
 Peranti teknologi
AI
Universiti Sains dan Teknologi Shanghai dan lain-lain mengeluarkan DreamFace: hanya teks boleh menjana 'manusia digital 3D yang hiper-realistik'
Peranti teknologi
AI
Universiti Sains dan Teknologi Shanghai dan lain-lain mengeluarkan DreamFace: hanya teks boleh menjana 'manusia digital 3D yang hiper-realistik'
Universiti Sains dan Teknologi Shanghai dan lain-lain mengeluarkan DreamFace: hanya teks boleh menjana 'manusia digital 3D yang hiper-realistik'

Dengan pembangunan model bahasa besar (LLM), penyebaran (Diffusion) dan teknologi lain, kelahiran produk seperti ChatGPT dan Midjourney telah mencetuskan gelombang baru kegilaan AI, dan AI generatif juga telah menjadi topik yang amat membimbangkan.
Tidak seperti teks dan imej, penjanaan 3D masih dalam peringkat penerokaan teknologi.
Pada penghujung tahun 2022, Google, NVIDIA dan Microsoft telah melancarkan kerja penjanaan 3D mereka sendiri secara berturut-turut, tetapi kebanyakannya adalah berdasarkan ungkapan tersirat Neural Radiation Field (NeRF) dan tidak serasi dengan perisian 3D industri Saluran paip Rendering seperti Unity, Unreal Engine dan Maya tidak serasi.
Walaupun ia ditukar kepada peta geometri dan warna yang dinyatakan oleh Mesh melalui penyelesaian tradisional, ia akan menyebabkan ketepatan yang tidak mencukupi dan kualiti visual yang berkurangan, dan tidak boleh digunakan secara langsung pada pengeluaran filem dan televisyen dan pengeluaran permainan.

Tapak web projek: https://sites.google.com/view/dreamface
Alamat kertas: https://arxiv.org/abs/2304.03117
Demo Web: https ://hyperhuman.top
Ruang Muka Peluk: https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
Untuk menyelesaikan masalah ini, pasukan R&D dari Yingmo Technology dan ShanghaiTech University mencadangkan rangka kerja penjanaan 3D progresif berpandukan teks.
Rangka kerja memperkenalkan set data luaran (termasuk bahan geometri dan PBR) yang mematuhi piawaian pengeluaran CG, dan boleh menjana secara langsung aset 3D yang mematuhi piawaian ini berdasarkan teks pertama untuk menyokong rangka kerja Sedia Pengeluaran A untuk penjanaan aset 3D.
Untuk mencapai manusia digital hiper-realistik 3D yang dipacu penjanaan teks, pasukan itu menggabungkan rangka kerja ini dengan set data manusia digital 3D gred pengeluaran. Kerja ini telah diterima oleh Transactions on Graphics, jurnal antarabangsa teratas dalam bidang grafik komputer, dan akan dibentangkan di SIGGRAPH 2023, persidangan grafik komputer antarabangsa teratas.
DreamFace terutamanya merangkumi tiga modul, penjanaan geometri, penyebaran bahan berasaskan fizik dan penjanaan keupayaan animasi.
Berbanding dengan karya generasi 3D sebelumnya, sumbangan utama karya ini termasuk:
· Cadangan DreamFace Novel ini pendekatan generatif menggabungkan model bahasa visual terkini dengan aset muka boleh animasi dan fizikal, menggunakan pembelajaran progresif untuk memisahkan geometri, rupa dan keupayaan animasi.
· Memperkenalkan reka bentuk penjanaan penampilan dwi saluran, menggabungkan model penyebaran bahan novel dengan model pra-latihan, serentak dalam ruang terpendam dan ruang imej Lakukan pengoptimuman dua peringkat.
· Aset muka menggunakan BlendShapes atau Personalized BlendShapes yang dihasilkan mempunyai keupayaan animasi dan seterusnya menunjukkan penggunaan DreamFace untuk reka bentuk watak semula jadi.
