

Kini, sudah penghujung tahun 2022.
Prestasi model pembelajaran mendalam dalam menjana imej sudah begitu baik. Jelas sekali, ia akan memberi kita lebih banyak kejutan pada masa hadapan.

Bagaimana kita sampai ke tahap sekarang dalam tempoh sepuluh tahun?
Dalam garis masa di bawah, kami akan mengesan beberapa detik penting, iaitu, apabila kertas kerja, seni bina, model, set data dan eksperimen yang mempengaruhi sintesis imej AI dilancarkan.
Semuanya bermula dari musim panas itu sepuluh tahun yang lalu.
Selepas kemunculan rangkaian neural dalam, orang ramai menyedari bahawa ia akan mengubah klasifikasi imej sepenuhnya.
Pada masa yang sama, penyelidik mula meneroka arah yang bertentangan, apakah yang akan berlaku jika imej dihasilkan menggunakan beberapa teknik yang sangat berkesan untuk pengelasan, seperti lapisan konvolusi?
Ini adalah permulaan "Musim Panas Kepintaran Buatan".
Disember 2012
Di sinilah semuanya bermula.
Tahun ini, kertas kerja "ImageNet Classification of Deep Convolutional Neural Networks" telah diterbitkan.

Salah seorang pengarang kertas kerja ialah Hinton, salah seorang daripada "Tiga Besar" AI.
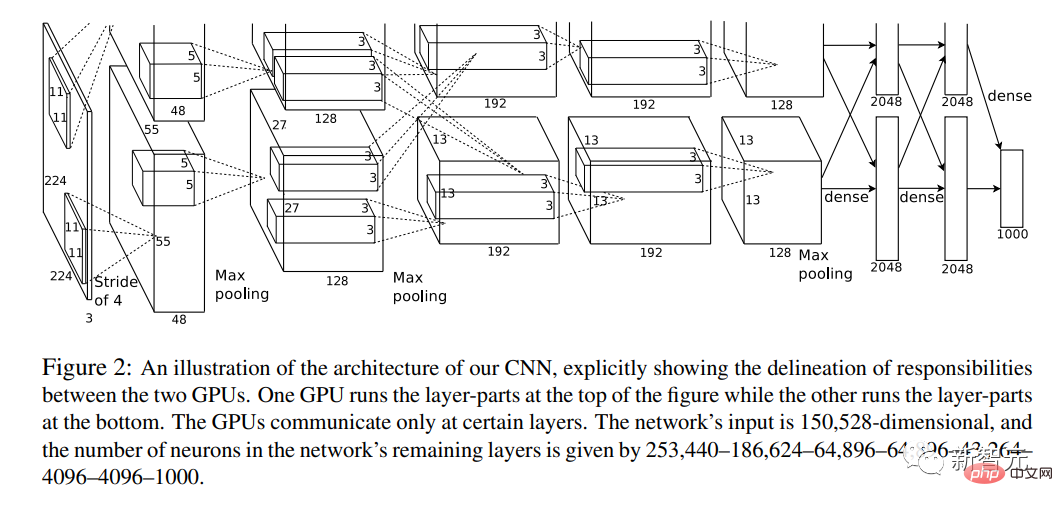
Buat pertama kali, ia menggabungkan rangkaian neural convolutional mendalam (CNN), GPU dan set data sumber internet yang besar (ImageNet).

