

Cara SpringBoot menggunakan Kafein untuk melaksanakan caching

Mengapa Tambah Caching pada Aplikasi
Sebelum mendalami cara menambah caching pada aplikasi, soalan pertama yang terlintas di fikiran ialah mengapa kita perlu menggunakan caching dalam aplikasi.
Andaikan terdapat aplikasi yang mengandungi data pelanggan dan pengguna membuat dua permintaan untuk mendapatkan data pelanggan (id=100).
Inilah yang berlaku tanpa caching.
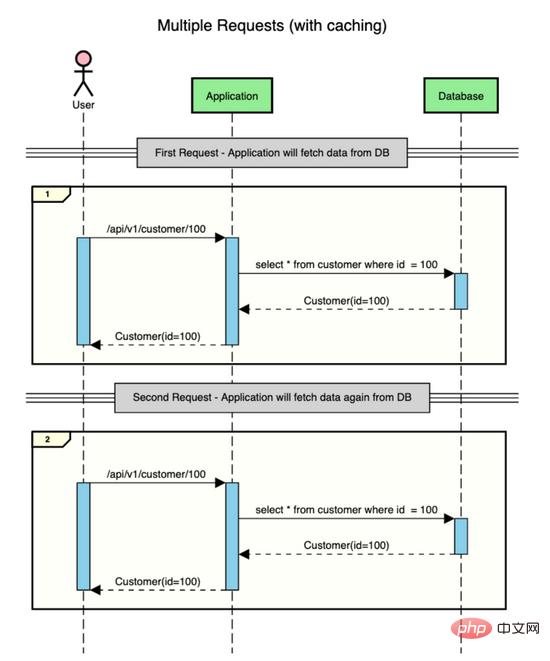
Seperti yang anda lihat, untuk setiap permintaan, aplikasi pergi ke pangkalan data untuk mendapatkan data. Mendapatkan data daripada pangkalan data adalah operasi yang mahal kerana ia melibatkan IO.
Walau bagaimanapun, jika anda mempunyai stor cache di tengah-tengah tempat anda boleh menyimpan data buat sementara waktu untuk jangka masa yang singkat, anda boleh menyimpan perjalanan pergi balik ini ke pangkalan data dan menyimpannya pada masa IO.
Beginilah rupa interaksi di atas apabila menggunakan caching.
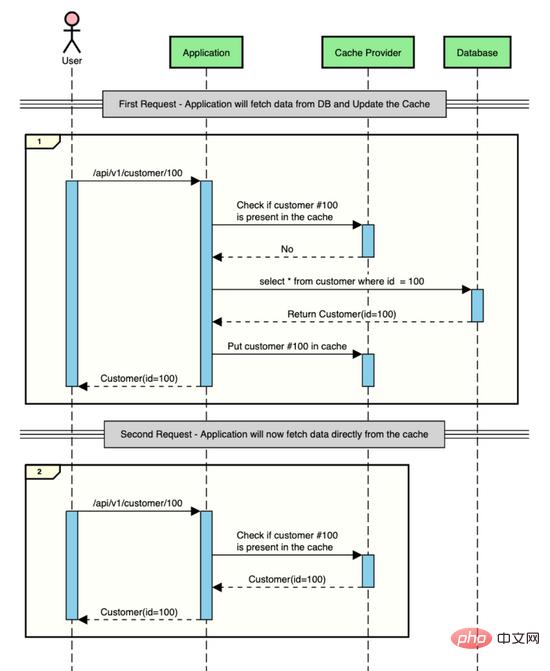
Melaksanakan Caching dalam Aplikasi Spring Boot
Apakah sokongan caching yang disediakan SpringBoot?
SpringBoot hanya menyediakan abstraksi cache yang boleh anda gunakan untuk menambahkan cache secara telus dan mudah pada aplikasi Spring anda.
Ia tidak menyediakan storan cache sebenar.
Walau bagaimanapun, ia boleh berfungsi dengan pelbagai jenis penyedia cache seperti Ehcache, Hazelcast, Redis, Caffee, dll.
Abstraksi caching SpringBoot boleh ditambah pada kaedah (menggunakan anotasi)
Pada asasnya, rangka kerja Spring akan menyemak kaedah sebelum melaksanakannya Adakah data sudah dicache?
