
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk melaksanakan penyalinan objek dan susun atur memori dalam Python
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk melaksanakan penyalinan objek dan susun atur memori dalam Python
Bagaimana untuk melaksanakan penyalinan objek dan susun atur memori dalam Python

Prakata
Adakah anda tahu output beberapa coretan atur cara di bawah?
1 2 3 4 5 |
|
1 2 3 4 5 |
|
1 2 3 4 5 |
|
1 2 3 4 5 |
|
1 2 3 4 5 |
|
Susun atur memori objek Python
Bagaimanakah kita harus menentukan alamat memori objek dalam python? Python memberikan kami fungsi id() terbenam untuk mendapatkan alamat memori objek:
1 2 3 4 5 6 7 8 9 10 |
|
Malah, terdapat masalah dengan reka letak memori objek di atas, atau ia tidak cukup tepat ia juga boleh menyatakan hubungan antara pelbagai objek Mari kita lihat dengan lebih dekat sekarang. Dalam Cpython, anda boleh menganggap setiap pembolehubah sebagai penunjuk, menunjuk kepada data yang diwakili Penunjuk ini menyimpan alamat memori objek Python.
Dalam Python, senarai sebenarnya menyimpan penunjuk kepada setiap objek Python, bukan data sebenar Oleh itu, sekeping kod kecil di atas boleh digunakan untuk mewakili susun atur objek dalam ingatan seperti berikut: <🎜. >
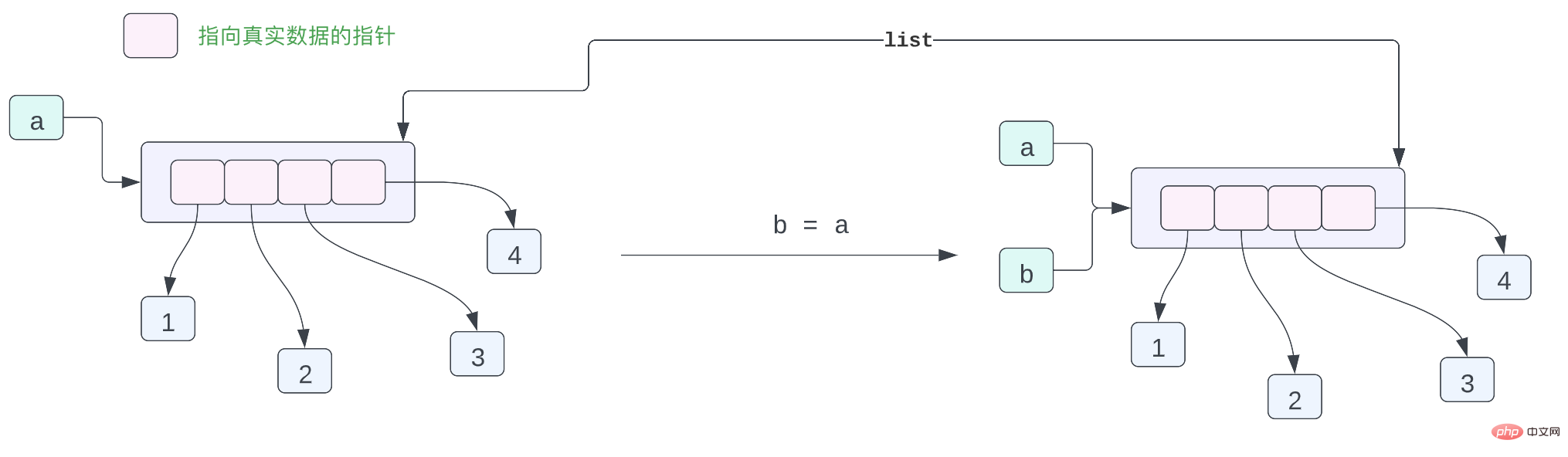
dalam ingatan Terdapat 4 data dalam senarai ini adalah penunjuk, dan empat penunjuk ini menghala ke 1 dan 2 inci ingatan ,3,4 empat data ini. Anda mungkin mempunyai soalan, bukankah ini masalah? Memandangkan kesemuanya adalah data integer, mengapa tidak menyimpan data integer secara langsung dalam senarai. Mengapakah kita perlu menambah penunjuk untuk menunjuk kepada data ini? [1, 2, 3, 4]
1 |
|
1 2 3 |
|
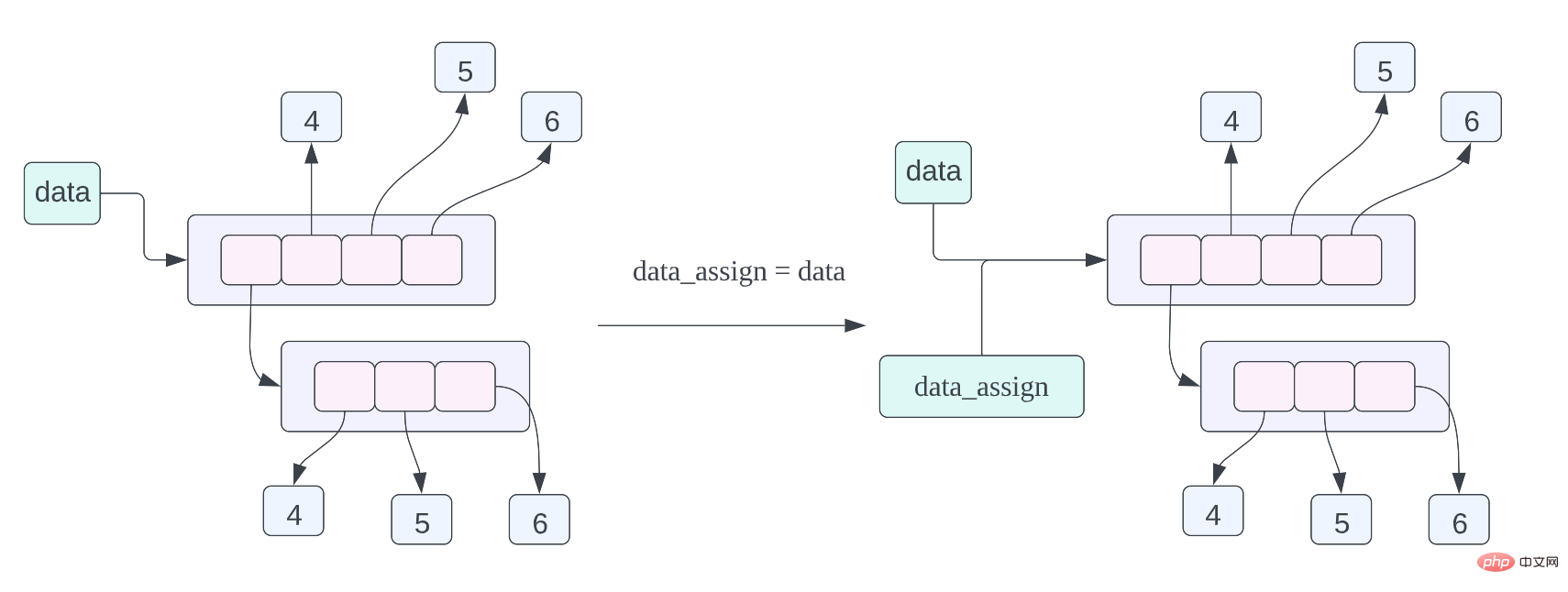
, kita pernah bercakap tentang susun atur memori penyata tugasan ini sebelum ini, tetapi mari kita semak semula, maksud penyata tugasan ini ialah Data yang ditunjuk oleh data_assign dan data adalah data yang sama, iaitu senarai yang sama.
