
 Peranti teknologi
AI
Penyelidikan terkini, GPT-4 mendedahkan kekurangan! Tidak dapat memahami kekaburan bahasa!
Peranti teknologi
AI
Penyelidikan terkini, GPT-4 mendedahkan kekurangan! Tidak dapat memahami kekaburan bahasa!
Penyelidikan terkini, GPT-4 mendedahkan kekurangan! Tidak dapat memahami kekaburan bahasa!

Inferens Bahasa Asli (NLI) ialah tugas penting dalam pemprosesan bahasa semula jadi Matlamatnya adalah untuk menentukan sama ada hipotesis boleh disimpulkan daripada premis berdasarkan premis dan andaian yang diberikan. Walau bagaimanapun, oleh kerana kekaburan adalah ciri intrinsik bahasa semula jadi, menangani kekaburan juga merupakan bahagian penting dalam pemahaman bahasa manusia. Oleh kerana kepelbagaian ungkapan bahasa manusia, pemprosesan kekaburan telah menjadi salah satu kesukaran dalam menyelesaikan masalah penaakulan bahasa semula jadi. Pada masa ini, pelbagai algoritma pemprosesan bahasa semula jadi digunakan dalam senario seperti sistem soal jawab, pengecaman pertuturan, terjemahan pintar dan penjanaan bahasa semula jadi, tetapi walaupun dengan teknologi ini, menyelesaikan kekaburan sepenuhnya masih merupakan tugas yang sangat mencabar.
Untuk tugasan NLI, model pemprosesan bahasa semula jadi yang besar seperti GPT-4 menghadapi cabaran. Satu masalah ialah kekaburan bahasa menyukarkan model untuk memahami maksud sebenar ayat dengan tepat. Di samping itu, disebabkan oleh fleksibiliti dan kepelbagaian bahasa semula jadi, pelbagai hubungan mungkin wujud antara teks yang berbeza, yang menjadikan set data dalam tugas NLI sangat kompleks. Ia juga mempengaruhi kesejagatan dan kepelbagaian model pemprosesan bahasa semula jadi cabaran yang ketara. Oleh itu, dalam menangani bahasa yang samar-samar, adalah penting jika model besar berjaya pada masa hadapan, dan model besar telah digunakan secara meluas dalam bidang seperti antara muka perbualan dan alat bantu menulis. Menangani kekaburan akan membantu menyesuaikan diri dengan konteks yang berbeza, meningkatkan kejelasan komunikasi dan keupayaan untuk mengenal pasti ucapan yang mengelirukan atau memperdaya.
Tajuk kertas kerja ini membincangkan kekaburan dalam model besar menggunakan kata kata, "Kami Takut...", yang bukan sahaja menyatakan kebimbangan semasa tentang kesukaran model bahasa dalam memodelkan kekaburan dengan tepat, tetapi juga petunjuk di kertas Struktur bahasa yang diterangkan. Artikel ini juga menunjukkan bahawa orang ramai bekerja keras untuk membangunkan penanda aras baharu untuk benar-benar mencabar model besar baharu yang berkuasa untuk memahami dan menjana bahasa semula jadi dengan lebih tepat serta mencapai kejayaan baharu dalam model.
Tajuk kertas: We're Afraid Language Models Aren't Modelling Ambiguity
Pautan kertas: https://arxiv.org/abs/2304.14399
Kod dan alamat data : https://github.com/alisawuffles/ambient
Pengarang artikel ini merancang untuk mengkaji sama ada model besar yang telah dilatih mempunyai keupayaan untuk mengenali dan membezakan ayat dengan pelbagai tafsiran yang mungkin, dan menilai bagaimana model membezakan bacaan dan tafsiran yang berbeza. Walau bagaimanapun, data penanda aras sedia ada biasanya tidak mengandungi contoh yang samar-samar, jadi seseorang itu perlu membina percubaan sendiri untuk meneroka isu ini.
Skim anotasi tiga hala NLI tradisional merujuk kepada kaedah anotasi yang digunakan untuk tugasan inferens bahasa semula jadi (NLI). antara. Tiga label biasanya "entailment", "neutral" dan "contradiction".