Jika ya, maka ia akan mendapat data daripada cache.
Jika tidak, ia akan melaksanakan kaedah dan cache data
Ia juga menyediakan abstraksi untuk mengemas kini atau memadam data daripada cache.
Dalam blog semasa kami, kami akan belajar cara menambah caching menggunakan Kafein, perpustakaan caching berprestasi tinggi dan hampir optimum berdasarkan Java 8.
Anda boleh menentukan penyedia cache yang hendak digunakan dalam fail application.yaml untuk menetapkan atribut spring.cache.type.
Walau bagaimanapun, jika tiada atribut disediakan, Spring akan mengesan pembekal cache secara automatik berdasarkan perpustakaan yang ditambahkan.
Tambah kebergantungan binaan
Sekarang dengan mengandaikan anda mempunyai aplikasi but Spring asas yang sedang berjalan, mari tambahkan kebergantungan cache.
Buka fail build.gradle dan tambahkan kebergantungan berikut untuk mendayakan cache Spring Boot
compile('org.springframework.boot:spring-boot-starter-cache')
Seterusnya kami akan menambah kebergantungan pada Kafein
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
Konfigurasi cache
Kini kita perlu mendayakan caching dalam aplikasi Spring Boot.
Untuk melakukan ini, kita perlu mencipta kelas konfigurasi dan menyediakan anotasi @EnableCaching .
@Configuration
@EnableCaching
public class CacheConfig {
}Sekarang kelas ini ialah kelas kosong, tetapi kami boleh menambah lebih konfigurasi padanya jika perlu.
Sekarang kami telah mendayakan cache, mari sediakan nama cache dan konfigurasi sifat cache seperti saiz cache, masa tamat tempoh cache, dll.
Cara paling mudah ialah menambah konfigurasi dalam application.yaml
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60sKonfigurasi di atas melakukan perkara berikut
Menghadkan nama cache yang tersedia kepada pelanggan, pengguna dan peranan. Tetapkan saiz cache maksimum kepada 500.
Apabila bilangan objek dalam cache mencapai had ini, objek akan dialih keluar daripada cache mengikut dasar pengusiran cache. Tetapkan masa tamat tempoh cache kepada 1 minit.
Ini bermakna item akan dialih keluar daripada cache 1 minit selepas ditambahkan pada cache.
Terdapat cara lain untuk mengkonfigurasi cache dan bukannya mengkonfigurasi cache dalam fail application.yaml.
Anda boleh menambah dan menyediakan CacheManager Bean dalam kelas konfigurasi cache yang melakukan kerja yang sama seperti konfigurasi di atas dalam application.yaml
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}dalam kod kami Sebagai contoh, kami akan menggunakan konfigurasi Java.
Kita boleh melakukan lebih banyak perkara dalam Java, seperti mengkonfigurasi RemovalListener , melaksanakan RemovalListener apabila item dialih keluar daripada cache atau mendayakan pengelogan statistik cache, dsb.
Hasil kaedah cache
Dalam contoh aplikasi but Spring yang kami gunakan, kami sudah mempunyai API GET /API/v1/customer/{id} berikut untuk mendapatkan semula rekod pelanggan.
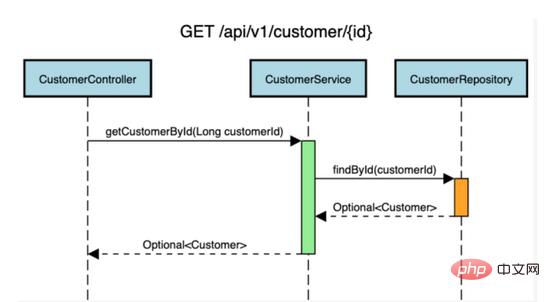
Kami akan menambah caching pada kaedah getCustomerByd(longCustomerId) kelas CustomerService.
