
 Peranti teknologi
AI
Kelajuan latihan meningkat sebanyak 17%. Rangka kerja penyelidikan pembelajaran tetulang sumber terbuka paradigma keempat menyokong latihan tunggal dan berbilang ejen.
Peranti teknologi
AI
Kelajuan latihan meningkat sebanyak 17%. Rangka kerja penyelidikan pembelajaran tetulang sumber terbuka paradigma keempat menyokong latihan tunggal dan berbilang ejen.
Kelajuan latihan meningkat sebanyak 17%. Rangka kerja penyelidikan pembelajaran tetulang sumber terbuka paradigma keempat menyokong latihan tunggal dan berbilang ejen.

OpenRL ialah rangka kerja penyelidikan pembelajaran pengukuhan berasaskan PyTorch yang dibangunkan oleh pasukan pembelajaran pengukuhan Paradigma Keempat Ia menyokong latihan ejen tunggal, berbilang ejen, bahasa semula jadi dan tugas lain. OpenRL dibangunkan berdasarkan PyTorch, dengan matlamat untuk menyediakan komuniti penyelidikan pembelajaran pengukuhan dengan platform yang mudah digunakan, fleksibel, cekap dan boleh skala yang mampan. Pada masa ini, ciri yang disokong oleh OpenRL termasuk:
- Antara muka biasa yang mudah digunakan dan menyokong latihan ejen tunggal dan berbilang ejen
- Menyokong latihan pembelajaran pengukuhan untuk tugasan bahasa semula jadi (seperti tugas dialog)
- Menyokong pengimportan model dan data daripada Hugging Face
- Menyokong LSTM, GRU, Transformer dan model lain
- Sokong pelbagai pecutan latihan, seperti: latihan ketepatan campuran automatik, pengumpulan data rangkaian dasar separuh ketepatan, dsb.