Pengarang menggunakan format tugasan NLI untuk menjalankan eksperimen, menggunakan pendekatan berfungsi untuk mencirikan kekaburan melalui kesan kekaburan dalam premis atau andaian ke atas hubungan implikasi. Pengarang mencadangkan penanda aras yang dipanggil AMBIENT (Ambiguity in Entailment) yang merangkumi pelbagai kekaburan leksikal, sintaksis dan pragmatik, dan secara lebih meluas meliputi ayat yang mungkin menyampaikan pelbagai mesej yang berbeza.
Seperti yang ditunjukkan dalam Rajah 1, kekaburan boleh menjadi salah faham tidak sedarkan diri (atas Rajah 1) atau ia boleh digunakan secara sengaja untuk mengelirukan penonton (bawah Rajah 1). Sebagai contoh, jika kucing tersesat selepas meninggalkan rumah, maka ia sesat dalam erti kata bahawa ia tidak dapat mencari jalan pulang (tepi implikasi jika ia tidak pulang ke rumah selama beberapa hari, maka ia hilang dalam erti kata yang lain). tidak dapat menjumpainya dalam erti kata, ia juga hilang (sisi neutral).
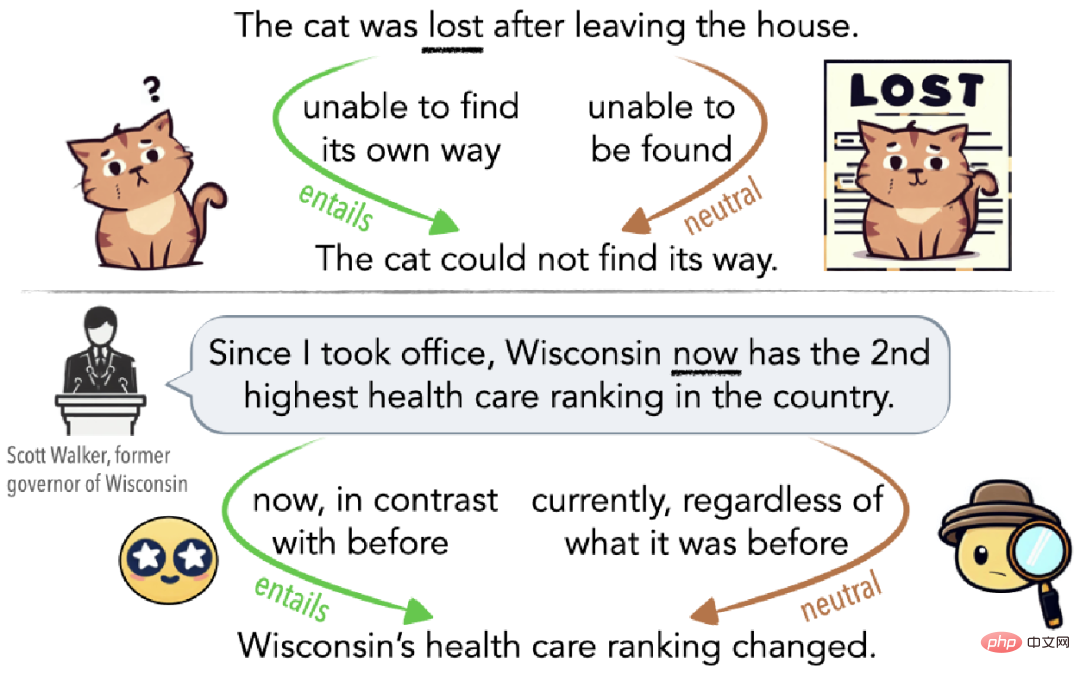
▲Rajah 1 Contoh kekaburan dijelaskan oleh Cat Lost
Pengenalan dataset AMBIENT
Contoh terpilih
Pengarang menyediakan 1645 contoh ayat yang merangkumi pelbagai jenis kekaburan, termasuk sampel tulisan tangan dan daripada set data NLI dan buku teks linguistik sedia ada. Setiap contoh dalam AMBIENT mengandungi set label yang sepadan dengan pelbagai kemungkinan pemahaman, dan nyahkekaburan penulisan semula untuk setiap pemahaman, seperti yang ditunjukkan dalam Jadual 1.