Untuk melakukan ini, kita hanya perlu melakukan dua perkara
1 Tambahkan anotasi @CacheConfig(cacheNames=“customers”) ke kelas CustomerService
Menyediakan pilihan ini akan memastikan bahawa < Semua. kaedah cache 🎜> akan menggunakan nama cache "pelanggan" CustomerService
2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
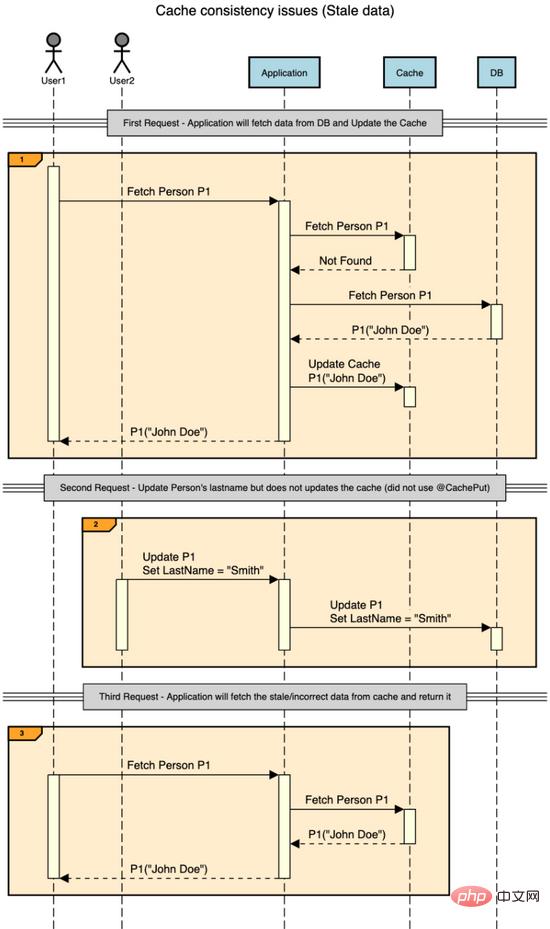
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
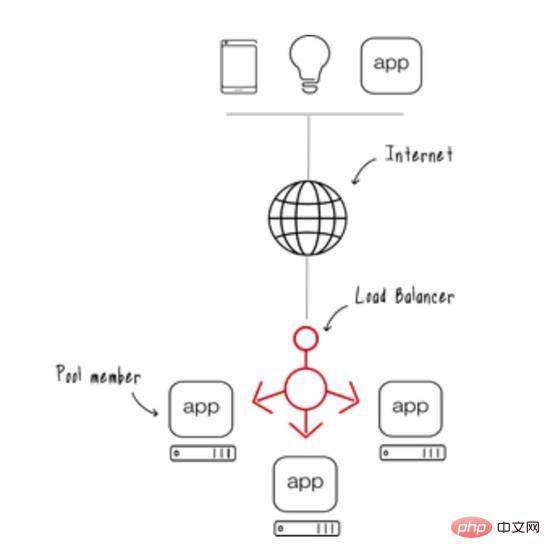
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
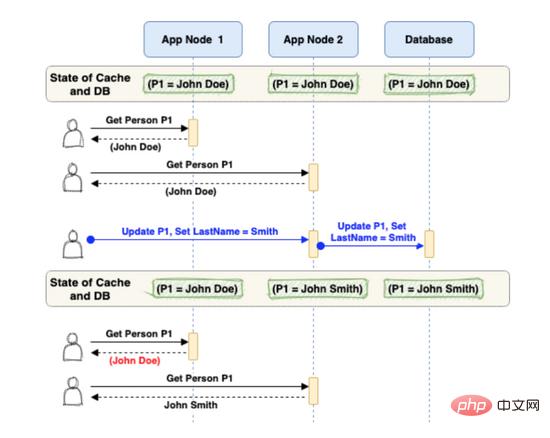
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
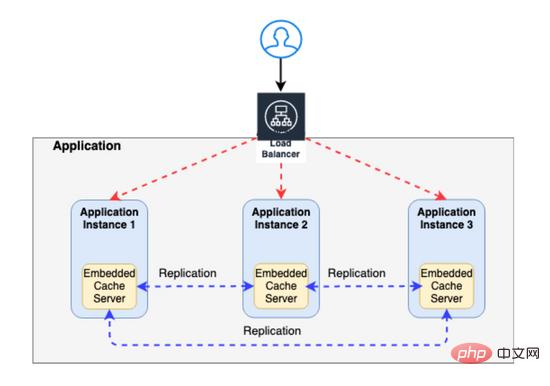
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
Atas ialah kandungan terperinci Cara SpringBoot menggunakan Kafein untuk melaksanakan caching. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Bagaimana Springboot menyepadukan Jasypt untuk melaksanakan penyulitan fail konfigurasi
Jun 01, 2023 am 08:55 AM
Bagaimana Springboot menyepadukan Jasypt untuk melaksanakan penyulitan fail konfigurasi
Jun 01, 2023 am 08:55 AM
Pengenalan kepada Jasypt Jasypt ialah perpustakaan java yang membenarkan pembangun menambah fungsi penyulitan asas pada projeknya dengan usaha yang minimum dan tidak memerlukan pemahaman yang mendalam tentang cara penyulitan berfungsi dengan tinggi untuk penyulitan sehala dan dua hala. teknologi penyulitan berasaskan piawai. Sulitkan kata laluan, teks, nombor, perduaan... Sesuai untuk penyepaduan ke dalam aplikasi berasaskan Spring, API terbuka, untuk digunakan dengan mana-mana pembekal JCE... Tambahkan kebergantungan berikut: com.github.ulisesbocchiojasypt-spring-boot-starter2 Faedah Jasypt melindungi keselamatan sistem kami Walaupun kod itu bocor, sumber data boleh dijamin.
