
 Peranti teknologi
AI
Model generasi baharu OpenAI ialah letupan sumber terbuka! Lebih pantas dan lebih kuat daripada Diffusion, karya alumnus Tsinghua Song Yang
Peranti teknologi
AI
Model generasi baharu OpenAI ialah letupan sumber terbuka! Lebih pantas dan lebih kuat daripada Diffusion, karya alumnus Tsinghua Song Yang
Model generasi baharu OpenAI ialah letupan sumber terbuka! Lebih pantas dan lebih kuat daripada Diffusion, karya alumnus Tsinghua Song Yang

Bidang penjanaan imej nampaknya berubah lagi.
Sebentar tadi, OpenAI sumber terbuka model konsisten yang lebih pantas dan lebih baik daripada model penyebaran:
Anda boleh menjana imej berkualiti tinggi tanpa latihan lawan!
Sebaik sahaja berita blockbuster ini dikeluarkan, ia segera meletupkan kalangan akademik.

Walaupun kertas itu sendiri dikeluarkan secara ringkas pada bulan Mac, pada masa itu secara amnya dipercayai bahawa ia hanyalah penyelidikan canggih OpenAI dan butiran tidak akan benar-benar didedahkan kepada umum.

Saya tidak sangka sumber terbuka akan datang secara langsung kali ini. Beberapa netizen serta-merta mula menguji kesan dan mendapati ia hanya mengambil masa kira-kira 3.5 saat untuk menjana kira-kira 64 imej 256×256:
Permainan tamat!

Ini adalah kesan imej yang dihasilkan oleh netizen ini, yang kelihatan cukup bagus:

Juga Netizen bergurau: Kali ini OpenAI akhirnya dibuka!

Perlu dinyatakan bahawa pengarang pertama kertas kerja, saintis OpenAI Song Hao, adalah alumni Tsinghua Pada usia 16 tahun, beliau memasuki Tsinghua Matematik dan Fizikal Kelas Asas Sains melalui Program Kepimpinan.
Mari kita lihat jenis penyelidikan OpenAI yang bersumberkan terbuka kali ini.
Apakah jenis penyelidikan blockbuster telah menjadi sumber terbuka?
Sebagai AI penjanaan imej, ciri terbesar Model Konsistensi ialah ia pantas dan baik.
Berbanding dengan model resapan, ia mempunyai dua kelebihan utama:
Pertama, ia boleh menjana secara langsung sampel imej berkualiti tinggi tanpa latihan lawan.
Kedua, berbanding model resapan yang mungkin memerlukan ratusan atau bahkan ribuan lelaran, model ketekalan boleh mengendalikan pelbagai tugas imej dalam hanya satu atau dua langkah -
termasuk pewarnaan, Denoising , pemarkahan super, dsb., semuanya boleh dilakukan dalam beberapa langkah tanpa memerlukan latihan yang jelas untuk tugasan ini. (Sudah tentu, jika pembelajaran beberapa pukulan dilakukan, kesan penjanaan akan menjadi lebih baik)

Jadi bagaimana model konsistensi mencapai kesan ini?
Dari sudut pandangan prinsip, kelahiran model ketekalan adalah berkaitan dengan model penyebaran generasi ODE (ordinary differential equation).
Seperti yang dapat dilihat dalam rajah, ODE akan mula-mula menukar data imej kepada hingar langkah demi langkah, dan kemudian melakukan penyelesaian terbalik untuk belajar menjana imej daripada hingar.
Dalam proses ini, pengarang cuba memetakan mana-mana titik pada trajektori ODE (seperti Xt, Xt dan Xr) kepada asalnya (seperti X0) untuk pemodelan generatif.
Seterusnya, model yang dipetakan ini dinamakan model ketekalan kerana output mereka semua pada titik yang sama pada trajektori yang sama:

Berdasarkan idea ini ialah model ketekalan tidak lagi perlu melalui lelaran yang panjang untuk menghasilkan imej yang agak berkualiti tinggi, tetapi boleh dijana dalam satu langkah.
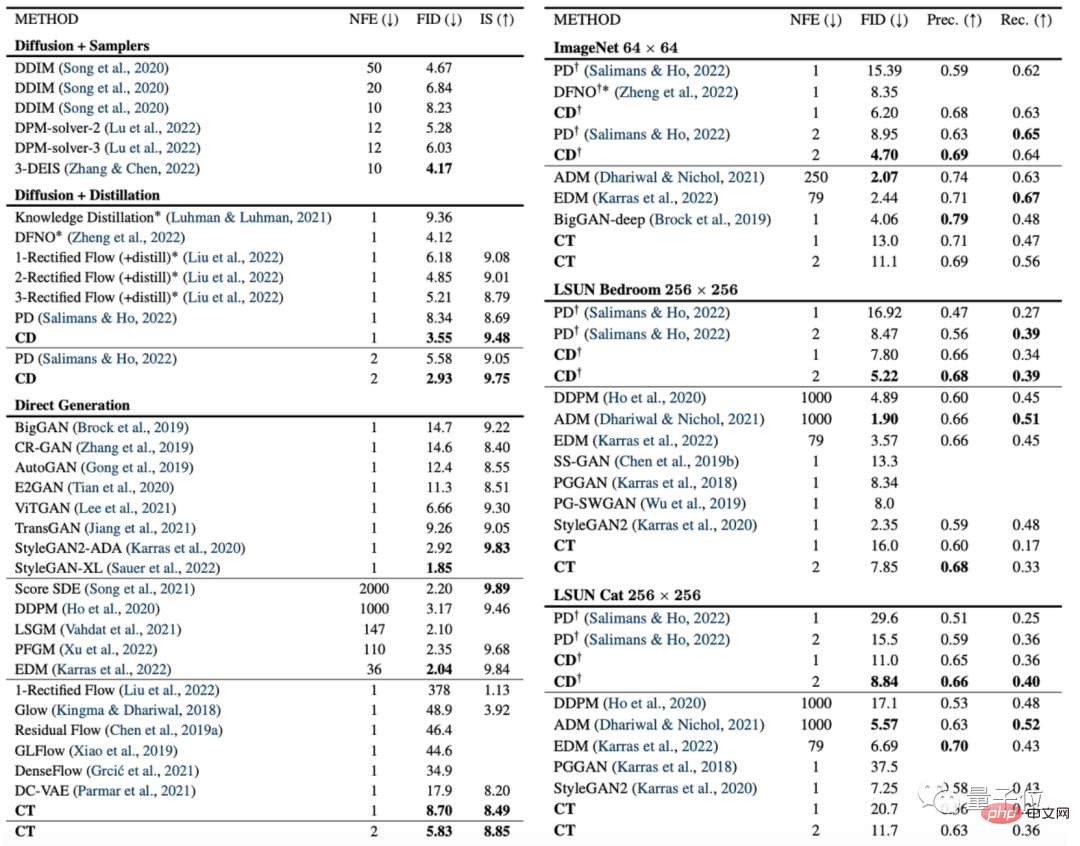
Rajah berikut ialah perbandingan model ketekalan (CD) dan model resapan (PD) pada indeks penjanaan imej FID.
Antaranya, PD ialah singkatan kepada penyulingan progresif (progressive distillation), kaedah model difusi terkini yang dicadangkan oleh Stanford dan Google Brain tahun lepas, dan CD (consistency distillation) ialah kaedah penyulingan konsisten.
Ia boleh dilihat bahawa kesan penjanaan imej model konsisten adalah lebih baik daripada model resapan pada hampir semua set data Satu-satunya pengecualian ialah set data bilik 256×256:

Selain itu, penulis juga membandingkan model seperti model resapan, model konsistensi dan GAN pada pelbagai set data lain:
Namun, sesetengah netizen menyebut bahawa imej yang dijana oleh model ketekalan AI sumber terbuka masih terlalu kecil:
Memang menyedihkan model sumber terbuka ini The imej yang dijana oleh versi masih terlalu kecil Ia akan menjadi sangat menarik jika versi sumber terbuka yang menjana imej yang lebih besar boleh disediakan.
Beberapa netizen juga membuat spekulasi bahawa OpenAI mungkin belum dilatih lagi. Tetapi mungkin selepas latihan, kita mungkin tidak dapat kod (kepala anjing manual).
Walau bagaimanapun, mengenai kepentingan kerja ini, TechCrunch berkata:
Jika anda mempunyai sekumpulan GPU, kemudian gunakan model resapan untuk mengulang lebih daripada 1,500 kali dalam satu atau dua minit, dan kesan penjanaan imej pastinya sangat baik
Tetapi jika anda ingin menjana imej dalam masa nyata pada telefon anda atau semasa perbualan sembang, jelas sekali model penyebaran bukanlah pilihan terbaik.
Model ketekalan ialah langkah penting OpenAI seterusnya.
Saya berharap OpenAI akan membuka sumber gelombang AI penjanaan imej dengan resolusi yang lebih tinggi~
Alumnus Tsinghua Song Hao ialah pengarang kertas kerja
Song Hao, pengarang pertama kertas itu, kini merupakan seorang saintis penyelidikan di OpenAI.

Ketika dia berumur 14 tahun, dia telah dipilih ke dalam "Program Kepimpinan Seratus Tahun Baru Universiti Tsinghua" dengan undian sebulat suara daripada 17 hakim. Dalam peperiksaan kemasukan kolej pada tahun berikutnya, beliau menjadi penjaring terbanyak dalam sains di Bandar Lianyungang dan berjaya dimasukkan ke Universiti Tsinghua.
Pada 2016, Song Yang lulus dari kelas asas matematik dan fizik Universiti Tsinghua, dan kemudian pergi ke Stanford untuk melanjutkan pelajaran. Pada 2022, Song Yang menerima PhD dalam sains komputer daripada Stanford dan kemudian menyertai OpenAI.
Semasa PhDnya, kertas pertamanya "Pemodelan Generatif Berasaskan Skor melalui Persamaan Pembezaan Stokastik" turut memenangi Anugerah Kertas Cemerlang ICLR 2021.

Menurut maklumat di laman utama peribadinya, mulai Januari 2024, Song Yang secara rasmi akan menyertai Jabatan Elektronik dan Sains Matematik Pengiraan di California Institute of Technology sebagai pembantu profesor.
Alamat projek:
https://www.php.cn/link/4845b84d63ea5fa8df6268b8d1616a8f
Alamat kertas:
Alamat kertas: https://www.php.cn/link/5f25fbe144e4a81a1b0080b6c1032778
Pautan rujukan:
[1]https://twitter.com/alfrededpl148/1816pl/status/1818pl18
Atas ialah kandungan terperinci Model generasi baharu OpenAI ialah letupan sumber terbuka! Lebih pantas dan lebih kuat daripada Diffusion, karya alumnus Tsinghua Song Yang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