Penjanaan geometri
Modul penjanaan geometri boleh menjana model geometri yang konsisten berdasarkan gesaan teks. Walau bagaimanapun, apabila ia datang untuk menghadapi penjanaan, ini boleh menjadi sukar untuk diawasi dan berkumpul.
Oleh itu, DreamFace mencadangkan rangka kerja pemilihan berdasarkan CLIP (Contrastive Language-Image Pra-Training), yang mula-mula memilih calon terbaik daripada calon sampel rawak dalam ruang parameter geometri muka model geometri kasar yang baik dan kemudian memahat butiran geometri untuk menjadikan model kepala lebih konsisten dengan gesaan teks.
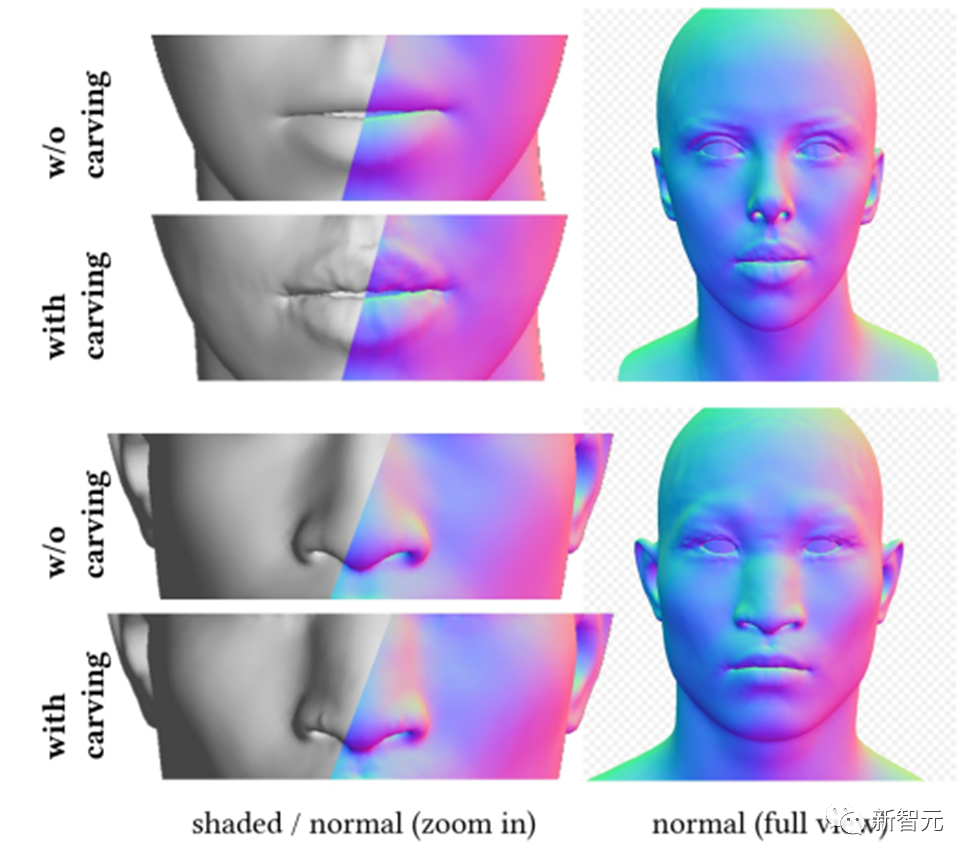
Menurut gesaan input, DreamFace menggunakan model CLIP untuk memilih calon geometri kasar dengan skor padanan tertinggi. Seterusnya, DreamFace menggunakan model resapan tersirat (LDM) untuk melakukan pemprosesan Pensampelan Penyulingan Berskor (SDS) pada imej yang diberikan di bawah sudut tontonan rawak dan keadaan pencahayaan.