 Bagaimana SpringBoot menyepadukan Redisson untuk melaksanakan baris gilir kelewatan
May 30, 2023 pm 02:40 PM
Bagaimana SpringBoot menyepadukan Redisson untuk melaksanakan baris gilir kelewatan
May 30, 2023 pm 02:40 PM
Senario penggunaan 1. Tempahan berjaya dibuat tetapi pembayaran tidak dibuat dalam masa 30 minit. Pembayaran tamat masa dan pesanan dibatalkan secara automatik 2. Pesanan telah ditandatangani dan tiada penilaian dilakukan selama 7 hari selepas ditandatangani. Jika pesanan tamat dan tidak dinilai, sistem lalai kepada penilaian positif 3. Pesanan dibuat dengan jayanya jika peniaga tidak menerima pesanan selama 5 minit, pesanan itu dibatalkan peringatan mesej teks dihantar... Untuk senario dengan kelewatan yang lama dan prestasi masa nyata yang rendah, kami boleh Gunakan penjadualan tugas untuk melaksanakan pemprosesan undian biasa. Contohnya: xxl-job Hari ini kita akan memilih
 Cara menggunakan Redis untuk melaksanakan kunci teragih dalam SpringBoot
Jun 03, 2023 am 08:16 AM
Cara menggunakan Redis untuk melaksanakan kunci teragih dalam SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis melaksanakan prinsip kunci teragih dan mengapa kunci teragih diperlukan Sebelum bercakap tentang kunci teragih, adalah perlu untuk menjelaskan mengapa kunci teragih diperlukan. Lawan daripada kunci yang diedarkan ialah kunci yang berdiri sendiri Apabila kami menulis program berbilang benang, kami mengelakkan masalah data yang disebabkan oleh mengendalikan pembolehubah yang dikongsi pada masa yang sama Kami biasanya menggunakan kunci untuk mengecualikan pembolehubah yang dikongsi bersama untuk memastikan ketepatannya pembolehubah yang dikongsi skop penggunaannya adalah dalam proses yang sama. Jika terdapat berbilang proses yang perlu mengendalikan sumber yang dikongsi pada masa yang sama, bagaimanakah ia boleh saling eksklusif? Aplikasi perniagaan hari ini biasanya merupakan seni bina perkhidmatan mikro, yang juga bermakna bahawa satu aplikasi akan menggunakan berbilang proses Jika berbilang proses perlu mengubah suai baris rekod yang sama dalam MySQL, untuk mengelakkan data kotor yang disebabkan oleh operasi yang tidak teratur, keperluan pengedaran. untuk diperkenalkan pada masa ini. Gaya dikunci. Ingin mencapai mata
 Bagaimana untuk menyelesaikan masalah bahawa springboot tidak boleh mengakses fail selepas membacanya ke dalam pakej balang
Jun 03, 2023 pm 04:38 PM
Bagaimana untuk menyelesaikan masalah bahawa springboot tidak boleh mengakses fail selepas membacanya ke dalam pakej balang
Jun 03, 2023 pm 04:38 PM
Springboot membaca fail, tetapi tidak boleh mengakses perkembangan terkini selepas membungkusnya ke dalam pakej balang Terdapat situasi di mana springboot tidak boleh membaca fail selepas membungkusnya ke dalam pakej balang adalah tidak sah dan hanya boleh diakses melalui strim. Fail berada di bawah resources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 Bagaimana untuk melaksanakan Springboot+Mybatis-plus tanpa menggunakan pernyataan SQL untuk menambah berbilang jadual
Jun 02, 2023 am 11:07 AM
