
 Peranti teknologi
AI
Menggunakan imej untuk menyelaraskan semua modaliti, model asas AI berbilang deria sumber terbuka Meta untuk mencapai penyatuan yang hebat
Peranti teknologi
AI
Menggunakan imej untuk menyelaraskan semua modaliti, model asas AI berbilang deria sumber terbuka Meta untuk mencapai penyatuan yang hebat
Menggunakan imej untuk menyelaraskan semua modaliti, model asas AI berbilang deria sumber terbuka Meta untuk mencapai penyatuan yang hebat

Dalam pancaindera manusia, gambar boleh menggabungkan banyak pengalaman sebagai contoh, gambar pantai boleh mengingatkan kita tentang bunyi ombak, tekstur pasir, angin bertiup ke muka kita, malah boleh memberi inspirasi. Inspirasi untuk sebuah puisi. Sifat imej "mengikat" ini menyediakan sumber penyeliaan yang besar untuk mempelajari ciri visual dengan menjajarkannya dengan sebarang pengalaman deria yang berkaitan dengannya.
Sebaik-baiknya, ciri visual harus dipelajari dengan menjajarkan semua deria untuk satu ruang benam bersama. Walau bagaimanapun, ini memerlukan mendapatkan data berpasangan untuk semua jenis deria dan gabungan daripada set imej yang sama, yang jelas tidak boleh dilaksanakan.
Baru-baru ini, banyak kaedah mempelajari ciri imej yang sejajar dengan teks, audio, dsb. Kaedah ini menggunakan satu pasangan modaliti atau paling banyak beberapa modaliti visual. Pembenaman terakhir adalah terhad kepada pasangan modal yang digunakan untuk latihan. Oleh itu, pembenaman video-audio tidak boleh digunakan secara langsung untuk tugasan teks imej dan sebaliknya. Halangan utama dalam mempelajari benam bersama yang benar ialah kekurangan sejumlah besar data multimodal di mana semua modaliti digabungkan bersama.
Hari ini, Meta AI mencadangkan ImageBind, yang mempelajari satu ruang perwakilan dikongsi dengan memanfaatkan berbilang jenis data gandingan imej. Penyelidikan ini tidak memerlukan set data di mana semua modaliti muncul serentak antara satu sama lain, Sebaliknya, mengambil kesempatan daripada sifat mengikat imej asalkan pembenaman setiap modaliti diselaraskan dengan pembenaman imej , semua modaliti akan dicapai dengan cepat . Meta AI juga mengumumkan kod yang sepadan.

- Alamat kertas: https://dl.fbaipublicfiles. com/imagebind/imagebind_final.pdf
- Alamat GitHub: https://github.com/facebookresearch/ImageBind
Khususnya, ImageBind memanfaatkan data padanan skala web (imej, teks) dan memasangkannya dengan data berpasangan sedia ada (video, audio, imej, kedalaman) digabungkan untuk mempelajari satu ruang benam bersama. Melakukannya membolehkan ImageBind menyelaraskan pembenaman teks secara tersirat dengan modaliti lain (seperti audio, kedalaman, dll.), membolehkan pengecaman sifar tangkapan pada modaliti ini tanpa gandingan semantik atau teks yang eksplisit.
