
 pembangunan bahagian belakang
Tutorial Python
Cara menggunakan perpustakaan Permintaan perangkak Python
pembangunan bahagian belakang
Tutorial Python
Cara menggunakan perpustakaan Permintaan perangkak Python
Cara menggunakan perpustakaan Permintaan perangkak Python

1. Pasang perpustakaan permintaan
Oleh kerana proses pembelajaran menggunakan bahasa Python, anda perlu memasang Python 3.8 terlebih dahulu python --version Versi Python yang dipasang, adalah disyorkan untuk memasang Python 3.X atau lebih tinggi.
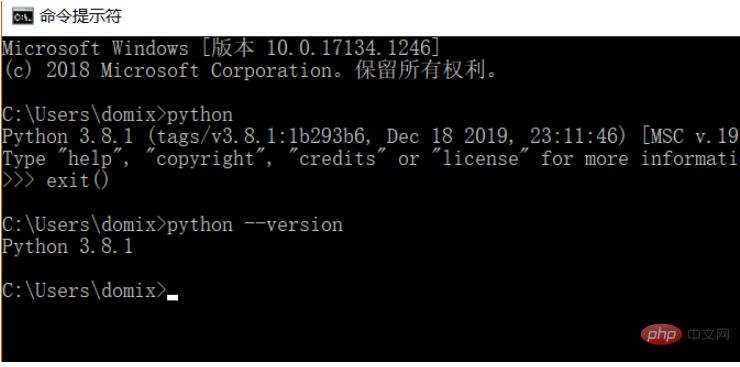
Selepas memasang Python, anda boleh terus memasang perpustakaan permintaan melalui arahan berikut.
pip install requests
Ps: Anda boleh bertukar kepada sumber pip domestik, seperti Alibaba dan Douban, yang pantas
Untuk menunjukkan fungsi, saya menggunakan nginx untuk mensimulasikan tapak web mudah .
Selepas memuat turun, jalankan sahaja program nginx.exe dalam direktori akar secara terus (nota: di bawah persekitaran Windows).
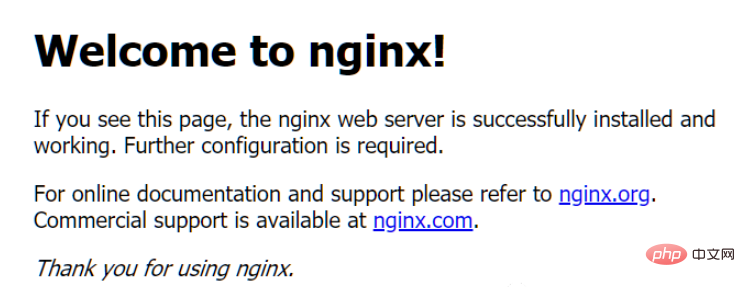
Pada masa ini, apabila komputer tempatan mengakses: http://127.0.0.1, ia akan memasuki halaman lalai nginx.
2. Dapatkan halaman web
Seterusnya kita mula menggunakan permintaan untuk mensimulasikan permintaan dan mendapatkan kod sumber halaman. Keputusan yang diperolehi selepas melaksanakan
import requestsr = requests.get('http://127.0.0.1')print(r.text)adalah seperti berikut:
nbsp;html><title>Welcome to nginx!</title><style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; }</style><h2 id="Welcome-to-nginx">Welcome to nginx!</h2><p>If you see this page, the nginx web server is successfully installed andworking. Further configuration is required.</p>
<p>For online documentation and support please refer to<a>nginx.org</a>.<br>Commercial support is available at<a>nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>3. Mengenai permintaan
Terdapat banyak permintaan biasa, seperti yang digunakan dalam contoh di atas Ia adalah permintaan GET Berikut ialah pengenalan terperinci kepada kaedah permintaan biasa ini.