Bagaimana untuk melaksanakan Springboot+Mybatis-plus tanpa menggunakan pernyataan SQL untuk menambah berbilang jadual
Jun 02, 2023 am 11:07 AM
Apabila Springboot+Mybatis-plus tidak menggunakan pernyataan SQL untuk melaksanakan operasi penambahan berbilang jadual, masalah yang saya hadapi akan terurai dengan mensimulasikan pemikiran dalam persekitaran ujian: Cipta objek BrandDTO dengan parameter untuk mensimulasikan parameter yang dihantar ke latar belakang bahawa adalah amat sukar untuk melaksanakan operasi berbilang jadual dalam Mybatis-plus Jika anda tidak menggunakan alatan seperti Mybatis-plus-join, anda hanya boleh mengkonfigurasi fail Mapper.xml yang sepadan dan mengkonfigurasi ResultMap yang berbau dan kemudian. tulis pernyataan sql yang sepadan Walaupun kaedah ini kelihatan menyusahkan, ia sangat fleksibel dan membolehkan kita
 Bagaimana SpringBoot menyesuaikan Redis untuk melaksanakan penyirian cache
Jun 03, 2023 am 11:32 AM
Bagaimana SpringBoot menyesuaikan Redis untuk melaksanakan penyirian cache
Jun 03, 2023 am 11:32 AM
1. Sesuaikan RedisTemplate1.1, mekanisme siri lalai RedisAPI Pelaksanaan cache Redis berasaskan API menggunakan templat RedisTemplate untuk operasi cache data Di sini, buka kelas RedisTemplate dan lihat maklumat kod sumber kelas tersebut. Isytihar kunci, Pelbagai kaedah pesirilan nilai, nilai awal kosong @NullableprivateRedisSe
 Analisis perbandingan dan perbezaan antara SpringBoot dan SpringMVC
Dec 29, 2023 am 11:02 AM
Analisis perbandingan dan perbezaan antara SpringBoot dan SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot dan SpringMVC adalah kedua-dua rangka kerja yang biasa digunakan dalam pembangunan Java, tetapi terdapat beberapa perbezaan yang jelas antara mereka. Artikel ini akan meneroka ciri dan penggunaan kedua-dua rangka kerja ini dan membandingkan perbezaannya. Mula-mula, mari belajar tentang SpringBoot. SpringBoot telah dibangunkan oleh pasukan Pivotal untuk memudahkan penciptaan dan penggunaan aplikasi berdasarkan rangka kerja Spring. Ia menyediakan cara yang pantas dan ringan untuk membina bersendirian, boleh dilaksanakan
 Bagaimana untuk mendapatkan nilai dalam application.yml dalam springboot
Jun 03, 2023 pm 06:43 PM
Bagaimana untuk mendapatkan nilai dalam application.yml dalam springboot
Jun 03, 2023 pm 06:43 PM
Dalam projek, beberapa maklumat konfigurasi sering diperlukan Maklumat ini mungkin mempunyai konfigurasi yang berbeza dalam persekitaran ujian dan persekitaran pengeluaran, dan mungkin perlu diubah suai kemudian berdasarkan keadaan perniagaan sebenar. Kami tidak boleh mengekodkan konfigurasi ini dalam kod. Adalah lebih baik untuk menulisnya dalam fail konfigurasi Sebagai contoh, anda boleh menulis maklumat ini dalam fail application.yml. Jadi, bagaimana untuk mendapatkan atau menggunakan alamat ini dalam kod? Terdapat 2 kaedah. Kaedah 1: Kita boleh mendapatkan nilai yang sepadan dengan kunci dalam fail konfigurasi (application.yml) melalui ${key} beranotasi dengan @Value Kaedah ini sesuai untuk situasi di mana terdapat sedikit perkhidmatan mikro projek, Apabila perniagaan adalah rumit, logik