Disember 2014
Ian Goodfellow dan gergasi AI lain menerbitkan kertas kerja epik "Rangkaian Adversarial Generatif".
GAN ialah seni bina rangkaian saraf moden pertama yang dikhususkan untuk sintesis imej dan bukannya analisis (takrifan "moden" adalah selepas 2012).
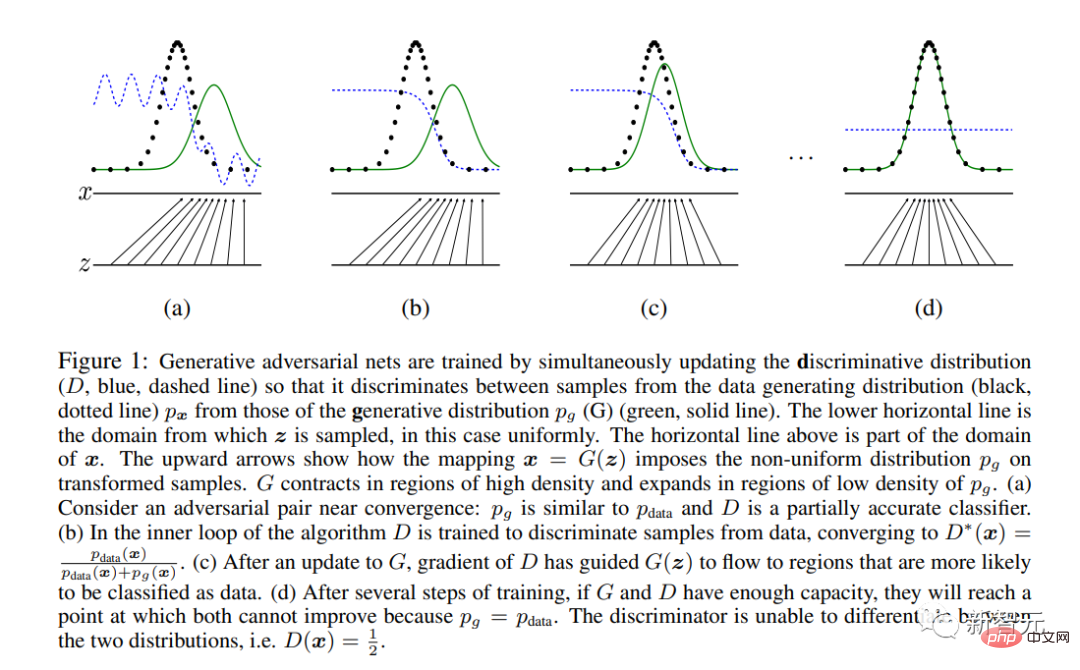
Ia memperkenalkan kaedah pembelajaran unik berdasarkan teori permainan, dengan dua sub-rangkaian "Generator" dan "Discriminator" bersaing.
Akhirnya, hanya "penjana" disimpan di luar sistem dan digunakan untuk sintesis imej.
Hello Dunia! GAN menjana sampel muka daripada kertas 2014 Goodfellow et al. Model ini dilatih pada set data Toronto Faces, yang telah dialih keluar daripada web
November 2015
Kertas penting "Pembelajaran Wakil Tanpa Pengawasan Menggunakan Rangkaian Adversarial Generatif Konvolusi Dalam" telah diterbitkan.