- Model latihan yang ditakrifkan pengguna, model ganjaran, data latihan dan persekitaran yang disokong
- Sokong persekitaran gimnasium
- Sokongan ruang pemerhatian kamus
- Menyokong alat visualisasi latihan arus perdana seperti wandb dan tensorboardX
- Menyokong latihan bersiri dan selari dalam persekitaran, sambil memastikan latihan yang konsisten kesan dalam dua mod
- dokumentasi Cina dan Inggeris
- Sediakan ujian unit dan ujian liputan kod
- Patuhi Gaya Kod Hitam dan semak taip
Pada masa ini, OpenRL ialah sumber terbuka pada GitHub:
Alamat projek: https ://github.com/OpenRL-Lab/openrl
Pengalaman pertama dengan OpenRL
OpenRL pada masa ini boleh dipasang melalui pip:
<code>pip install openrl</code>
juga boleh dipasang melalui conda:
<code>conda install -c openrl openrl</code>
OpenRL menyediakan mudah dan mudah digunakan antara muka untuk pengguna peringkat permulaan pembelajaran pengukuhan Berikut ialah persekitaran CartPole yang dilatih menggunakan algoritma PPO:
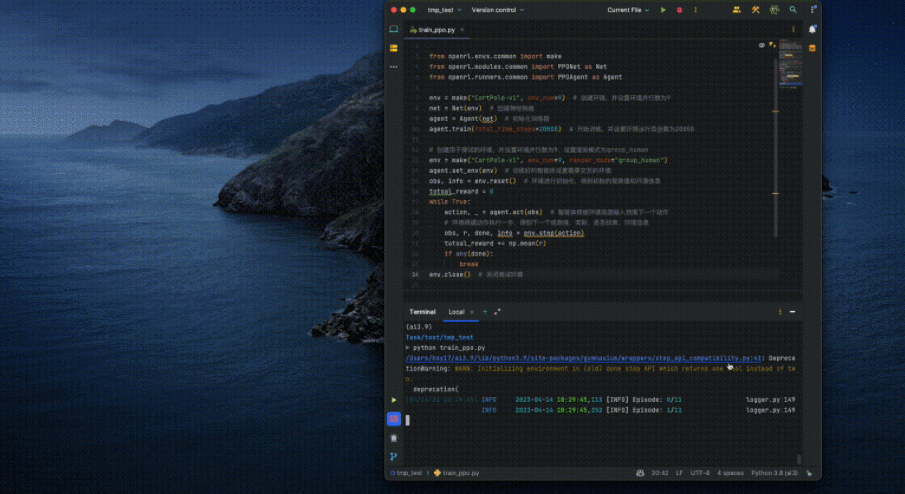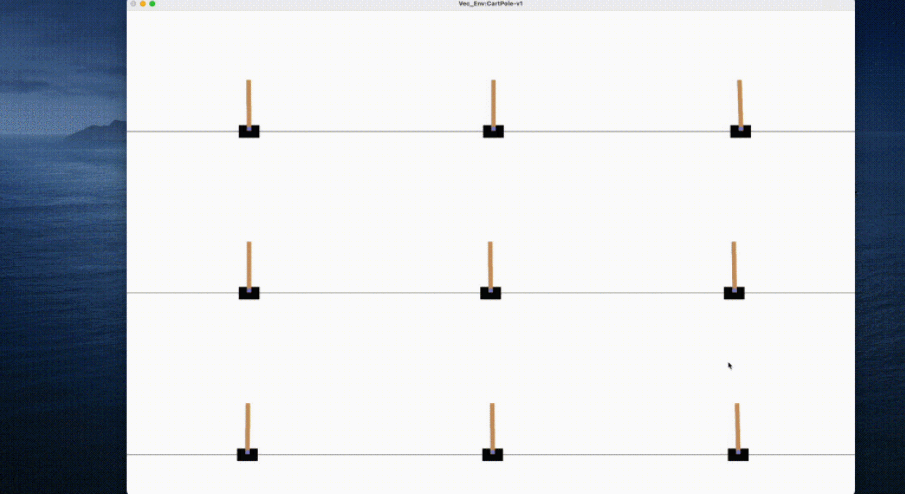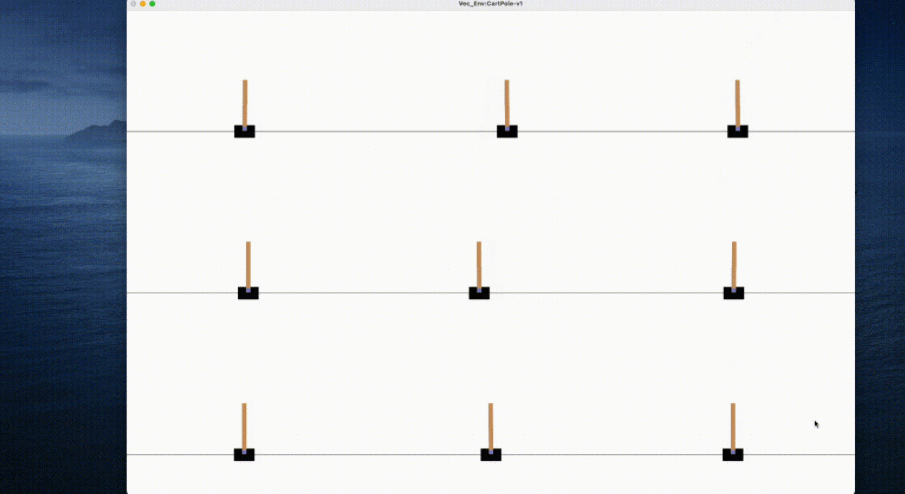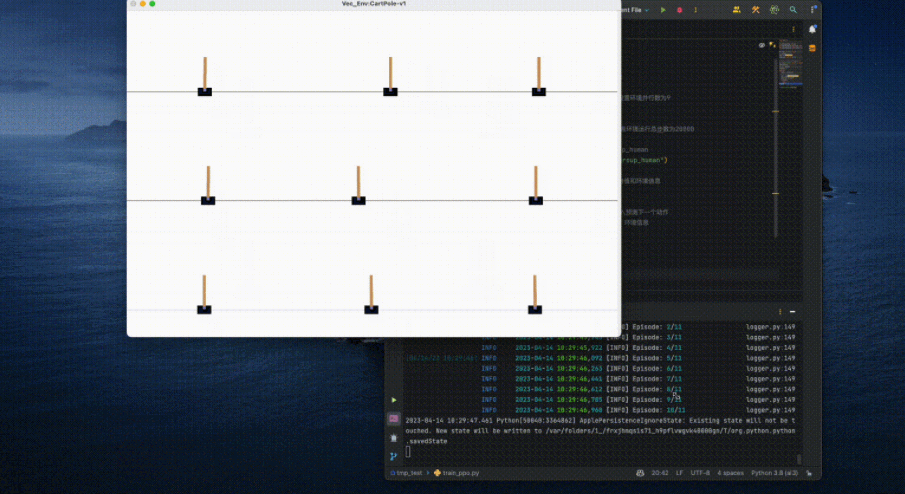
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>Menggunakan OpenRL untuk melatih ejen hanya memerlukan empat langkah mudah: <.>Buat persekitaran=> Inisialisasikan ejen=>
Laksanakan kod di atas pada komputer riba biasa, dan hanya mengambil masa beberapa saat untuk melengkapkan latihan ejen:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>
