

Bagaimana SpringBoot menyepadukan kelas alat konfigurasi Kafka

spring-kafka adalah berdasarkan integrasi klien kafka versi Java dan spring Ia menyediakan KafkaTemplate, yang merangkumi pelbagai kaedah untuk operasi mudah Ia merangkum klien kafka apache dan tidak perlu mengimport kebergantungan klien
.<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>Konfigurasi YML
kafka:
#bootstrap-servers: server1:9092,server2:9093 #kafka开发地址,
#生产者配置
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 1 # 消息发送重试次数
#acks = 0:设置成 表示 producer 完全不理睬 leader broker 端的处理结果。此时producer 发送消息后立即开启下 条消息的发送,根本不等待 leader broker 端返回结果
#acks= all 或者-1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时还会等待所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给,消息安全但是吞吐量会比较低。
#acks = 1:默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给producer ,而无须等待其他副本写入该消息。折中方案,只要leader一直活着消息就不会丢失,同时也保证了吞吐量
acks: 1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 #批量大小
properties:
linger:
ms: 0 #提交延迟
buffer-memory: 33554432 # 生产端缓冲区大小
# 消费者配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 分组名称
group-id: web
enable-auto-commit: false
#提交offset延时(接收到消息后多久提交offset)
# auto-commit-interval: 1000ms
#当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
auto-offset-reset: latest
properties:
#消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
session.timeout.ms: 15000
#消费请求超时时间
request.timeout.ms: 18000
#批量消费每次最多消费多少条消息
#每次拉取一条,一条条消费,当然是具体业务状况设置
max-poll-records: 1
# 指定心跳包发送频率,即间隔多长时间发送一次心跳包,优化该值的设置可以减少Rebalance操作,默认时间为3秒;
heartbeat-interval: 6000
# 发出请求时传递给服务器的 ID。用于服务器端日志记录 正常使用后解开注释,不然只有一个节点会报错
#client-id: mqtt
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
#设置消费类型 批量消费 batch,单条消费:single
type: single
#指定容器的线程数,提高并发量
#concurrency: 3
#手动提交偏移量 manual达到一定数据后批量提交
#ack-mode: manual
ack-mode: MANUAL_IMMEDIATE #手動確認消息
# 认证
#properties:
#security:
#protocol: SASL_PLAINTEXT
#sasl:
#mechanism: SCRAM-SHA-256
#jaas:config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'Kelas alat mudah yang boleh memenuhi penggunaan biasa, tema tidak boleh diubah suai
@Component
@Slf4j
public class KafkaUtils<K, V> {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.bootstrap-servers}")
String[] servers;
/**
* 获取连接
* @return
*/
private Admin getAdmin() {
Properties properties = new Properties();
properties.put("bootstrap.servers", servers);
// 正式环境需要添加账号密码
return Admin.create(properties);
}
/**
* 增加topic
*
* @param name 主题名字
* @param partition 分区数量
* @param replica 副本数量
* @date 2022-06-23 chens
*/
public R addTopic(String name, Integer partition, Integer replica) {
Admin admin = getAdmin();
if (replica > servers.length) {
return R.error("副本数量不允许超过Broker数量");
}
try {
NewTopic topic = new NewTopic(name, partition, Short.parseShort(replica.toString()));
admin.createTopics(Collections.singleton(topic));
} finally {
admin.close();
}
return R.ok();
}
/**
* 删除主题
*
* @param names 主题名字集合
* @date 2022-06-23 chens
*/
public void deleteTopic(List<String> names) {
Admin admin = getAdmin();
try {
admin.deleteTopics(names);
} finally {
admin.close();
}
}
/**
* 查询所有主题
*
* @date 2022-06-24 chens
*/
public Set<String> queryTopic() {
Admin admin = getAdmin();
try {
ListTopicsResult topics = admin.listTopics();
Set<String> set = topics.names().get();
return set;
} catch (Exception e) {
log.error("查询主题错误!");
} finally {
admin.close();
}
return null;
}
// 向所有分区发送消息
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
return kafkaTemplate.send(topic, data);
}
// 指定key发送消息,相同key保证消息在同一个分区
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
return kafkaTemplate.send(topic, key, data);
}
// 指定分区和key发送。
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data) {
return kafkaTemplate.send(topic, partition, key, data);
}
}Hantar mesej Gunakan asynchronous
@GetMapping("/{topic}")
public String test(@PathVariable String topic, @PathVariable Long index) throws ExecutionException, InterruptedException {
ListenableFuture future = null;
Chenshuang user = new Chenshuang(i, "陈爽", "123456", new Date());
String s = JSON.toJSONString(user);
KafkaUtils utils = new KafkaUtils();
future = kafkaUtils.send(topic, s);
// 异步回调,同步get,会等待 不推荐同步!