Dalam kertas kerja ini, penulis menerangkan seni bina GAN yang boleh digunakan secara praktikal (DCGAN) pertama.
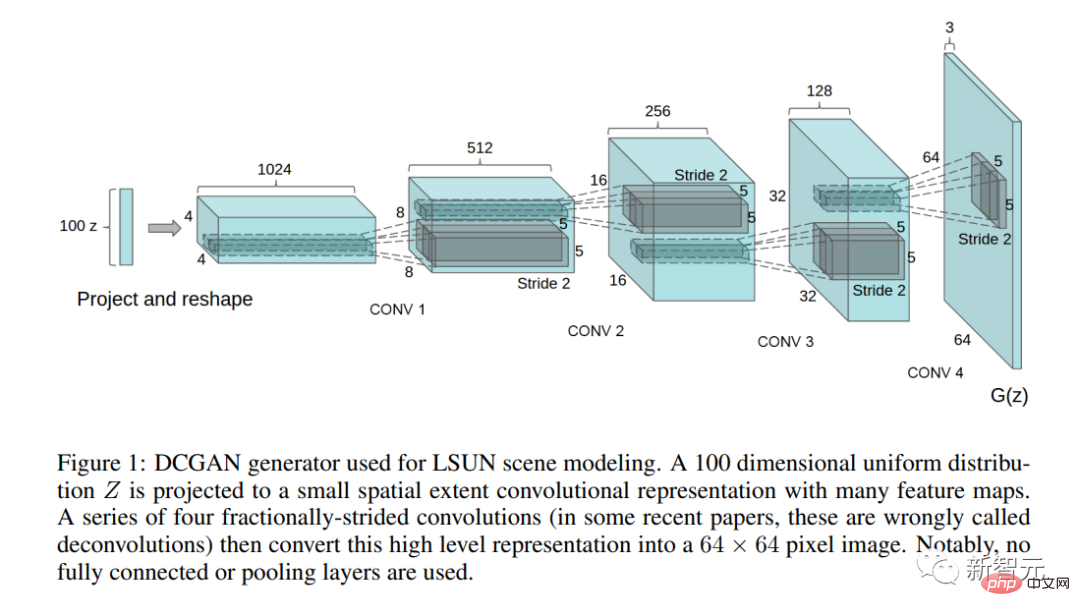
Kertas kerja ini juga menimbulkan persoalan manipulasi ruang terpendam buat kali pertama - adakah konsep memetakan arah ruang terpendam?
Sepanjang lima tahun ini, GAN telah digunakan untuk pelbagai tugas pemprosesan imej, seperti pemindahan gaya, pemulihan, denoising dan resolusi super. Semasa
, kertas kerja mengenai seni bina GAN mula meletup.

Alamat projek: https://github.com/nightrome/really-awesome-gan
Pada masa yang sama, eksperimen artistik dengan GAN mula muncul, dan karya pertama Mike Tyka, Mario Klingenmann, Anna Ridler, Helena Sarin dan lain-lain muncul.
Skandal “seni AI” pertama berlaku pada 2018. Tiga pelajar Perancis menggunakan kod "pinjaman" untuk menghasilkan potret AI, yang menjadi potret AI pertama yang dilelong di Christie's.

Pada masa yang sama, seni bina transformer merevolusikan NLP.
Perkara ini akan memberi kesan yang ketara kepada sintesis imej dalam masa terdekat.
Jun 2017
Kertas "Perhatian Adalah Semua yang Anda Perlukan" telah dikeluarkan.

Terdapat juga penjelasan terperinci dalam "Transformers, Explained: Understand the Model Behind GPT-3, BERT, and T5".
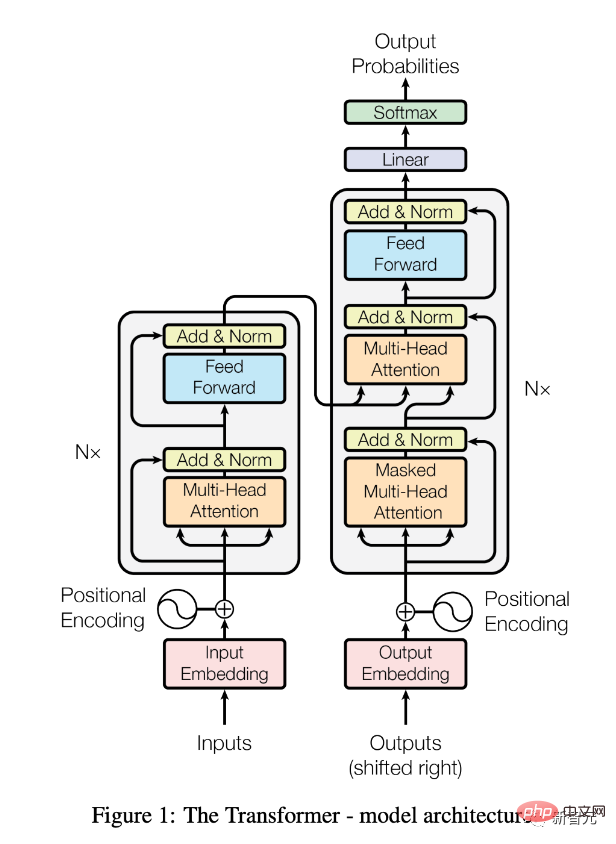
Sejak itu, seni bina Transformer (dalam bentuk model pra-latihan seperti BERT) telah merevolusikan bidang pemprosesan bahasa semula jadi (NLP) .