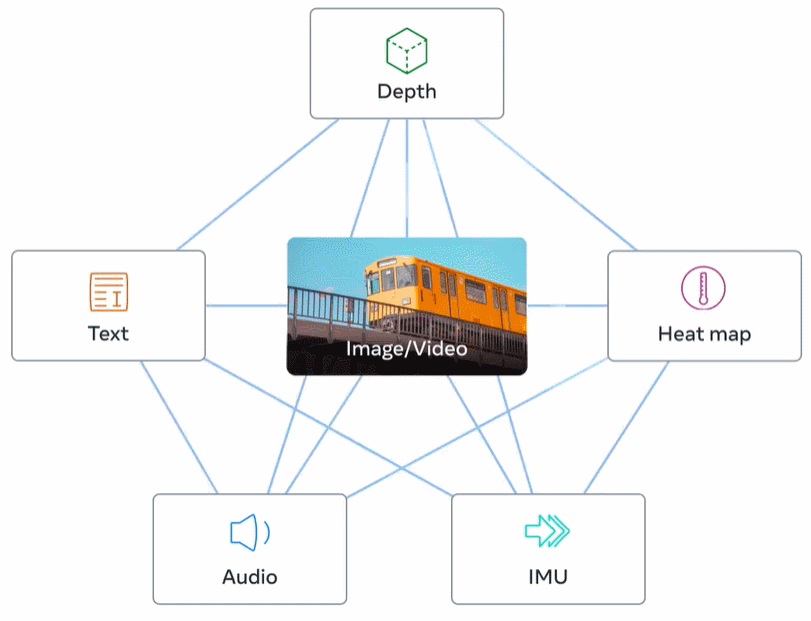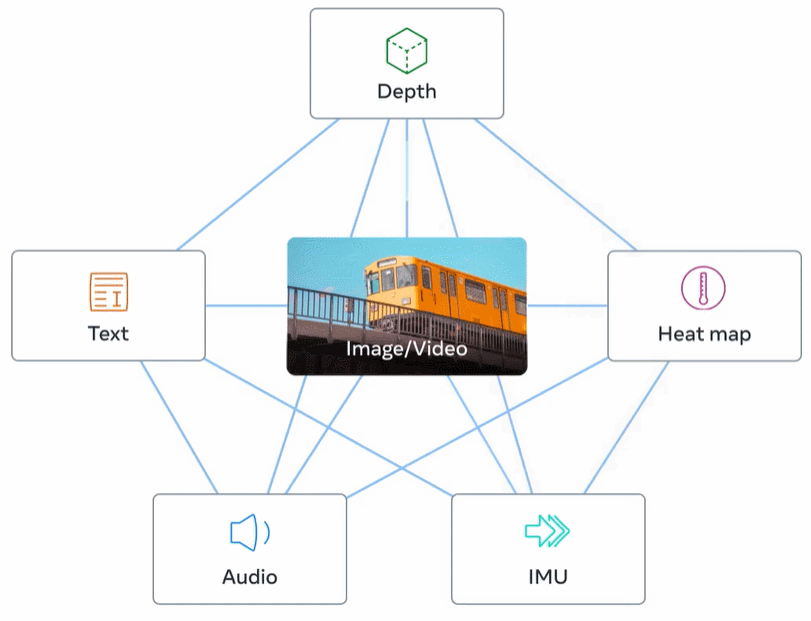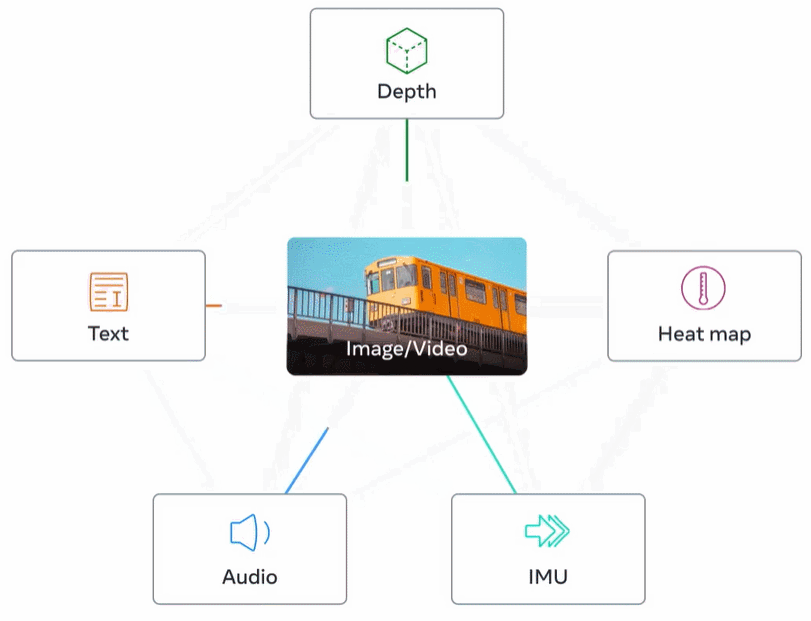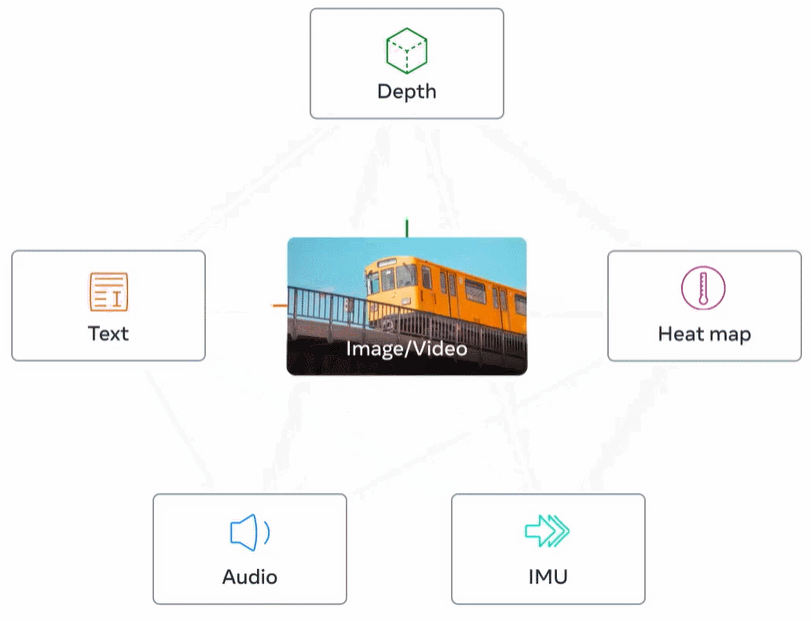
Rajah 2 di bawah ialah gambaran keseluruhan ImageBind.

Pada masa yang sama, penyelidik berkata bahawa ImageBind boleh dimulakan menggunakan model bahasa visual berskala besar (seperti CLIP) untuk memanfaatkan imej yang kaya bagi model ini dan perwakilan teks. Oleh itu, ImageBind memerlukan latihan yang sangat sedikit dan boleh digunakan untuk pelbagai modaliti dan tugasan yang berbeza.
ImageBind ialah sebahagian daripada komitmen Meta untuk mencipta sistem AI berbilang modal yang belajar daripada semua jenis data yang berkaitan. Apabila bilangan modaliti meningkat, ImageBind membuka pintu air kepada penyelidik untuk cuba membangunkan sistem holistik baharu, seperti menggabungkan penderia 3D dan IMU untuk mereka bentuk atau mengalami dunia maya yang mengasyikkan. Ia juga menyediakan cara yang kaya untuk meneroka memori anda dengan menggunakan gabungan teks, video dan imej untuk mencari imej, video, fail audio atau maklumat teks.
Ikat kandungan dan imej untuk mempelajari satu ruang benam
