

Video ialah sumber kandungan media di mana-mana yang menyentuh banyak aspek kehidupan seharian orang ramai. Semakin banyak aplikasi video dunia sebenar, seperti sari kata video, analisis kandungan dan jawapan soalan video (VideoQA), bergantung pada model yang boleh menyambungkan kandungan video kepada teks atau bahasa semula jadi.
Antaranya, model soalan dan jawapan video amat mencabar kerana ia memerlukan pemahaman serentak maklumat semantik, seperti sasaran dalam tempat kejadian, dan maklumat temporal, seperti cara sesuatu bergerak dan berinteraksi. Kedua-dua jenis maklumat mesti diletakkan dalam konteks soalan bahasa semula jadi dengan maksud tertentu. Selain itu, memandangkan video mempunyai banyak bingkai, memproses kesemuanya untuk mempelajari maklumat spatiotemporal mungkin melarang pengiraan.

Pautan kertas: https://arxiv.org/pdf/2208.00934.pdf Untuk Untuk menyelesaikan masalah ini, dalam artikel "Menjawab Soalan Video dengan Tokenisasi Teks Video Berulang", penyelidik dari Google dan MIT memperkenalkan kaedah pembelajaran teks video baharu, yang dipanggil "Tokenisasi Bersama Berulang", yang secara berkesan boleh Gabungan maklumat spatial, temporal dan linguistik untuk pemprosesan maklumat dalam menjawab soalan video.

Pendekatan ini berbilang aliran, menggunakan model tulang belakang bebas untuk mengendalikan skala berbeza Video, menghasilkan perwakilan video yang menangkap ciri yang berbeza, seperti resolusi spatial tinggi atau video berdurasi panjang. Model ini menggunakan modul "pengesahan bersama" untuk mempelajari perwakilan yang berkesan daripada gabungan strim video dan teks. Model ini sangat cekap dari segi pengiraan, hanya memerlukan 67 GFLOP, iaitu sekurang-kurangnya 50% lebih rendah daripada kaedah sebelumnya, dan mempunyai prestasi yang lebih baik daripada model SOTA yang lain.
Matlamat utama model ini adalah untuk menjana ciri daripada video dan teks (iaitu soalan pengguna) yang bersama-sama membenarkan input yang sepadan untuk berinteraksi. Matlamat kedua adalah untuk melakukan ini dengan cara yang cekap, yang sangat penting untuk video kerana ia mengandungi puluhan hingga ratusan bingkai input.
Model belajar untuk melabelkan input bahasa video bersama ke dalam set label yang lebih kecil untuk mewakili kedua-dua modaliti secara bersama dan cekap. Semasa membuat token, penyelidik menggunakan kedua-dua mod untuk menghasilkan perwakilan padat bersama, yang dimasukkan ke dalam lapisan transformasi untuk menghasilkan perwakilan peringkat seterusnya.
Cabaran di sini, yang juga merupakan masalah biasa dalam pembelajaran silang mod, ialah bingkai video selalunya tidak sepadan secara langsung dengan teks yang berkaitan. Para penyelidik menyelesaikan masalah ini dengan menambahkan dua lapisan linear yang boleh dipelajari untuk menyatukan dimensi ciri visual dan teks sebelum tokenisasi. Ini membolehkan penyelidik mempunyai keadaan video dan teks bagaimana teg video dipelajari.
Selain itu, satu langkah tokenisasi tidak membenarkan interaksi lanjut antara kedua-dua mod. Untuk melakukan ini, penyelidik menggunakan perwakilan ciri baharu ini untuk berinteraksi dengan ciri input video dan menghasilkan satu lagi set ciri token, yang kemudiannya dimasukkan ke dalam lapisan pengubah seterusnya. Proses berulang ini mencipta ciri atau penanda baharu yang mewakili penambahbaikan berterusan perwakilan bersama kedua-dua mod. Akhir sekali, ciri ini dimasukkan ke dalam penyahkod yang menjana output teks.

