

Saya tidak dapat mengikuti volum model besar tanpa tidur...
Tidak, Microsoft Asia The institut baru sahaja mengeluarkan model bahasa besar multimodal (MLLM) - KOSMOS-1.

Alamat kertas: https://arxiv.org/pdf/2302.14045.pdf
Tajuk tesis Language Is Not All You Need berasal daripada pepatah terkenal.
Terdapat ayat dalam artikel, "Keterbatasan bahasa saya adalah batasan dunia saya. - ahli falsafah Austria Ludwig Wittgenstein"

Kemudian soalan datang...
Bolehkah anda memikirkannya jika anda memegang gambar itu dan bertanya kepada KOSMOS-1 "Adakah ia itik atau arnab?" Meme dengan sejarah lebih daripada 100 tahun ini tidak dapat menghentikan Google AI.
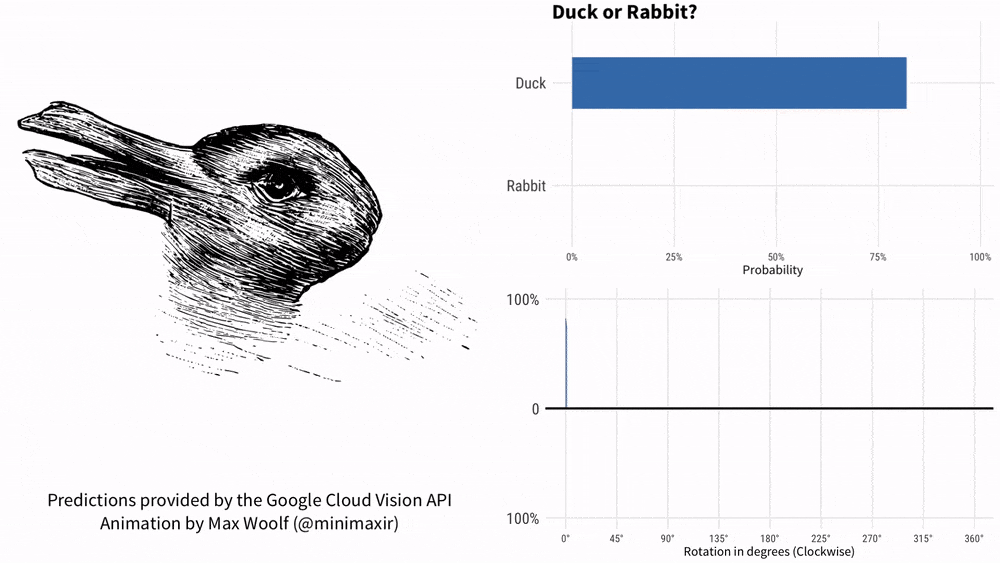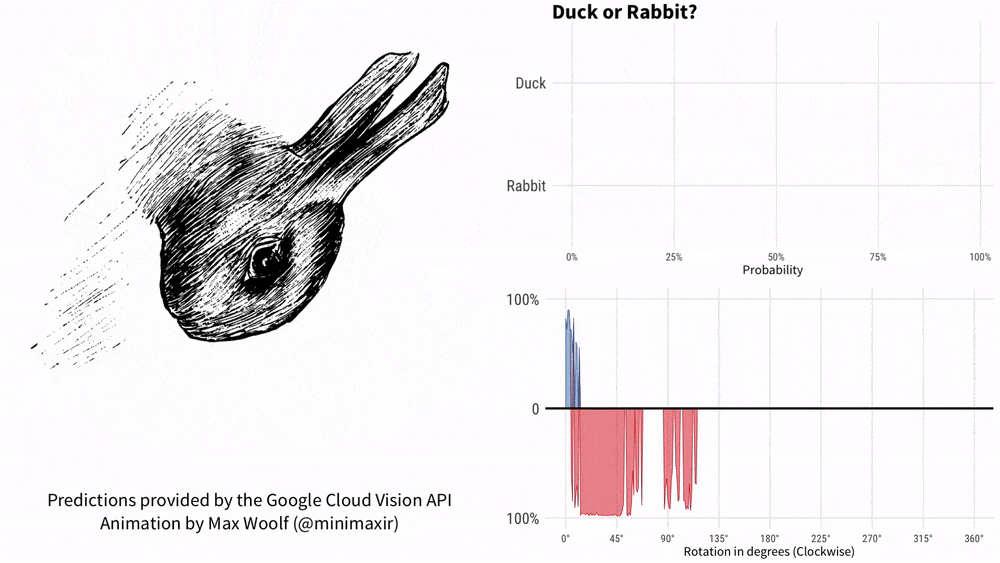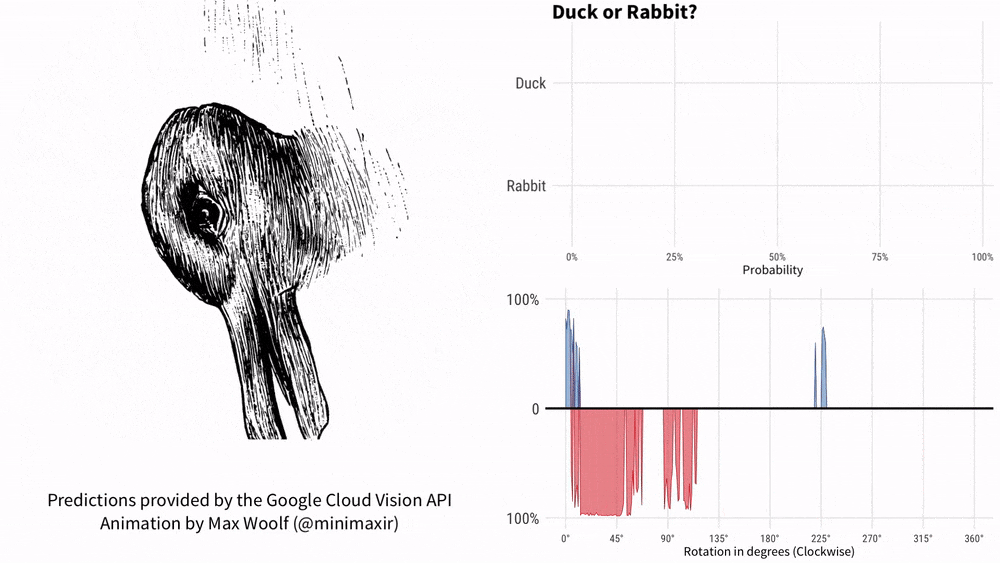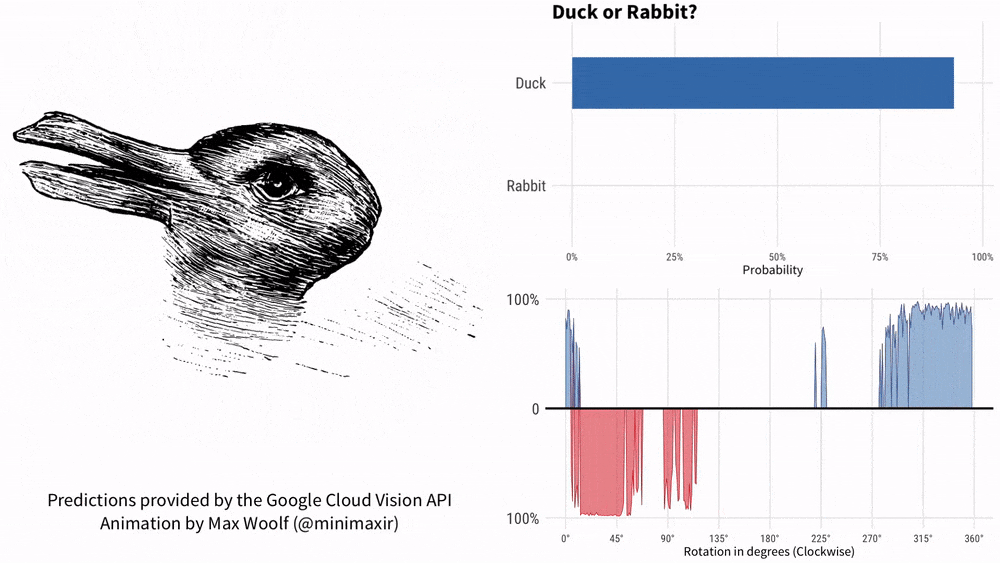
Pada tahun 1899, ahli psikologi Amerika Joseph Jastrow mula-mula menggunakan "Carta Itik dan Arnab" untuk Ia menunjukkan bahawa persepsi bukan sahaja apa yang dilihat orang, tetapi juga aktiviti mental.
