh operasi biasa ndarray dalam Python Numpy. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Penyimpanan Objek Minio: Penyebaran berprestasi tinggi di bawah CentOS System Minio adalah prestasi tinggi, sistem penyimpanan objek yang diedarkan yang dibangunkan berdasarkan bahasa Go, serasi dengan Amazons3. Ia menyokong pelbagai bahasa pelanggan, termasuk Java, Python, JavaScript, dan GO. Artikel ini akan memperkenalkan pemasangan dan keserasian minio pada sistem CentOS. Keserasian versi CentOS Minio telah disahkan pada pelbagai versi CentOS, termasuk tetapi tidak terhad kepada: CentOS7.9: Menyediakan panduan pemasangan lengkap yang meliputi konfigurasi kluster, penyediaan persekitaran, tetapan fail konfigurasi, pembahagian cakera, dan mini
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