Julai 2018

Kertas "Anotasi Konseptual: Pembersihan, Superpositioning dan Set Data Teks Alternatif Imej untuk Kapsyen Imej Automatik" telah diterbitkan.
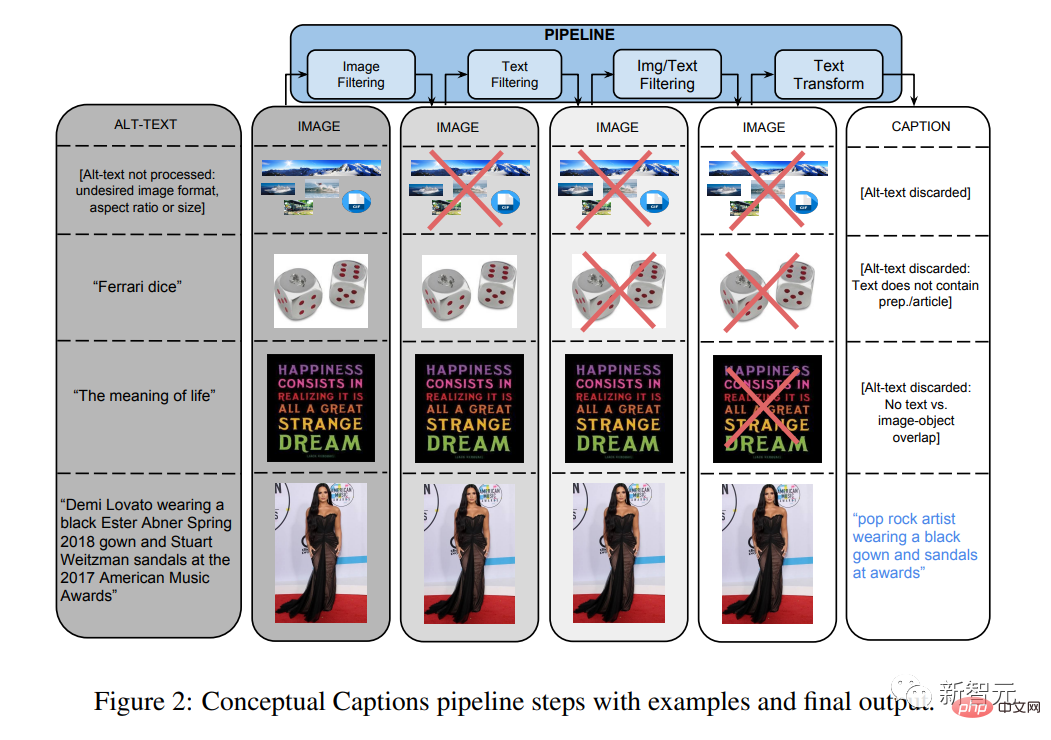
Ini dan set data multimodal lain akan menjadi sangat penting untuk model seperti CLIP dan DALL-E.
Pada 2018-20
Penyelidik NVIDIA menjalankan kajian tentang seni bina GAN. Siri dirombak sepenuhnya.
Dalam kertas kerja "Melatih Rangkaian Musuh Penjanaan Menggunakan Data Terhad", StyleGAN2-ada terbaru diperkenalkan.

Buat pertama kali, imej yang dijana GAN menjadi tidak dapat dibezakan daripada imej semula jadi, sekurang-kurangnya untuk set data yang sangat dioptimumkan seperti Flickr-Faces-HQ (FFHQ) jadi.