4. Permintaan GET
4.1 Mulakan permintaan
Kami menggunakan kaedah yang sama untuk memulakan permintaan GET:
import requests r = requests.get('http://httpbin.org/get') print(r.text)Hasil pulangan adalah seperti berikut:
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5f846520-19f215aa46213a2b4241c18a" }, "origin": "xxxx", "url": "http://httpbin.org/get"}Dengan mengembalikan hasil, kita dapat melihat bahawa maklumat yang disertakan dalam hasil pulangan ialah: Pengepala, URL, IP, dsb.
4.2. Tambah parameter
Biasanya URL yang kami lawati akan mengandungi beberapa parameter, seperti: id ialah 100 dan nama ialah YOOAO. Untuk akses biasa, kami akan menulis URL berikut untuk akses:
http://httpbin.org/get?id=100&name=YOOAO
Jelas sekali ia sangat menyusahkan, dan ia akan terdedah kepada ralat apabila terdapat banyak parameter Pada masa ini, kami boleh mengoptimumkan kandungan input melalui parameter params.
import requests data = { 'id': '100', 'name': 'YOOAO'} r = requests.get('http://httpbin.org/get', params=data) print(r.text)Ini adalah hasil yang dikembalikan dengan melaksanakan kod seperti berikut:
{"args": {"id": "100", "name": "YOOAO" }, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5f84658a-1cd0437b4cf34835410d7161" }, "origin": "xxx.xxxx.xxx.xxx", "url": "http://httpbin.org/get?id=100&name=YOOAO"}Dengan mengembalikan hasilnya, kita dapat melihat bahawa parameter yang dihantar melalui kamus secara automatik dibina menjadi URL lengkap, tanpa kami Siapkan pembinaan secara manual.
4.3. Memproses hasil pulangan
Hasil pulangan adalah dalam format json, jadi kita boleh menggunakan kaedah memanggil json untuk menghuraikan. Jika kandungan yang dikembalikan tidak dalam format json, panggilan ini akan melaporkan ralat.
import requests
r = requests.get('http://httpbin.org/get') print(type(r.text)) print(type(r.json()))Kembali hasil:
<class><class></class></class>
4.4 Tangkapan kandungan
Di sini kami menggunakan ungkapan biasa mudah untuk menangkap jenis halaman sampel nginx Untuk kandungan semua. teg, kodnya adalah seperti berikut:
import requestsimport re
r = requests.get('http://127.0.0.1')pattern = re.compile('<a.>(.*?)', re.S)a_content = re.findall(pattern, r.text)print(a_content)</a.>Mengambil hasil:
['nginx.org', 'nginx.com']
Pemerolehan halaman mudah dan merangkak kandungan selesai di sini,
4.5. Muat turun fail data
Contoh di atas mengembalikan maklumat halaman Jika kita ingin mendapatkan imej, fail audio dan video pada halaman web, kita perlu belajar merangkak data binari halaman. Kita boleh menggunakan kaedah terbuka untuk memuat turun fail binari seperti imej Contoh kod:
import requests
r = requests.get('http://tu.ossfiles.cn:9186/group3/M00/09/FB/rBpVfl8QFLOAYhhcAAC-pTdNj7g471.jpg')with open('image.jpg', 'wb') as f: f.write(r.content)print('下载完成')Dalam kaedah terbuka, parameter pertamanya ialah nama fail, dan parameter kedua mewakili pembukaan dalam bentuk binari data binari kepada fail.
Selepas operasi selesai, imej yang dimuat turun akan disimpan dalam folder yang sama pada fail yang sedang berjalan. Menggunakan prinsip yang sama, kami boleh memproses fail video dan audio.