future.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
System.out.println("发送成功:" + result);
}
});
return "发送成功";
}untuk mencipta topik
Jika broker mengkonfigurasi auto.create.topics.enable menjadi benar (lalai adalah benar), ia akan digunakan apabila menerima permintaan metadata daripada klien Cipta topik.
Menghantar dan menggunakan topik yang tidak wujud akan mencipta topik baharu Dalam kebanyakan kes, penciptaan topik yang tidak dijangka akan membawa kepada banyak masalah yang tidak dijangka.
Topik topik digunakan untuk membezakan jenis mesej yang berbeza, sebenarnya, ia sesuai untuk senario perniagaan yang berbeza Secara lalai, mesej disimpan selama satu minggu
Di bawah tema Topik yang sama. lalai ialah partition. Maksudnya, hanya ada satu pengguna untuk penggunaan Jika anda ingin meningkatkan kapasiti penggunaan, anda perlu menambah partition tiga cara untuk mengedarkan mesej (kunci, nilai) kepada Partition yang berbeza, nyatakan partition, laluan HASH, lalai, ID mesej dalam partition yang sama adalah unik dan teratur
Apabila pengguna menggunakan mesej dalam partition partition , mereka menggunakan offset untuk mengenal pasti lokasi mesej;
GroupId digunakan untuk menyelesaikan masalah penggunaan berulang di bawah Topik yang sama Contohnya, jika penggunaan perlu diterima oleh berbilang pengguna, ia boleh dicapai dengan menetapkan GroupId yang berbeza
Mesej sebenar disimpan dalam satu salinan. Ia hanya dibezakan dengan menetapkan logo secara logik mengenal pasti sama ada ia telah dimakan.
Ketersediaan tinggi untuk menghantar mesej—
Mod kluster, pelaksanaan berbilang salinan; penghantaran berjaya ; Apabila =1, induk hanya akan bertindak balas apabila =semua, lebih separuh daripada jawapan akan OK (ketersediaan tinggi sebenar)
Ketersediaan tinggi mesej yang digunakan—
<. 🎜>Pengenalan automatik boleh dimatikan mod Offsert, mula-mula tarik mesej, selepas penggunaan selesai, kemudian tetapkan kedudukan offset untuk menyelesaikan ketersediaan tinggi penggunaanimport org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaTopic {
// yml自定义主题,项目启动就创建,
@Value("${spring.kafka.topic}")
String topic;
@Value("${spring.kafka.bootstrap-servers}")
String[] server;
/**
* 项目启动 初始化主题,如果存在不会覆盖主题的
*/
@Bean
public NewTopic batchTopic() {
// 最大复制因子 <= 经纪人broker数量.
return new NewTopic(topic, 10, (short) server.length);
}
}Anda juga boleh memantau topik yang berbeza dengan kaedah yang sama dan menentukan monitor anjakan
The kumpulan yang sama akan mengambil sama rata, dan kumpulan yang berbeza akan mengambil berulang kali.