Mario Klingenmann, Memories of Passerby I, 2018. Wajah baconesque adalah tipikal seni AI di rantau ini, di mana sifat tidak realistik model generatif Ia menjadi tumpuan penerokaan artistik
Mei 2020
Kertas kerja "Model Bahasa ialah Pelajar Sampel Kecil" diterbitkan.
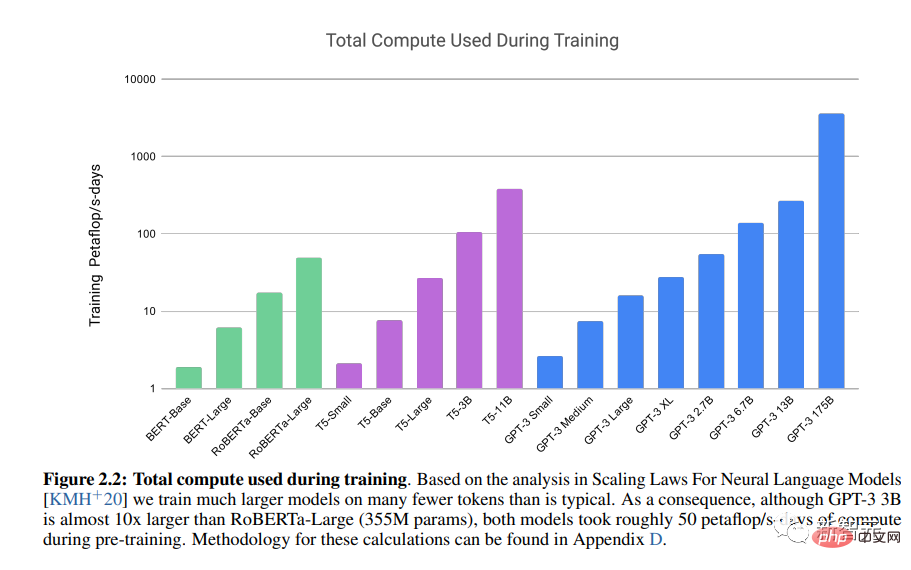
Transformer Pra-latihan LLM Generatif OpenAI 3 (GPT-3) menunjukkan kuasa seni bina transformer.
Disember 2020
Kertas "Taming transformer untuk sintesis imej resolusi tinggi" diterbitkan.

ViT menunjukkan bahawa seni bina Transformer boleh digunakan untuk imej.
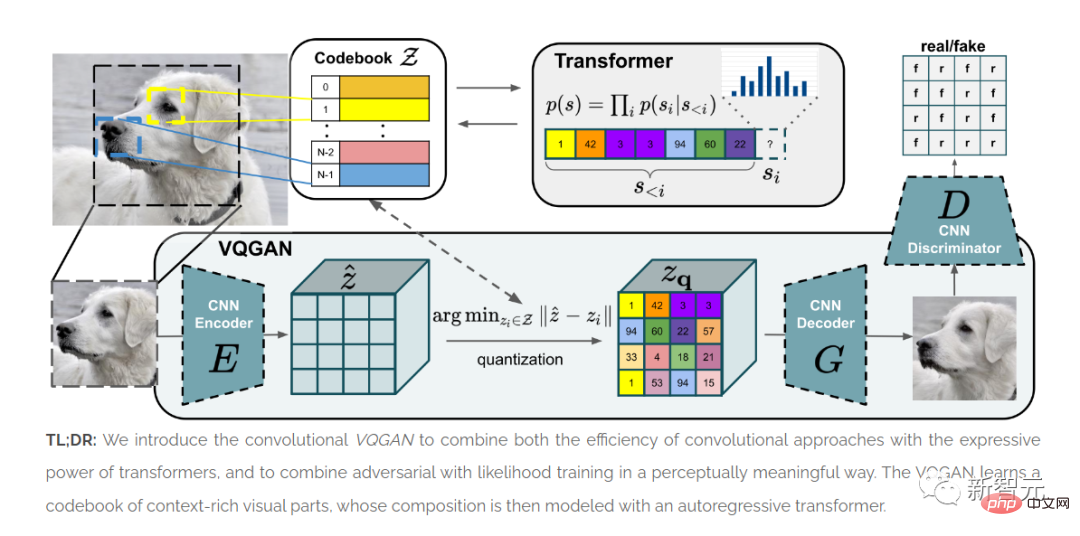
Kaedah yang dibentangkan dalam artikel ini, VQGAN, menghasilkan keputusan SOTA dalam ujian penanda aras.
Kualiti seni bina GAN dari akhir 2010-an dinilai terutamanya berdasarkan imej muka yang dijajarkan, dengan hasil terhad untuk set data yang lebih heterogen.
Oleh itu, wajah manusia kekal sebagai titik rujukan penting dalam eksperimen akademik/perindustrian dan seni.
Era Transformer (2020-2022)
Kemunculan seni bina Transformer telah menulis semula sepenuhnya sejarah sintesis imej.
Sejak itu, bidang sintesis imej telah mula meninggalkan GAN.
Pembelajaran mendalam "Multi-modal" menyepadukan NLP dan teknologi penglihatan komputer "Kejuruteraan tepat dalam masa" menggantikan latihan dan pelarasan model dan menjadi kaedah artistik sintesis imej.
Dalam kertas kerja "Learning Transferable Vision Models from Natural Language Supervision", seni bina CLIP dicadangkan.