Seperti amalan biasa dalam penilaian kualiti video, sebelum memperhalusi model pada set data penilaian kualiti video individu, penyelidik Buat latihan pra. Dalam kerja ini, penyelidik menganotasi video secara automatik dengan teks berdasarkan pengecaman pertuturan, menggunakan set data HowTo100M dan bukannya pra-latihan pada set data VideoQA yang besar. Data pra-latihan yang lebih lemah ini masih membolehkan model penyelidik mempelajari ciri teks video.
Penyelidik menggunakan algoritma pengesahan bersama lelaran bahasa video kepada tiga penanda aras VideoQA utama, MSRVTT-QA, MSVD-QA dan IVQA , dan menunjukkan bahawa pendekatan ini mencapai hasil yang lebih baik daripada model tercanggih lain tanpa menjadikan model terlalu besar. Di samping itu, pembelajaran label bersama berulang juga memerlukan kuasa pengkomputeran yang lebih rendah pada tugas pembelajaran teks video.
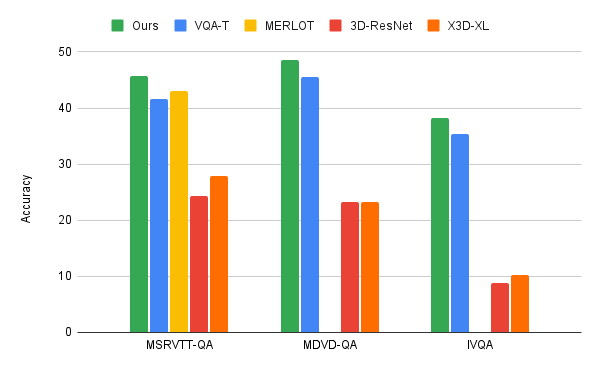
Model ini hanya menggunakan kuasa pengkomputeran 67GFLOPS, iaitu kuasa pengkomputeran yang diperlukan untuk model dan teks video 3D-ResNet ( 360GFLOPS ), yang lebih daripada dua kali lebih cekap daripada model X3D. dan menjana keputusan yang sangat tepat, melebihi kaedah terkini.
Untuk VideoQA atau beberapa tugas lain yang melibatkan input video, penyelidik mendapati bahawa input berbilang strim adalah lebih tepat untuk menjawab soalan tentang ruang dan temporal perhubungan Persoalannya amat penting.
Para penyelidik menggunakan tiga strim video dengan resolusi dan kadar bingkai yang berbeza: strim video input beresolusi rendah, kadar bingkai tinggi (32 bingkai sesaat, resolusi spatial 64x64, ditandakan sebagai 32x64x64 resolusi tinggi, video kadar bingkai rendah (8x224x224 dan satu di antaranya (16x112x112);
Walaupun jelas terdapat lebih banyak maklumat untuk diproses dengan tiga aliran data, model yang sangat cekap diperoleh kerana kaedah pelabelan bersama berulang. Pada masa yang sama, aliran data tambahan ini membolehkan maklumat yang paling relevan diekstrak.
Sebagai contoh, seperti yang ditunjukkan dalam rajah di bawah, soalan yang berkaitan dengan aktiviti tertentu akan menghasilkan pengaktifan yang lebih tinggi dalam input video dengan resolusi yang lebih rendah tetapi kadar bingkai yang lebih tinggi berbanding dengan aktiviti umum Soalan berkaitan boleh dijawab daripada input resolusi tinggi dengan beberapa bingkai.

Manfaat lain dari algoritma ini ialah tokenisasi akan berdasarkan soalan yang ditanya. Berbeza dan berubah.
Para penyelidik mencadangkan kaedah pembelajaran bahasa video baharu yang memfokuskan pada pembelajaran bersama merentas modaliti teks video. Penyelidik menangani tugas penting dan mencabar menjawab soalan video. Pendekatan penyelidik adalah cekap dan tepat, mengatasi prestasi model terkini walaupun lebih cekap.
Pendekatan penyelidik Google mempunyai saiz model yang sederhana dan boleh memperoleh peningkatan prestasi selanjutnya dengan model dan data yang lebih besar. Para penyelidik berharap kerja ini akan mencetuskan lebih banyak penyelidikan dalam pembelajaran bahasa visual untuk membolehkan interaksi yang lebih lancar dengan media berasaskan visual.
Atas ialah kandungan terperinci Model soal jawab video 'Persijilan Bersama Berulang' Google dan MIT: prestasi SOTA, menggunakan 80% kurang kuasa pengkomputeran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 sistem Hongmeng
sistem Hongmeng
 Apakah format video
Apakah format video
 Bagaimana untuk mengubah suai nama fail secara kelompok
Bagaimana untuk mengubah suai nama fail secara kelompok
 Bagaimana untuk menerangi Douyin kawan rapat
Bagaimana untuk menerangi Douyin kawan rapat
 Ringkasan ralat soket biasa
Ringkasan ralat soket biasa
 Bolehkah syiling BAGS disimpan lama?
Bolehkah syiling BAGS disimpan lama?
 Cara menghidupkan dan mematikan Douyin Xiaohuoren
Cara menghidupkan dan mematikan Douyin Xiaohuoren
 Bagaimanakah cara saya menyediakan WeChat untuk memerlukan persetujuan saya apabila orang menambahkan saya ke kumpulan?
Bagaimanakah cara saya menyediakan WeChat untuk memerlukan persetujuan saya apabila orang menambahkan saya ke kumpulan?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