1 Mod Unicast, hanya terdapat satu kumpulan pengguna
Rajah 1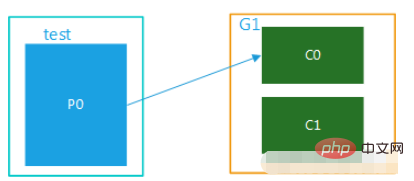
Gambar 2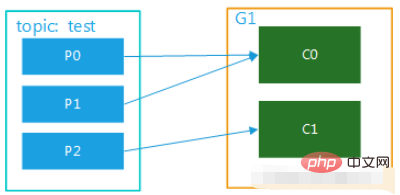
Gambar 3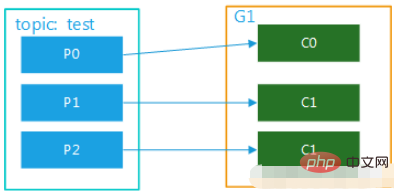
Jika anda ingin melaksanakan mod siaran, anda perlu menyediakan beberapa kumpulan pengguna, supaya selepas satu kumpulan pengguna menggunakan mesej, ia tidak akan menjejaskan penggunaan pengguna dalam kumpulan lain sama sekali daripada penyiaran.
(1) Berbilang kumpulan pengguna, 1 partition
Data dalam topik ini digunakan oleh berbilang kumpulan pengguna pada masa yang sama Apabila kumpulan pengguna mempunyai berbilang pengguna Ia hanya boleh digunakan oleh satu pengguna, seperti yang ditunjukkan dalam Rajah 4:
Rajah 4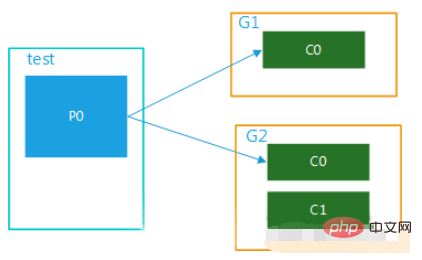 (2) Berbilang kumpulan pengguna, berbilang partition
(2) Berbilang kumpulan pengguna, berbilang partition
Data dalam topik ini boleh digunakan berbilang kali oleh berbilang kumpulan pengguna Dalam kumpulan pengguna, setiap pengguna boleh menggunakan secara selari dengan satu atau lebih partition dalam topik, seperti yang ditunjukkan dalam rajah Lima:
<. 🎜>注意: 消费者的数量并不能决定一个topic的并行度。它是由分区的数目决定的。
再多的消费者,分区数少,也是浪费!
一个组的最大并行度将等于该主题的分区数。
@Component
@Slf4j
public class Consumer {
// 监听主题 分组a
@KafkaListener(topics =("${spring.kafka.topic}") ,groupId = "a")
public void getMessage(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组a
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "a")
public void getMessage2(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage3(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage4(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 指定监听分区1的消息
@KafkaListener(topicPartitions = {@TopicPartition(topic = ("${spring.kafka.topic}"),partitions = {"1"})})
public void getMessage5(ConsumerRecord message, Acknowledgment ack) {
Long id = JSONObject.parseObject(message.value().toString()).getLong("id");
//确认收到消息//确认收到消息
ack.acknowledge();
}
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* 注意:topics和topicPartitions不能同时使用;
**/
@KafkaListener(id = "c1",groupId = "c",topicPartitions = {
@TopicPartition(topic = "t1", partitions = { "0" }),
@TopicPartition(topic = "t2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})
public void getMessage6(ConsumerRecord record,Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
/**
* 批量消费监听goods变更消息
* yml配置listener:type 要改为batch
* ymk配置consumer:max-poll-records: ??(每次拉取多少条数据消费)
* concurrency = "2" 启动多少线程执行,应小于等于broker数量,避免资源浪费
*/
@KafkaListener(id="sync-modify-goods", topics = "${spring.kafka.topic}",concurrency = "4")
public void getMessage7(List<ConsumerRecord<String, String>> records){
for (ConsumerRecord<String, String> msg:records) {
GoodsChangeMsg changeMsg = null;
try {
changeMsg = JSONObject.parseObject(msg.value(), GoodsChangeMsg.class);
syncGoodsProcessor.handle(changeMsg);
}catch (Exception exception) {
log.error("解析失败{}", msg, exception);
}
}
}