4.6. Tambah pengepala
Dalam contoh di atas, permintaan yang kami mulakan secara langsung tidak menambah pengepala Sesetengah tapak web disebabkan oleh permintaan yang tidak membawa pengepala permintaan. Pengecualian akses, di sini kita boleh menambah kandungan pengepala secara manual, mensimulasikan penambahan kod kandungan Uer-Agent dalam pengepala:
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'}r = requests.get('http://httpbin.org/get', headers=headers)print(r.text)Hasil pelaksanaan:
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36", "X-Amzn-Trace-Id": "Root=1-5ec8f342-8a9f986011eac8f07be8b450" }, "origin": "xxx3.xx.xxx.xxx", "url": "http://httpbin.org/get"}Hasilnya dapat dilihat, nilai Pengguna -Agen telah bertukar. Bukan yang sebelumnya: python-requests/2.23.0.
5. Permintaan POST
Kini setelah kita membincangkan pengetahuan yang berkaitan dengan permintaan GET, mari bercakap tentang kaedah permintaan biasa yang lain: permintaan POST.
使用 requests 实现 POST 请求的代码如下:
import requestsdata = { 'id': '100', 'name': 'YOOAO'}
r = requests.post("http://httpbin.org/post", data=data)print(r.text)结果如下
{"args": {}, "data": "", "files": {}, "form": {"id": "100", "name": "YOOAO" }, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "17", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5ec8f4a0-affca27a05e320a84ca6535a" }, "json": null, "origin": "xxxx", "url": "http://httpbin.org/post"}从 form 中我们看到了自己提交的数据,可见我们的 POST 请求访问成功。
6、响应
访问URL时,有请求就会有响应,上面的示例使用 text 和 content 获取了响应的内容。除此以外,还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookies 等。
import requests
r = requests.get('http://127.0.0.1/')print(type(r.status_code), r.status_code)print(type(r.headers), r.headers)print(type(r.cookies), r.cookies)print(type(r.url), r.url)print(type(r.history), r.history)关于状态码,requests 还提供了一个内置的状态码查询对象 requests.codes,用法示例如下:
import requestsr = requests.get('http://127.0.0.1/')exit() if not r.status_code == requests.codes.ok else print('Request Successfully')==========执行结果==========Request Successfully这里通过比较返回码和内置的成功的返回码,来保证请求得到了正常响应,输出成功请求的消息,否则程序终止。
这里我们用 requests.codes.ok 得到的是成功的状态码 200。
这样的话,我们就不用再在程序里面写状态码对应的数字了,用字符串表示状态码会显得更加直观。
下面是响应码和查询条件对照信息:
# 信息性状态码 100: ('continue',), 101: ('switching_protocols',), 102: ('processing',), 103: ('checkpoint',), 122: ('uri_too_long', 'request_uri_too_long'),
# 成功状态码 200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'), 201: ('created',), 202: ('accepted',), 203: ('non_authoritative_info', 'non_authoritative_information'), 204: ('no_content',), 205: ('reset_content', 'reset'), 206: ('partial_content', 'partial'), 207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'), 208: ('already_reported',), 226: ('im_used',),
# 重定向状态码 300: ('multiple_choices',), 301: ('moved_permanently', 'moved', '\\o-'), 302: ('found',), 303: ('see_other', 'other'), 304: ('not_modified',), 305: ('use_proxy',), 306: ('switch_proxy',), 307: ('temporary_redirect', 'temporary_moved', 'temporary'), 308: ('permanent_redirect', 'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误状态码 400: ('bad_request', 'bad'), 401: ('unauthorized',), 402: ('payment_required', 'payment'), 403: ('forbidden',), 404: ('not_found', '-o-'), 405: ('method_not_allowed', 'not_allowed'), 406: ('not_acceptable',), 407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'), 408: ('request_timeout', 'timeout'), 409: ('conflict',), 410: ('gone',), 411: ('length_required',), 412: ('precondition_failed', 'precondition'), 413: ('request_entity_too_large',), 414: ('request_uri_too_large',), 415: ('unsupported_media_type', 