
 pembangunan bahagian belakang
Tutorial Python
Gabungan sempurna Python dan Excel: ringkasan operasi biasa (analisis kes terperinci)
pembangunan bahagian belakang
Tutorial Python
Gabungan sempurna Python dan Excel: ringkasan operasi biasa (analisis kes terperinci)
Gabungan sempurna Python dan Excel: ringkasan operasi biasa (analisis kes terperinci)


Teks
Pada masa lalu, perkataan bahasa Inggeris yang sepadan dengan analisis perniagaan ialah Analisis Perniagaan, dan alat analisis yang digunakan oleh semua orang ialah Excel Kemudian, jumlah data meningkat , dan Excel tidak dapat mengendalikannya (Bilangan maksimum baris yang disokong oleh Excel ialah 1,048,576 baris), orang mula beralih kepada alat analisis seperti Python dan R. Pada masa ini, perkataan yang sepadan untuk analisis perniagaan ialah Analitis Perniagaan.
Malah, garis panduan penggunaan python dan Excel adalah sama, ia adalah [Kami tidak mengulangi diri kita sendiri], dan ia akan menggantikan operasi mekanikal dan buruh manual tulen dengan operasi yang lebih mudah seboleh-bolehnya .
Menggunakan Python untuk analisis data tidak dapat dipisahkan daripada pakej panda yang terkenal Selepas banyak versi pengoptimuman lelaran, ekosistem panda kini cukup lengkap . 🎜>
fungsi vlookup Jadual pangsi
Jadual pangsi
Melukis
- Jika saya menemui lebih banyak fungsi Excel pada masa hadapan, saya akan kembali dan terus mengemas kini dan Isi semula. Sebelum memulakan, mula-mula muatkan pakej panda seperti biasa:
- Interaksi antara Python dan Excel
- Empat fungsi yang paling biasa digunakan berkaitan dengan Excel I/O dalam panda ialah read_csv/ read_excel/ to_csv/ to_excel, semuanya mempunyai tetapan parameter khusus untuk menyesuaikan kesan bacaan dan eksport yang diingini.
- Sebagai contoh, jika anda ingin membaca bahagian kiri atas jadual sedemikian:
import numpy as np
import pandas as pd
pd.set_option('max_columns', 10)
pd.set_option('max_rows', 20)
pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法Anda boleh menggunakan pd.read_excel("test.xlsx" , header=1 , nrows=17, usecols=3), pulangan hasil:
df Out[]: 工号 姓名 性别部门 0 A0001 张伟男工程 1 A0002王秀英女人事 2 A0003 王芳女行政 3 A0004 郑勇男市场 4 A0005 张丽女研发 5 A0006 王艳女后勤 6 A0007 李勇男市场 7 A0008 李娟女工程 8 A0009 张静女人事 9 A0010 王磊男行政 10A0011 李娜女市场 11A0012刘诗雯女研发 12A0013 王刚男后勤 13A0014 叶倩女后勤 14A0015金雯雯女市场 15A0016王超杰男工程 16A0017 李军男人事
Begitu juga dengan fungsi output Anda boleh mengawal bilangan lajur untuk digunakan, sama ada untuk mengindeks dan cara meletakkan tajuk.