Kini, KOSMOS-1 boleh menggabungkan persepsi dan model bahasa ini.
-Apa yang ada dalam gambar?
-Seperti itik.
- Jika bukan itik, apakah itu?
- Kelihatan lebih seperti arnab.
-Kenapa?
-Ia mempunyai telinga arnab.
Jika anda bertanya soalan ini, KOSMOS-1 benar-benar sedikit seperti versi ChatGPT Microsoft.

Bukan itu sahaja, Kosmos-1 juga boleh memahami imej, teks, imej dengan teks Imej, OCR, kapsyen imej, QA visual.
Ujian IQ pun tiada masalah.
Kosmos berasal daripada perkataan Greek cosmos, yang bermaksud "alam semesta".
Menurut kertas itu, model Kosmos-1 terbaharu ialah model bahasa berskala besar berbilang modal.
Tulang belakang ialah model bahasa kausal berdasarkan Transformer Selain teks, modaliti lain seperti penglihatan dan audio boleh dibenamkan dalam model.
Penyahkod Transformer berfungsi sebagai antara muka universal untuk input berbilang modal, jadi ia boleh melihat modaliti umum, melaksanakan pembelajaran konteks dan mengikut arahan.
Kosmos-1 mencapai prestasi yang mengagumkan tanpa penalaan halus pada bahasa dan tugasan pelbagai mod, termasuk pengecaman imej dengan arahan teks, jawapan soalan visual dan dialog pelbagai mod .
Berikut ialah beberapa contoh gaya yang dijana oleh Kosmos-1.
Penjelasan gambar, soal jawab bergambar, jawapan soalan halaman web, formula nombor mudah dan pengecaman nombor.

Jadi, pada set data manakah Kosmos-1 dilatih terlebih dahulu?
Pangkalan data yang digunakan untuk latihan, termasuk korpus teks, pasangan sari kata imej, set data silang imej dan teks.
Korpus teks diambil daripada The Pile dan Common Crawl (CC); -Sumber pasangan sari kata ialah Bahasa Inggeris LAION-2B, LAION-400M, COYO-700M dan Kapsyen Konseptual; Gambar merangkak.
Sekarang pangkalan data tersedia, langkah seterusnya ialah pralatih model.
Komponen MLLM mempunyai 24 lapisan, 2,048 dimensi tersembunyi, 8,192 FFN dan 32 kepala perhatian, menghasilkan kira-kira 1.3B parameter.
Untuk memastikan kestabilan pengoptimuman, permulaan Magneto digunakan untuk menumpu lebih cepat, perwakilan imej diperoleh daripada yang telah dilatih dengan 1024 dimensi ciri Diperolehi daripada model CLIP ViT-L/14. Semasa proses latihan, imej dipraproses kepada resolusi 224×224, dan parameter model CLIP dibekukan kecuali untuk lapisan terakhir.
Jumlah bilangan parameter KOSMOS-1 adalah lebih kurang 1.6 bilion.
Untuk menjajarkan KOSMOS-1 dengan arahan dengan lebih baik, pelarasan arahan bahasa sahaja telah dibuat [LHV+23, HSLS22], iaitu Teruskan melatih model dengan data arahan, yang merupakan satu-satunya data bahasa, bercampur dengan korpus latihan.
Proses penalaan dijalankan mengikut kaedah pemodelan bahasa, dan set data arahan yang dipilih ialah Arahan Tidak Semulajadi [HSLS22] dan FLANv2 [LHV+23] .
