

Kemunculan "Divide Everything" Meta membuatkan ramai orang berseru bahawa CV tidak lagi wujud.
Berdasarkan model ini, ramai netizen telah melakukan kerja lanjutan, seperti Grounded SAM.
Menggunakan Stable Diffusion, Whisper dan ChatGPT bersama-sama, anda boleh menukar anjing menjadi monyet melalui suara.

Dan kini, bukan sahaja suara, anda boleh membahagikan semuanya di mana-mana sekaligus melalui gesaan berbilang modal .
Bagaimana untuk melakukannya secara khusus?
Klik tetikus untuk terus memilih kandungan yang dibahagikan.

Buka mulut dan katakan sesuatu.

Hanya leret dan pakej emotikon lengkap akan ada.

Anda juga boleh membahagikan video.

Penyelidikan terkini tentang SEEM telah disiapkan bersama oleh sarjana dari University of Wisconsin-Madison, Microsoft Research dan institusi lain .
Segmen imej dengan mudah menggunakan SEEM menggunakan pelbagai jenis isyarat, isyarat visual (titik, penanda, kotak, coretan dan serpihan imej), serta isyarat lisan (teks dan audio).

Alamat kertas: https://arxiv.org/pdf/2304.06718.pdf
Perkara yang menarik tentang tajuk kertas ini ialah ia hampir sama dengan nama filem fiksyen sains Amerika "Everywhere All at Once" yang akan dikeluarkan pada 2022.

Saintis NVIDIA Jim Fan berkata bahawa Oscar untuk tajuk kertas terbaik diberikan kepada "Segment Everything Everywhere All at Once"
Mempunyai antara muka spesifikasi tugas yang bersatu dan serba boleh adalah kunci untuk meningkatkan model asas yang besar. Gesaan multimodal adalah cara masa depan.

Selepas membaca kertas itu, netizen berkata bahawa CV kini akan mula menerima model besar pelajar?