Ini membolehkan DreamFace menambah butiran muka pada model geometri kasar melalui anjakan bucu dan peta normal yang terperinci, menghasilkan geometri yang sangat terperinci.
Sama seperti model kepala, DreamFace juga membuat pilihan gaya rambut dan warna berdasarkan rangka kerja ini.
Penjanaan resapan bahan berasaskan fizikal
Modul resapan bahan berasaskan fizikal direka untuk meramalkan tekstur muka yang konsisten dengan geometri dan isyarat teks yang diramalkan.
Pertama, DreamFace memperhalusi LDM pra-latihan pada set data bahan UV berskala besar yang dikumpul untuk mendapatkan dua model penyebaran LDM.

DreamFace menggunakan skema latihan bersama yang menyelaraskan dua proses penyebaran, satu untuk menafikan secara langsung peta tekstur UV dan satu lagi digunakan untuk mengawasi imej yang diberikan untuk memastikan pembentukan peta UV muka yang betul dan imej yang dihasilkan konsisten dengan isyarat teks.
Untuk mengurangkan masa penjanaan, DreamFace menggunakan peringkat resapan potensi tekstur kasar untuk menyediakan potensi priori untuk penjanaan tekstur terperinci.
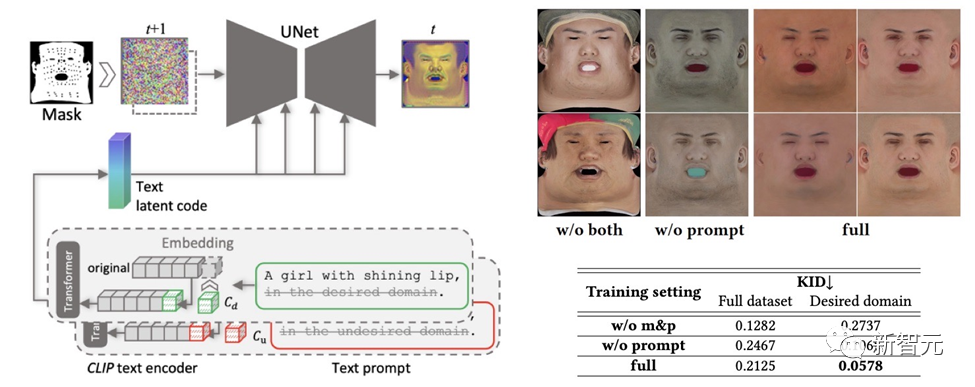
Untuk memastikan peta tekstur yang dibuat tidak mengandungi ciri atau situasi pencahayaan yang tidak diingini sambil mengekalkan kepelbagaian, reka bentuk A strategi pembelajaran cued.
Pasukan menggunakan dua kaedah untuk menjana peta meresap berkualiti tinggi:
(1) Penalaan Segera. Tidak seperti isyarat teks khusus domain buatan tangan, DreamFace menggabungkan dua isyarat teks berterusan khusus domain Cd dan Cu dengan isyarat teks yang sepadan, yang akan dioptimumkan semasa latihan denoiser U-Net untuk mengelakkan ketidakstabilan dan penulisan gesaan manual yang memakan masa.
(2) Topeng bukan kawasan muka. Proses denoising LDM akan dikekang tambahan oleh topeng bukan kawasan muka untuk memastikan peta meresap yang terhasil tidak mengandungi sebarang unsur yang tidak diingini.
