
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk melaksanakan Parser keturunan rekursif dalam Python
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk melaksanakan Parser keturunan rekursif dalam Python
Bagaimana untuk melaksanakan Parser keturunan rekursif dalam Python

1. Penilaian ungkapan aritmetik
Untuk menghuraikan jenis teks ini, satu lagi peraturan tatabahasa yang khusus diperlukan. Kami memperkenalkan di sini peraturan tatabahasa Backus Normal Form (BNF) dan Extended Backus Normal Form (EBNF) yang boleh mewakili tatabahasa bebas konteks. Daripada sekecil ungkapan operasi aritmetik kepada sebesar hampir semua bahasa pengaturcaraan, ia ditakrifkan menggunakan tatabahasa tanpa konteks.
Untuk ungkapan operasi aritmetik yang mudah, diandaikan bahawa kami telah menggunakan teknologi pembahagian perkataan untuk menukarnya kepada aliran token input, seperti NUM+NUM*NUM (lihat catatan blog sebelumnya untuk kaedah pembahagian perkataan).
Atas dasar ini, kami mentakrifkan peraturan BNF seperti berikut:
expr ::= expr + term
| expr - term
| term
term ::= term * factor
| term / factor
| factor
factor ::= (expr)
| NUMSudah tentu kaedah ini tidak cukup ringkas dan jelas Apa yang sebenarnya kami gunakan ialah borang EBNF:
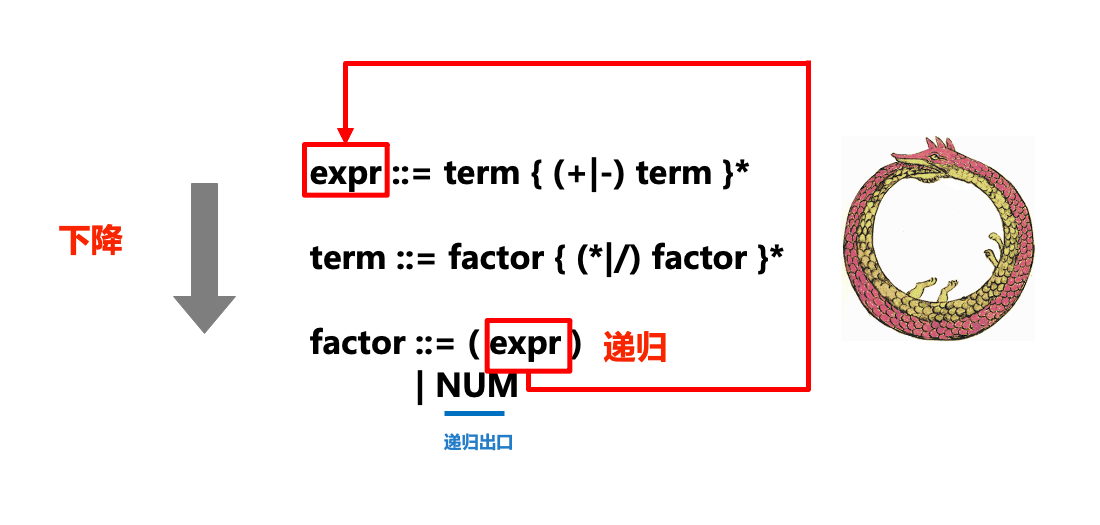
expr ::= term { (+|-) term }*
term ::= factor { (*|/) factor }*
factor ::= (expr)
| NUMSetiap peraturan BNF dan EBNF (ungkapan dalam bentuk ::=) boleh dianggap sebagai penggantian, iaitu simbol di sebelah kiri boleh digantikan dengan simbol di sebelah kanan. Kami cuba menggunakan BNF/EBNF untuk memadankan teks input dengan peraturan tatabahasa semasa proses penghuraian untuk melengkapkan pelbagai penggantian dan pengembangan. Dalam EBNF, peraturan yang diletakkan dalam {...}* adalah pilihan dan * menunjukkan bahawa peraturan itu boleh diulang sifar atau lebih kali (bersamaan dengan ungkapan biasa).
Rajah berikut dengan jelas menunjukkan hubungan antara bahagian "rekursi" dan "keturunan" bagi penghurai turunan rekursif (penghurai) dan ENBF:
Dalam amalan Semasa proses penghuraian, kami mengimbas aliran token dari kiri ke kanan, dan memproses token semasa proses pengimbasan Jika ia tersekat, ralat sintaks akan dihasilkan. Setiap peraturan tatabahasa ditukar kepada fungsi atau kaedah Contohnya, peraturan ENBF di atas ditukar kepada kaedah berikut:
class ExpressionEvaluator():
...
def expr(self):
...
def term(self):
...
def factor(self):
...Dalam proses memanggil kaedah yang sepadan dengan peraturan, jika kita menemui simbol seterusnya. Jika kita perlu menggunakan peraturan lain untuk dipadankan, kita akan "menurun" ke kaedah peraturan lain (seperti memanggil istilah dalam expr dan faktor dalam istilah), iaitu bahagian "menurun" daripada keturunan rekursif.