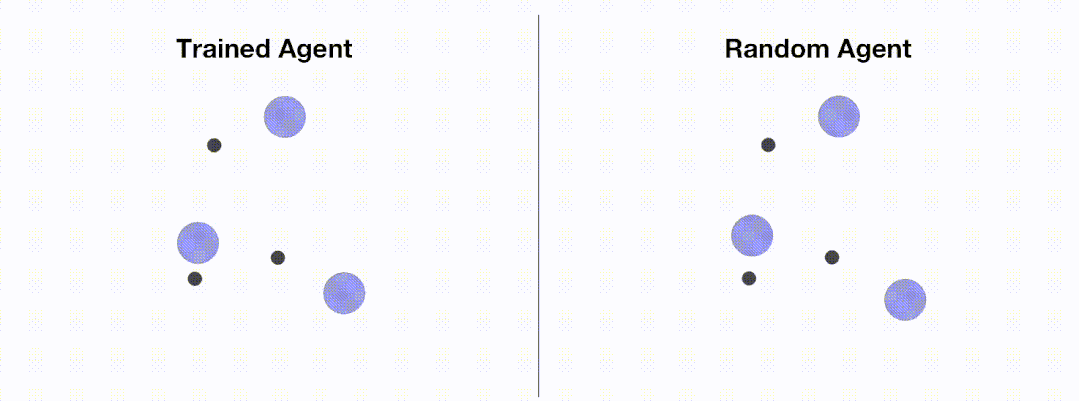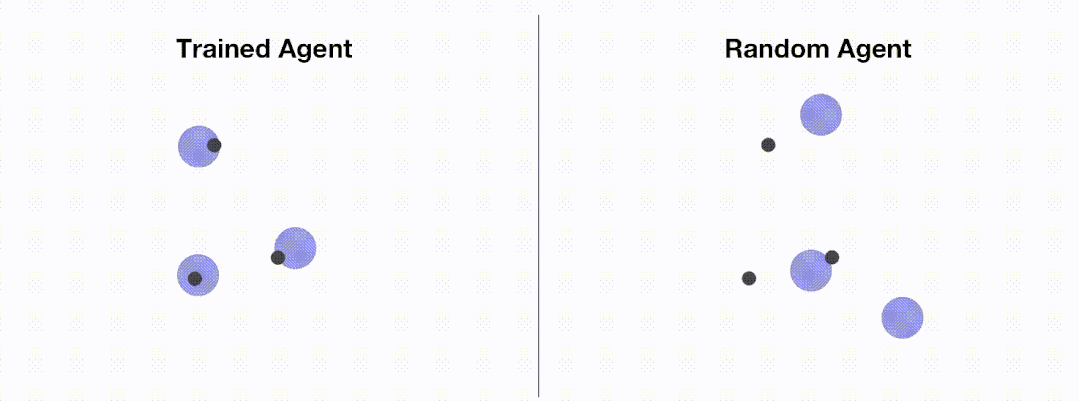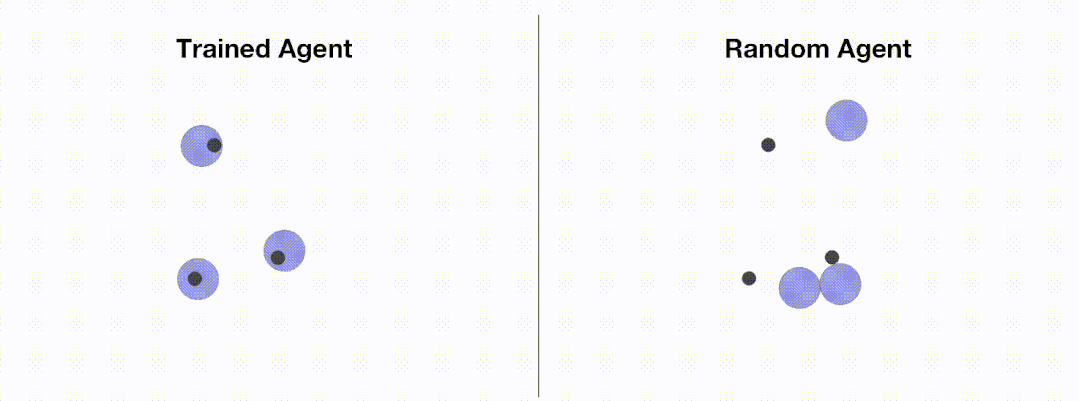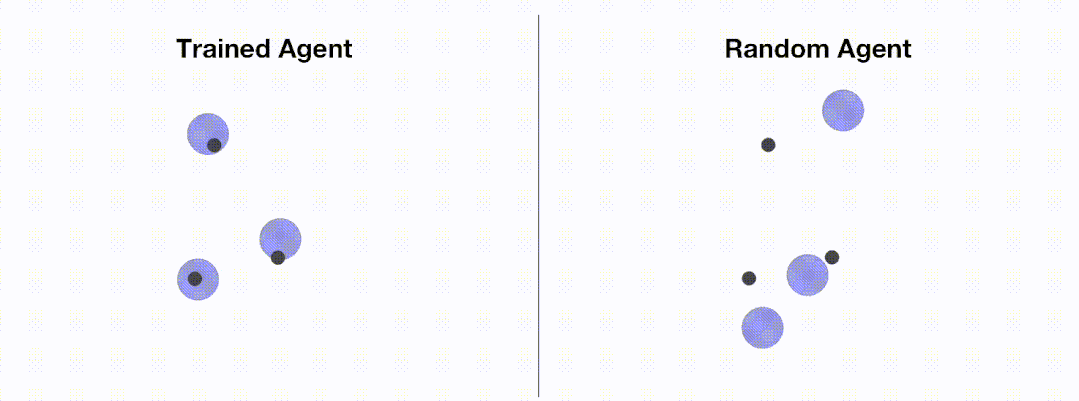
Apabila terdapat banyak parameter konfigurasi, OpenRL turut menyokong pengguna untuk menulis fail konfigurasi mereka sendiri untuk mengubah suai parameter latihan. Sebagai contoh, pengguna boleh mencipta fail konfigurasi berikut (mpe_ppo.yaml) dan mengubah suai parameter di dalamnya:
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程: OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化: 此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画: OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作: 执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):<code>python train_ppo.py --config mpe_ppo.yaml</code>
训练与测试可视化
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code><code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
智能体的保存和加载
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>
训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
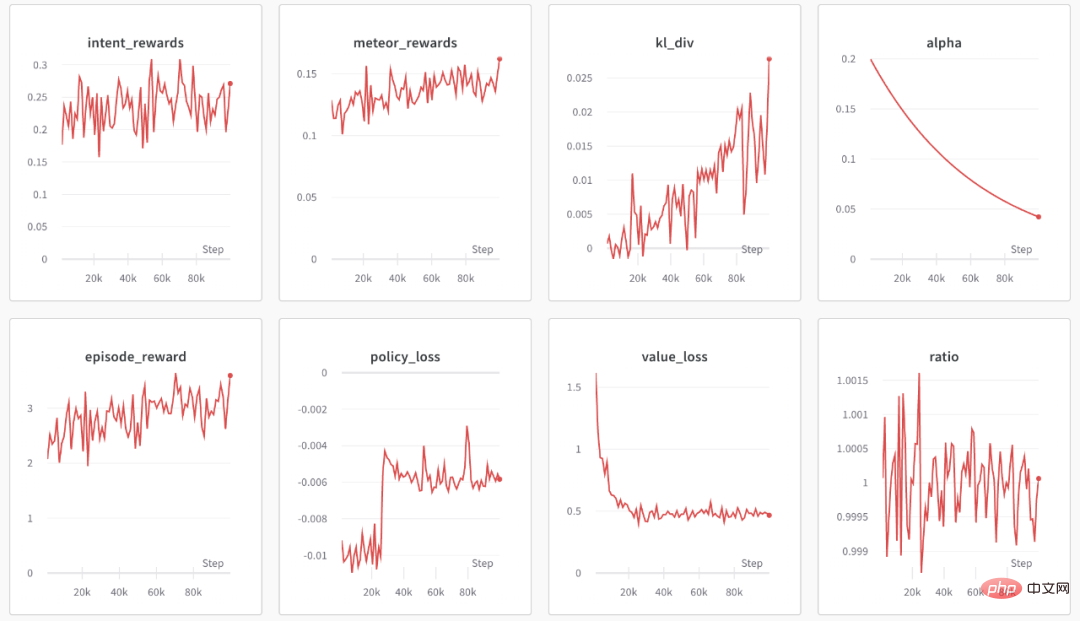
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
对比评测
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
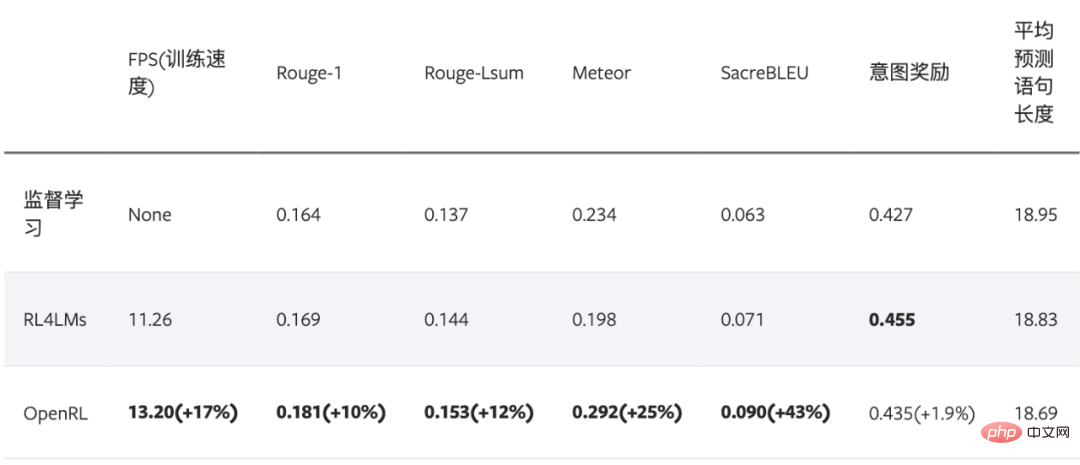
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
- OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
- OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- MAPPO: https://github.com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-enjin: https://github.com/opendilab/DI -enjin/
