
 Peranti teknologi
AI
Aplikasi model pemeringkatan pengesyoran domain merentas pembelajaran pemindahan berterusan dalam sistem pengesyoran Taobao
Peranti teknologi
AI
Aplikasi model pemeringkatan pengesyoran domain merentas pembelajaran pemindahan berterusan dalam sistem pengesyoran Taobao
Aplikasi model pemeringkatan pengesyoran domain merentas pembelajaran pemindahan berterusan dalam sistem pengesyoran Taobao

Artikel ini meneroka cara melaksanakan model pengesyoran merentas domain di bawah rangka kerja pembelajaran berterusan dalam industri, dan mencadangkan paradigma pengesyoran merentas domain baharu bagi pembelajaran pemindahan berterusan, menggunakan hasil perwakilan lapisan pertengahan bagi pra- model domain sumber terlatih sebagai Berdasarkan pengetahuan tambahan model domain sasaran, modul Penyesuai ringan telah direka untuk merealisasikan penghijrahan pengetahuan merentas domain, dan mencapai keputusan perniagaan yang ketara dalam penarafan produk yang disyorkan.
Latar Belakang
Dalam beberapa tahun kebelakangan ini, dengan penerapan model mendalam, kesan pengesyoran sistem pengesyoran dalam industri telah dipertingkatkan dengan ketara Dengan pengoptimuman berterusan model, hanya Ia menjadi lebih sukar untuk mengoptimumkan struktur dan ciri model bergantung pada data dalam senario. Pada platform e-dagang berskala besar seperti Taobao, untuk memenuhi pelbagai keperluan pengguna yang berbeza, terdapat satu siri senario pengesyoran dengan saiz yang berbeza, seperti pengesyoran aliran maklumat (anda mungkin menyukainya di halaman utama), produk yang bagus , pengesyoran selepas pembelian dan pengumpulan Senario ini berkongsi sistem produk Taobao, tetapi terdapat perbezaan yang ketara dalam kumpulan pemilihan produk tertentu, pengguna teras dan matlamat perniagaan, dan skala senario berbeza sangat berbeza. Senario "Barang Baik" kami ialah senario panduan beli-belah untuk produk terpilih Taobao Berbanding dengan pengesyoran aliran maklumat, carian utama dan senario lain, skalanya agak kecil. Oleh itu, cara menggunakan pembelajaran pemindahan, pengesyoran merentas domain dan kaedah lain untuk meningkatkan kesan model sentiasa Ia adalah salah satu perkara utama dalam mengoptimumkan model pengisihan barangan yang baik. Walaupun produk dan pengguna dalam senario perniagaan Taobao yang berbeza bertindih, disebabkan perbezaan ketara dalam senario, model kedudukan untuk senario besar seperti pengesyoran aliran maklumat tidak berfungsi dengan baik apabila digunakan secara langsung pada senario di mana barangan yang baik tersedia . Oleh itu, pasukan telah membuat banyak percubaan ke arah pengesyoran merentas domain, termasuk menggunakan satu siri kaedah sedia ada seperti pra-latihan dan penalaan halus, latihan bersama pelbagai senario dan pembelajaran global. Kaedah ini sama ada tidak cukup berkesan atau mempunyai beberapa masalah dalam aplikasi dalam talian sebenar. Projek pembelajaran pemindahan berterusan mencadangkan kaedah cadangan merentas domain baharu yang mudah dan berkesan untuk satu siri masalah dalam aplikasi kaedah ini dalam perniagaan. Kaedah ini
menggunakan hasil perwakilan lapisan pertengahan model domain sumber yang dipralatih secara berterusan sebagai pengetahuan tambahan tentang model domain sasarandan telah mencapai keputusan perniagaan yang ketara dalam penarafan cadangan produk yang baik di Taobao.
Versi terperinci artikel ini Pembelajaran Pemindahan Berterusan untuk Ramalan Kadar Klik Lalu Merentas Domain di Taobao telah diterbitkan di ArXiv https://arxiv.org/abs/2208.05728.Kaedah
▐ Kerja sedia ada dan kekurangannyaAnalisis kerja merentas domain sedia ada dalam bidang akademik dan industri Cross- Kerja berkaitan Pengesyoran Domain (CDR) boleh dibahagikan terutamanya kepada dua kategori: Pembelajaran Bersama dan Pra-latihan & Penalaan Halus. Antaranya, kaedah latihan bersama secara serentak mengoptimumkan model domain sumber (Domain Sumber) dan domain sasaran (Domain Sasaran). Walau bagaimanapun, kaedah jenis ini memerlukan pengenalan data domain sumber dalam latihan, dan sampel domain sumber biasanya bersaiz besar, sekali gus memakan sumber pengkomputeran dan penyimpanan yang besar. Sebaliknya, kaedah jenis ini perlu mengoptimumkan berbilang matlamat adegan pada masa yang sama, dan perbezaan antara adegan juga boleh membawa kesan negatif konflik matlamat Oleh itu, kaedah pra-latihan-penalaan halus mempunyai aplikasi yang lebih luas dalam banyak adegan industri.
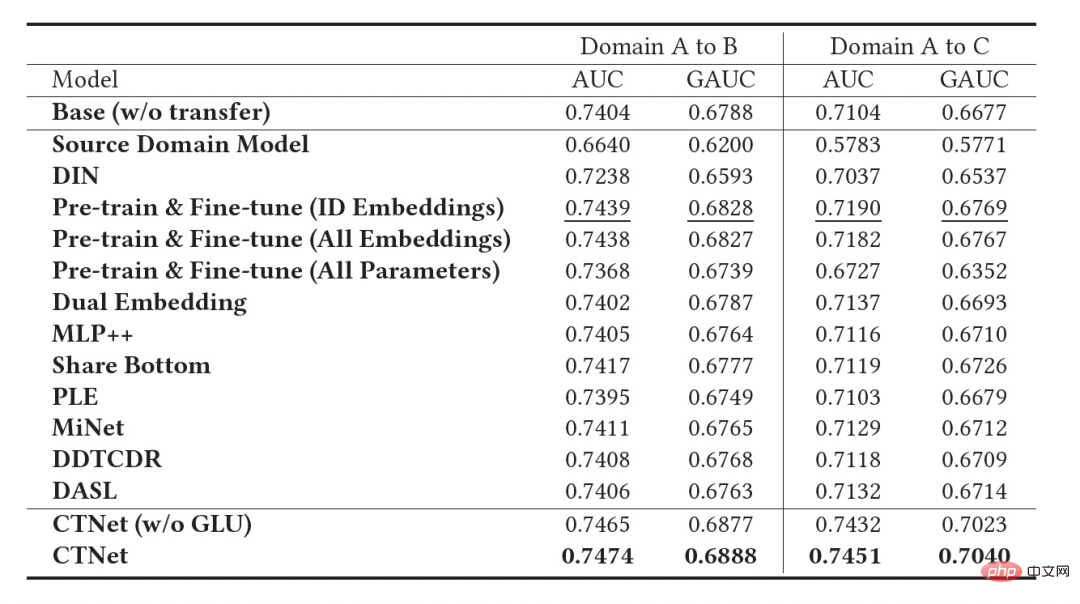
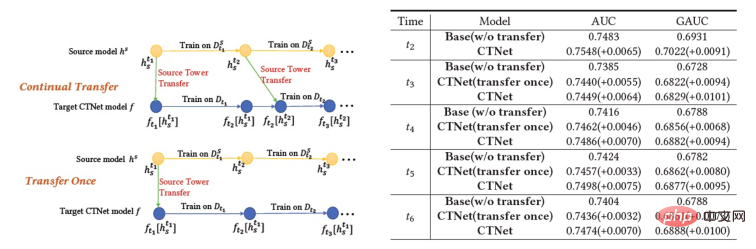
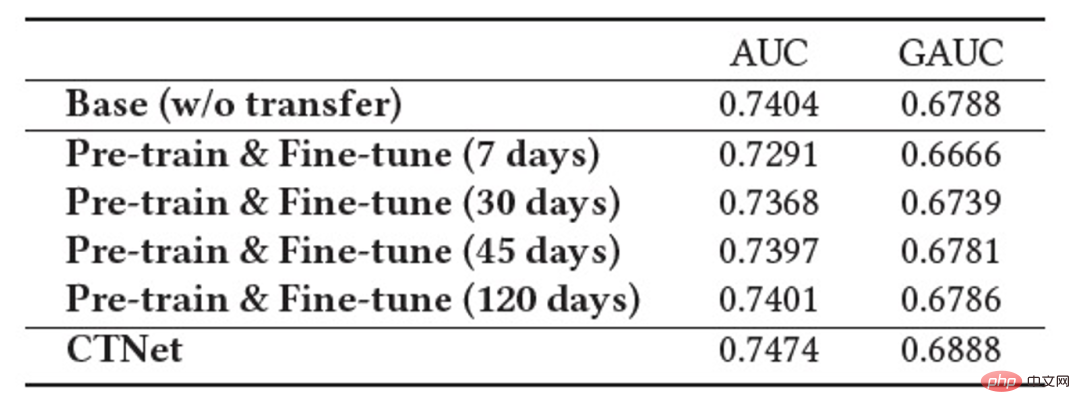
Ciri penting sistem pengesyoran industri ialah latihan model mengikut paradigma Pembelajaran Berterusan (Pembelajaran Berterusan) , iaitu model perlu menggunakan sampel terkini dan menggunakan kemas kini tambahan luar talian (Pembelajaran Tambahan) atau Pembelajaran Dalam Talian (Pembelajaran Dalam Talian) untuk mengetahui pengedaran data terkini. Untuk tugas pengesyoran merentas domain yang dikaji dalam artikel ini, model dalam domain sumber dan domain sasaran kedua-duanya mengikut kaedah latihan pembelajaran berterusan. Oleh itu, kami mencadangkan masalah baharu yang akan digunakan secara meluas dalam aplikasi akademik dan industri: Pembelajaran Pemindahan Berterusan , ditakrifkan sebagai berpindah dari satu domain yang berubah dari semasa ke semasa ke yang lain yang juga berubah dari semasa ke semasa. Kami percaya bahawa aplikasi pengesyoran merentas domain dan kaedah pembelajaran pemindahan sedia ada dalam sistem pengesyoran industri, enjin carian, pengiklanan pengiraan, dan lain-lain harus mengikut paradigma pembelajaran pemindahan berterusan, iaitu proses pemindahan hendaklah berterusan dan berkali-kali. Sebabnya ialah pengedaran data berubah dengan cepat, dan hanya penghijrahan berterusan boleh memastikan kesan penghijrahan yang stabil. Digabungkan dengan ciri-ciri sistem pengesyoran industri ini, kita boleh menemui masalah dalam aplikasi praktikal pra-latihan dan penalaan halus. Disebabkan oleh perbezaan pemandangan antara domain sumber dan domain sasaran, biasanya perlu menggunakan sejumlah besar sampel untuk mendapatkan hasil yang lebih baik dengan memperhalusi model domain sumber. Untuk mencapai pembelajaran pemindahan berterusan, kita perlu menggunakan model domain sumber terkini untuk memperhalusinya sekali-sekala, mengakibatkan kos latihan yang sangat besar Kaedah latihan ini juga sukar untuk digunakan dalam talian. Di samping itu, menggunakan bilangan sampel yang besar untuk penalaan halus juga boleh menyebabkan model domain sumber melupakan pengetahuan berguna yang disimpan, mengelakkan masalah pelupaan bencana dalam model menggunakan parameter model domain sumber untuk menggantikan parameter asal yang telah; yang dipelajari dalam domain sasaran juga mungkin Pengetahuan berguna yang diperoleh dari segi sejarah daripada model asal dibuang. Oleh itu, kita perlu mereka bentuk model pembelajaran pemindahan berterusan yang lebih cekap sesuai untuk senario pengesyoran industri. Artikel ini mencadangkan model yang mudah dan berkesan CTNet (Rangkaian Pemindahan Berterusan, rangkaian pemindahan berterusan) untuk menyelesaikan masalah di atas. Berbeza daripada kaedah pra-latihan-penalaan halus tradisional, idea teras CTNet ialah tidak boleh melupakan dan membuang semua pengetahuan yang diperolehi oleh model dalam sejarah, dan mengekalkan semua parameter model dan sasaran domain sumber asal model domain . Parameter ini menyimpan pengetahuan yang diperoleh melalui pembelajaran data sejarah yang sangat panjang (contohnya, model penarafan halus Taobao telah dilatih secara berperingkat secara berterusan selama lebih daripada dua tahun). CTNet mengguna pakai struktur menara berkembar yang ringkas dan menggunakan lapisan Penyesuai ringan untuk memetakan hasil perwakilan lapisan perantaraan model domain sumber yang dipralatih secara berterusan sebagai pengetahuan tambahan tentang model domain sasaran. Tidak seperti kaedah pra-latihan-penalaan halus yang memerlukan data penjejakan ke belakang untuk mencapai pembelajaran pemindahan berterusan, CTNet hanya memerlukan data tambahan untuk dikemas kini, dengan itu mencapai pembelajaran pemindahan berterusan yang cekap. Kaedah Tidak perlu menggunakan sejumlah besar sampel domain sumber Tidak terjejas oleh sasaran adegan domain sumber Hanya data tambahan diperlukan untuk mencapai Pembelajaran pemindahan berterusan Latihan bersama Tidak Tidak Ya Pra-latihan-Penalaan halus Ya Ya Tidak CTNet yang dicadangkan dalam artikel ini ialah adalah ialah Jadual 1: Perbandingan antara CTNet dan model pengesyoran merentas domain sedia ada Artikel ini meneroka isu baharu pembelajaran pemindahan berterusan: Memandangkan domain sumber dan domain sasaran yang terus berubah dari semasa ke semasa, pembelajaran pemindahan berterusan (Continual Transfer Learning) berharap dapat boleh Menggunakan domain sumber sejarah atau yang diperoleh pada masa ini dan pengetahuan domain sasaran untuk meningkatkan ketepatan ramalan dalam domain sasaran masa hadapan. Kami menggunakan masalah pembelajaran pemindahan berterusan pada tugas pengesyoran merentas domain Taobao. Tugasan ini mempunyai ciri-ciri berikut: Rajah 1: Gambar rajah penggunaan model Gambar di atas Menunjukkan penggunaan kaedah kami dalam talian. Sebelum detik Rajah 2: CTNet Rangkaian Migrasi Berterusan Seperti yang ditunjukkan dalam Rajah 2, model Rangkaian Pemindahan Berterusan (CTNet) yang kami cadangkan membenamkan semua model domain sumber dalam model kedudukan halus asal bagi domain sasaran parameter rangkaian membentuk struktur dua menara, di mana menara kiri CTNet adalah menara sumber dan menara kanan adalah menara sasaran. Berbeza daripada kaedah biasa yang hanya menggunakan skor pemarkahan akhir model domain sumber atau hanya menggunakan beberapa perwakilan cetek (seperti Benam), kami menggunakan rangkaian Penyesuai ringan untuk menggabungkan semua lapisan tersembunyi perantaraan model domain sumber MLP (Khususnya, hasil perwakilan Kunci untuk meningkatkan prestasi CTNet adalah dengan menggunakan pemindahan maklumat perwakilan mendalam dalam MLP. Berdasarkan idea Unit Linear Berpagar (GLU), rangkaian Penyesuai menggunakan lapisan linear berpagar, yang boleh melaksanakan pemilihan ciri penyesuaian ciri domain sumber dengan berkesan, dan maklumat yang tidak konsisten dengan model akan dipindahkan ciri pemandangan akan dipindahkan boleh ditapis. Memandangkan model domain sumber terus menggunakan data penyeliaan domain sumber terkini untuk pra-latihan berterusan, semasa proses latihan kami, Source Tower juga akan terus memuatkan parameter model domain sumber terkini dan kekal tetap semasa proses perambatan belakang , memastikan kemajuan cekap pembelajaran pemindahan berterusan. Oleh itu, model CTNet sangat sesuai untuk paradigma pembelajaran berterusan, membolehkan model domain sasaran mempelajari secara berterusan pengetahuan terkini yang disediakan oleh model domain sumber untuk menyesuaikan diri dengan perubahan pengedaran data terkini. Pada masa yang sama, kerana model hanya dilatih pada data domain sasaran, ia memastikan model tidak terjejas oleh objektif latihan domain sumber, dan tidak memerlukan latihan data domain sumber sama sekali, mengelakkan jumlah storan yang besar dan overhed pengiraan. Di samping itu, struktur rangkaian sedemikian menggunakan kaedah reka bentuk tambahan, supaya dimensi lapisan MLP model asal tidak perlu diubah semasa proses migrasi Menara Sasaran dimulakan sepenuhnya oleh model dalam talian domain sasaran asal, mengelakkan Inisialisasi semula rawak lapisan MLP Ia boleh memastikan bahawa kesan model asal tidak rosak ke tahap yang paling besar, dan hanya memerlukan kurang data tambahan untuk mendapatkan hasil yang baik, merealisasikan permulaan model yang panas. Kami mentakrifkan model domain sumber sebagai Rajah 3: Latihan CTNet Jadual 2: Keputusan percubaan luar talian Seperti yang ditunjukkan dalam jadual di atas, kami mempunyai set data pengeluaran yang sepadan dalam dua sub-senario (Domain B dan C dalam jadual) dengan perniagaan barangan yang baik Satu siri percubaan luar talian telah dijalankan di tapak web, di mana domain sumber (Domain A dalam jadual) ialah senario pengesyoran aliran maklumat halaman utama. Dapat dilihat bahawa penggunaan langsung pengesyoran aliran maklumat (anda mungkin menyukainya di halaman utama) keputusan pemarkahan model (Model Domain Sumber dalam jadual) tidak berkesan dalam perniagaan barangan yang baik Berbanding dengan model volum penuh dalam talian , nilai mutlak ialah GAUC-5.88 % dan GAUC-9.06%, membuktikan perbezaan antara senario. Kami juga membandingkan satu siri kaedah Garis Dasar pengesyoran merentas domain tradisional, termasuk kaedah pra-latihan-penalaan halus dan kaedah latihan bersama (seperti MLP++, PLE, MiNet, DDTCDR, DASL, dll.) , dan CTNet yang dicadangkan dengan ketara mengatasi kaedah sedia ada pada kedua-dua set data. Berbanding dengan model utama dalam talian penuh, CTNet mencapai peningkatan ketara dalam GAUC masing-masing sebanyak +1.0% dan +3.6% pada dua set data. Kami selanjutnya menganalisis kelebihan pemindahan berterusan berbanding dengan pemindahan tunggal melalui eksperimen. Di bawah rangka kerja CTNet, peningkatan kesan yang dibawa oleh satu pemindahan akan dilemahkan dengan kemas kini tambahan model, manakala pembelajaran pemindahan berterusan boleh memastikan peningkatan yang stabil bagi kesan model. Rajah 4: Kelebihan pembelajaran pemindahan berterusan berbanding pemindahan tunggal Jadual berikut menunjukkan kesan pra-latihan-penalaan halus Kami menggunakan model domain sumber lengkap untuk melatih data domain sasaran. Disebabkan perbezaan antara medan, bilangan sampel yang sangat besar (seperti sampel 120 hari) diperlukan untuk melaraskan kesan model pada tahap yang setanding dengan model Pangkalan dalam talian penuh. Untuk mencapai pembelajaran pemindahan berterusan, kita perlu menyesuaikan semula menggunakan model domain sumber terkini pada selang masa yang tetap. Kos yang besar bagi setiap pelarasan juga menjadikan kaedah ini tidak sesuai untuk pembelajaran pemindahan berterusan. Selain itu, kaedah ini tidak mengatasi model asas tanpa migrasi dari segi kesan Sebab utama ialah penggunaan latihan sampel domain sasaran secara besar-besaran juga menyebabkan model melupakan pengetahuan domain sumber asal, dan kesan model akhir yang diperolehi oleh. latihan adalah serupa dengan Kesan latihan hanya pada data domain sasaran. Di bawah paradigma pra-latihan-penalaan halus, memuatkan hanya beberapa parameter Pembenaman adalah lebih baik daripada menggunakan semula semua parameter (seperti ditunjukkan dalam Jadual 2). Jadual 3: Kesan latihan pada domain sasaran menggunakan model domain sumber pra-latihan CTNet akan disiapkan paling awal pada penghujung 2021, dan akan berada dalam talian sepenuhnya pada Februari 2022 untuk perniagaan cadangan produk yang bagus. Berbanding model penuh generasi sebelumnya, peningkatan ketara dalam penunjuk perniagaan telah dicapai dalam dua senario cadangan: Senario B: CTR+2.5%, pembelian tambahan +6.7%, bilangan transaksi +3.4%, GMV+7.7% Senario C: CTR+12.3%, tempoh penginapan +8.8%, pembelian tambahan +10.9%, bilangan transaksi +30.9%, GMV+31.9% CTNet menggunakan struktur rangkaian selari Untuk menjimatkan sumber pengkomputeran, kami berkongsi beberapa parameter dan hasil lapisan Perhatian, supaya bahagian yang sama pada lapisan Perhatian Menara Sumber dan Menara Sasaran hanya perlu dikira sekali. Berbanding dengan model Base, masa tindak balas dalam talian (RT) CTNet pada asasnya adalah sama. Artikel ini meneroka cara melaksanakan model pengesyoran merentas domain di bawah rangka kerja pembelajaran berterusan dalam industri dan mencadangkan domain silang baharu model pengesyoran yang dipanggil pembelajaran pemindahan berterusan Paradigma pengesyoran domain menggunakan hasil perwakilan lapisan perantaraan model domain sumber yang telah dilatih secara berterusan sebagai pengetahuan tambahan tentang model domain sasaran. Modul Penyesuai ringan direka untuk merealisasikan pemindahan pengetahuan merentas domain dan mencapai kedudukan pengesyoran produk yang baik mencapai hasil perniagaan yang ketara. Walaupun kaedah ini dilaksanakan untuk ciri perniagaan barangan yang baik, ia juga merupakan kaedah pemodelan yang agak umum Kaedah dan idea pemodelan yang berkaitan boleh digunakan untuk mengoptimumkan banyak senario perniagaan lain yang serupa. Memandangkan model domain sumber pra-latihan berterusan sedia ada bagi CTNet hanya menggunakan senario pengesyoran aliran maklumat, pada masa hadapan kami akan mempertimbangkan untuk menaik taraf model domain sumber pra-latihan berterusan kepada model pra-latihan pembelajaran domain penuh yang merangkumi pengesyoran, carian, domain persendirian dan lebih banyak senario lain. Kami ialah pasukan algoritma barangan yang bagus dengan kandungan teknologi Taobao. Produk yang baik disyorkan oleh Taobao berdasarkan dari mulut ke mulut, dan direka bentuk untuk membantu pengguna menemui produk yang baik melalui adegan panduan membeli-belah. Pasukan ini bertanggungjawab untuk mengoptimumkan algoritma pautan penuh untuk pengesyoran produk dan perniagaan pengesyoran kandungan video pendek untuk meningkatkan keupayaan perlombongan produk yang berfaedah dan keupayaan panduan membeli-belah saluran. Arahan teknikal utama semasa ialah pengesyoran merentas domain pembelajaran pemindahan berterusan, pembelajaran tidak berat sebelah, pemodelan pautan penuh sistem pengesyoran, pemodelan jujukan, dsb. Sambil mencipta nilai perniagaan, kami juga telah menerbitkan beberapa kertas kerja di persidangan antarabangsa seperti SIGIR Hasil utama termasuk PDN, UMI, CDAN, dll.