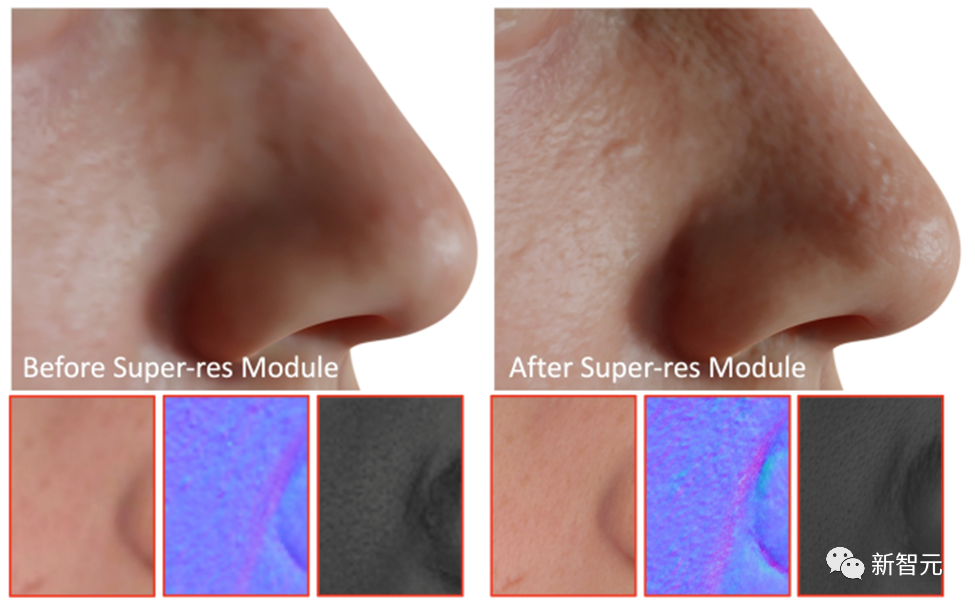
Sebagai langkah terakhir, DreamFace menggunakan modul resolusi super untuk menjana tekstur berasaskan fizikal 4K untuk kualiti tinggi rendering.

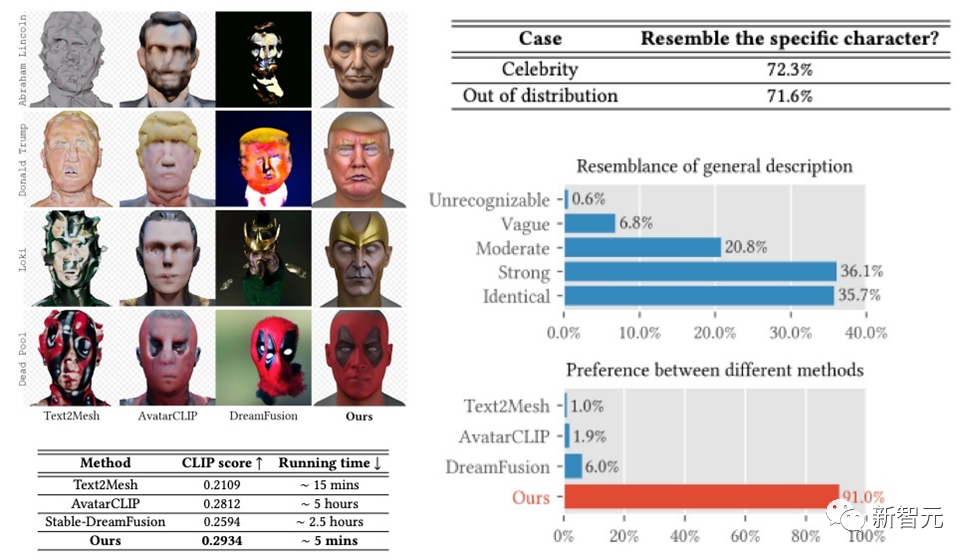
Rangka kerja DreamFace telah mencapai hasil yang cukup baik dalam menjana selebriti dan menjana watak berdasarkan huraian Dalam Kajian Pengguna Diperolehi keputusan yang jauh melebihi kerja sebelumnya. Berbanding dengan kerja sebelumnya, ia juga mempunyai kelebihan yang jelas dalam masa berjalan.