fungsi vlookup
vlookup dikenali sebagai salah satu artifak dalam Excel dan mempunyai pelbagai kegunaan Contoh berikut adalah daripada Douban 10 kegunaan fungsi VLOOKUP yang paling biasa. Berapa ramai yang anda tahu?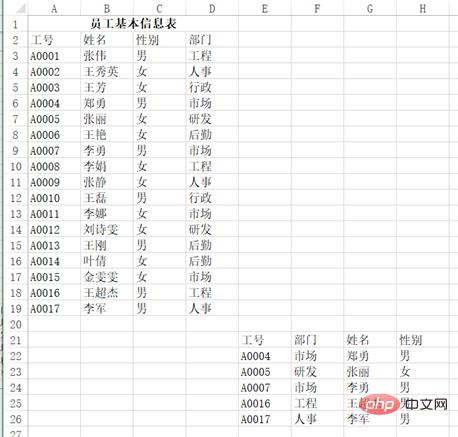
Kaedah: Masukkan =VLOOKUP(G3, $A$3:$B$7, 2) dalam julat sel H3:H13
Pelaksanaan Python:
df = pd.read_excel("test.xlsx", sheet_name=0)
def grade_to_point(x):
if x >= 90:
return 'A'
elif x >= 80:
return 'B'
elif x >= 70:
return 'C'
elif x >= 60:
return 'D'
else:
return 'E'
df['等级'] = df['语文'].apply(grade_to_point)
df
Out[]:
学号 姓名 性别 语文 等级
0 101王小丽女 69D
1 102王宝勤男 85B
2 103杨玉萍女 49E
3 104田东会女 90A
4 105陈雪蛟女 73C
5 106杨建丰男 42E
6 107黎梅佳女 79C
7 108 张兴 男 91A
8 109马进春女 48E
9 110魏改娟女100A
10111王冰研女 64DKes 2
Soalan: Bagaimana untuk mencari jumlah susut nilai bulanan di bawah nombor yang sepadan dalam jadual susut nilai dalam Helaian1? (Pertanyaan merentas jadual). 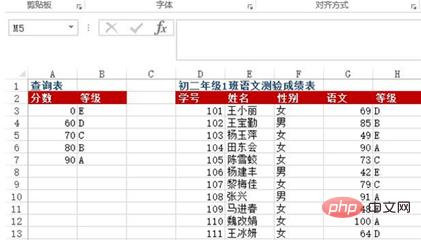
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1
df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')
Out[]:
编号 资产名称月折旧额
0YT001电动门 1399
1YT005桑塔纳轿车1147
2YT008打印机51 Kes Tiga
Kes TigaMasalah: Sama seperti Kes Dua, tetapi kali ini anggaran carian perlu digunakan. 
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表
df3['月折旧额'] = 0
for i in range(len(df3['资产名称'])):
df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3
Out[]:
资产名称 月折旧额
0 电动 1399
1 货车 2438
2 惠普132
3 交联10133
4桑塔纳 1147
5 春兰230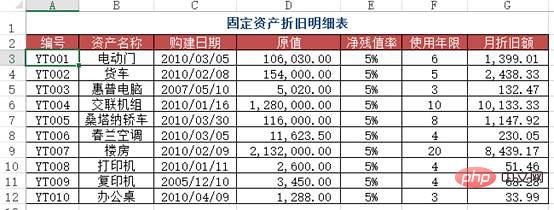 Kes 4
Kes 4Masalah: Apabila memasukkan maklumat data dalam Excel, untuk meningkatkan kecekapan kerja, pengguna berharap untuk memaparkan secara automatik baki maklumat rekod dengan memasukkan kata kunci data , sebagai contoh, Memasukkan nombor kerja pekerja akan memaparkan nama pekerja secara automatik Memasukkan nombor bahan akan memaparkan nama produk, harga unit, dsb. bahan secara automatik. 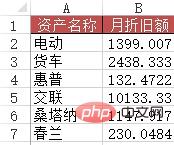
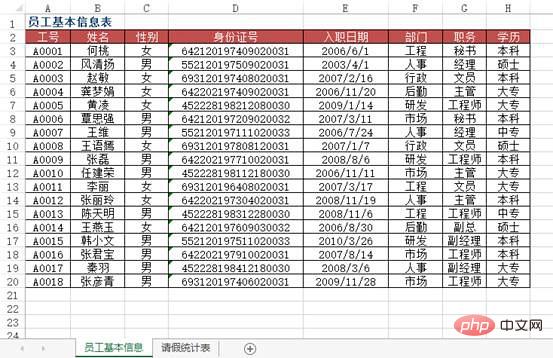
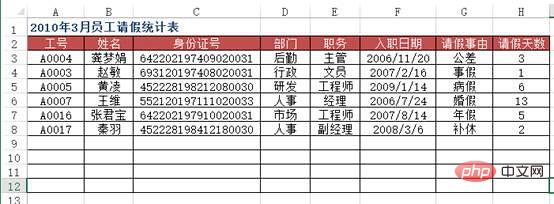
方法:使用VLOOKUP+MATCH函数,在“2010年3月员工请假统计表”工作表中选择B3:F8单元格区域,输入下列公式=IF($A3="","",VLOOKUP($A3,员工基本信息!$A:$H,MATCH(B$2,员工基本信息!$2:$2,0),0)),按下【Ctrl+Enter】组合键结束。
python实现:上面的Excel的方法用得很灵活,但是pandas的想法和操作更简单方便些。
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')
df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')
df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')
Out[]:
工号 姓名部门 职务 入职日期
0A0004龚梦娟后勤 主管 2006-11-20
1A0003 赵敏行政 文员 2007-02-16
2A0005 黄凌研发工程师 2009-01-14
3A0007 王维人事 经理 2006-07-24
4A0016张君宝市场工程师 2007-08-14
5A0017 秦羽人事副经理 2008-03-06案例五
问题:用VLOOKUP函数实现批量查找,VLOOKUP函数一般情况下只能查找一个,那么多项应该怎么查找呢?如下图,如何把张一的消费额全部列出?