- Tianshou: https://github.com/thu-ml/tianshou
- RL4LMs: https://github. com/allenai/RL4LMs
Kerja masa hadapan
Pada masa ini, OpenRL masih dalam peringkat pembangunan dan pembinaan berterusan Pada masa hadapan, OpenRL akan lebih banyak lagi ciri:
- Menyokong latihan permainan kendiri ejen
- Tambah pembelajaran tetulang luar talian, pembelajaran model dan algoritma pembelajaran tetulang songsang
- Tambah lebih banyak persekitaran pembelajaran dan algoritma pengukuhan
- Sepadukan rangka kerja pecutan seperti Deepspeed
- Sokong berbilang- latihan teragih mesin
Pasukan OpenRL Lab
Rangka kerja OpenRL dibangunkan oleh pasukan OpenRL Lab, yang merupakan pasukan penyelidikan pembelajaran pengukuhan di bawah 4Paradigm. Paradigma Keempat telah lama komited kepada penyelidikan dan pembangunan dan aplikasi industri pembelajaran pengukuhan. Untuk menggalakkan integrasi industri, akademik dan penyelidikan dalam pembelajaran pengukuhan, 4Paradigm menubuhkan pasukan penyelidikan OpenRL Lab, dengan matlamat teknologi canggih sumber terbuka dan penerokaan sempadan kecerdasan buatan. Kurang daripada setahun selepas penubuhannya, pasukan OpenRL Lab telah menerbitkan tiga kertas kerja di AAMAS, menyertai pertandingan Google Football Game 11 vs 11 dan memenangi tempat ketiga. Ejen TiZero yang dicadangkan oleh pasukan adalah yang pertama melengkapkan latihan ejen permainan penuh Google Football dari awal melalui pembelajaran kurikulum, pembelajaran pengukuhan yang diedarkan, permainan kendiri dan teknologi lain:
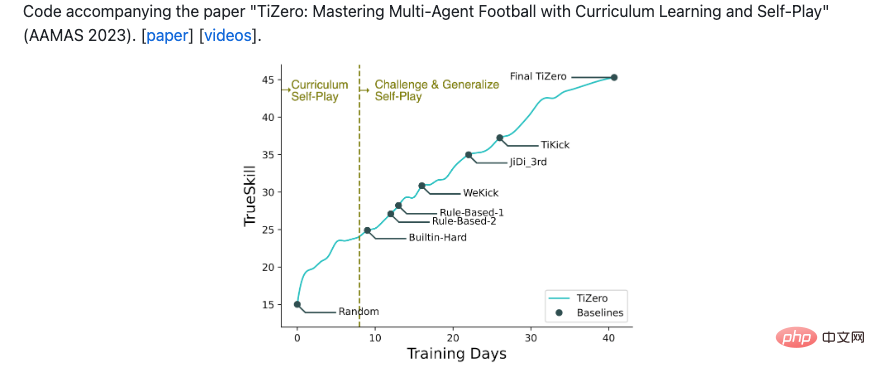
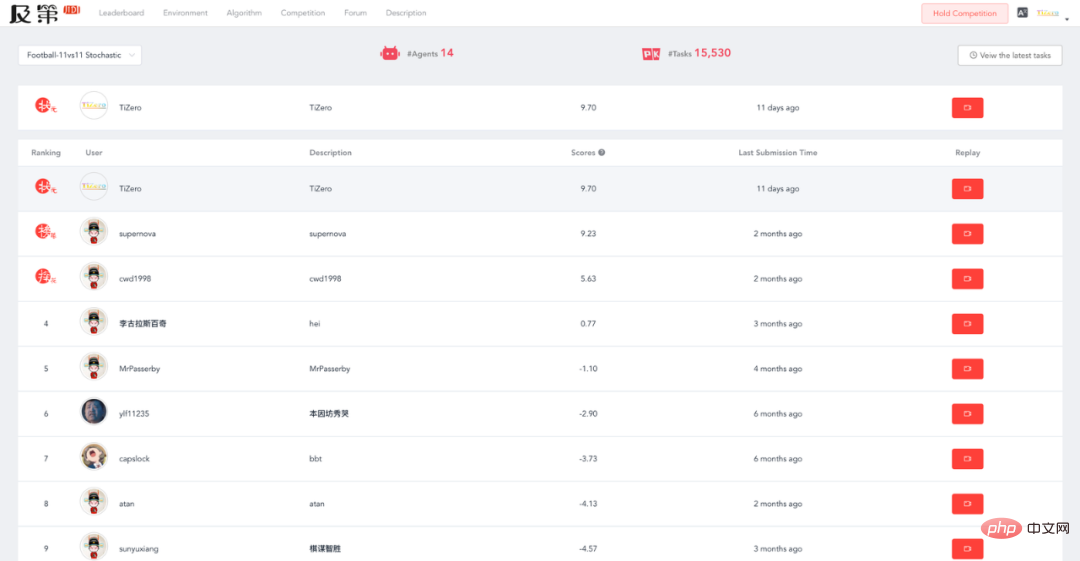
Sehingga 28 Oktober 2022, Tizero menduduki tempat pertama pada platform penilaian Jidi:
Atas ialah kandungan terperinci Kelajuan latihan meningkat sebanyak 17%. Rangka kerja penyelidikan pembelajaran tetulang sumber terbuka paradigma keempat menyokong latihan tunggal dan berbilang ejen.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Empat alat pengaturcaraan berbantukan AI yang disyorkan
Apr 22, 2024 pm 05:34 PM
Empat alat pengaturcaraan berbantukan AI yang disyorkan
Apr 22, 2024 pm 05:34 PM
Alat pengaturcaraan berbantukan AI ini telah menemui sejumlah besar alat pengaturcaraan berbantukan AI yang berguna dalam peringkat pembangunan AI yang pesat ini. Alat pengaturcaraan berbantukan AI boleh meningkatkan kecekapan pembangunan, meningkatkan kualiti kod dan mengurangkan kadar pepijat Ia adalah pembantu penting dalam proses pembangunan perisian moden. Hari ini Dayao akan berkongsi dengan anda 4 alat pengaturcaraan berbantukan AI (dan semua menyokong bahasa C# saya harap ia akan membantu semua orang). https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot ialah pembantu pengekodan AI yang membantu anda menulis kod dengan lebih pantas dan dengan sedikit usaha, supaya anda boleh lebih memfokuskan pada penyelesaian masalah dan kerjasama. Git