Boleh dikatakan kegilaan sintesis imej semasa didorong oleh fungsi multi-modal yang diperkenalkan buat pertama kali oleh CLIP.
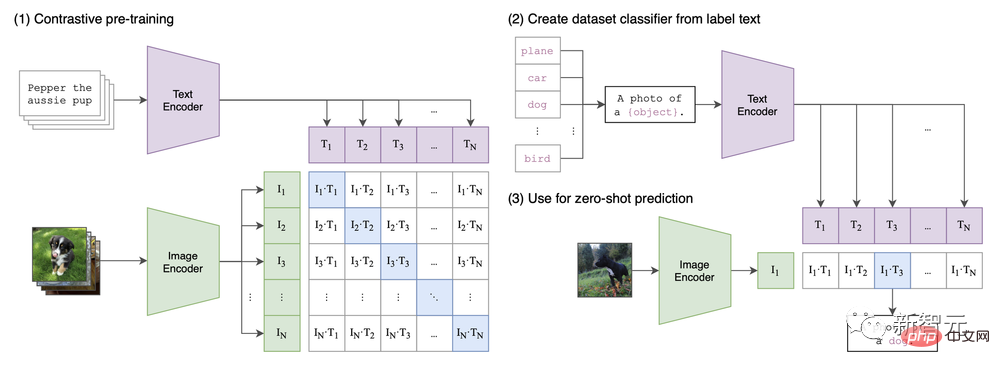
CIP seni bina dalam kertas
Januari 2021

Kertas "Teks Sampel Sifar kepada Penjanaan Imej" telah diterbitkan (lihat juga catatan blog OpenAI), yang memperkenalkan versi pertama DALL-E yang bakal melanda dunia.
Versi ini berfungsi dengan menggabungkan teks dan imej (dimampatkan oleh VAE menjadi "TOKEN") dalam satu aliran data.
Model ini hanya "meneruskan" "ayat".
Data (imej 250J) termasuk pasangan imej teks daripada Wikipedia, penerangan konsep dan subset ditapis YFCM100M.
CLIP meletakkan asas bagi pendekatan "multi-modal" kepada sintesis imej.
Januari 2021
Kertas "Pembelajaran Visi Boleh Dipindah dari Model Penyeliaan Bahasa Semulajadi" diterbitkan.