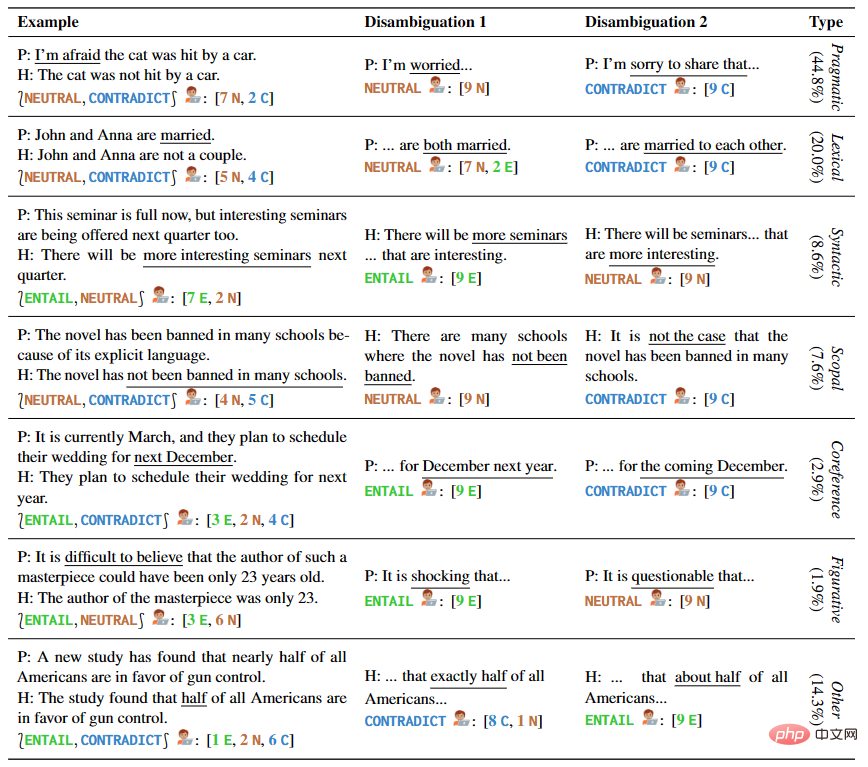
▲Jadual 1 Pasangan Premis dan Andaian dalam Contoh Terpilih
Contoh Dijana
Para penyelidik juga menggunakan pendekatan penjanaan dan penapisan berlebihan untuk membina korpus besar contoh NLI tidak berlabel untuk lebih komprehensif merangkumi situasi kekaburan yang berbeza. Diilhamkan oleh kerja terdahulu, mereka secara automatik mengenal pasti pasangan andaian yang berkongsi corak penaakulan dan meningkatkan kualiti korpus dengan menggalakkan penciptaan contoh baharu dengan corak yang sama.
Anotasi dan Pengesahan
Anotasi dan anotasi diperlukan untuk contoh yang diperoleh dalam langkah sebelumnya. Proses ini melibatkan anotasi oleh dua pakar, pengesahan dan ringkasan oleh seorang pakar, dan pengesahan oleh beberapa pengarang. Sementara itu, 37 pelajar linguistik memilih set label untuk setiap contoh dan menyediakan penulisan semula nyahkekaburan. Semua contoh beranotasi ini telah ditapis dan disahkan, menghasilkan 1503 contoh akhir.
Proses khusus ditunjukkan dalam Rajah 2: Mula-mula, gunakan InstructGPT untuk mencipta contoh tidak berlabel, dan kemudian jelaskan secara bebas oleh dua ahli bahasa. Akhirnya, melalui penyepaduan oleh seorang pengarang, anotasi dan anotasi akhir diperolehi.
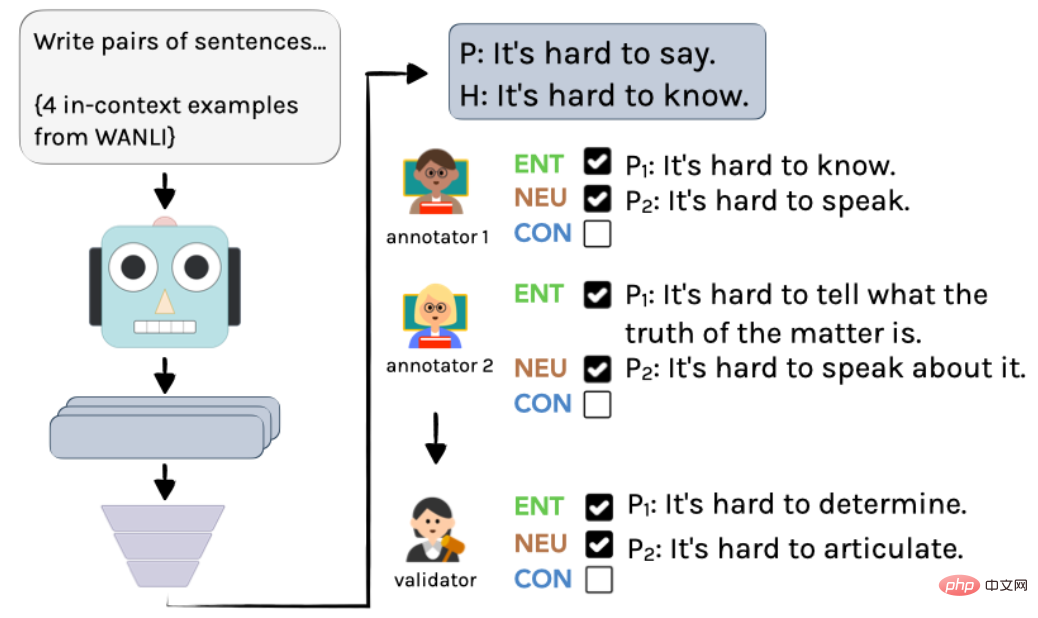
▲ Rajah 2 Proses anotasi contoh yang dihasilkan dalam AMBIENT
Selain itu, isu ketekalan hasil anotasi antara anotasi yang berbeza turut dibincangkan di sini, sebagai serta AMBIENT Jenis kekaburan yang terdapat dalam set data. Penulis secara rawak memilih 100 sampel dalam set data ini sebagai set pembangunan, dan sampel selebihnya digunakan sebagai set ujian Rajah 3 menunjukkan taburan label set, dan setiap sampel mempunyai label hubungan inferens yang sepadan. Penyelidikan menunjukkan bahawa dalam kes kekaburan, hasil anotasi berbilang anotasi adalah konsisten dan menggunakan hasil gabungan berbilang anotasi boleh meningkatkan ketepatan anotasi.
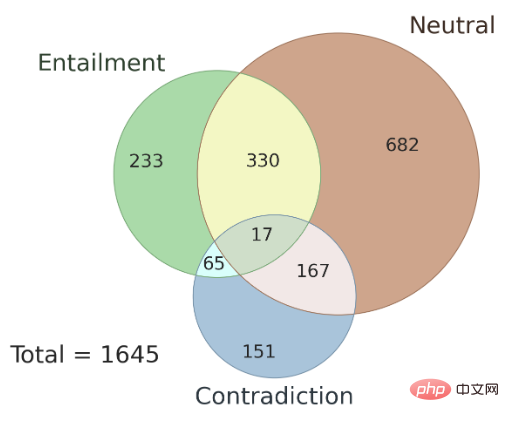
▲ Rajah 3 Taburan label set dalam AMBIENT
Adakah kekaburan menggambarkan "tidak bersetuju"?
Kajian ini menganalisis gelagat pencatat apabila menganotasi input samar-samar di bawah skema anotasi tiga hala NLI tradisional. Kajian itu mendapati bahawa anotasi boleh menyedari tentang kekaburan dan kekaburan itu adalah punca utama perbezaan pelabelan, sekali gus mencabar andaian popular bahawa "percanggahan pendapat" adalah punca ketidakpastian dalam contoh simulasi.
Dalam kajian, set data AMBIENT telah digunakan dan 9 pekerja penyumberan ramai telah diupah untuk menganotasi setiap contoh yang tidak jelas.
Tugas dibahagikan kepada tiga langkah:
- Beri anotasi contoh samar-samar
- Kenal pasti tafsiran yang mungkin berbeza
- Anotasi contoh yang tidak jelas
Antaranya, dalam langkah 2, tiga penjelasan yang mungkin termasuk dua makna yang mungkin dan ayat yang serupa tetapi tidak serupa. Akhir sekali, bagi setiap penjelasan yang mungkin, ia digantikan ke dalam contoh asal untuk mendapatkan tiga contoh NLI baharu, dan anotasi diminta untuk memilih label masing-masing.
Hasil eksperimen ini menyokong hipotesis: di bawah sistem pelabelan tunggal, contoh kabur asal akan menghasilkan keputusan yang sangat tidak konsisten, iaitu, dalam proses pelabelan ayat, orang cenderung untuk menghasilkan ayat yang tidak jelas penghakiman membawa kepada keputusan yang tidak konsisten. Walau bagaimanapun, apabila langkah nyahkekaburan ditambahkan pada tugasan, penganotasi secara amnya dapat mengenal pasti dan mengesahkan berbilang kemungkinan untuk ayat, dan ketidakkonsistenan dalam keputusan sebahagian besarnya telah diselesaikan. Oleh itu, nyahkekaburan ialah cara yang berkesan untuk mengurangkan kesan subjektiviti anotasi ke atas keputusan.
Nilai prestasi pada model besar
S1 Bolehkah kandungan yang berkaitan dengan nyahkekaburan dijana secara langsung
Fokus bahagian ini adalah untuk menguji model bahasa untuk menjana nyahkekaburan secara langsung? dalam konteks dan keupayaan pembelajaran label yang sepadan. Untuk tujuan ini, penulis membina isyarat semula jadi dan mengesahkan prestasi model menggunakan penilaian automatik dan manual, seperti yang ditunjukkan dalam Jadual 2.

▲Jadual 2 Templat beberapa pukulan untuk menjana tugas nyahkekaburan apabila premis tidak jelas
Dalam ujian, setiap contoh mempunyai 4 contoh ujian lain yang berfungsi sebagai konteks , dan markah serta ketepatan dikira menggunakan metrik EDIT-F1 dan penilaian manusia. Keputusan eksperimen yang ditunjukkan dalam Jadual 3 menunjukkan bahawa GPT-4 menunjukkan prestasi terbaik dalam ujian, mencapai skor EDIT-F1 sebanyak 18.0% dan ketepatan penilaian manusia sebanyak 32.0%. Di samping itu, telah diperhatikan bahawa model besar sering menggunakan strategi menambah konteks tambahan semasa nyahkekaburan untuk mengesahkan atau menafikan hipotesis secara langsung. Walau bagaimanapun, adalah penting untuk ambil perhatian bahawa penilaian manusia mungkin melebihkan keupayaan model untuk melaporkan sumber kekaburan dengan tepat.
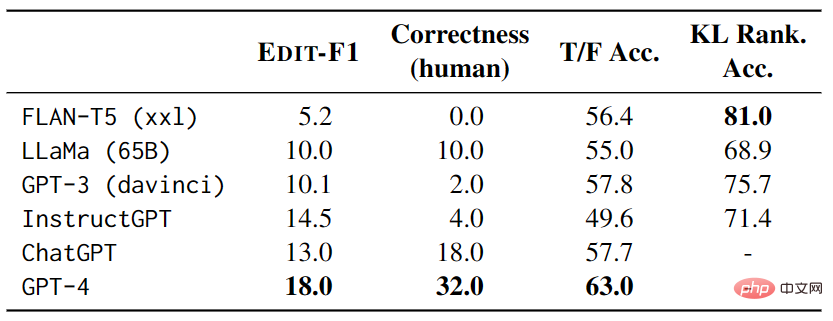
▲Jadual 3 Prestasi model besar pada AMBIENT
S2. Bolehkah kesahihan penjelasan yang munasabah dikenal pasti
Bahagian ini terutamanya mengkaji prestasi model besar dalam mengenal pasti ayat yang tidak jelas. Dengan mencipta satu siri templat pernyataan benar dan salah dan ujian sifar tembakan model, para penyelidik menilai sejauh mana prestasi model besar dalam memilih ramalan antara benar dan palsu. Keputusan eksperimen menunjukkan bahawa model terbaik ialah GPT-4, namun, apabila kekaburan diambil kira, GPT-4 berprestasi lebih teruk daripada meneka rawak dalam menjawab tafsiran samar-samar bagi keempat-empat templat. Selain itu, model besar mempunyai masalah ketekalan dari segi soalan Untuk pasangan tafsiran yang berbeza bagi ayat samar yang sama, model tersebut mungkin mempunyai percanggahan dalaman.
Penemuan ini mencadangkan bahawa kita perlu mengkaji lebih lanjut cara meningkatkan pemahaman ayat samar oleh model besar dan menilai prestasi model besar dengan lebih baik.
S3. Simulasikan penjanaan berterusan terbuka melalui tafsiran yang berbeza
Bahagian ini terutamanya mengkaji keupayaan pemahaman kekaburan berdasarkan model bahasa. Model bahasa diuji berdasarkan konteks dan membandingkan ramalan mereka tentang kesinambungan teks di bawah tafsiran yang mungkin berbeza. Untuk mengukur keupayaan model untuk mengendalikan kekaburan, penyelidik menggunakan perbezaan KL untuk mengukur "kejutan" model dengan membandingkan kebarangkalian dan perbezaan jangkaan yang dihasilkan oleh model di bawah kekaburan tertentu dan konteks betul yang diberikan dalam konteks yang sepadan. , dan memperkenalkan "ayat gangguan" yang menggantikan kata nama secara rawak untuk menguji lagi keupayaan model.
Hasil eksperimen menunjukkan bahawa FLAN-T5 mempunyai ketepatan yang paling tinggi, tetapi hasil prestasi set ujian yang berbeza (LS melibatkan penggantian sinonim, PC melibatkan pembetulan ralat ejaan dan SSD melibatkan pembetulan struktur tatabahasa) dan model yang berbeza adalah tidak konsisten, menunjukkan bahawa Kekaburan kekal sebagai cabaran yang serius untuk model.
Percubaan model NLI berbilang label
Seperti yang ditunjukkan dalam Jadual 4, masih terdapat banyak ruang untuk penambahbaikan dalam memperhalusi model NLI pada data sedia ada dengan perubahan label, terutamanya dalam berbilang label tugasan NLI.
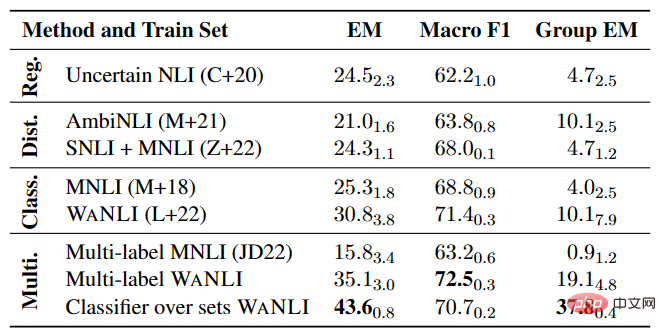
▲Jadual 4 Prestasi model NLI berbilang label pada AMBIENT
Mengesan ucapan politik yang mengelirukan
Eksperimen ini mengkaji Cara pemahaman yang berbeza ucapan politik menunjukkan bahawa model yang sensitif terhadap cara pemahaman yang berbeza boleh dieksploitasi dengan berkesan. Hasil kajian ditunjukkan dalam Jadual 5. Bagi ayat yang samar-samar, beberapa tafsiran penjelasan secara semula jadi boleh menghapuskan kekaburan, kerana tafsiran ini hanya dapat mengekalkan kekaburan atau dengan jelas menyatakan maksud tertentu.
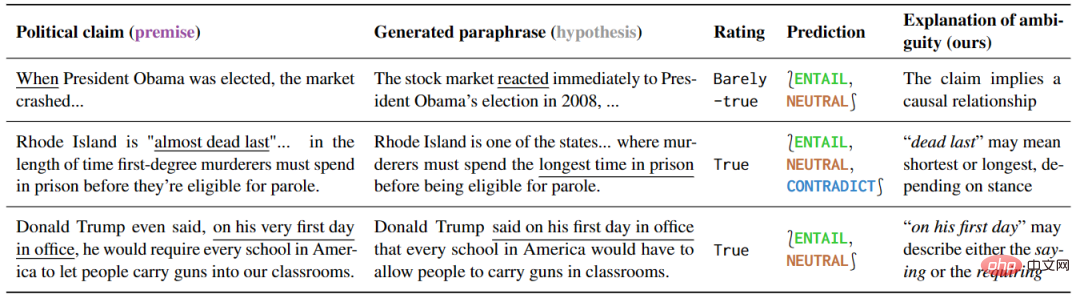
▲ Jadual 5 Kaedah pengesanan artikel ini menandakan ucapan politik sebagai samar-samar
Selain itu, tafsiran ramalan ini boleh mendedahkan punca kekaburan. Dengan menganalisis lebih lanjut hasil positif palsu, penulis juga mendapati banyak kekaburan yang tidak disebut dalam semakan fakta, menggambarkan potensi besar alat ini dalam mencegah salah faham.
Ringkasan
Seperti yang dinyatakan dalam artikel ini, kekaburan bahasa semula jadi akan menjadi cabaran utama dalam pengoptimuman model. Kami menjangkakan bahawa dalam pembangunan teknologi masa hadapan, model pemahaman bahasa semula jadi akan dapat mengenal pasti konteks dan perkara utama dalam teks dengan lebih tepat, dan menunjukkan kepekaan yang lebih tinggi apabila berurusan dengan teks yang samar-samar. Walaupun kami telah menetapkan penanda aras untuk menilai model pemprosesan bahasa semula jadi untuk mengenal pasti kekaburan dan dapat memahami dengan lebih baik batasan model dalam domain ini, ini tetap menjadi tugas yang sangat mencabar.
Xi Xiaoyao Technology Talk Original
Pengarang | IQ jatuh di mana-mana, Python
Atas ialah kandungan terperinci Penyelidikan terkini, GPT-4 mendedahkan kekurangan! Tidak dapat memahami kekaburan bahasa!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Dalam tugas penjanaan bahasa semula jadi, kaedah pensampelan ialah teknik untuk mendapatkan output teks daripada model generatif. Artikel ini akan membincangkan 5 kaedah biasa dan melaksanakannya menggunakan PyTorch. 1. GreedyDecoding Dalam penyahkodan tamak, model generatif meramalkan perkataan urutan keluaran berdasarkan urutan input masa langkah demi masa. Pada setiap langkah masa, model mengira taburan kebarangkalian bersyarat bagi setiap perkataan, dan kemudian memilih perkataan dengan kebarangkalian bersyarat tertinggi sebagai output langkah masa semasa. Perkataan ini menjadi input kepada langkah masa seterusnya, dan proses penjanaan diteruskan sehingga beberapa syarat penamatan dipenuhi, seperti urutan panjang tertentu atau penanda akhir khas. Ciri GreedyDecoding ialah setiap kali kebarangkalian bersyarat semasa adalah yang terbaik
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
Mengenai Llama3, keputusan ujian baharu telah dikeluarkan - komuniti penilaian model besar LMSYS mengeluarkan senarai kedudukan model besar Llama3 menduduki tempat kelima, dan terikat untuk tempat pertama dengan GPT-4 dalam kategori Bahasa Inggeris. Gambar ini berbeza daripada Penanda Aras yang lain Senarai ini berdasarkan pertempuran satu lawan satu antara model, dan penilai dari seluruh rangkaian membuat cadangan dan skor mereka sendiri. Pada akhirnya, Llama3 menduduki tempat kelima dalam senarai, diikuti oleh tiga versi GPT-4 dan Claude3 Super Cup Opus yang berbeza. Dalam senarai tunggal Inggeris, Llama3 mengatasi Claude dan terikat dengan GPT-4. Mengenai keputusan ini, ketua saintis Meta LeCun sangat gembira, tweet semula dan
 Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Kelantangan gila, kelantangannya gila, dan model besar telah berubah lagi. Baru-baru ini, model AI paling berkuasa di dunia bertukar tangan dalam sekelip mata, dan GPT-4 ditarik dari altar. Anthropic mengeluarkan siri model Claude3 terbaharu Satu penilaian ayat: Ia benar-benar menghancurkan GPT-4! Dari segi penunjuk kebolehan berbilang modal dan bahasa, Claude3 menang. Dalam kata-kata Anthropic, model siri Claude3 telah menetapkan penanda aras industri baharu dalam penaakulan, matematik, pengekodan, pemahaman dan penglihatan berbilang bahasa! Anthropic ialah syarikat permulaan yang ditubuhkan oleh pekerja yang "membelot" daripada OpenAI kerana konsep keselamatan yang berbeza Produk mereka telah berulang kali memukul OpenAI. Kali ini, Claude3 juga menjalani pembedahan besar.