 Pengaturcara AI manakah yang terbaik? Terokai potensi Devin, Tongyi Lingma dan ejen SWE
Apr 07, 2024 am 09:10 AM
Pengaturcara AI manakah yang terbaik? Terokai potensi Devin, Tongyi Lingma dan ejen SWE
Apr 07, 2024 am 09:10 AM
Pada 3 Mac 2022, kurang daripada sebulan selepas kelahiran pengaturcara AI pertama di dunia, Devin, pasukan NLP Universiti Princeton membangunkan pengaturcara AI sumber terbuka ejen SWE. Ia memanfaatkan model GPT-4 untuk menyelesaikan isu secara automatik dalam repositori GitHub. Prestasi ejen SWE pada set ujian bangku SWE adalah serupa dengan Devin, mengambil purata 93 saat dan menyelesaikan 12.29% masalah. Dengan berinteraksi dengan terminal khusus, ejen SWE boleh membuka dan mencari kandungan fail, menggunakan semakan sintaks automatik, mengedit baris tertentu dan menulis serta melaksanakan ujian. (Nota: Kandungan di atas adalah sedikit pelarasan bagi kandungan asal, tetapi maklumat utama dalam teks asal dikekalkan dan tidak melebihi had perkataan yang ditentukan.) SWE-A
 Ringkasan lima perpustakaan bahasa Go yang paling popular: alat yang mesti ada untuk pembangunan
Feb 22, 2024 pm 02:33 PM
Ringkasan lima perpustakaan bahasa Go yang paling popular: alat yang mesti ada untuk pembangunan
Feb 22, 2024 pm 02:33 PM