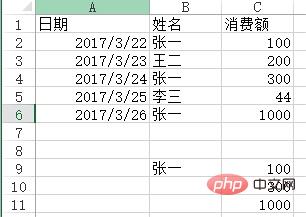
方法:在C9:C11单元格里面输入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。
python实现:vlookup函数有两个不足(或者算是特点吧),一个是被查找的值一定要在区域里的第一列,另一个是只能查找一个值,剩余的即便能匹配也不去查找了,这两点都能通过灵活应用if和indirect函数来解决,不过pandas能做得更直白一些。
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')
df6[df6['姓名'] == '张一'][['姓名', '消费额']]
Out[]:
姓名 消费额
0张一 100
2张一 300
4张一1000数据透视表
数据透视表是Excel的另一个神器,本质上是一系列的表格重组整合的过程。这里用的案例来自知乎,Excel数据透视表有什么用途:(https://www.zhihu.com/question/22484899/answer/39933218 )
问题:需要汇总各个区域,每个月的销售额与成本总计,并同时算出利润。
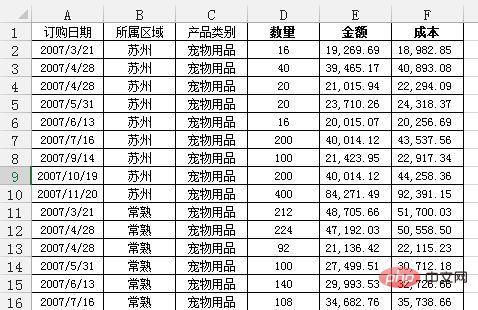
通过Excel的数据透视表的操作最终实现了下面这样的效果:
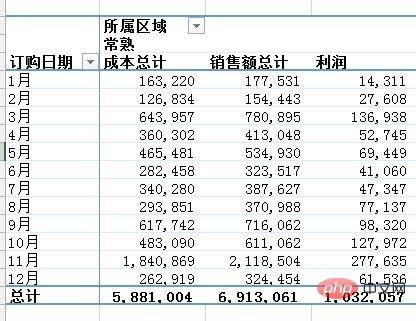
python实现:对于这样的分组的任务,首先想到的就是pandas的groupby,代码写起来也简单,思路就是把刚才Excel的点鼠标的操作反映到代码命令上:
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')
df['订购月份'] = df['订购日期'].apply(lambda x:x.month)
df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')
df2['利润'] = df2['销售额'] - df2['成本']
df2
Out[]:
销售额 成本利润
订购月份 所属区域
1南京134313.61 94967.8439345.77
常熟177531.47163220.0714311.40
无锡316418.09231822.2884595.81
昆山159183.35145403.3213780.03
苏州287253.99238812.0348441.96
2南京187129.13138530.4248598.71
常熟154442.74126834.3727608.37
无锡464012.20376134.9887877.22
昆山102324.46 86244.5216079.94
苏州105940.34 91419.5414520.80
...... ...