'unsupported_media', 'media_type'), 416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'), 417: ('expectation_failed',), 418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'), 421: ('misdirected_request',), 422: ('unprocessable_entity', 'unprocessable'), 423: ('locked',), 424: ('failed_dependency', 'dependency'), 425: ('unordered_collection', 'unordered'), 426: ('upgrade_required', 'upgrade'), 428: ('precondition_required', 'precondition'), 429: ('too_many_requests', 'too_many'), 431: ('header_fields_too_large', 'fields_too_large'), 444: ('no_response', 'none'), 449: ('retry_with', 'retry'), 450: ('blocked_by_windows_parental_controls', 'parental_controls'), 451: ('unavailable_for_legal_reasons', 'legal_reasons'), 499: ('client_closed_request',),
# 服务端错误状态码 500: ('internal_server_error', 'server_error', '/o\\', '✗'), 501: ('not_implemented',), 502: ('bad_gateway',), 503: ('service_unavailable', 'unavailable'), 504: ('gateway_timeout',), 505: ('http_version_not_supported', 'http_version'), 506: ('variant_also_negotiates',), 507: ('insufficient_storage',), 509: ('bandwidth_limit_exceeded', 'bandwidth'), 510: ('not_extended',), 511: ('network_authentication_required', 'network_auth', 'network_authentication')7、SSL 证书验证
现在很多网站都会验证证书,我们可以设置参数来忽略证书的验证。
import requests
response = requests.get('https://XXXXXXXX', verify=False)print(response.status_code)或者制定本地证书作为客户端证书:
import requests
response = requests.get('https://xxxxxx', cert=('/path/server.crt', '/path/server.key'))print(response.status_code)注意:本地私有证书的 key 必须是解密状态,加密状态的 key 是不支持的。
8、设置超时
很多时候我们需要设置超时时间来控制访问的效率,遇到访问慢的链接直接跳过。
示例代码:
import requests# 设置超时时间为 10 秒r = requests.get('https://httpbin.org/get', timeout=10)print(r.status_code)将连接时间和读取时间分开计算:
r = requests.get('https://httpbin.org/get', timeout=(3, 10))不添加参数,默认不设置超时时间,等同于:
r = requests.get('https://httpbin.org/get', timeout=None)9、身份认证
遇到一些网站需要输入用户名和密码,我们可以通过 auth 参数进行设置。
import requests from requests.auth import HTTPBasicAuth # 用户名为 admin ,密码为 admin r = requests.get('https://xxxxxx/', auth=HTTPBasicAuth('admin', 'admin')) print(r.status_code)简化写法:
import requests
r = requests.get('https://xxxxxx', auth=('admin', 'admin'))print(r.status_code)10、设置代理
如果频繁的访问某个网站时,后期会被一些反爬程序识别,要求输入验证信息,或者其他信息,甚至IP被封无法再次访问,这时候,我们可以通过设置代理来避免这样的问题。
import requests
proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080",}
requests.get("http://example.org", proxies=proxies)若你的代理需要使用HTTP Basic Auth,可以使用
http://user:password@host/ 语法:
proxies = { "http": "http://user:pass@10.10.1.10:3128/",}要为某个特定的连接方式或者主机设置代理,使用 scheme://hostname 作为 key, 它会针对指定的主机和连接方式进行匹配。
proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}Atas ialah kandungan terperinci Cara menggunakan perpustakaan Permintaan perangkak Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1380
1380
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Penyimpanan Objek Minio: Penyebaran berprestasi tinggi di bawah CentOS System Minio adalah prestasi tinggi, sistem penyimpanan objek yang diedarkan yang dibangunkan berdasarkan bahasa Go, serasi dengan Amazons3. Ia menyokong pelbagai bahasa pelanggan, termasuk Java, Python, JavaScript, dan GO. Artikel ini akan memperkenalkan pemasangan dan keserasian minio pada sistem CentOS. Keserasian versi CentOS Minio telah disahkan pada pelbagai versi CentOS, termasuk tetapi tidak terhad kepada: CentOS7.9: Menyediakan panduan pemasangan lengkap yang meliputi konfigurasi kluster, penyediaan persekitaran, tetapan fail konfigurasi, pembahagian cakera, dan mini
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