Selain itu, DreamFace juga menyokong penyuntingan tekstur menggunakan pembayang dan lakaran. Kesan penyuntingan global seperti penuaan dan solek boleh dicapai dengan terus menggunakan tekstur LDM dan isyarat yang diperhalusi. Dengan menggabungkan lagi topeng atau lakaran, pelbagai kesan boleh dicipta seperti tatu, janggut, dan tanda lahir.

Penjanaan keupayaan animasi
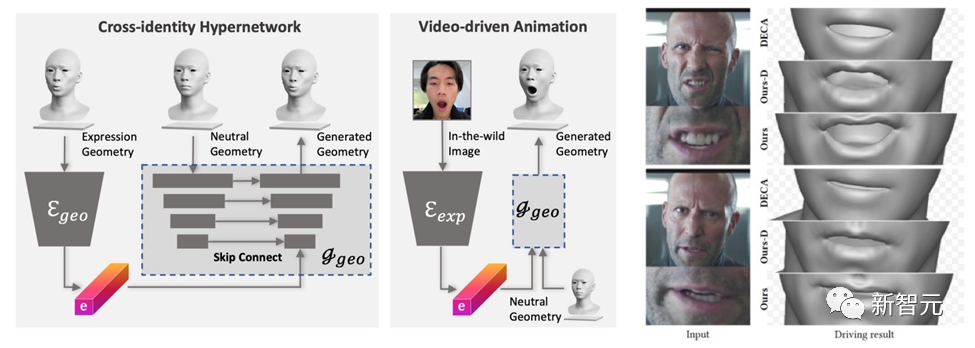
Model yang dihasilkan oleh DreamFace mempunyai keupayaan animasi. Tidak seperti kaedah berasaskan BlendShapes, kaedah animasi muka saraf DreamFace menghasilkan animasi diperibadikan dengan meramalkan ubah bentuk unik untuk menghidupkan model Neutral yang terhasil.
Pertama, penjana geometri dilatih untuk mempelajari ruang terpendam ungkapan, di mana penyahkod dilanjutkan untuk dikondisikan pada geometri neutral. Kemudian, pengekod ekspresi dilatih lagi untuk mengekstrak ciri ekspresi daripada imej RGB. Oleh itu, DreamFace mampu menjana animasi diperibadikan yang dikondisikan pada bentuk geometri neutral menggunakan imej RGB monokular.
Berbanding DECA yang menggunakan BlendShapes generik untuk kawalan ekspresi, rangka kerja DreamFace memberikan butiran ekspresi yang halus dan mampu menangkap persembahan dengan perincian yang halus.
Kesimpulan
Kertas kerja ini memperkenalkan DreamFace, rangka kerja penjanaan 3D progresif berpandukan teks yang menggabungkan model bahasa visual terkini, model Difusi tersirat dan secara fizikal berasaskan teknik penyebaran bahan.
Inovasi utama DreamFace termasuk penjanaan geometri, penjanaan penyebaran bahan berasaskan fizikal dan penjanaan keupayaan animasi. Berbanding dengan kaedah penjanaan 3D tradisional, DreamFace mempunyai ketepatan yang lebih tinggi, kelajuan larian yang lebih pantas dan keserasian saluran paip CG yang lebih baik.
Rangka kerja penjanaan progresif DreamFace menyediakan penyelesaian yang berkesan untuk menyelesaikan tugas penjanaan 3D yang kompleks dan dijangka mempromosikan penyelidikan dan pembangunan teknologi yang lebih serupa.
Selain itu, penjanaan penyebaran bahan berasaskan fizikal dan penjanaan keupayaan animasi akan menggalakkan aplikasi teknologi penjanaan 3D dalam pengeluaran filem dan televisyen, pembangunan permainan dan industri lain yang berkaitan.