telah diilhamkan oleh pembangunan antara muka universal berasaskan segera untuk LLM , penyelidik mencadangkan SEEM.
Seperti yang ditunjukkan dalam rajah, model SEEM boleh melaksanakan sebarang tugas pembahagian dalam set terbuka tanpa petunjuk, seperti pembahagian semantik, pembahagian contoh dan pembahagian panorama.
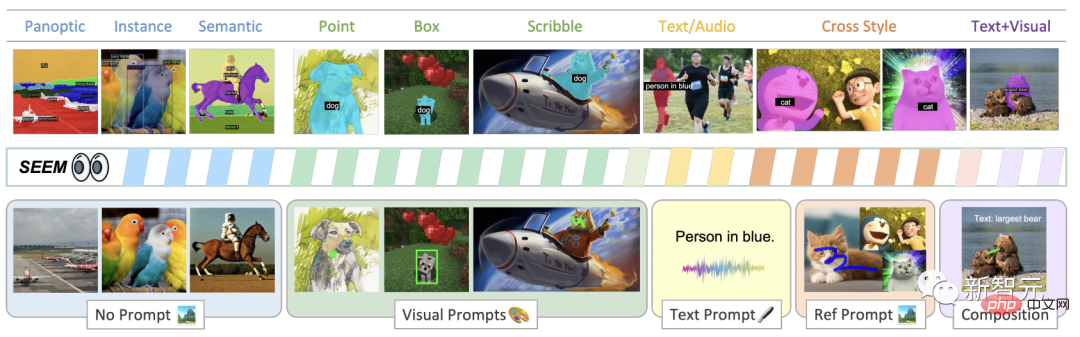
Selain itu, ia menyokong sebarang gabungan gesaan kawasan visual, tekstual dan rujukan, membenarkan pemisahan Rujukan yang serba boleh dan interaktif.
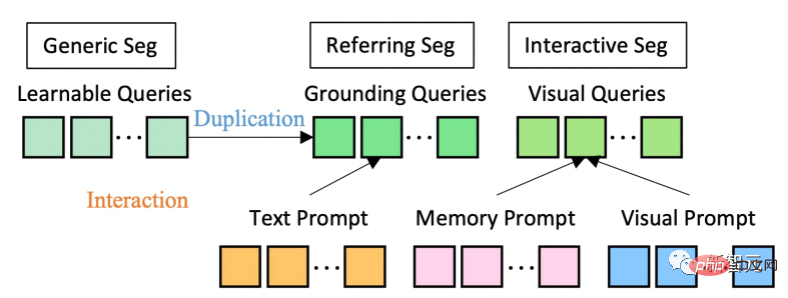
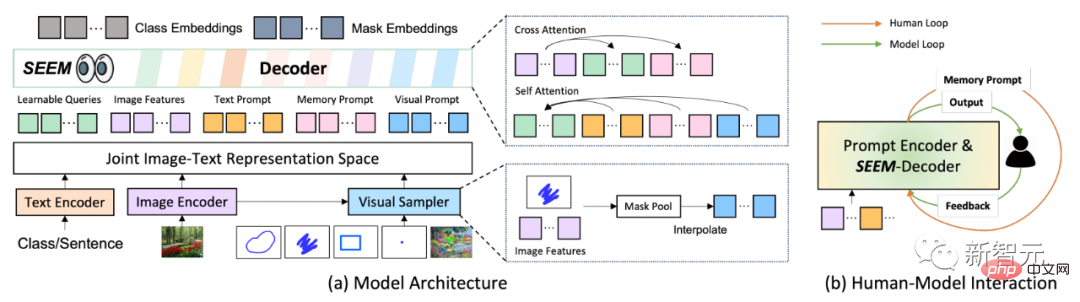
Dari segi seni bina model, SEEM menggunakan seni bina pengekod-penyahkod biasa. Apa yang menjadikannya unik ialah interaksi kompleks antara pertanyaan dan gesaan.
Ciri dan isyarat dikodkan ke dalam ruang visual-semantik bersama oleh pengekod atau pensampel yang sepadan.
Pertanyaan boleh dipelajari dimulakan secara rawak, dan penyahkod SEEM menerima pertanyaan boleh dipelajari, ciri imej dan pembayang teks sebagai input dan output, termasuk pembenaman kelas dan topeng untuk topeng dan ramalan semantik.
Perlu dinyatakan bahawa model SEEM mempunyai beberapa pusingan interaksi. Setiap pusingan terdiri daripada kitaran manual dan kitaran model.
Dalam gelung manual, output topeng lelaran sebelumnya diterima secara manual dan maklum balas positif untuk pusingan penyahkodan seterusnya diberikan melalui isyarat visual. Dalam gelung model, model menerima dan mengemas kini isyarat memori untuk ramalan masa hadapan.
Melalui SEEM, diberikan gambar trak Optimus Prime, anda boleh membahagikan Optimus Prime pada mana-mana imej sasaran .

Jana topeng daripada teks yang dimasukkan pengguna untuk pembahagian satu klik.

Selain itu, SEEM boleh menambah semantik yang serupa pada imej sasaran dengan hanya mengklik atau graffiti pada objek yang dirujuk adalah bersegmen.

Selain itu, SEEM memahami perhubungan ruang penyelesaian dengan baik. Selepas zebra di barisan kiri atas dicoretkan, zebra paling kiri juga akan dibahagikan.

SEEM juga boleh merujuk imej kepada topeng video, yang boleh membahagikan video dengan sempurna tanpa sebarang latihan data video.