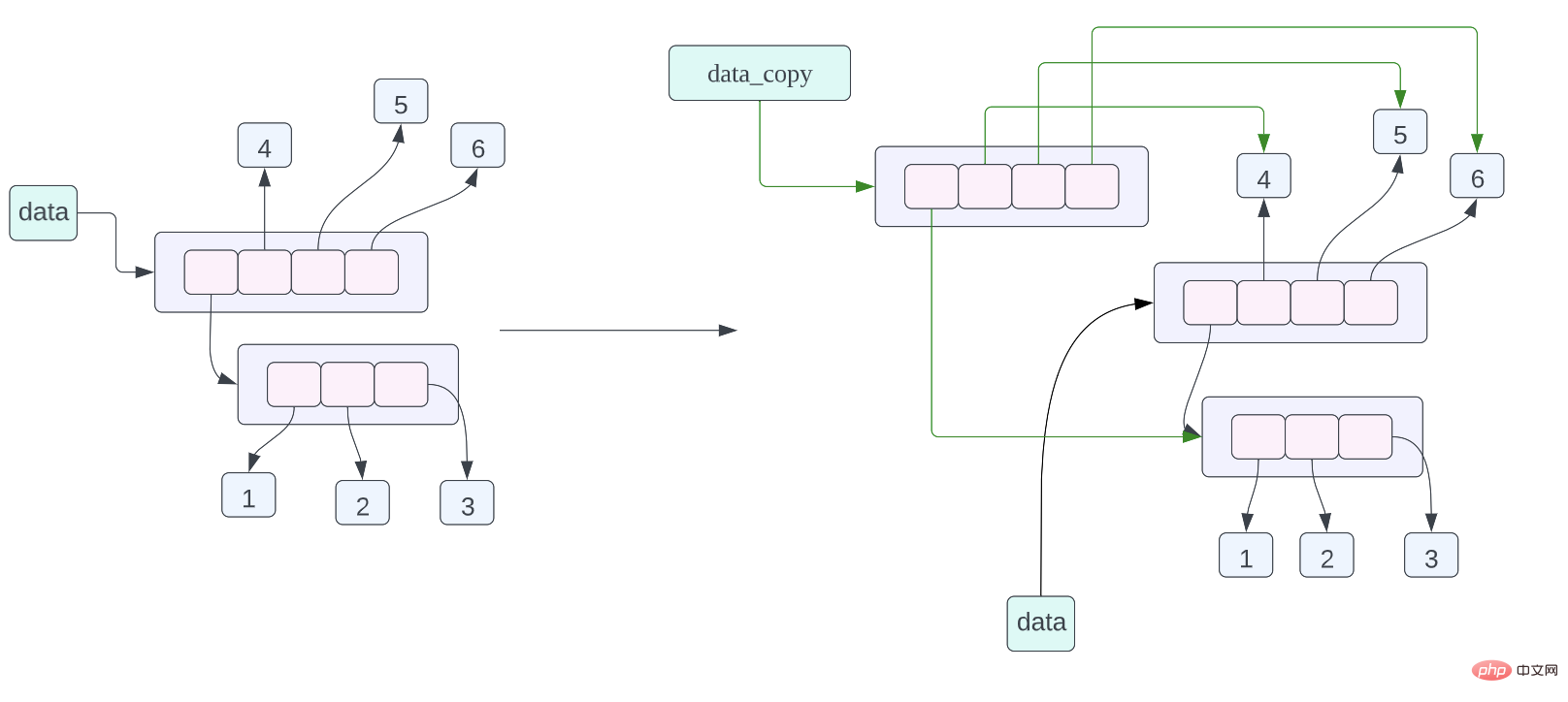
data_assign = data, maksud penyataan tugasan ini ialah membuat salinan cetek data yang ditunjuk oleh data, dan kemudian biarkan data_copy menghala ke data yang disalin di sini bermakna, untuk Setiap penunjuk dalam senarai disalin, tetapi data yang ditunjukkan oleh penunjuk dalam senarai tidak disalin. Daripada rajah susun atur memori objek di atas, kita dapat melihat bahawa data_copy menunjuk ke senarai baharu, tetapi data yang ditunjukkan oleh penunjuk dalam senarai adalah sama dengan data yang ditunjukkan oleh penunjuk dalam senarai data diwakili oleh anak panah hijau, data Gunakan anak panah hitam untuk menunjukkan ini.