Hasilnya menunjukkan bahawa peningkatan dalam keupayaan mengikut arahan boleh dipindahkan merentas mod.
Ringkasnya, MLLM boleh mendapat manfaat daripada pemindahan silang modal, memindahkan pengetahuan daripada bahasa kepada pelbagai mod dan sebaliknya
5 kategori utama dan 10 tugasan, semuanya dikuasaiAnda akan tahu sama ada model mudah digunakan atau tidak, cuma keluarkan dan main-main.
Pasukan penyelidik menjalankan eksperimen dari pelbagai sudut untuk menilai prestasi KOSMOS-1, termasuk sepuluh tugasan dalam 5 kategori:
1 Tugas bahasa (pemahaman bahasa, penjanaan bahasa, klasifikasi teks tanpa OCR)
2 Pemindahan pelbagai mod (biasa Penaakulan rasa)
3 Penaakulan Bukan Verbal (Ujian IQ)
4 Persepsi - Tugas Bahasa (huraian imej, Soal Jawab visual, Soal Jawab web)
5 Tugas penglihatan (klasifikasi imej sifar tangkapan, klasifikasi imej sifar tangkapan dengan penerangan)
Tiada OCR Klasifikasi Teks
Ini ialah tugas pemahaman teks dan imej yang tidak bergantung pada pengecaman aksara optik (OCR).
Ketepatan KOSMOS-1 pada HatefulMemes dan pada set ujian Rendered SST-2 adalah lebih tinggi daripada model lain.
Walaupun Flamingo secara eksplisit menyediakan teks OCR ke dalam gesaan, KOSMOS-1 tidak mengakses sebarang alat atau sumber luaran, yang menunjukkan bahawa KOSMOS-1 membaca dan memahami rendering Keupayaan wujud teks dalam imej.
Ujian IQ
Ujian Kepintaran Raven ialah penilaian Salah satu ujian bukan lisan yang paling biasa digunakan.
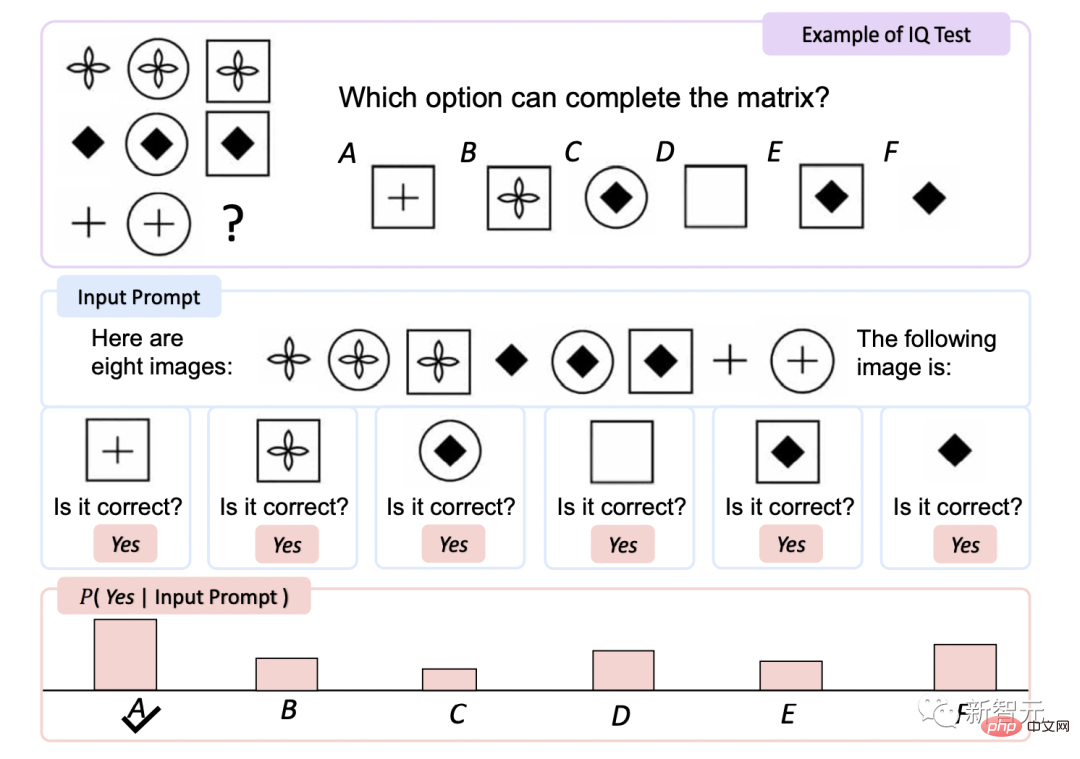
KOSMOS-1 meningkatkan ketepatan sebanyak 5.3% berbanding pemilihan rawak tanpa penalaan halus , ia bertambah baik sebanyak 9.3% selepas penalaan halus, menunjukkan keupayaannya untuk melihat corak konsep abstrak dalam persekitaran bukan linguistik.