Ringkasan lima pustaka bahasa Go yang paling popular: alatan penting untuk pembangunan, memerlukan contoh kod khusus Sejak kelahirannya, bahasa Go telah mendapat perhatian dan aplikasi yang meluas. Sebagai bahasa pengaturcaraan yang cekap dan ringkas, pembangunan pesat Go tidak dapat dipisahkan daripada sokongan perpustakaan sumber terbuka yang kaya. Artikel ini akan memperkenalkan lima perpustakaan bahasa Go yang paling popular. Perpustakaan ini memainkan peranan penting dalam pembangunan Go dan menyediakan pembangun dengan fungsi yang berkuasa dan pengalaman pembangunan yang mudah. Pada masa yang sama, untuk lebih memahami kegunaan dan fungsi perpustakaan ini, kami akan menerangkannya dengan contoh kod khusus.
 Ketahui cara membangunkan aplikasi mudah alih menggunakan bahasa Go
Mar 28, 2024 pm 10:00 PM
Ketahui cara membangunkan aplikasi mudah alih menggunakan bahasa Go
Mar 28, 2024 pm 10:00 PM
Tutorial aplikasi mudah alih pembangunan bahasa Go Memandangkan pasaran aplikasi mudah alih terus berkembang pesat, semakin ramai pembangun mula meneroka cara menggunakan bahasa Go untuk membangunkan aplikasi mudah alih. Sebagai bahasa pengaturcaraan yang mudah dan cekap, bahasa Go juga telah menunjukkan potensi yang kukuh dalam pembangunan aplikasi mudah alih. Artikel ini akan memperkenalkan secara terperinci cara menggunakan bahasa Go untuk membangunkan aplikasi mudah alih dan melampirkan contoh kod khusus untuk membantu pembaca bermula dengan cepat dan mula membangunkan aplikasi mudah alih mereka sendiri. 1. Persediaan Sebelum memulakan, kita perlu menyediakan persekitaran dan alatan pembangunan. kepala
 Pengedaran Linux manakah yang terbaik untuk pembangunan Android?