data_copy = data.copy()
1 2 3 4 5 |
|
id(a) = 4392953984 id(b) = 4392953984Lihat alamat memori salinan cetek:i = 0. id(a[i]) = 4312613104 id(b[i]) = 4312613104
i = 1 id(a[i]) = 4312613136 id(b[i]) = 4312613136
i a[i]) = 4312613168 id(b[i]) = 4312613168
rreee
Menurut analisis kami sebelum ini, panggilan senarai sendiri Kaedah salin adalah untuk melakukan salinan cetek senarai Ia hanya menyalin data penunjuk senarai dan tidak menyalin data sebenar yang ditunjukkan oleh penunjuk dalam senarai dapatkan alamat objek runcing, senarai a dan Hasil yang dikembalikan oleh senarai b adalah sama, tetapi apa yang berbeza daripada contoh sebelumnya ialah alamat senarai yang ditunjuk oleh a dan b adalah berbeza (kerana data disalin, anda boleh rujuk hasil salinan cetek di bawah untuk pemahaman).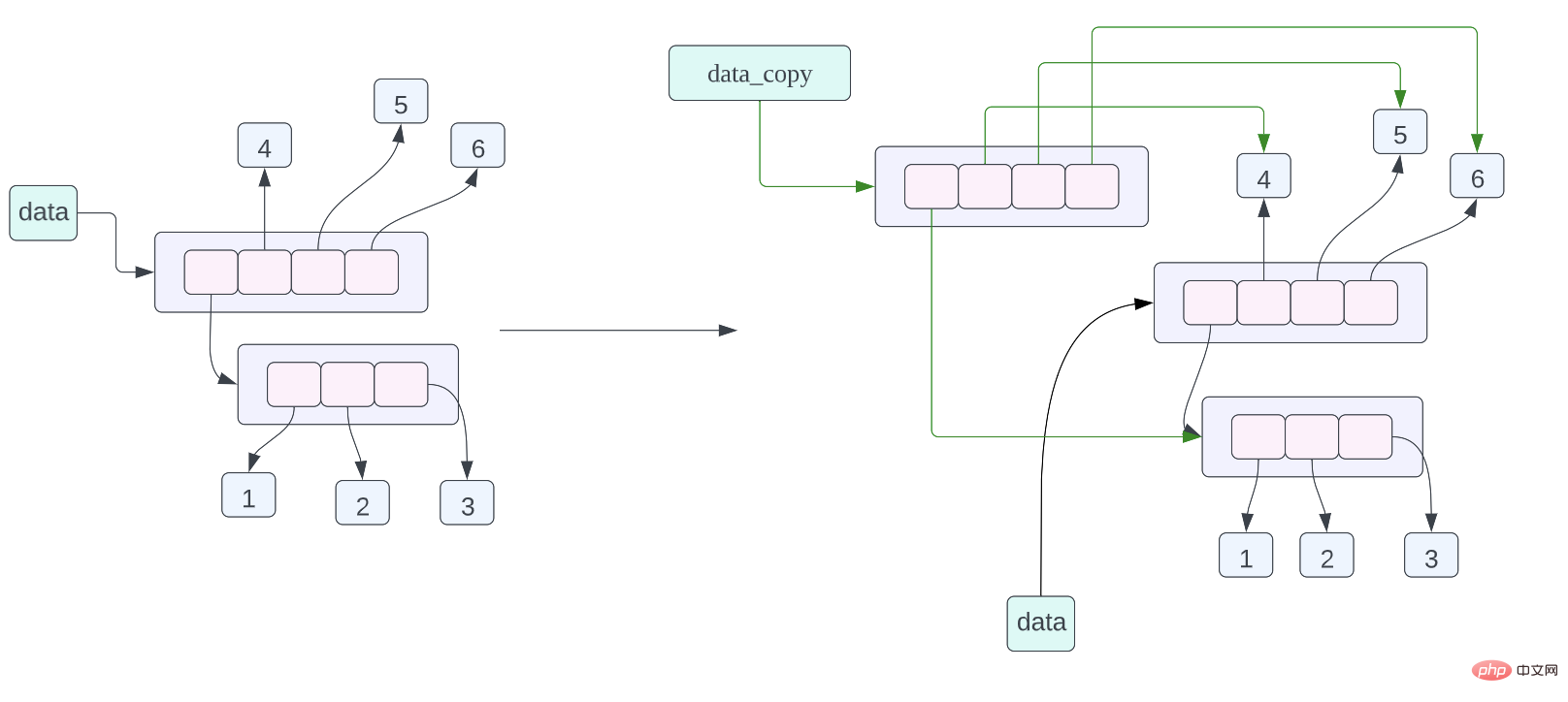
可以结合下面的输出结果和上面的文字进行理解:
1 2 3 4 |
|
copy模块
在 python 里面有一个自带的包 copy ,主要是用于对象的拷贝,在这个模块当中主要有两个方法 copy.copy(x) 和 copy.deepcopy()。
copy.copy(x) 方法主要是用于浅拷贝,这个方法的含义对于列表来说和列表本身的 x.copy() 方法的意义是一样的,都是进行浅拷贝。这个方法会构造一个新的 python 对象并且会将对象 x 当中所有的数据引用(指针)拷贝一份。
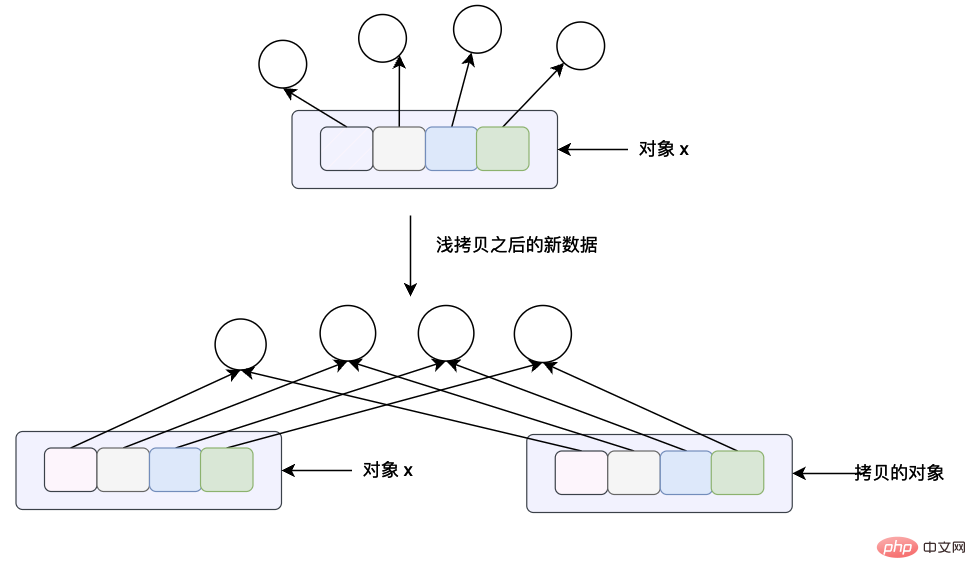
copy.deepcopy(x) 这个方法主要是对对象 x 进行深拷贝,这里的深拷贝的含义是会构造一个新的对象,会递归的查看对象 x 当中的每一个对象,如果递归查看的对象是一个不可变对象将不会进行拷贝,如果查看到的对象是可变对象的话,将重新开辟一块内存空间,将原来的在对象 x 当中的数据拷贝的新的内存当中。(关于可变和不可变对象我们将在下一个小节仔细分析)
根据上面的分析我们可以知道深拷贝的花费是比浅拷贝多的,尤其是当一个对象当中有很多子对象的时候,会花费很多时间和内存空间。
对于 python 对象来说进行深拷贝和浅拷贝的区别主要在于复合对象(对象当中有子对象,比如说列表,元祖、类的实例等等)。这一点主要是和下一小节的可变和不可变对象有关系。
可变和不可变对象与对象拷贝
在 python 当中主要有两大类对象,可变对象和不可变对象,所谓可变对象就是对象的内容可以发生改变,不可变对象就是对象的内容不能够发生改变。
可变对象:比如说列表(list),字典(dict),集合(set),字节数组(bytearray),类的实例对象。
不可变对象:整型(int),浮点型(float),复数(complex),字符串,元祖(tuple),不可变集合(frozenset),字节(bytes)。
看到这里你可能会有疑问了,整数和字符串不是可以修改吗?