Manusia mempunyai keupayaan untuk mempelajari konsep baharu dengan sampel yang sangat sedikit, seperti selepas membaca penerangan haiwan Anda boleh mengenali mereka dalam kehidupan sebenar; daripada foto model kereta yang tidak dikenali, anda boleh meramalkan bunyi yang mungkin dihasilkan oleh enjinnya. Ini sebahagiannya kerana satu imej boleh "menggabungkan" pengalaman deria keseluruhan bersama-sama. Walau bagaimanapun, dalam bidang kecerdasan buatan, walaupun bilangan modaliti telah meningkat, kekurangan data pelbagai deria akan mengehadkan pembelajaran multi-modal standard yang memerlukan data berpasangan.
Sebaik-baiknya, ruang benam bersama dengan jenis data yang berbeza membolehkan model mempelajari modaliti lain sambil mempelajari ciri visual. Sebelum ini, selalunya perlu untuk mengumpul semua gabungan data berpasangan yang mungkin untuk semua modaliti mempelajari ruang benam bersama.
ImageBind memintas kesukaran ini dengan memanfaatkan model bahasa visual berskala besar terbaharu ini memanjangkan keupayaan tangkapan sifar model bahasa visual berskala besar terkini kepada modaliti baharu yang berkaitan dengan imej. Gandingan semula jadi, seperti video-audio dan data kedalaman imej, untuk mempelajari ruang benam bersama. Untuk empat modaliti lain (audio, kedalaman, pengimejan terma dan bacaan IMU), para penyelidik menggunakan data seliaan sendiri yang dipasangkan secara semula jadi.
