
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk membina pepohon keputusan dalam Python
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk membina pepohon keputusan dalam Python
Bagaimana untuk membina pepohon keputusan dalam Python

Pokok Keputusan
Pokok keputusan ialah sebahagian daripada kaedah pembelajaran penyeliaan yang paling berkuasa masa kini. Pokok keputusan pada asasnya ialah carta alir bagi pokok binari di mana setiap nod membahagikan satu set pemerhatian berdasarkan beberapa pembolehubah ciri.
Matlamat pepohon keputusan adalah untuk membahagikan data kepada kumpulan supaya setiap elemen dalam kumpulan tergolong dalam kategori yang sama. Pokok keputusan juga boleh digunakan untuk menganggarkan pembolehubah sasaran berterusan. Dalam kes ini, pokok akan dipecahkan supaya setiap kumpulan mempunyai min ralat kuasa dua terkecil.
Sifat penting pepohon keputusan ialah ia mudah ditafsir. Anda tidak perlu membiasakan diri dengan teknik pembelajaran mesin sama sekali untuk memahami perkara yang dilakukan oleh pokok keputusan. Gambar rajah pokok keputusan mudah ditafsir.
Kebaikan dan Keburukan
Kelebihan kaedah pepohon keputusan ialah:
Pokok keputusan boleh menjana peraturan yang boleh difahami.
Pokok keputusan melakukan pengelasan tanpa memerlukan pengiraan yang meluas.
Pokok keputusan boleh mengendalikan kedua-dua pembolehubah berterusan dan kategori.
Pokok keputusan memberikan petunjuk yang jelas tentang bidang mana yang paling penting.
Kelemahan kaedah pepohon keputusan ialah:
Pokok keputusan tidak sesuai untuk tugasan anggaran di mana matlamatnya adalah untuk meramalkan nilai atribut berterusan .
Pokok keputusan terdedah kepada ralat dalam masalah pengelasan dengan banyak kelas dan sedikit sampel latihan.
Latihan pokok keputusan boleh mahal dari segi pengiraan. Proses menjana pepohon keputusan secara pengiraan sangat mahal. Pada setiap nod, setiap medan pemisahan calon mesti diisih untuk mencari pemisahan terbaiknya. Dalam sesetengah algoritma, menggunakan gabungan medan, gabungan pemberat terbaik mesti dicari. Algoritma pemangkasan juga boleh mahal kerana banyak subpokok calon mesti dibentuk dan dibandingkan.
Python Decision Tree
Python ialah bahasa pengaturcaraan tujuan umum yang menyediakan saintis data pakej dan alatan pembelajaran mesin yang berkuasa. Dalam artikel ini, kami akan menggunakan scikit-learn, pakej pembelajaran mesin yang paling terkenal dalam python, untuk membina model pepohon keputusan. Kami akan mencipta model menggunakan algoritma "DecisionTreeClassifier" yang disediakan oleh scikit learn dan kemudian memvisualisasikan model menggunakan fungsi "plot_tree".
Langkah 1: Import pakej
Pakej perisian utama yang kami gunakan untuk membina model ialah panda, scikit learn dan NumPy. Ikut kod untuk mengimport pakej yang diperlukan dalam python.
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20)
Selepas mengimport semua pakej yang diperlukan untuk membina model kami, tiba masanya untuk mengimport data dan melakukan beberapa EDA padanya.
Langkah 2: Import data dan EDA
Dalam langkah ini, kami akan menggunakan pakej "Panda" yang disediakan dalam python untuk mengimport dan melakukan beberapa EDA padanya. Kami akan membina model pepohon keputusan kami pada set data yang merupakan set data ubat yang ditetapkan kepada pesakit berdasarkan kriteria tertentu. Mari import data menggunakan python!
Pelaksanaan Python:
df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold']))Output:
Age Sex BP Cholesterol Na_to_K Drug 0 23 F HIGH HIGH 25.355 drugY 1 47 M LOW HIGH 13.093 drugC 2 47 M LOW HIGH 10.114 drugC 3 28 F NORMAL HIGH 7.798 drugX 4 61 F LOW HIGH 18.043 drugY
Kini kami mempunyai idea yang jelas tentang dataset. Selepas mengimport data, mari gunakan fungsi "info" untuk mendapatkan beberapa maklumat asas tentang data. Maklumat yang disediakan oleh fungsi ini termasuk bilangan entri, nombor indeks, nama lajur, kiraan nilai bukan nol, jenis atribut, dsb.
Pelaksanaan Python:
df.info()
Output:
<class> RangeIndex: 200 entries, 0 to 199 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 200 non-null int64 1 Sex 200 non-null object 2 BP 200 non-null object 3 Cholesterol 200 non-null object 4 Na_to_K 200 non-null float64 5 Drug 200 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 9.5+ KB</class>
Langkah 3: Pemprosesan data
Kita boleh Lihat bahawa sifat seperti Sex, BP dan Kolesterol adalah kategori dan jenis objek secara semula jadi. Masalahnya ialah algoritma pepohon keputusan dalam scikit-learn sememangnya tidak menyokong pembolehubah X (ciri) yang jenis "objek". Oleh itu, adalah perlu untuk menukar nilai "objek" ini kepada nilai "perduaan". Marilah kita menggunakan python untuk melaksanakan
Pelaksanaan Python:
for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold']))
Output:
Age Sex BP Cholesterol Na_to_K Drug 0 23 1 2 1 25.355 drugY 1 47 1 0 1 13.093 drugC 2 47 1 0 1 10.114 drugC 3 28 1 1 1 7.798 drugX 4 61 1 0 1 18.043 drugY .. ... ... .. ... ... ... 195 56 1 0 1 11.567 drugC 196 16 1 0 1 12.006 drugC 197 52 1 1 1 9.894 drugX 198 23 1 1 1 14.020 drugX 199 40 1 0 1 11.349 drugX [200 rows x 6 columns]
Kita dapat melihat bahawa semua nilai "objek" diproses ke dalam nilai "binari" untuk mewakili data kategori. Sebagai contoh, dalam atribut kolesterol, nilai yang menunjukkan "rendah" diproses sebagai 0, dan nilai "tinggi" diproses sebagai 1. Kini kami bersedia untuk mencipta pembolehubah bersandar dan bebas daripada data.
Langkah 4: Pisahkan data
Selepas memproses data kami ke dalam struktur yang betul, kami kini menetapkan pembolehubah "X" (pembolehubah bebas), "Y "Pembolehubah (pembolehubah bersandar). Marilah kita menggunakan python untuk melaksanakan
Pelaksanaan Python:
X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold']))Output:
X variable samples : [[ 1. 2. 23. 1. 25.355] [ 1. 0. 47. 1. 13.093] [ 1. 0. 47. 1. 10.114] [ 1. 1. 28. 1. 7.798] [ 1. 0. 61. 1. 18.043]] Y variable samples : ['drugY' 'drugC' 'drugC' 'drugX' 'drugY']
Kini kita boleh menggunakan algoritma "train_test_split" dalam scikit belajar untuk Data dibahagikan kepada set latihan dan set ujian, yang mengandungi pembolehubah X dan Y yang kami takrifkan. Ikut kod untuk memisahkan data dalam python.
Pelaksanaan Python:
X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'black')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'black')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'black')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'black'))Output:
X_train shape : (160, 5) X_test shape : (40, 5) y_train shape : (160,) y_test shape : (40,)
Kini kami mempunyai semua komponen untuk membina model pepohon keputusan. Jadi, mari kita teruskan dan bina model kita dalam python.