Mar 14, 2024 pm 12:30 PM
Pengedaran Linux manakah yang terbaik untuk pembangunan Android?
Mar 14, 2024 pm 12:30 PM
Pembangunan Android ialah kerja yang sibuk dan menarik, dan amat penting untuk memilih pengedaran Linux yang sesuai untuk pembangunan. Di antara banyak pengedaran Linux, yang manakah paling sesuai untuk pembangunan Android? Artikel ini akan meneroka isu ini dari beberapa aspek dan memberikan contoh kod khusus. Mula-mula, mari kita lihat beberapa pengedaran Linux yang popular pada masa ini: Ubuntu, Fedora, Debian, CentOS, dll. Mereka semua mempunyai kelebihan dan ciri tersendiri.
 Memahami VSCode: Untuk apa alat ini digunakan?
Mar 25, 2024 pm 03:06 PM
Memahami VSCode: Untuk apa alat ini digunakan?
Mar 25, 2024 pm 03:06 PM
"Memahami VSCode: Untuk apa alat ini digunakan?" 》Sebagai pengaturcara, sama ada anda seorang pemula atau pembangun berpengalaman, anda tidak boleh melakukannya tanpa menggunakan alat penyuntingan kod. Di antara banyak alat penyuntingan, Kod Visual Studio (pendek kata VSCode) sangat popular di kalangan pembangun sebagai penyunting kod sumber terbuka, ringan dan berkuasa. Jadi, untuk apa sebenarnya VSCode digunakan? Artikel ini akan menyelidiki fungsi dan kegunaan VSCode dan menyediakan contoh kod khusus untuk membantu pembaca
 Meneroka teknologi bahagian hadapan bahasa Go: visi baharu untuk pembangunan bahagian hadapan
Mar 28, 2024 pm 01:06 PM
Meneroka teknologi bahagian hadapan bahasa Go: visi baharu untuk pembangunan bahagian hadapan
Mar 28, 2024 pm 01:06 PM
Sebagai bahasa pengaturcaraan yang pantas dan cekap, bahasa Go popular secara meluas dalam bidang pembangunan bahagian belakang. Walau bagaimanapun, beberapa orang mengaitkan bahasa Go dengan pembangunan bahagian hadapan. Malah, menggunakan bahasa Go untuk pembangunan bahagian hadapan bukan sahaja boleh meningkatkan kecekapan, tetapi juga membawa ufuk baharu kepada pembangun. Artikel ini akan meneroka kemungkinan menggunakan bahasa Go untuk pembangunan bahagian hadapan dan memberikan contoh kod khusus untuk membantu pembaca memahami dengan lebih baik bahagian ini. Dalam pembangunan front-end tradisional, JavaScript, HTML dan CSS sering digunakan untuk membina antara muka pengguna
 Adakah PHP front-end atau back-end dalam pembangunan web?
Mar 24, 2024 pm 02:18 PM
Adakah PHP front-end atau back-end dalam pembangunan web?
Mar 24, 2024 pm 02:18 PM
PHP tergolong dalam bahagian belakang dalam pembangunan web. PHP ialah bahasa skrip sebelah pelayan, terutamanya digunakan untuk memproses logik sebelah pelayan dan menjana kandungan web dinamik. Berbanding dengan teknologi bahagian hadapan, PHP lebih banyak digunakan untuk operasi bahagian belakang seperti berinteraksi dengan pangkalan data, memproses permintaan pengguna dan menjana kandungan halaman. Seterusnya, contoh kod khusus akan digunakan untuk menggambarkan aplikasi PHP dalam pembangunan back-end. Mula-mula, mari kita lihat contoh kod PHP mudah untuk menyambung ke pangkalan data dan menanyakan data:
