

Ia hanya mengambil masa 12 saat untuk menggunakan Stable Diffusion untuk menjana imej hanya menggunakan kuasa pengkomputeran telefon mudah alih itu sendiri.
Dan yang telah melengkapkan 20 lelaran.

Anda mesti tahu bahawa model penyebaran semasa pada asasnya melebihi 1 bilion parameter Jika anda ingin menjana gambar dengan cepat, anda mesti bergantung pada pengkomputeran awan atau perkakasan tempatan mestilah cukup berkuasa.
Apabila aplikasi model besar secara beransur-ansur menjadi lebih popular, menjalankan model besar pada komputer peribadi dan telefon mudah alih berkemungkinan menjadi trend baharu pada masa hadapan.
Hasilnya, penyelidik Google telah membawa hasil baharu ini, yang dipanggil Kelajuan adalah semua yang anda perlukan: Mempercepatkan kelajuan inferens model penyebaran berskala besar pada peranti melalui pengoptimuman GPU .

Kaedah ini dioptimumkan untuk Resapan Stabil, tetapi ia juga boleh disesuaikan dengan model resapan lain. Tugasnya adalah untuk menghasilkan imej daripada teks.
Pengoptimuman khusus boleh dibahagikan kepada tiga bahagian:
Pertama lihat kernel yang direka khas, yang merangkumi normalisasi kumpulan dan fungsi pengaktifan GELU.
Penormalan kumpulan dilaksanakan sepanjang seni bina UNet ini berfungsi dengan membahagikan saluran peta ciri kepada kumpulan yang lebih kecil dan menormalkan setiap kumpulan secara bebas, supaya penormalan Kumpulan kurang bergantung pada saiz kelompok dan boleh menyesuaikan diri dengan sesuatu. julat saiz kelompok dan seni bina rangkaian yang lebih luas.
Para penyelidik mereka bentuk kernel yang unik dalam bentuk shader GPU yang boleh melaksanakan semua kernel dalam satu arahan GPU tanpa sebarang tensor perantaraan.
Fungsi pengaktifan GELU mengandungi sejumlah besar pengiraan berangka, seperti penalti, fungsi ralat Gaussian, dsb.
Pelorek khusus menyepadukan pengiraan berangka ini dan operasi bahagi dan pendaraban yang disertakan, membolehkan pengiraan ini diletakkan dalam panggilan cabutan mudah.
Panggilan lukis ialah operasi di mana CPU memanggil antara muka pengaturcaraan imej dan mengarahkan GPU untuk membuat.
Seterusnya, apabila ia datang untuk meningkatkan kecekapan model Attention, makalah ini memperkenalkan dua kaedah pengoptimuman.
Salah satunya ialah gabungan separa fungsi softmax.
Untuk mengelak daripada melakukan keseluruhan pengiraan softmax pada matriks besar A, kajian itu mereka bentuk pelorek GPU untuk mengira vektor L dan S untuk mengurangkan pengiraan, akhirnya menghasilkan tensor saiz N×2. Kemudian pengiraan softmax dan pendaraban matriks matriks V digabungkan.
Pendekatan ini mengurangkan jejak memori dan kependaman keseluruhan program perantaraan dengan ketara.
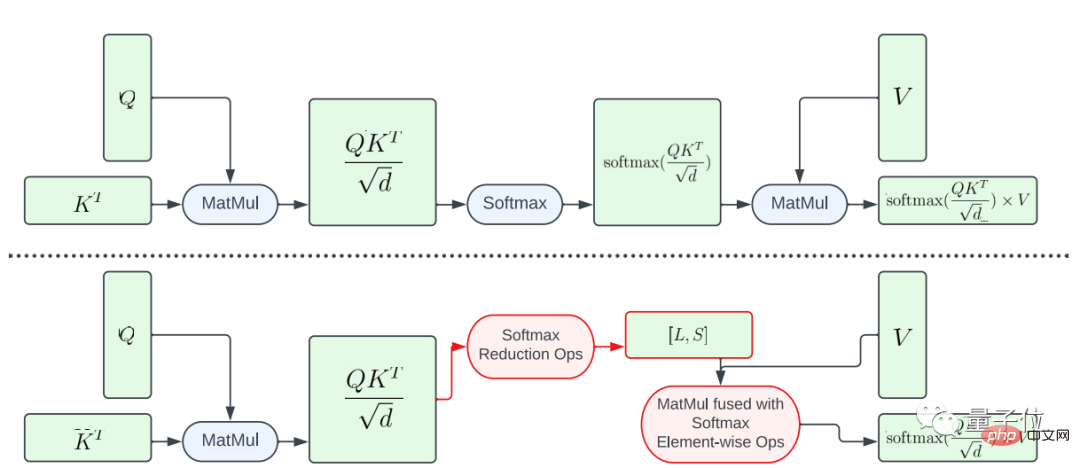
Perlu ditegaskan bahawa keselarian pemetaan pengiraan dari A ke L, S adalah terhad, kerana bilangan elemen dalam hasil tensor adalah lebih kecil daripada bilangan elemen dalam tensor input A Banyak lagi.
Untuk meningkatkan keselarian dan mengurangkan lagi kependaman, kajian ini menyusun elemen dalam A ke dalam blok dan membahagikan operasi pengurangan kepada beberapa bahagian.
Pengiraan kemudiannya dilakukan pada setiap blok dan kemudian dikurangkan kepada keputusan akhir.
Menggunakan benang yang direka dengan teliti dan pengurusan cache memori, kependaman yang lebih rendah boleh dicapai dalam berbilang bahagian menggunakan satu arahan GPU.
Kaedah pengoptimuman lain ialah FlashAttention.