}Atas ialah kandungan terperinci Bagaimana SpringBoot menyepadukan kelas alat konfigurasi Kafka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Bagaimana untuk melaksanakan analisis saham masa nyata menggunakan PHP dan Kafka
Jun 28, 2023 am 10:04 AM
Bagaimana untuk melaksanakan analisis saham masa nyata menggunakan PHP dan Kafka
Jun 28, 2023 am 10:04 AM
Dengan perkembangan Internet dan teknologi, pelaburan digital telah menjadi topik yang semakin membimbangkan. Ramai pelabur terus meneroka dan mengkaji strategi pelaburan, dengan harapan memperoleh pulangan pelaburan yang lebih tinggi. Dalam perdagangan saham, analisis saham masa nyata adalah sangat penting untuk membuat keputusan, dan penggunaan baris gilir mesej masa nyata Kafka dan teknologi PHP adalah cara yang cekap dan praktikal. 1. Pengenalan kepada Kafka Kafka ialah sistem pemesejan terbitan dan langgan yang diedarkan tinggi yang dibangunkan oleh LinkedIn. Ciri-ciri utama Kafka ialah
 Analisis perbandingan dan perbezaan antara SpringBoot dan SpringMVC
Dec 29, 2023 am 11:02 AM
Analisis perbandingan dan perbezaan antara SpringBoot dan SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot dan SpringMVC adalah kedua-dua rangka kerja yang biasa digunakan dalam pembangunan Java, tetapi terdapat beberapa perbezaan yang jelas antara mereka. Artikel ini akan meneroka ciri dan penggunaan kedua-dua rangka kerja ini dan membandingkan perbezaannya. Mula-mula, mari belajar tentang SpringBoot. SpringBoot telah dibangunkan oleh pasukan Pivotal untuk memudahkan penciptaan dan penggunaan aplikasi berdasarkan rangka kerja Spring. Ia menyediakan cara yang pantas dan ringan untuk membina bersendirian, boleh dilaksanakan
 Cara membina aplikasi pemprosesan data masa nyata menggunakan React dan Apache Kafka
Sep 27, 2023 pm 02:25 PM
Cara membina aplikasi pemprosesan data masa nyata menggunakan React dan Apache Kafka
Sep 27, 2023 pm 02:25 PM
Cara menggunakan React dan Apache Kafka untuk membina aplikasi pemprosesan data masa nyata Pengenalan: Dengan peningkatan data besar dan pemprosesan data masa nyata, membina aplikasi pemprosesan data masa nyata telah menjadi usaha ramai pembangun. Gabungan React, rangka kerja bahagian hadapan yang popular dan Apache Kafka, sistem pemesejan teragih berprestasi tinggi, boleh membantu kami membina aplikasi pemprosesan data masa nyata. Artikel ini akan memperkenalkan cara menggunakan React dan Apache Kafka untuk membina aplikasi pemprosesan data masa nyata, dan
 Tutorial praktikal pembangunan SpringBoot+Dubbo+Nacos
Aug 15, 2023 pm 04:49 PM
Tutorial praktikal pembangunan SpringBoot+Dubbo+Nacos
Aug 15, 2023 pm 04:49 PM
Artikel ini akan menulis contoh terperinci untuk bercakap tentang perkembangan sebenar dubbo+nacos+Spring Boot. Artikel ini tidak akan merangkumi terlalu banyak pengetahuan teori, tetapi akan menulis contoh paling mudah untuk menggambarkan bagaimana dubbo boleh disepadukan dengan nacos untuk membina persekitaran pembangunan dengan cepat.