11 南京286329.88221687.1164642.77
常熟 2118503.54 1840868.53 277635.01
无锡633915.41536866.7797048.64
昆山351023.24342420.18 8603.06
苏州 1269351.39 1144809.83 124541.56
12 南京894522.06808959.3285562.74
常熟324454.49262918.8161535.68
无锡 1040127.19856816.72 183310.48
昆山 1096212.75951652.87 144559.87
苏州347939.30302154.2545785.05
[60 rows x 3 columns]也可以使用pandas里的pivot_table函数来实现:
df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum') df3['利润'] = df3['销售额'] - df3['成本'] df3 Out[]: 成本销售额利润 订购月份 所属区域 1南京 94967.84134313.6139345.77 常熟163220.07177531.4714311.40 无锡231822.28316418.0984595.81 昆山145403.32159183.3513780.03 苏州238812.03287253.9948441.96 2南京138530.42187129.1348598.71 常熟126834.37154442.7427608.37 无锡376134.98464012.2087877.22 昆山 86244.52102324.4616079.94 苏州 91419.54105940.3414520.80 ...... ... 11 南京221687.11286329.8864642.77 常熟 1840868.53 2118503.54 277635.01 无锡536866.77633915.4197048.64 昆山342420.18351023.24 8603.06 苏州 1144809.83 1269351.39 124541.56 12 南京808959.32894522.0685562.74 常熟262918.81324454.4961535.68 无锡856816.72 1040127.19 183310.48 昆山951652.87 1096212.75 144559.87 苏州302154.25347939.3045785.05 [60 rows x 3 columns]
pandas的pivot_table的参数index/ columns/ values和Excel里的参数是对应上的(当然,我这话说了等于没说,数据透视表里不就是行/列/值吗还能有啥。)
但是我个人还是更喜欢用groupby,因为它运算速度非常快。我在打kaggle比赛的时候,有一张表是贷款人的行为信息,大概有2700万行,用groupby算了几个聚合函数,几秒钟就完成了。
groupby的功能很全面,内置了很多aggregate函数,能够满足大部分的基本需求,如果你需要一些其他的函数,可以搭配使用apply和lambda。
不过pandas的官方文档说了,groupby之后用apply速度非常慢,aggregate内部做过优化,所以很快,apply是没有优化的,所以建议有问题先想想别的方法,实在不行的时候再用apply。
我打比赛的时候,为了生成一个新变量,用了groupby的apply,写了这么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。
绘图
因为Excel画出来的图能够交互,能够在图上进行一些简单操作,所以这里用的python的可视化库是plotly,案例就用我这个学期发展经济学课上的作业吧,当时的图都是用Excel画的,现在用python再画一遍。开始之前,首先加载plotly包。
import plotly.offline as off import plotly.graph_objs as go off.init_notebook_mode()
柱状图
当时用Excel画了很多的柱状图,其中的一幅图是:
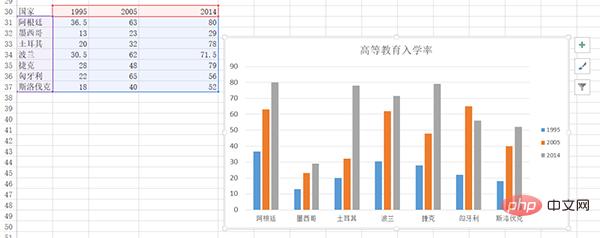
下面用plotly来画一下:
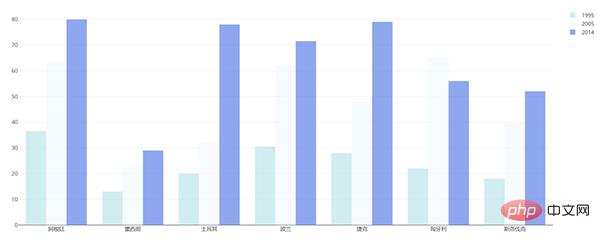
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')
trace1 = go.Bar(
x=df['国家'],
y=df[1995],
name='1995',
opacity=0.6,
marker=dict(
color='powderblue'
)
)
trace2 = go.Bar(
x=df['国家'],
y=df[2005],
name='2005',
opacity=0.6,
marker=dict(
color='aliceblue',
)
)
trace3 = go.Bar(
x=df['国家'],
y=df[2014],
name='2014',
opacity=0.6,
marker=dict(
color='royalblue'
)
)
layout = go.Layout(barmode='group')
data = [trace1, trace2, trace3]
fig = go.Figure(data, layout)