Ini ialah algoritma perhatian tepat sedar IO yang menjadi popular tahun lepas Terdapat dua teknologi pecutan khusus: pengiraan tambahan dalam blok, iaitu jubin dan pengiraan semula perhatian dalam hantaran ke belakang untuk mengendalikan semua perhatian. Disepadukan ke dalam kernel CUDA.
Berbanding dengan Perhatian standard, kaedah ini boleh mengurangkan akses HBM (memori lebar jalur tinggi) dan meningkatkan kecekapan keseluruhan.
Walau bagaimanapun, teras FlashAttention adalah sangat intensif pendaftaran, jadi pasukan menggunakan kaedah pengoptimuman ini secara selektif.
Mereka menggunakan FlashAttention pada GPU Adreno dan GPU Apple dengan matriks perhatian d=40, dan menggunakan fungsi softmax gabungan separa dalam kes lain.
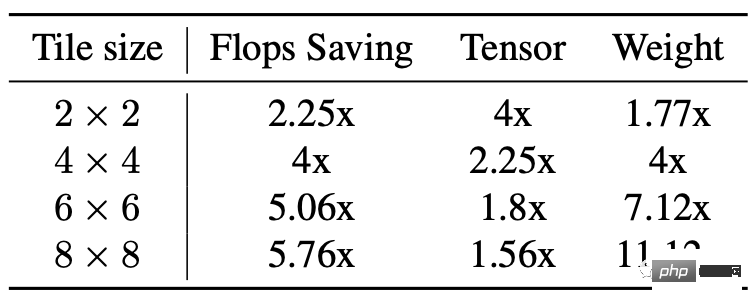
Bahagian ketiga ialah pecutan konvolusi Winograd.
Prinsipnya ialah menggunakan lebih banyak pengiraan tambahan untuk mengurangkan pengiraan pendaraban, dengan itu mengurangkan jumlah pengiraan.
Tetapi kelemahannya juga jelas, yang akan membawa lebih banyak penggunaan memori video dan ralat berangka, terutamanya apabila jubin agak besar.
Tunjang belakang Resapan Stabil sangat bergantung pada lapisan konvolusi 3×3, terutamanya dalam penyahkod imej, di mana 90% daripada lapisan terdiri daripada lapisan konvolusi 3×3.
Selepas analisis, penyelidik mendapati bahawa apabila menggunakan jubin 4×4, ia adalah titik keseimbangan terbaik antara kecekapan pengiraan model dan penggunaan memori video.
Untuk menilai kesan penambahbaikan, penyelidik mula-mula menjalankan ujian penanda aras pada telefon mudah alih.
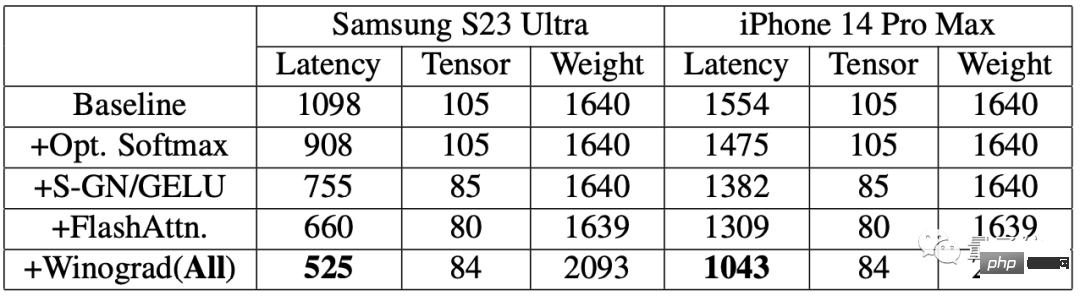
Keputusan menunjukkan bahawa selepas menggunakan algoritma pecutan, kelajuan penjanaan imej pada kedua-dua telefon telah dipertingkatkan dengan ketara.
Antaranya, kependaman pada Samsung S23 Ultra dikurangkan sebanyak 52.2%, dan kependaman pada iPhone 14 Pro Max dikurangkan sebanyak 32.9%.
Menjana imej 512×512 piksel daripada teks hujung ke hujung pada Samsung S23 Ultra, dengan 20 lelaran, mengambil masa kurang daripada 12 saat.
Alamat kertas: https://www.php.cn/link/ba825ea8a40c385c33407ebe566fa1bc
Atas ialah kandungan terperinci AI melengkapkan lukisan pada telefon bimbit dalam masa 12 saat! Google mencadangkan kaedah baharu untuk mempercepatkan inferens model resapan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Akar telefon mudah alih
Akar telefon mudah alih
 Telefon bimbit projektor
Telefon bimbit projektor
 Telefon tidak boleh bersambung ke set kepala Bluetooth
Telefon tidak boleh bersambung ke set kepala Bluetooth
 Mengapa telefon saya terus dimulakan semula?
Mengapa telefon saya terus dimulakan semula?
 Perbezaan antara telefon gantian rasmi dan telefon baharu
Perbezaan antara telefon gantian rasmi dan telefon baharu
 Mengapa telefon saya terus dimulakan semula?
Mengapa telefon saya terus dimulakan semula?
 Apa yang salah dengan telefon bimbit saya yang boleh membuat panggilan tetapi tidak melayari Internet?
Apa yang salah dengan telefon bimbit saya yang boleh membuat panggilan tetapi tidak melayari Internet?
 Mengapa telefon saya tidak dimatikan tetapi apabila seseorang menghubungi saya, telefon itu menggesa saya untuk mematikannya?
Mengapa telefon saya tidak dimatikan tetapi apabila seseorang menghubungi saya, telefon itu menggesa saya untuk mematikannya?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