1 2 3 4 |
|
比如下面的代码是正确的,并不会发生错误,但是事实上其实 a 指向的对象是发生了变化的,第一个对象指向整型或者字符串的时候,如果重新赋一个新的不同的整数或者字符串对象的话,python 会创建一个新的对象,我们可以使用下面的代码进行验证:
1 2 3 4 5 6 7 8 |
|
上面的程序的输出结果如下所示:
id(a) = 4365566480
id(a) = 4365569360
id(a) = 4424109232
id(a) = 4616350128
可以看到的是当重新赋值之后变量指向的内存对象是发生了变化的(因为内存地址发生了变化),这就是不可变对象,虽然可以对变量重新赋值,但是得到的是一个新对象并不是在原来的对象上进行修改的!
我们现在来看一下可变对象列表发生修改之后内存地址是怎么发生变化的:
1 2 3 4 5 6 7 8 9 10 |
|
上面的代码输出结果如下所示:
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
从上面的输出结果来看可以知道,当我们往列表当中加入新的数据之后(修改了列表),列表本身的地址并没有发生变化,这就是可变对象。
我们在前面谈到了深拷贝和浅拷贝,我们现在来分析一下下面的代码:
1 2 3 4 5 6 7 |
|
上面的代码输出结果如下所示:
id(data ) = 4620333952 | id(data_copy) = 4619860736 | id(data_deep) = 4621137024
id(data[0]) = 4365566192 | id(data_copy[0]) = 4365566192 | id(data_deep[0]) = 4365566192
id(data[1]) = 4365566224 | id(data_copy[1]) = 4365566224 | id(data_deep[1]) = 4365566224
id(data[2]) = 4365566256 | id(data_copy[2]) = 4365566256 | id(data_deep[2]) = 4365566256
看到这里你肯定会非常疑惑,为什么深拷贝和浅拷贝指向的内存对象是一样的呢?前列我们可以理解,因为浅拷贝拷贝的是引用,因此他们指向的对象是同一个,但是为什么深拷贝之后指向的内存对象和浅拷贝也是一样的呢?这正是因为列表当中的数据是整型数据,他是一个不可变对象,如果对 data 或者 data_copy 指向的对象进行修改,那么将会指向一个新的对象并不会直接修改原来的对象,因此对于不可变对象其实是不用开辟一块新的内存空间在重新赋值的,因为这块内存中的对象是不会发生改变的。
我们再来看一个可拷贝的对象:
1 2 3 4 5 6 7 |
|
上面的代码输出结果如下所示:
id(data ) = 4619403712 | id(data_copy) = 4617239424 | id(data_deep) = 4620032640
id(data[0]) = 4620112640 | id(data_copy[0]) = 4620112640 | id(data_deep[0]) = 4620333952
id(data[1]) = 4619848128 | id(data_copy[1]) = 4619848128 | id(data_deep[1]) = 4621272448
id(data[2]) = 4620473280 | id(data_copy[2]) = 4620473280 | id(data_deep[2]) = 4621275840
从上面程序的输出结果我们可以看到,当列表当中保存的是一个可变对象的时候,如果我们进行深拷贝将创建一个全新的对象(深拷贝的对象内存地址和浅拷贝的不一样)。
代码片段分析
经过上面的学习对于在本篇文章开头提出的问题对于你来说应该是很简单的,我们现在来分析一下这几个代码片段:
1 2 3 4 5 |
|
这个很简单啦,a 和 b 不同的变量指向同一个列表,a 中间的数据发生变化,那么 b 的数据也会发生变化,输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
id(a) = 4614458816 | id(b) = 4614458816
我们再来看一下第二个代码片段
1 2 3 4 5 |
|
因为 b 是 a 的一个浅拷贝,所以 a 和 b 指向的是不同的列表,但是列表当中数据的指向是相同的,但是由于整型数据是不可变数据,当a[0] 发生变化的时候,并不会修改原来的数据,而是会在内存当中创建一个新的整型数据,因此列表 b 的内容并不会发生变化。因此上面的代码输出结果如下所示:
1 2 |
|
再来看一下第三个片段:
1 2 3 4 5 |
|
这个和第二个片段的分析是相似的,但是 a[0] 是一个可变对象,因此进行数据修改的时候,a[0] 的指向没有发生变化,因此 a 修改的内容会影响 b。
1 2 |
|
最后一个片段:
1 2 3 4 5 |
|
深拷贝会在内存当中重新创建一个和a[0]相同的对象,并且让 b[0] 指向这个对象,因此修改 a[0],并不会影响 b[0],因此输出结果如下所示:
1 2 |
|
撕开 Python 对象的神秘面纱
我们现在简要看一下 Cpython 是如何实现 list 数据结构的,在 list 当中到底定义了一些什么东西:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
在上面定义的结构体当中 :
allocated 表示分配的内存空间的数量,也就是能够存储指针的数量,当所有的空间用完之后需要再次申请内存空间。
ob_item 指向内存当中真正存储指向 python 对象指针的数组,比如说我们想得到列表当中第一个对象的指针的话就是 list->ob_item[0],如果要得到真正的数据的话就是 *(list->ob_item[0])。
PyObject_VAR_HEAD 是一个宏,会在结构体当中定一个子结构体,这个子结构体的定义如下:
1 2 3 4 |
|
这里我们不去谈对象 PyObject 了,主要说一下 ob_size,他表示列表当中存储了多少个数据,这个和 allocated 不一样,allocated 表示 ob_item 指向的数组一共有多少个空间,ob_size 表示这个数组存储了多少个数据 ob_size
在了解列表的结构体之后我们现在应该能够理解之前的内存布局了,所有的列表并不存储真正的数据而是存储指向这些数据的指针。
Atas ialah kandungan terperinci Bagaimana untuk melaksanakan penyalinan objek dan susun atur memori dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.
Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cara Membuka Format XML
Apr 02, 2025 pm 09:00 PM
Cara Membuka Format XML
Apr 02, 2025 pm 09:00 PM
Gunakan kebanyakan editor teks untuk membuka fail XML; Jika anda memerlukan paparan pokok yang lebih intuitif, anda boleh menggunakan editor XML, seperti editor XML oksigen atau XMLSPY; Jika anda memproses data XML dalam program, anda perlu menggunakan bahasa pengaturcaraan (seperti Python) dan perpustakaan XML (seperti XML.Etree.ElementTree) untuk menghuraikan.
 Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 08:54 PM
Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 08:54 PM
Permohonan yang menukarkan XML terus ke PDF tidak dapat dijumpai kerana mereka adalah dua format yang berbeza. XML digunakan untuk menyimpan data, manakala PDF digunakan untuk memaparkan dokumen. Untuk melengkapkan transformasi, anda boleh menggunakan bahasa pengaturcaraan dan perpustakaan seperti Python dan ReportLab untuk menghuraikan data XML dan menghasilkan dokumen PDF.
 Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Kelajuan XML mudah alih ke PDF bergantung kepada faktor -faktor berikut: kerumitan struktur XML. Kaedah Penukaran Konfigurasi Perkakasan Mudah Alih (Perpustakaan, Algoritma) Kaedah Pengoptimuman Kualiti Kod (Pilih perpustakaan yang cekap, mengoptimumkan algoritma, data cache, dan menggunakan pelbagai threading). Secara keseluruhannya, tidak ada jawapan mutlak dan ia perlu dioptimumkan mengikut keadaan tertentu.