Atas ialah kandungan terperinci Universiti Sains dan Teknologi Shanghai dan lain-lain mengeluarkan DreamFace: hanya teks boleh menjana 'manusia digital 3D yang hiper-realistik'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1666
1666
 14
1425
52
1327
25
1273
29
1253
24
14
1425
52
1327
25
1273
29
1253
24

 Universiti Sains dan Teknologi Shanghai dan lain-lain mengeluarkan DreamFace: hanya teks boleh menjana 'manusia digital 3D yang hiper-realistik'
May 17, 2023 am 08:02 AM
Universiti Sains dan Teknologi Shanghai dan lain-lain mengeluarkan DreamFace: hanya teks boleh menjana 'manusia digital 3D yang hiper-realistik'
May 17, 2023 am 08:02 AM
Dengan pembangunan model bahasa besar (LLM), penyebaran (Difusi) dan teknologi lain, kelahiran produk seperti ChatGPT dan Midjourney telah mencetuskan gelombang baru kegilaan AI, dan AI generatif juga telah menjadi topik yang sangat membimbangkan. Tidak seperti teks dan imej, penjanaan 3D masih dalam peringkat penerokaan teknologi. Pada penghujung tahun 2022, Google, NVIDIA dan Microsoft telah melancarkan kerja penjanaan 3D mereka sendiri secara berturut-turut, tetapi kebanyakannya adalah berdasarkan ungkapan tersirat medan sinaran saraf lanjutan (NeRF) dan tidak serasi dengan saluran paip pemaparan perisian 3D industri seperti Unity , UnrealEngine dan Maya. Walaupun ia ditukar kepada peta geometri dan warna yang dinyatakan oleh Mesh melalui penyelesaian tradisional, ia akan menyebabkan kekurangan ketepatan.
 Model besar popular dengan orang digital: satu ayat boleh disesuaikan dalam masa 5 minit, dan ia boleh dipegang sambil menari, mengacara dan menghantar barangan
May 08, 2024 pm 08:10 PM
Model besar popular dengan orang digital: satu ayat boleh disesuaikan dalam masa 5 minit, dan ia boleh dipegang sambil menari, mengacara dan menghantar barangan
May 08, 2024 pm 08:10 PM
Dalam masa seawal 5 minit, anda boleh mencipta manusia digital 3D yang boleh pergi terus ke tempat kerja. Ini adalah kejutan terbaru yang dibawa oleh model besar ke bidang manusia digital. Sama seperti ini, satu ayat menerangkan permintaan: orang digital yang dijana boleh terus memasuki bilik siaran langsung dan berfungsi sebagai sauh. Tidak ada masalah untuk menari dalam tarian kumpulan perempuan. Semasa keseluruhan proses pengeluaran, sebut sahaja apa sahaja yang terlintas di fikiran Model besar boleh membuka keperluan secara automatik dan anda boleh mendapatkan reka bentuk dan mengubah suai idea dengan serta-merta. △Dengan kelajuan 2x ganda, anda tidak perlu lagi risau tentang idea bos/Parti A yang terlalu baru. Teknologi manusia digital Vincent sedemikian datang daripada keluaran terbaru Baidu Intelligent Cloud. Ia tidak sepatutnya dikatakan, tetapi sudah tiba masanya untuk mengurangkan ambang untuk orang digital menggunakannya dalam satu masa. Selepas mendengar tentang artifak sebegitu, kami serta-merta memperoleh kelayakan untuk ujian dalaman seperti biasa Mari kita lihat butiran lanjut~ Dalam 5 minit dalam satu ayat, lelaki digital 3D akan bertugas secara langsung.