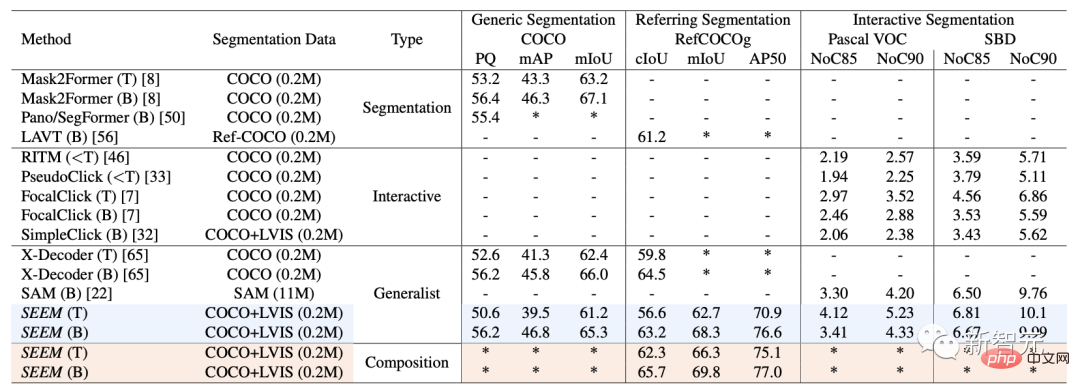
Pada set data dan tetapan, SEEM Three set data telah dilatih: segmentasi panorama, segmentasi rujukan dan segmentasi interaktif.
Segmentasi Interaktif
Mengenai segmentasi interaktif, penyelidik membandingkan SEEM dengan model segmentasi interaktif terkini.
Sebagai model umum, SEEM telah mencapai prestasi yang setanding dengan RITM, SimpleClick, dsb. Dan ia mencapai prestasi yang hampir sama dengan SAM juga menggunakan 50 lebih data bersegmen untuk latihan.
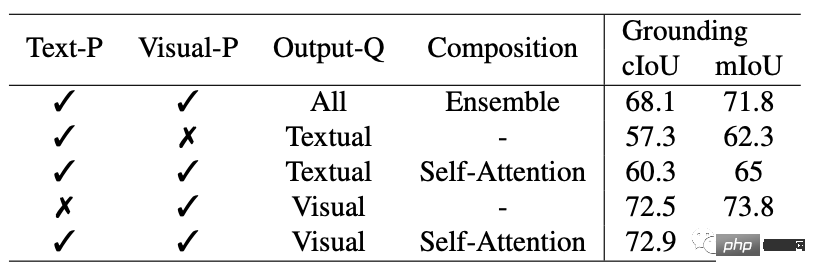
Terutama, tidak seperti model interaktif sedia ada, SEEM ialah yang pertama menyokong bukan sahaja tugasan segmentasi klasik tetapi juga pelbagai input berbilang modal, termasuk teks , titik, coretan, kotak sempadan dan imej, menyediakan keupayaan gabungan yang berkuasa.
Universal Split
Lulus kepada semua Satu set parameter yang telah dilatih untuk tugasan pembahagian, yang membolehkan penyelidik menilai secara langsung prestasinya pada set data pembahagian biasa.
SEEM mencapai paparan panorama, contoh dan prestasi segmentasi semantik yang lebih baik.
Penyelidik mempunyai empat matlamat yang diingini untuk SEEM:
1 : Dengan memperkenalkan enjin pembayang serba boleh untuk mengendalikan pelbagai jenis pembayang, termasuk mata, kotak, grafiti, topeng, teks dan kawasan rujukan imej lain
2 ruang visual-semantik bersama, menggabungkan isyarat visual dan teks untuk penaakulan pertanyaan segera; 🎜>
4. Kesedaran semantik: Pembahagian kosa kata terbuka dicapai dengan mengekod pertanyaan teks dan tag topeng menggunakan pengekod teks.
Perbezaan antara
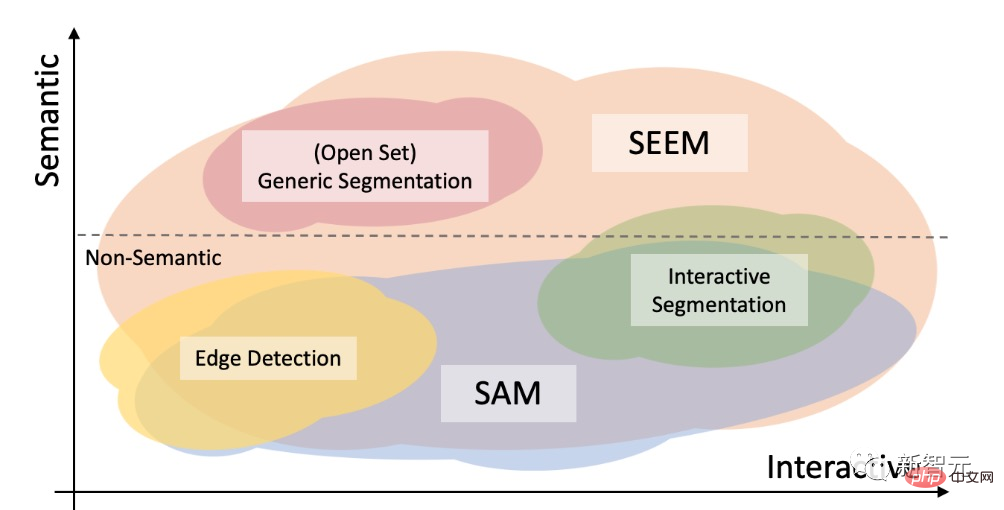
Model SAM yang dicadangkan oleh Meta boleh dinyatakan dalam rangka kerja bersatu Mata pengekod gesaan, kotak sempadan, dan ayat boleh membahagikan objek dengan satu klik.