▐ Definisi Masalah
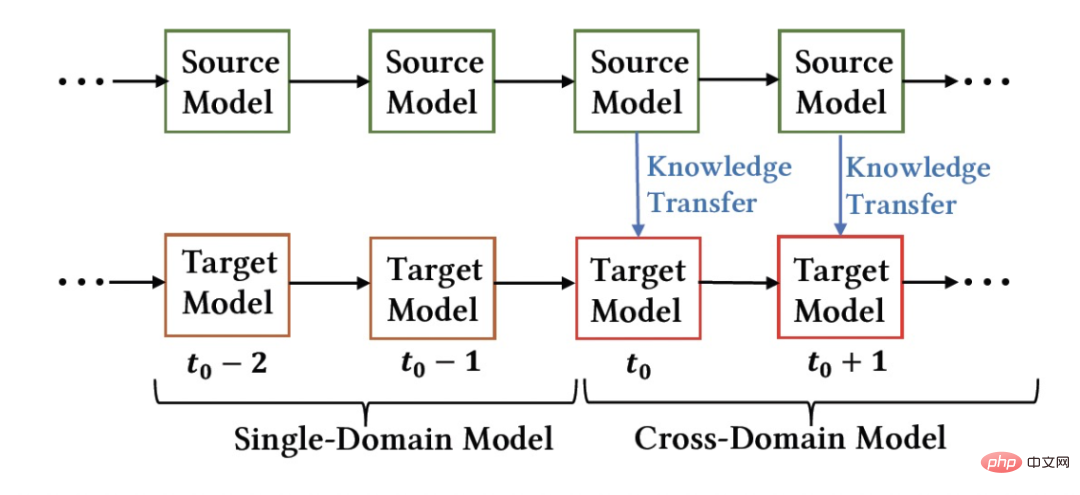
 , model domain sumber dan model domain sasaran dilatih secara individu dan secara berterusan secara berperingkat hanya menggunakan data penyeliaan adegan masing-masing. Bermula dari detik
, model domain sumber dan model domain sasaran dilatih secara individu dan secara berterusan secara berperingkat hanya menggunakan data penyeliaan adegan masing-masing. Bermula dari detik 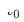 , kami menggunakan model pengesyoran merentas domain CTNet pada domain sasaran Model ini akan terus meningkat pada data domain sasaran tanpa melupakan pengetahuan yang diperoleh dalam latihan secara berterusan memindahkan pengetahuan daripada model domain sumber terkini.
, kami menggunakan model pengesyoran merentas domain CTNet pada domain sasaran Model ini akan terus meningkat pada data domain sasaran tanpa melupakan pengetahuan yang diperoleh dalam latihan secara berterusan memindahkan pengetahuan daripada model domain sumber terkini. ▐ Model Rangkaian Migrasi Berterusan (CTNet)
 daripada maklumat interaksi ciri peringkat tinggi yang terkandung secara mendalam dalam MLP domain sumber) dipetakan ke domain pengesyoran sasaran dan Tambahkan hasil pada lapisan Menara Sasaran yang sepadan
daripada maklumat interaksi ciri peringkat tinggi yang terkandung secara mendalam dalam MLP domain sumber) dipetakan ke domain pengesyoran sasaran dan Tambahkan hasil pada lapisan Menara Sasaran yang sepadan  (rumus di bawah mewakili kes
(rumus di bawah mewakili kes  ).
). 
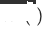 , model domain sasaran disyorkan domain tunggal asal ialah
, model domain sasaran disyorkan domain tunggal asal ialah 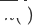 , model pengesyoran domain merentas domain sasaran yang baru digunakan ialah
, model pengesyoran domain merentas domain sasaran yang baru digunakan ialah 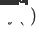 dan
dan 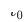 ialah pengerahan model pengesyoran merentas domain masa dalam talian, yang Model sentiasa dikemas kini secara berperingkat sehingga masa
ialah pengerahan model pengesyoran merentas domain masa dalam talian, yang Model sentiasa dikemas kini secara berperingkat sehingga masa 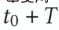 . Parameter Penyesuai, Menara Sumber dan Menara Sasaran masing-masing ialah
. Parameter Penyesuai, Menara Sumber dan Menara Sasaran masing-masing ialah 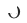 ,
, 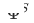 dan
dan 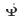 . Proses latihan CTNet adalah seperti berikut:
. Proses latihan CTNet adalah seperti berikut: 
Eksperimen▐ Kesan luar talian
▐ Kesan dalam talian
Ringkasan dan Tinjauan
Pengenalan pasukan
Atas ialah kandungan terperinci Aplikasi model pemeringkatan pengesyoran domain merentas pembelajaran pemindahan berterusan dalam sistem pengesyoran Taobao. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