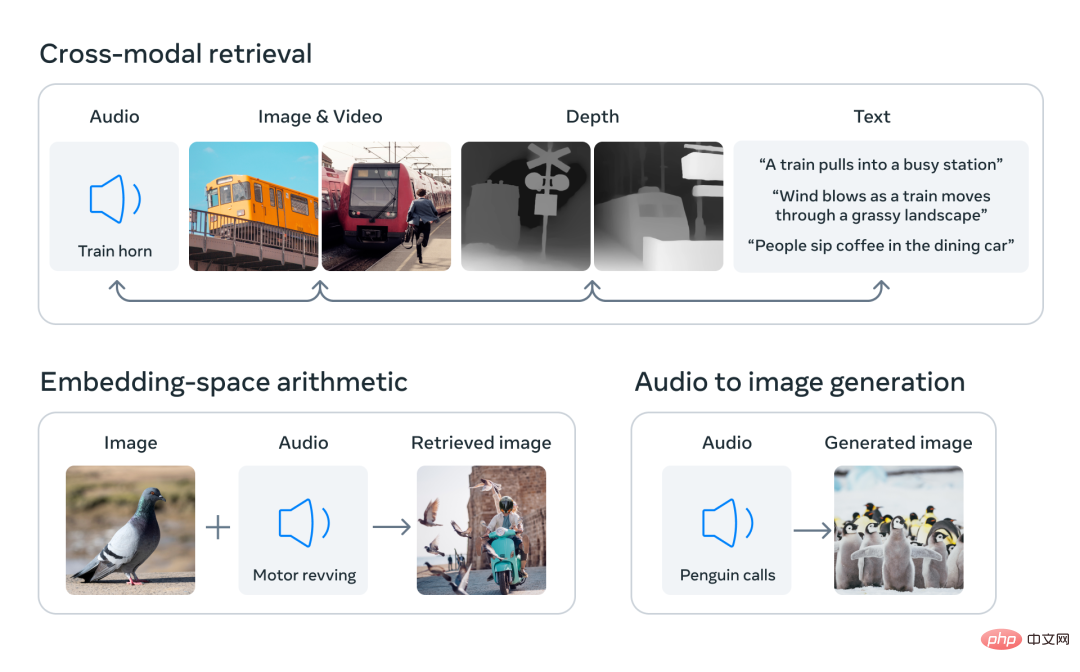
Dengan menyelaraskan benam enam modaliti ke dalam ruang bersama, ImageBind boleh merentas mod mendapatkan semula jenis kandungan yang berbeza yang tidak diperhatikan serentak, menambah pembenaman modaliti berbeza untuk menggabungkan semantiknya secara semula jadi, dan menggunakan pembenaman audio Meta AI dengan penyahkod DALLE-2 yang telah terlatih (direka bentuk Digunakan dengan pembenaman teks CLIP) untuk melaksanakan penjanaan audio-ke-imej.
Terdapat sejumlah besar imej yang muncul bersama-sama dengan teks di Internet, jadi latihan model teks imej telah dikaji secara meluas. ImageBind memanfaatkan sifat pengikatan imej yang boleh disambungkan kepada pelbagai modaliti, seperti menyambungkan teks ke imej menggunakan data rangkaian, atau menyambungkan gerakan ke video menggunakan data video yang ditangkap dalam kamera boleh pakai dengan penderia IMU.
Perwakilan visual yang dipelajari daripada data rangkaian berskala besar boleh digunakan sebagai sasaran untuk mempelajari ciri mod yang berbeza. Ini membolehkan ImageBind menjajarkan imej dengan mana-mana modaliti yang hadir pada masa yang sama, secara semula jadi menjajarkan modaliti tersebut antara satu sama lain. Modaliti seperti peta haba dan peta kedalaman yang mempunyai perkaitan kuat dengan imej lebih mudah untuk diselaraskan. Modaliti bukan visual seperti audio dan IMU (Unit Pengukuran Inersia) mempunyai korelasi yang lebih lemah Contohnya, bunyi tertentu seperti tangisan bayi boleh sepadan dengan pelbagai latar belakang visual.