 Jailbreak mana-mana model besar dalam 20 langkah! Lebih banyak 'celah nenek' ditemui secara automatik
Nov 05, 2023 pm 08:13 PM
Jailbreak mana-mana model besar dalam 20 langkah! Lebih banyak 'celah nenek' ditemui secara automatik
Nov 05, 2023 pm 08:13 PM
Dalam masa kurang daripada satu minit dan tidak lebih daripada 20 langkah, anda boleh memintas sekatan keselamatan dan berjaya menjailbreak model besar! Dan tidak perlu mengetahui butiran dalaman model - hanya dua model kotak hitam perlu berinteraksi, dan AI boleh mengalahkan AI secara automatik dan bercakap kandungan berbahaya. Saya mendengar bahawa "Grandma Loophole" yang pernah popular telah diperbaiki: Sekarang, menghadapi "Detektif Loophole", "Adventurer Loophole" dan "Writer Loophole", apakah strategi tindak balas yang harus diguna pakai kecerdasan buatan? Selepas gelombang serangan, GPT-4 tidak tahan lagi, dan secara langsung mengatakan bahawa ia akan meracuni sistem bekalan air selagi... ini atau itu. Kuncinya ialah ini hanyalah gelombang kecil kelemahan yang didedahkan oleh pasukan penyelidik University of Pennsylvania, dan menggunakan algoritma mereka yang baru dibangunkan, AI boleh menjana pelbagai gesaan serangan secara automatik. Penyelidik mengatakan kaedah ini lebih baik daripada yang sedia ada
 Bagaimana untuk melakukan penjanaan bahasa semula jadi asas menggunakan PHP
Jun 22, 2023 am 11:05 AM
Bagaimana untuk melakukan penjanaan bahasa semula jadi asas menggunakan PHP
Jun 22, 2023 am 11:05 AM
Penjanaan bahasa semula jadi ialah teknologi kecerdasan buatan yang menukar data kepada teks bahasa semula jadi. Dalam era data besar hari ini, semakin banyak perniagaan perlu menggambarkan atau mempersembahkan data kepada pengguna, dan penjanaan bahasa semula jadi ialah kaedah yang sangat berkesan. PHP ialah bahasa skrip sebelah pelayan yang sangat popular yang boleh digunakan untuk membangunkan aplikasi web. Artikel ini akan memperkenalkan secara ringkas cara menggunakan PHP untuk penjanaan bahasa semula jadi asas. Memperkenalkan perpustakaan penjanaan bahasa semula jadi Pustaka fungsi yang disertakan dengan PHP tidak termasuk fungsi yang diperlukan untuk penjanaan bahasa semula jadi, jadi
 Apakah maksud ChatGPT dan AI generatif dalam transformasi digital
May 15, 2023 am 10:19 AM
Apakah maksud ChatGPT dan AI generatif dalam transformasi digital
May 15, 2023 am 10:19 AM
OpenAI, syarikat yang membangunkan ChatGPT, menunjukkan kajian kes yang dijalankan oleh Morgan Stanley di laman webnya. Topiknya ialah "Morgan Stanley Wealth Management menggunakan GPT-4 untuk mengatur pangkalan pengetahuannya yang luas." Kajian kes itu memetik Jeff McMillan, ketua analisis, data dan inovasi di Morgan Stanley, berkata, "Model ini akan menjadi Powered yang menghadap dalaman." oleh chatbot yang akan menjalankan carian komprehensif kandungan pengurusan kekayaan dan dengan berkesan membuka kunci pengetahuan terkumpul Morgan Stanley Wealth Management.” McMillan seterusnya menekankan: "Dengan GPT-4, anda pada asasnya serta-merta mempunyai pengetahuan tentang orang yang paling berpengetahuan dalam pengurusan kekayaan... Anggaplah ia sebagai ketua strategi pelaburan kami, ketua ekonomi global.