 Alamak, saya dikelilingi oleh rakan sekerja digital! Pekerja digital Xiaobing AI dinaik taraf semula, dengan penyesuaian sampel sifar dan pekerjaan segera
Jul 19, 2024 pm 05:52 PM
Alamak, saya dikelilingi oleh rakan sekerja digital! Pekerja digital Xiaobing AI dinaik taraf semula, dengan penyesuaian sampel sifar dan pekerjaan segera
Jul 19, 2024 pm 05:52 PM
"Helo, saya baru sahaja menyertai syarikat kami. Jika saya mempunyai sebarang soalan tentang perniagaan, sila berikan saya nasihat anda!" Ia hanya mengambil 30 saat imej, 10 saat audio dan 10 minit untuk menyesuaikan "rakan sekerja digital" dengan cepat yang tidak berbeza daripada orang sebenar. Ia boleh berinteraksi secara langsung dengan anda dalam masa nyata, dan mempunyai penghantaran audio dan video dan video berkualiti tinggi dan kependaman rendah di peringkat operator komunikasi. Seperti ini: Seperti ini: Ini ialah teknologi "Rendering Neural Xiaoice, Zero-XNR" terbaharu yang dilancarkan oleh Xiaoice Bergantung pada asas model besar lebih 100 bilion, teknologi baharu
 Orang digital menyalakan obor utama Sukan Asia, dan kertas ICCV ini mendedahkan teknologi hitam AI generatif Ant
Sep 29, 2023 pm 11:57 PM
Orang digital menyalakan obor utama Sukan Asia, dan kertas ICCV ini mendedahkan teknologi hitam AI generatif Ant
Sep 29, 2023 pm 11:57 PM
Buka manusia digital dan ia akan penuh dengan AI generatif. Pada petang 23 September, pada majlis perasmian Sukan Asia Hangzhou, penyalaan obor utama menunjukkan "api kecil" ratusan juta pembawa obor digital dalam talian berkumpul di Sungai Qiantang, membentuk imej manusia digital . Kemudian, pembawa obor manusia digital dan pembawa obor keenam di tapak berjalan ke pentas obor bersama-sama dan menyalakan obor utama bersama-sama Sebagai idea teras majlis perasmian, format lampu obor yang saling berkaitan digital menjadi topik carian hangat , membangkitkan minat orang ramai. Kandungan yang ditulis semula: Sebagai idea teras majlis perasmian, kaedah pencahayaan obor Internet Realiti Digital telah membangkitkan perbincangan hangat dan menarik perhatian orang ramai adalah inisiatif yang belum pernah berlaku sebelum ini, melibatkan ratusan juta orang sejumlah besar teknologi canggih dan Kompleks. Salah satu soalan yang paling penting ialah bagaimana
 DreamFace: Hasilkan manusia digital 3D dalam satu ayat?
May 16, 2023 pm 09:46 PM
DreamFace: Hasilkan manusia digital 3D dalam satu ayat?
May 16, 2023 pm 09:46 PM
Hari ini, dengan perkembangan pesat sains dan teknologi, penyelidikan dalam bidang kecerdasan buatan generatif dan grafik komputer semakin menarik perhatian Industri seperti pengeluaran filem dan televisyen serta pembangunan permainan menghadapi cabaran dan peluang yang besar. Artikel ini akan memperkenalkan anda kepada penyelidikan dalam bidang penjanaan 3D - DreamFace, yang merupakan rangka kerja penjanaan 3D progresif berpandukan teks pertama yang menyokong penjanaan aset Production-Ready3D, dan boleh merealisasikan orang digital hiper-realistik 3D yang dipacu penjanaan teks. Kerja ini telah diterima oleh Transactionson Graphics, jurnal antarabangsa teratas dalam bidang grafik komputer, dan akan dibentangkan di persidangan grafik komputer antarabangsa teratas SIGGRAPH2023. Laman web projek: https://sites.