SAM mempunyai fleksibiliti yang luas, iaitu, ia mempunyai keupayaan migrasi sifar sampel, yang cukup untuk menampung pelbagai kes penggunaan Dengan latihan tambahan, ia boleh digunakan di luar kotak dalam domain pengimejan baharu, sama ada foto bawah air atau mikroskop sel. 
Penyelidik membincangkan keupayaan interaktif dan semantik bagi tiga tugasan segmentasi (pengesanan tepi, set terbuka dan segmentasi interaktif) Perbandingan dibuat antara SEEM dan SAM. 
Segmentasi set terbuka juga memerlukan semantik peringkat tinggi dan tidak memerlukan interaksi.
Berbanding dengan SAM, SEEM merangkumi julat interaksi dan tahap semantik yang lebih luas.
SAM hanya menyokong jenis interaksi terhad, seperti titik dan kotak sempadan serta mengabaikan tugas semantik tinggi kerana ia tidak mengeluarkan label semantik itu sendiri.
Untuk SEEM, penyelidik telah menyerlahkan dua sorotan:
Pertama, SEEM mempunyai pengekod gesaan bersatu yang menggabungkan semua isyarat Visual dan lisan dikodkan ke dalam ruang perwakilan bersama. Oleh itu, SEEM boleh menyokong penggunaan yang lebih umum dan ia berpotensi diperluaskan kepada gesaan tersuai.
Kedua, SEEM melakukan tugas yang baik dalam menutup teks dan mengeluarkan ramalan sedar semantik.
Xueyan Zou, pengarang pertama makalah
Beliau kini merupakan pelajar kedoktoran di Jabatan Sains Komputer di Universiti Wisconsin-Madison, di bawah seliaan Profesor Yong Jae Lee.
Sebelum ini, Zou menghabiskan tiga tahun di Universiti California, Davis, di bawah bimbingan mentor yang sama dan bekerja rapat dengan Dr. Fanyi Xiao.
Beliau menerima ijazah sarjana muda dari Hong Kong Baptist University, diselia oleh Profesor PC Yuen dan Profesor Chu Xiaowen.