Ini adalah kali pertama model telah dapat melengkapkan ujian Raven sifar pukulan, membuktikan potensi MLLM untuk sifar pukulan bukan lisan penaakulan dengan menggabungkan persepsi dengan model bahasa.

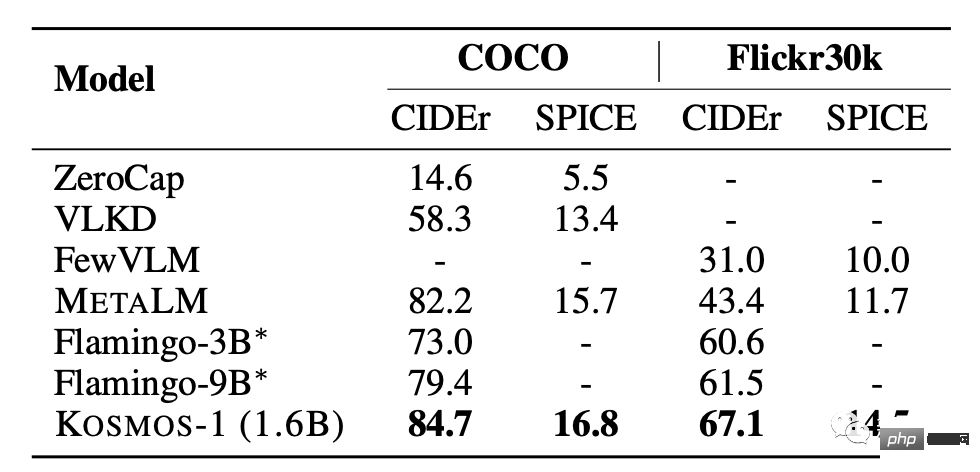
Penerangan imej
KOSMOS-1 mempunyai prestasi sifar sampel yang sangat baik dalam kedua-dua ujian COCO dan Flickr30k Berbanding dengan model lain, ia mendapat markah yang lebih tinggi tetapi menggunakan bilangan parameter yang lebih kecil.
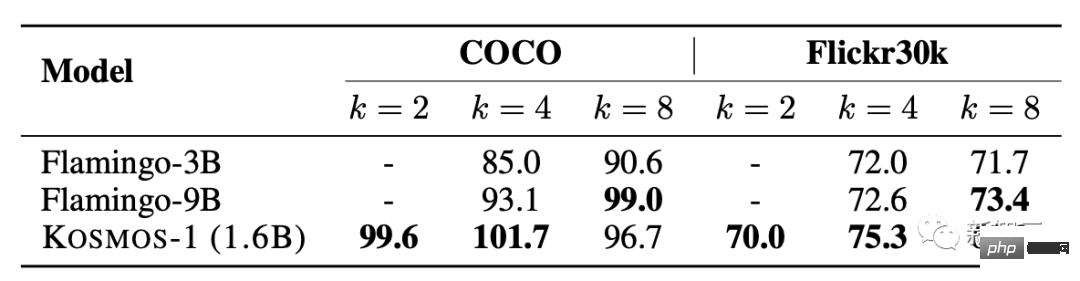
Dalam ujian prestasi beberapa sampel, markah meningkat apabila nilai k meningkat .