Langkah 5: Bina model dan ramalan
Dengan bantuan algoritma "DecisionTreeClassifier" yang disediakan oleh pakej scikit-learn, ia boleh dilakukan untuk membina pepohon keputusan . Selepas itu, kami boleh menggunakan model terlatih kami untuk meramalkan data kami. Akhir sekali, ketepatan keputusan ramalan kami boleh dikira menggunakan metrik penilaian "Ketepatan". Mari gunakan python untuk melengkapkan proses ini
Pelaksanaan Python:
model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold']))Output:
Accuracy of the model is 88%
在代码的第一步中,我们定义了一个名为“model”变量的变量,我们在其中存储DecisionTreeClassifier模型。接下来,我们将使用我们的训练集对模型进行拟合和训练。之后,我们定义了一个变量,称为“pred_model”变量,其中我们将模型预测的所有值存储在数据上。最后,我们计算了我们的预测值与实际值的精度,其准确率为88%。
步骤6:可视化模型
现在我们有了决策树模型,让我们利用python中scikit learn包提供的“plot_tree”函数来可视化它。按照代码从python中的决策树模型生成一个漂亮的树图。
Python实现:
feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')输出:
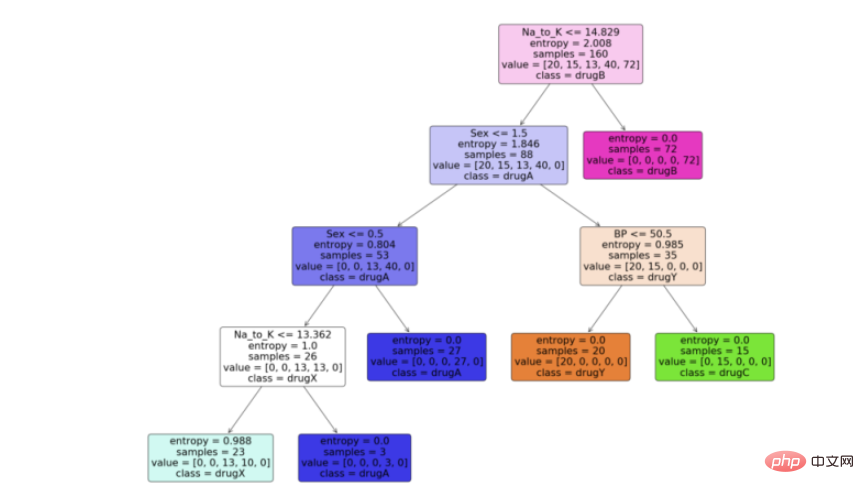
结论
有很多技术和其他算法用于优化决策树和避免过拟合,比如剪枝。虽然决策树通常是不稳定的,这意味着数据的微小变化会导致最优树结构的巨大变化,但其简单性使其成为广泛应用的有力候选。在神经网络流行之前,决策树是机器学习中最先进的算法。其他一些集成模型,比如随机森林模型,比普通决策树模型更强大。
决策树由于其简单性和可解释性而非常强大。决策树和随机森林在用户注册建模、信用评分、故障预测、医疗诊断等领域有着广泛的应用。我为本文提供了完整的代码。
完整代码:
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20) df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold'])) df.info() for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold'])) X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold'])) X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'red')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'red')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'green')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'green')) model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold'])) feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')Atas ialah kandungan terperinci Bagaimana untuk membina pepohon keputusan dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python cemerlang dalam automasi, skrip, dan pengurusan tugas. 1) Automasi: Sandaran fail direalisasikan melalui perpustakaan standard seperti OS dan Shutil. 2) Penulisan Skrip: Gunakan Perpustakaan Psutil untuk memantau sumber sistem. 3) Pengurusan Tugas: Gunakan perpustakaan jadual untuk menjadualkan tugas. Kemudahan penggunaan Python dan sokongan perpustakaan yang kaya menjadikannya alat pilihan di kawasan ini.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
 Apa itu vscode untuk apa vscode?
Apr 15, 2025 pm 06:45 PM
Apa itu vscode untuk apa vscode?
Apr 15, 2025 pm 06:45 PM
VS Kod adalah nama penuh Visual Studio Code, yang merupakan editor kod dan persekitaran pembangunan yang dibangunkan oleh Microsoft. Ia menyokong pelbagai bahasa pengaturcaraan dan menyediakan penonjolan sintaks, penyiapan automatik kod, coretan kod dan arahan pintar untuk meningkatkan kecekapan pembangunan. Melalui ekosistem lanjutan yang kaya, pengguna boleh menambah sambungan kepada keperluan dan bahasa tertentu, seperti debuggers, alat pemformatan kod, dan integrasi Git. VS Kod juga termasuk debugger intuitif yang membantu dengan cepat mencari dan menyelesaikan pepijat dalam kod anda.