 Yang Dong, Pengarah Teknikal Platform Unity Greater China: Memulakan Perjalanan Manusia Digital dalam Metaverse
Apr 08, 2023 pm 06:11 PM
Yang Dong, Pengarah Teknikal Platform Unity Greater China: Memulakan Perjalanan Manusia Digital dalam Metaverse
Apr 08, 2023 pm 06:11 PM
Sebagai asas pembinaan kandungan Metaverse, orang digital adalah senario matang terawal untuk subbahagian metaverse yang boleh dilaksanakan dan dibangunkan secara mampan Pada masa ini, aplikasi komersial seperti idola maya, penghantaran e-dagang, pengehosan TV dan sauh maya telah diiktiraf oleh. orang ramai. Dalam dunia Metaverse, salah satu kandungan yang paling teras adalah tidak lain daripada manusia digital, kerana manusia digital bukan sahaja "jelmaan" manusia dunia sebenar dalam Metaverse, mereka juga merupakan salah satu kenderaan penting untuk kita menjalankan pelbagai interaksi dalam satu Metaverse. Umum mengetahui bahawa mencipta dan mempersembahkan watak manusia digital yang realistik adalah salah satu masalah paling sukar dalam grafik komputer. Baru-baru ini, di venue cawangan "Interaksi Permainan dan AI" MetaCon Metaverse Technology yang dihoskan oleh 51CTO, Pengarah Teknikal Platform Unity Greater China Yang Dong telah memberikan satu siri demonstrasi Demo
 AI+Digital Human Realisasi Interaksi Baharu China Telecom Membawa AI kepada Kehidupan Pintar
May 27, 2023 pm 12:34 PM
AI+Digital Human Realisasi Interaksi Baharu China Telecom Membawa AI kepada Kehidupan Pintar
May 27, 2023 pm 12:34 PM
(Sumber foto: Rangkaian Foto) (Pemberita Chen Jinfeng) Baru-baru ini, Festival Penggunaan Maklumat Shanghai 2023 bermula, dan "orang digital" telah menjadi protagonis yang tidak dapat dielakkan. Orang dalam industri percaya bahawa aplikasi teknologi AI akan mempercepatkan pembangunan kandungan berkualiti tinggi, dan orang digital maya mungkin menjadi pintu masuk trafik baharu. Orang digital AI memasuki kehidupan seharian Dengan perkembangan kecerdasan buatan, realiti maya dan teknologi lain, orang digital maya memasuki kehidupan harian manusia dan memainkan peranan unik dalam banyak bidang. Pakar kecantikan maya Liu Yexi menerima lebih satu juta suka dalam masa tiga hari selepas debut Douyin, menjadi idola maya teratas di China semalaman di konsert Malam Tahun Baru Jiangsu Satellite TV, bekas penyanyi Teresa Teng kembali ke pentas nyanyian bersama penyanyi Zhou Shen di pentas yang sama, menjalin kenangan muda beberapa generasi lebih daripada 20 orang digital muncul di pentas yang sama di Sukan Olimpik Musim Sejuk, berkhidmat sebagai protagonis bahasa isyarat
 Apakah manusia digital dan apakah masa depan?
Oct 16, 2023 pm 02:25 PM
Apakah manusia digital dan apakah masa depan?
Oct 16, 2023 pm 02:25 PM
Dalam dunia teknologi yang maju hari ini, manusia digital seperti hidup telah menjadi bidang baru muncul yang menarik banyak perhatian. Sebagai imej maya digital yang hampir dengan imej manusia yang dicipta berdasarkan teknologi grafik komputer (CG) dan teknologi kecerdasan buatan, manusia digital boleh menyediakan perkhidmatan yang lebih mudah, cekap dan diperibadikan kepada orang ramai. Pada masa yang sama, kemunculan orang digital juga boleh menggalakkan pembangunan ekonomi maya dan menyediakan lebih banyak peluang untuk inovasi kandungan digital dan penggunaan digital. Menurut laporan yang dikeluarkan oleh International Data Corporation (IDC), pasaran manusia digital maya global dijangka mencecah AS$27 bilion pada 2025, dengan kadar pertumbuhan tahunan kompaun sebanyak 22.5%. Dapat dilihat bahawa manusia digital mempunyai prospek aplikasi dan potensi pasaran yang sangat luas. Apakah orang digital? Orang digital bertuah