Klasifikasi imej tangkapan sifar
Memandangkan imej input, sambungkan imej dengan gesaan "The photo of the". Kemudian, suapkan model untuk mendapatkan nama kelas imej.

Dengan menilai model pada ImageNet [DDS+09], dengan kekangan dan Di bawah tanpa kekangan Dalam keadaan tertentu, kesan pengelasan imej KOSMOS-1 adalah jauh lebih baik daripada GIT [WYH+22], menunjukkan kebolehannya yang berkuasa untuk menyelesaikan tugasan visual.

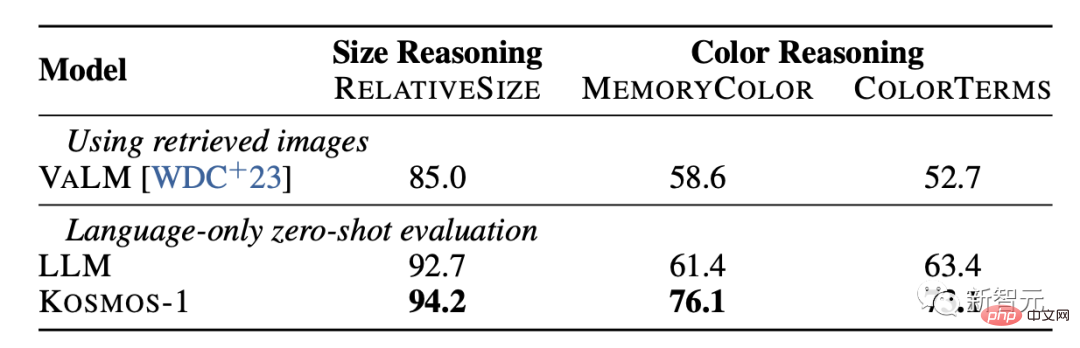
Penaakulan akal
Tugas penaakulan akal visual memerlukan model memahami sifat objek harian di dunia nyata, seperti warna, saiz dan bentuk Tugasan ini mencabar kerana ia mungkin memerlukan lebih banyak maklumat tentang objek di dunia nyata daripada dalam teks Maklumat tentang sifat objek.
Keputusan menunjukkan bahawa keupayaan penaakulan KOSMOS-1 adalah jauh lebih baik daripada model LLM dalam kedua-dua saiz dan warna. Ini terutamanya kerana KOSMOS-1 mempunyai keupayaan pemindahan pelbagai mod, yang membolehkannya menggunakan pengetahuan visual pada tugas bahasa tanpa perlu bergantung pada pengetahuan teks dan petunjuk untuk penaakulan seperti LLM.
Untuk Microsoft Kosmos-1, netizen memuji Dao, dalam tempoh 5 tahun akan datang, saya dapat melihat robot canggih melayari web dan bekerja berdasarkan input teks manusia hanya melalui cara visual. Masa yang begitu menarik.

Atas ialah kandungan terperinci Malah meme berusia satu abad itu jelas! 'Universe' multi-modal Microsoft mengendalikan ujian IQ dengan hanya 1.6 bilion parameter. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
 Cara menggunakan kod js
Cara menggunakan kod js
 Alat muat turun dan pemasangan Linux biasa
Alat muat turun dan pemasangan Linux biasa
 Trend harga Eth hari ini
Trend harga Eth hari ini
 Cara menonton rekod main balik siaran langsung di Douyin
Cara menonton rekod main balik siaran langsung di Douyin
 Bagaimana untuk menggunakan pernyataan sisip dalam mysql
Bagaimana untuk menggunakan pernyataan sisip dalam mysql
 Penggunaan kata kunci Jenis dalam Go
Penggunaan kata kunci Jenis dalam Go
 Apakah tujuh prinsip spesifikasi kod PHP?
Apakah tujuh prinsip spesifikasi kod PHP?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