 Cara mengubahsuai kandungan komen dalam XML
Apr 02, 2025 pm 06:15 PM
Cara mengubahsuai kandungan komen dalam XML
Apr 02, 2025 pm 06:15 PM
Untuk fail XML kecil, anda boleh menggantikan kandungan anotasi secara langsung dengan editor teks; Untuk fail besar, adalah disyorkan untuk menggunakan parser XML untuk mengubahnya untuk memastikan kecekapan dan ketepatan. Berhati -hati apabila memadam komen XML, menyimpan komen biasanya membantu pemahaman dan penyelenggaraan kod. Petua Lanjutan menyediakan kod sampel Python untuk mengubahsuai komen menggunakan parser XML, tetapi pelaksanaan khusus perlu diselaraskan mengikut perpustakaan XML yang digunakan. Beri perhatian kepada isu pengekodan semasa mengubah suai fail XML. Adalah disyorkan untuk menggunakan pengekodan UTF-8 dan menentukan format pengekodan.
 Alat pemformatan XML yang disyorkan
Apr 02, 2025 pm 09:03 PM
Alat pemformatan XML yang disyorkan
Apr 02, 2025 pm 09:03 PM
Alat pemformatan XML boleh menaip kod mengikut peraturan untuk meningkatkan kebolehbacaan dan pemahaman. Apabila memilih alat, perhatikan keupayaan penyesuaian, pengendalian keadaan khas, prestasi dan kemudahan penggunaan. Jenis alat yang biasa digunakan termasuk alat dalam talian, pemalam IDE, dan alat baris arahan.
 Adakah terdapat XML percuma untuk alat PDF untuk telefon bimbit?
Apr 02, 2025 pm 09:12 PM
Adakah terdapat XML percuma untuk alat PDF untuk telefon bimbit?
Apr 02, 2025 pm 09:12 PM
Tidak ada XML percuma yang mudah dan langsung ke alat PDF di mudah alih. Proses visualisasi data yang diperlukan melibatkan pemahaman dan rendering data yang kompleks, dan kebanyakan alat yang dipanggil "percuma" di pasaran mempunyai pengalaman yang buruk. Adalah disyorkan untuk menggunakan alat sampingan komputer atau menggunakan perkhidmatan awan, atau membangunkan aplikasi sendiri untuk mendapatkan kesan penukaran yang lebih dipercayai.
 Bagaimana cara menukar XML ke PDF di telefon anda dengan kualiti tinggi?
Apr 02, 2025 pm 09:48 PM
Bagaimana cara menukar XML ke PDF di telefon anda dengan kualiti tinggi?
Apr 02, 2025 pm 09:48 PM
Tukar XML ke PDF dengan kualiti tinggi pada telefon bimbit anda memerlukan: Parsing XML di awan dan menjana PDF menggunakan platform pengkomputeran tanpa pelayan. Pilih Parser XML yang cekap dan perpustakaan penjanaan PDF. Mengendalikan kesilapan dengan betul. Menggunakan sepenuhnya kuasa pengkomputeran awan untuk mengelakkan tugas berat pada telefon anda. Laraskan kerumitan mengikut keperluan, termasuk memproses struktur XML kompleks, menghasilkan PDF multi-halaman, dan menambah imej. Cetak maklumat log untuk membantu debug. Mengoptimumkan prestasi, pilih parser yang cekap dan perpustakaan PDF, dan boleh menggunakan pengaturcaraan asynchronous atau data XML preprocessing. Memastikan kualiti kod yang baik dan penyelenggaraan.
 Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Tidak mustahil untuk menyelesaikan penukaran XML ke PDF secara langsung di telefon anda dengan satu aplikasi. Ia perlu menggunakan perkhidmatan awan, yang boleh dicapai melalui dua langkah: 1. Tukar XML ke PDF di awan, 2. Akses atau muat turun fail PDF yang ditukar pada telefon bimbit.