ImageBind menunjukkan bahawa data gandingan imej adalah mencukupi untuk mengikat enam modaliti ini bersama-sama. Model ini boleh menerangkan kandungan dengan lebih lengkap, membenarkan modaliti yang berbeza untuk "bercakap" antara satu sama lain dan mencari hubungan antara mereka tanpa memerhatikannya secara serentak. Sebagai contoh, ImageBind boleh memautkan audio dan teks tanpa memerhatikannya bersama-sama. Ini membolehkan model lain "memahami" modaliti baharu tanpa memerlukan sebarang latihan intensif sumber.
Prestasi penskalaan hebat ImageBind membolehkan model ini menggantikan atau mempertingkatkan banyak model kecerdasan buatan, membolehkan mereka menggunakan modaliti lain. Contohnya, sementara Make-A-Scene boleh menjana imej dengan menggunakan gesaan teks, ImageBind boleh menaik tarafnya untuk menjana imej menggunakan audio, seperti ketawa atau bunyi hujan.
Prestasi unggul ImageBind
Analisis Meta menunjukkan bahawa tingkah laku penskalaan ImageBind bertambah baik dengan kekuatan pengekod imej. Dengan kata lain, keupayaan ImageBind untuk menyelaraskan skala modaliti dengan kuasa dan saiz model visual. Ini menunjukkan bahawa model visual yang lebih besar bermanfaat untuk tugas bukan visual, seperti klasifikasi audio, dan bahawa faedah latihan model sedemikian melangkaui tugas penglihatan komputer.
Dalam percubaan, Meta menggunakan pengekod audio dan kedalaman ImageBind dan membandingkannya dengan kerja sebelumnya pada pengambilan sifar tangkapan dan tugas pengelasan audio dan kedalaman.
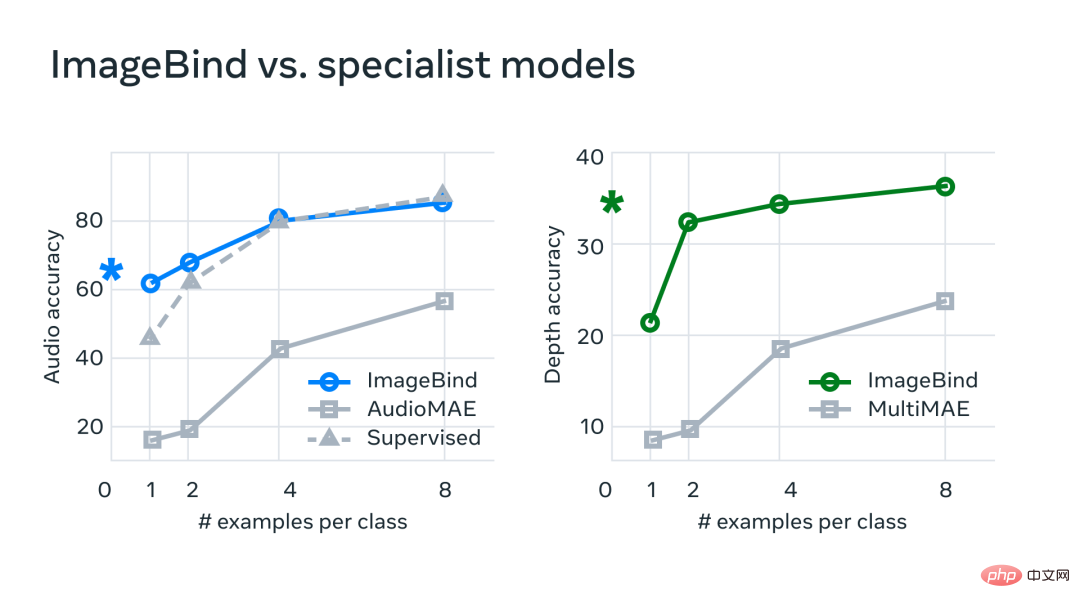
Pada penanda aras, ImageBind mengatasi pakar dalam Model audio dan kedalaman.
Meta mendapati bahawa ImageBind boleh digunakan untuk tugas audio beberapa tangkapan dan pengelasan mendalam serta mengatasi kaedah tersuai sebelumnya. Contohnya, ImageBind dengan ketara mengatasi model AudioMAE seliaan sendiri Meta yang dilatih pada Audioset, serta model AudioMAE seliaannya diperhalusi pada klasifikasi audio.