Makalah ini memperkenalkan CLIP, model pelbagai mod yang menggabungkan ViT dan Transformer biasa.
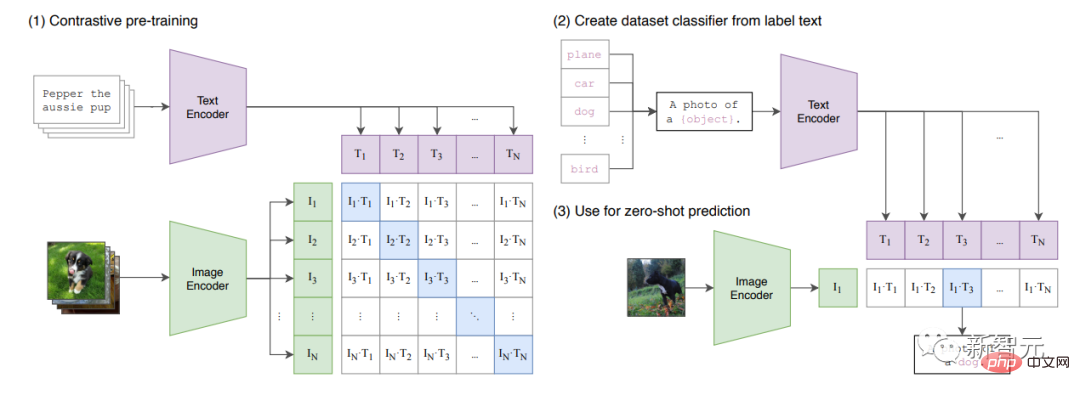
KLIP akan mempelajari "ruang pendam kongsi" imej dan kapsyen, supaya ia boleh melabelkan imej.
Model ini dilatih pada sejumlah besar set data yang disenaraikan dalam Lampiran A.1 kertas. GAN "diterbitkan.
Model resapan memperkenalkan kaedah sintesis imej yang berbeza daripada kaedah GAN.
Penyelidik belajar dengan membina semula imej daripada bunyi yang ditambah secara buatan.

Ia berkaitan dengan pengekod auto variasi (VAE).