off.plot(fig)雷达图
用Excel画的:
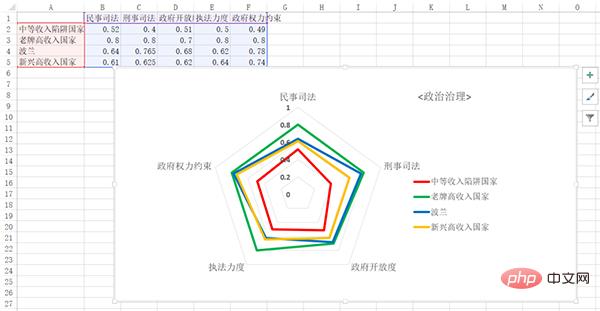
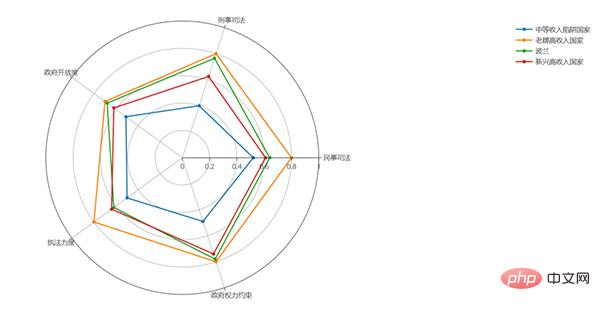
用python画的:
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')
theta = df.columns.tolist()
theta.append(theta[0])
names = df.index
df[''] = df.iloc[:,0]
df = np.array(df)
trace1 = go.Scatterpolar(
r=df[0],
theta=theta,
name=names[0]
)
trace2 = go.Scatterpolar(
r=df[1],
theta=theta,
name=names[1]
)
trace3 = go.Scatterpolar(
r=df[2],
theta=theta,
name=names[2]
)
trace4 = go.Scatterpolar(
r=df[3],
theta=theta,
name=names[3]
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0,1]
)
),
showlegend=True
)
fig = go.Figure(data, layout)
off.plot(fig)画起来比Excel要麻烦得多。
总体而言,如果画简单基本的图形,用Excel是最方便的,如果要画高级一些的或者是需要更多定制化的图形,使用python更合适。
Atas ialah kandungan terperinci Gabungan sempurna Python dan Excel: ringkasan operasi biasa (analisis kes terperinci). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Penyimpanan Objek Minio: Penyebaran berprestasi tinggi di bawah CentOS System Minio adalah prestasi tinggi, sistem penyimpanan objek yang diedarkan yang dibangunkan berdasarkan bahasa Go, serasi dengan Amazons3. Ia menyokong pelbagai bahasa pelanggan, termasuk Java, Python, JavaScript, dan GO. Artikel ini akan memperkenalkan pemasangan dan keserasian minio pada sistem CentOS. Keserasian versi CentOS Minio telah disahkan pada pelbagai versi CentOS, termasuk tetapi tidak terhad kepada: CentOS7.9: Menyediakan panduan pemasangan lengkap yang meliputi konfigurasi kluster, penyediaan persekitaran, tetapan fail konfigurasi, pembahagian cakera, dan mini
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
 Cara Memilih Versi PyTorch di CentOS
Apr 14, 2025 pm 06:51 PM
Cara Memilih Versi PyTorch di CentOS
Apr 14, 2025 pm 06:51 PM
Apabila memasang pytorch pada sistem CentOS, anda perlu dengan teliti memilih versi yang sesuai dan pertimbangkan faktor utama berikut: 1. Keserasian Persekitaran Sistem: Sistem Operasi: Adalah disyorkan untuk menggunakan CentOS7 atau lebih tinggi. CUDA dan CUDNN: Versi Pytorch dan versi CUDA berkait rapat. Sebagai contoh, Pytorch1.9.0 memerlukan CUDA11.1, manakala Pytorch2.0.1 memerlukan CUDA11.3. Versi CUDNN juga mesti sepadan dengan versi CUDA. Sebelum memilih versi PyTorch, pastikan anda mengesahkan bahawa versi CUDA dan CUDNN yang serasi telah dipasang. Versi Python: Cawangan Rasmi Pytorch
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