Selain itu, ImageBind mencapai prestasi SOTA baharu pada tugas pengecaman sifar pukulan merentas modaliti, mengatasi prestasi walaupun model terkini yang dilatih untuk mengenali konsep dalam modaliti tersebut.
Atas ialah kandungan terperinci Menggunakan imej untuk menyelaraskan semua modaliti, model asas AI berbilang deria sumber terbuka Meta untuk mencapai penyatuan yang hebat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Disyorkan: Projek pengesanan dan pengecaman muka sumber terbuka JS yang sangat baik
Apr 03, 2024 am 11:55 AM
Disyorkan: Projek pengesanan dan pengecaman muka sumber terbuka JS yang sangat baik
Apr 03, 2024 am 11:55 AM
Teknologi pengesanan dan pengecaman muka adalah teknologi yang agak matang dan digunakan secara meluas. Pada masa ini, bahasa aplikasi Internet yang paling banyak digunakan ialah JS Melaksanakan pengesanan muka dan pengecaman pada bahagian hadapan Web mempunyai kelebihan dan kekurangan berbanding dengan pengecaman muka bahagian belakang. Kelebihan termasuk mengurangkan interaksi rangkaian dan pengecaman masa nyata, yang sangat memendekkan masa menunggu pengguna dan meningkatkan pengalaman pengguna termasuk: terhad oleh saiz model, ketepatannya juga terhad. Bagaimana untuk menggunakan js untuk melaksanakan pengesanan muka di web? Untuk melaksanakan pengecaman muka di Web, anda perlu biasa dengan bahasa dan teknologi pengaturcaraan yang berkaitan, seperti JavaScript, HTML, CSS, WebRTC, dll. Pada masa yang sama, anda juga perlu menguasai visi komputer yang berkaitan dan teknologi kecerdasan buatan. Perlu diingat bahawa kerana reka bentuk bahagian Web
 Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
SOTA baharu untuk keupayaan memahami dokumen multimodal! Pasukan Alibaba mPLUG mengeluarkan kerja sumber terbuka terkini mPLUG-DocOwl1.5, yang mencadangkan satu siri penyelesaian untuk menangani empat cabaran utama pengecaman teks imej resolusi tinggi, pemahaman struktur dokumen am, arahan mengikut dan pengenalan pengetahuan luaran. Tanpa berlengah lagi, mari kita lihat kesannya dahulu. Pengecaman satu klik dan penukaran carta dengan struktur kompleks ke dalam format Markdown: Carta gaya berbeza tersedia: Pengecaman dan kedudukan teks yang lebih terperinci juga boleh dikendalikan dengan mudah: Penjelasan terperinci tentang pemahaman dokumen juga boleh diberikan: Anda tahu, "Pemahaman Dokumen " pada masa ini Senario penting untuk pelaksanaan model bahasa yang besar. Terdapat banyak produk di pasaran untuk membantu pembacaan dokumen. Sesetengah daripada mereka menggunakan sistem OCR untuk pengecaman teks dan bekerjasama dengan LLM untuk pemprosesan teks.
 Baru dikeluarkan! Model sumber terbuka untuk menghasilkan imej gaya anime dengan satu klik
Apr 08, 2024 pm 06:01 PM
Baru dikeluarkan! Model sumber terbuka untuk menghasilkan imej gaya anime dengan satu klik
Apr 08, 2024 pm 06:01 PM
Izinkan saya memperkenalkan kepada anda projek sumber terbuka AIGC terkini-AnimagineXL3.1. Projek ini adalah lelaran terkini model teks-ke-imej bertema anime, yang bertujuan untuk menyediakan pengguna pengalaman penjanaan imej anime yang lebih optimum dan berkuasa. Dalam AnimagineXL3.1, pasukan pembangunan menumpukan pada mengoptimumkan beberapa aspek utama untuk memastikan model mencapai tahap prestasi dan kefungsian yang baharu. Pertama, mereka mengembangkan data latihan untuk memasukkan bukan sahaja data watak permainan daripada versi sebelumnya, tetapi juga data daripada banyak siri anime terkenal lain ke dalam set latihan. Langkah ini memperkayakan pangkalan pengetahuan model, membolehkannya memahami pelbagai gaya dan watak anime dengan lebih lengkap. AnimagineXL3.1 memperkenalkan set teg khas dan estetika baharu