DALL-E mini dikeluarkan.
Ia adalah salinan DALL-E (lebih kecil, dengan sedikit pelarasan pada seni bina dan data).
Data termasuk 12M Konseptual, Kapsyen Konseptual dan subset ditapis yang sama bagi YFCM100M yang digunakan oleh OpenAI untuk model DALL-E asal.
Tanpa penapis kandungan atau sekatan API, DALL-E mini menawarkan potensi besar untuk penerokaan kreatif dan menghasilkan letupan imej "DALL-E yang pelik" pada pertumbuhan Twitter. 
2021-2022
Katherine Crowson mengeluarkan satu siri nota CoLab meneroka pembuatan CLIP membimbing penjanaan model.
Sebagai contoh, resapan berpandukan 512x512CLIP dan VQGAN-CLIP (Penjanaan imej domain terbuka dan pengeditan dengan panduan bahasa semula jadi, hanya akan dikeluarkan sebagai pracetak pada tahun 2022 tetapi percubaan awam muncul sebaik sahaja VQGAN telah dikeluarkan). Sama seperti pada era awal GAN, artis dan pembangun membuat penambahbaikan yang ketara pada seni bina sedia ada dengan cara yang sangat terhad, yang kemudiannya dipermudahkan oleh syarikat dan akhirnya dikomersialkan oleh "startups" seperti wombo.ai. April 2022 Tesis "Keadaan teks hierarki dengan potensi CLIP" Penjanaan Imej" diterbitkan. Kertas kerja ini memperkenalkan DALL-E 2. Ia dibina di atas kertas GLIDE yang diterbitkan hanya beberapa minggu lalu (" GLIDE : Berdasarkan Penjanaan Imej Realistik dan Penyuntingan Menggunakan Model Resapan Berpandukan Teks》Pada masa yang sama, disebabkan oleh akses DALL-E 2. Terhad dan sengaja dihadkan, terdapat minat baharu dalam DALL-E mini Menurut kad model, data itu termasuk "gabungan sumber awam dan sumber berlesen kami," dan mengikut dataset lengkap dan Dall-E dalam kertas ini. , dijana menggunakan DALL-E 2. Model generatif berasaskan Transformer sepadan dengan realisme seni bina GAN kemudiannya seperti StyleGAN 2, tetapi membenarkan penciptaan pelbagai jenis tema dan corak Mei-Jun 2022
Dalam dua kertas ini, Imagegen dan Parti telah diperkenalkan. 🎜> dan jawapan Google kepada DALL-E 2. >"Adakah anda tahu mengapa saya menghalang anda hari ini?" kejuruteraan segera" telah menjadi kaedah utama sintesis imej artistik AI Photoshop (2022 hingga sekarang) Walaupun DALL-E 2 menetapkan standard baharu untuk pemodelan imej, pengkomersilan pantasnya juga bermakna penggunaannya terhad dari awal > Kemudian semua itu berubah dengan keluaran Stable Diffusion yang hebat Boleh dikatakan Stable Diffusion menandakan permulaan "era Photoshop" sintesis imej. "Masih hidup dengan empat tandan anggur, cuba mencipta sesuatu seperti pelukis purba Zeuxis Juan El Labrador Fernandez, 1636, Prado , Madrid "Anggur seakan hidup seperti anggur", enam perubahan yang dihasilkan oleh Stable Diffusion Ogos 2022 Stability.ai mengeluarkan model Stable Diffusion. Dalam kertas kerja "Sintesis Imej Resolusi Tinggi dengan Model Resapan Terpendam", Stability.ai dengan hebatnya melancarkan Resapan Stabil. Model ini boleh mencapai fotorealisme yang sama seperti DALL-E 2. Selain DALL-E 2, model tersedia kepada orang ramai dengan segera dan boleh dijalankan pada platform CoLab dan Huggingface. Ogos 2022 Google menerbitkan makalah "DreamBooth: Generating for theme-driven Penalaan halus model resapan teks ke imej. DreamBooth menyediakan kawalan yang semakin halus ke atas model resapan. Walau bagaimanapun, walaupun tanpa campur tangan teknikal tambahan sedemikian, ia menjadi sesuai untuk menggunakan model generatif seperti Photoshop, bermula dari lakaran dan bekerja lapisan demi lapisan Tambah pengubahsuaian yang terhasil. Oktober 2022 Maks , salah satu syarikat galeri foto, mengumumkan bahawa ia bekerjasama dengan OpenAI untuk menyediakan/memberi lesen imej yang dihasilkan Ia boleh dijangka bahawa pasaran galeri foto akan terjejas dengan serius oleh model generatif seperti Stable Diffusion. 



 Pengguna terus mencuba model yang lebih kecil seperti DALL-E mini
Pengguna terus mencuba model yang lebih kecil seperti DALL-E mini 




Atas ialah kandungan terperinci Hinton ada dalam senarai! Mengambil kira sejarah 10 tahun sintesis imej AI, kertas kerja dan nama yang patut diingat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perbezaan antara sqlserver dan mysql
Perbezaan antara sqlserver dan mysql
 Excel menjana kod QR
Excel menjana kod QR
 Windows tidak dapat menyelesaikan pemformatan penyelesaian cakera keras
Windows tidak dapat menyelesaikan pemformatan penyelesaian cakera keras
 Cara menggunakan fungsi max
Cara menggunakan fungsi max
 Apakah DNS yang biasa digunakan?
Apakah DNS yang biasa digunakan?
 Bagaimana untuk menyambung php ke pangkalan data mssql
Bagaimana untuk menyambung php ke pangkalan data mssql
 Bagaimana untuk membuka fail xml
Bagaimana untuk membuka fail xml
 Bagaimana untuk menyelesaikan masalah bahawa folder Win10 tidak boleh dipadamkan
Bagaimana untuk menyelesaikan masalah bahawa folder Win10 tidak boleh dipadamkan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