 Lima pilihan alat visualisasi untuk meneroka Kafka
Feb 01, 2024 am 08:03 AM
Lima pilihan alat visualisasi untuk meneroka Kafka
Feb 01, 2024 am 08:03 AM
Lima pilihan untuk alat visualisasi Kafka ApacheKafka ialah platform pemprosesan strim teragih yang mampu memproses sejumlah besar data masa nyata. Ia digunakan secara meluas untuk membina saluran paip data masa nyata, baris gilir mesej dan aplikasi dipacu peristiwa. Alat visualisasi Kafka boleh membantu pengguna memantau dan mengurus kelompok Kafka serta lebih memahami aliran data Kafka. Berikut ialah pengenalan kepada lima alat visualisasi Kafka yang popular: ConfluentControlCenterConfluent
 Analisis perbandingan alat visualisasi kafka: Bagaimana untuk memilih alat yang paling sesuai?
Jan 05, 2024 pm 12:15 PM
Analisis perbandingan alat visualisasi kafka: Bagaimana untuk memilih alat yang paling sesuai?
Jan 05, 2024 pm 12:15 PM
Bagaimana untuk memilih alat visualisasi Kafka yang betul? Analisis perbandingan lima alat Pengenalan: Kafka ialah sistem baris gilir mesej teragih berprestasi tinggi dan tinggi yang digunakan secara meluas dalam bidang data besar. Dengan populariti Kafka, semakin banyak perusahaan dan pembangun memerlukan alat visual untuk memantau dan mengurus kelompok Kafka dengan mudah. Artikel ini akan memperkenalkan lima alat visualisasi Kafka yang biasa digunakan dan membandingkan ciri serta fungsinya untuk membantu pembaca memilih alat yang sesuai dengan keperluan mereka. 1. KafkaManager
 Bagaimana untuk memasang Apache Kafka pada Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Bagaimana untuk memasang Apache Kafka pada Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Untuk memasang ApacheKafka pada RockyLinux, anda boleh mengikuti langkah di bawah: Kemas kini sistem: Pertama, pastikan sistem RockyLinux anda dikemas kini, laksanakan arahan berikut untuk mengemas kini pakej sistem: sudoyumupdate Pasang Java: ApacheKafka bergantung pada Java, jadi anda perlu memasang Java Development Kit (JDK) terlebih dahulu ). OpenJDK boleh dipasang melalui arahan berikut: sudoyuminstalljava-1.8.0-openjdk-devel Muat turun dan nyahmampat: Lawati laman web rasmi ApacheKafka () untuk memuat turun pakej binari terkini. Pilih versi yang stabil
 Amalan go-zero dan Kafka+Avro: membina sistem pemprosesan data interaktif berprestasi tinggi
Jun 23, 2023 am 09:04 AM
Amalan go-zero dan Kafka+Avro: membina sistem pemprosesan data interaktif berprestasi tinggi
Jun 23, 2023 am 09:04 AM
Dalam tahun-tahun kebelakangan ini, dengan peningkatan data besar dan komuniti sumber terbuka yang aktif, semakin banyak perusahaan telah mula mencari sistem pemprosesan data interaktif berprestasi tinggi untuk memenuhi keperluan data yang semakin meningkat. Dalam gelombang peningkatan teknologi ini, go-zero dan Kafka+Avro sedang diberi perhatian dan diterima pakai oleh semakin banyak perusahaan. go-zero ialah rangka kerja mikroperkhidmatan yang dibangunkan berdasarkan bahasa Golang Ia mempunyai ciri-ciri prestasi tinggi, kemudahan penggunaan, pengembangan mudah dan penyelenggaraan yang mudah. Ia direka untuk membantu perusahaan membina sistem aplikasi perkhidmatan mikro yang cekap. pertumbuhannya yang pesat