Jianwei Yang

Yang ialah penyelidik kanan dalam kumpulan pembelajaran mendalam Microsoft Research di Redmond, diselia oleh Dr. Jianfeng Gao.
Penyelidikan Yang tertumpu terutamanya pada penglihatan komputer, penglihatan dan bahasa serta pembelajaran mesin. Beliau memfokuskan pada tahap pemahaman visual berstruktur yang berbeza dan bagaimana ia boleh dieksploitasi selanjutnya untuk interaksi pintar dengan manusia melalui bahasa dan penjelmaan alam sekitar.
Sebelum menyertai Microsoft pada Mac 2020, Yang menerima PhD dalam Sains Komputer dari Georgia Tech's School of Interactive Computing, di mana penasihatnya ialah Profesor Devi Parikh, dan dia juga bekerja dengan Profesor Dhruv Batra Bekerjasama rapat.
Gao Jianfeng

Gao Jianfeng ialah seorang saintis dan profesor bersekutu yang terkenal di Microsoft Research President, ahli IEEE, dan ACM Distinguished Member.
Pada masa ini, Gao Jianfeng mengetuai kumpulan pembelajaran mendalam. Misi kumpulan itu adalah untuk memajukan teknologi terkini dalam pembelajaran mendalam dan aplikasinya kepada bahasa semula jadi dan pemahaman imej, dan untuk membuat kemajuan dalam model dan kaedah perbualan.
Penyelidikan terutamanya merangkumi model bahasa saraf untuk pemahaman dan penjanaan bahasa semula jadi, pengkomputeran simbolik saraf, asas dan pemahaman bahasa visual, kecerdasan buatan perbualan, dsb.
Dari 2014 hingga 2018, Gao Jianfeng berkhidmat sebagai pengurus penyelidikan rakan kongsi untuk kecerdasan buatan komersial di Jabatan Kecerdasan Buatan dan Penyelidikan Microsoft dan Pusat Teknologi Pembelajaran Dalam (DLTC) Redmond Microsoft Research .
Dari 2006 hingga 2014, Gao Jianfeng berkhidmat sebagai ketua penyelidik dalam kumpulan pemprosesan bahasa semula jadi.
Yong Jae Lee

Lee ialah seorang saintis komputer di Universiti dari Washington, Madison Profesor Madya di Jabatan Sains.
Beliau menghabiskan masa setahun sebagai pengajar pelawat dalam kecerdasan buatan di Cruise sebelum menyertai UW-Madison pada musim gugur 2021. Sebelum itu, beliau berada di University of California, Davis Served sebagai penolong dan profesor madya selama 6 tahun.
Beliau juga menghabiskan setahun sebagai penyelidik pasca doktoral di Institut Robotik di Universiti Carnegie Mellon.
Beliau menerima PhD dari University of Texas di Austin pada Mei 2012 dengan Kristen Grauman, dan dari University of Illinois di Urbana-Champaign pada Mei 2006 Memperoleh ijazah sarjana muda.
Beliau juga bekerja sebagai pelatih musim panas di Microsoft Research bersama Larry Zitnick dan Michael Cohen.
Pada masa ini, penyelidikan Lee memfokuskan pada penglihatan komputer dan pembelajaran mesin. Lee amat berminat untuk mencipta sistem pengecaman visual yang berkuasa yang boleh memahami data visual dengan pengawasan manusia yang minimum.
Pada masa ini, SEEM telah membuka demo:
https://huggingface.co/spaces/xdecoder/SEEM
Cepat dan cuba.
Atas ialah kandungan terperinci Pasukan China menumbangkan CV! SEEM membahagikan semua letupan dengan sempurna dan membahagikan 'alam semesta serta-merta' dengan satu klik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apa yang perlu dilakukan dengan kad video
Apa yang perlu dilakukan dengan kad video
 Bagaimana untuk memuat turun video dari Douyin
Bagaimana untuk memuat turun video dari Douyin
 Apakah platform e-dagang?
Apakah platform e-dagang?
 Mengapakah vue.js melaporkan ralat?
Mengapakah vue.js melaporkan ralat?
 Bagaimana untuk menyemak pautan mati laman web
Bagaimana untuk menyemak pautan mati laman web
 Bolehkah windows.old dipadamkan?
Bolehkah windows.old dipadamkan?
 Apakah maksud Saham Konsep Metaverse?
Apakah maksud Saham Konsep Metaverse?
 Apakah yang perlu saya lakukan jika eDonkey Search tidak dapat menyambung ke pelayan?
Apakah yang perlu saya lakukan jika eDonkey Search tidak dapat menyambung ke pelayan?
 jquery mengesahkan
jquery mengesahkan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