Kadangkala kaedah yang sudah dilaksanakan dipanggil (contohnya, istilah dipanggil dalam expr, faktor dipanggil dalam istilah, dan expr dipanggil dalam faktor, yang bersamaan dengan ouroboros), iaitu keturunan rekursif. Bahagian "rekursif".
Untuk bahagian berulang yang muncul dalam tatabahasa (seperti expr ::= term { (+|-) term }*), kami melaksanakannya melalui gelung sementara.
Mari kita lihat pelaksanaan kod khusus. Yang pertama ialah bahagian segmentasi perkataan Mari kita rujuk artikel sebelum ini untuk memperkenalkan kod blog segmentasi perkataan.
import re
import collections
# 定义匹配token的模式
NUM = r'(?P<NUM>\d+)' # \d表示匹配数字,+表示任意长度
PLUS = r'(?P<PLUS>\+)' # 注意转义
MINUS = r'(?P<MINUS>-)'
TIMES = r'(?P<TIMES>\*)' # 注意转义
DIVIDE = r'(?P<DIVIDE>/)'
LPAREN = r'(?P<LPAREN>\()' # 注意转义
RPAREN = r'(?P<RPAREN>\))' # 注意转义
WS = r'(?P<WS>\s+)' # 别忘记空格,\s表示空格,+表示任意长度
master_pat = re.compile(
'|'.join([NUM, PLUS, MINUS, TIMES, DIVIDE, LPAREN, RPAREN, WS]))
# Tokenizer
Token = collections.namedtuple('Token', ['type', 'value'])
def generate_tokens(text):
scanner = master_pat.scanner(text)
for m in iter(scanner.match, None):
tok = Token(m.lastgroup, m.group())
if tok.type != 'WS': # 过滤掉空格符
yield tokBerikut ialah pelaksanaan khusus penilai ungkapan:
class ExpressionEvaluator():
""" 递归下降的Parser实现,每个语法规则都对应一个方法,
使用 ._accept()方法来测试并接受当前处理的token,不匹配不报错,
使用 ._except()方法来测试当前处理的token,并在不匹配的时候抛出语法错误
"""
def parse(self, text):
""" 对外调用的接口 """
self.tokens = generate_tokens(text)
self.tok, self.next_tok = None, None # 已匹配的最后一个token,下一个即将匹配的token
self._next() # 转到下一个token
return self.expr() # 开始递归
def _next(self):
""" 转到下一个token """
self.tok, self.next_tok = self.next_tok, next(self.tokens, None)
def _accept(self, tok_type):
""" 如果下一个token与tok_type匹配,则转到下一个token """
if self.next_tok and self.next_tok.type == tok_type:
self._next()
return True
else:
return False
def _except(self, tok_type):
""" 检查是否匹配,如果不匹配则抛出异常 """
if not self._accept(tok_type):
raise SyntaxError("Excepted"+tok_type)
# 接下来是语法规则,每个语法规则对应一个方法
def expr(self):
""" 对应规则: expression ::= term { ('+'|'-') term }* """
exprval = self.term() # 取第一项
while self._accept("PLUS") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.term()
if op == "PLUS":
exprval += right
elif op == "MINUS":
exprval -= right
return exprval
def term(self):
""" 对应规则: term ::= factor { ('*'|'/') factor }* """
termval = self.factor() # 取第一项
while self._accept("TIMES") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.factor()
if op == "TIMES":
termval *= right
elif op == "DIVIDE":
termval /= right
return termval
def factor(self):
""" 对应规则: factor ::= NUM | ( expr ) """
if self._accept("NUM"): # 递归出口
return int(self.tok.value)
elif self._accept("LPAREN"):
exprval = self.expr() # 继续递归下去求表达式值
self._except("RPAREN") # 别忘记检查是否有右括号,没有则抛出异常
return exprval
else:
raise SyntaxError("Expected NUMBER or LPAREN")Kami memasukkan ungkapan berikut untuk ujian:
e = ExpressionEvaluator()
print(e.parse("2"))
print(e.parse("2+3"))
print(e.parse("2+3*4"))
print(e.parse("2+(3+4)*5"))Hasil penilaian adalah seperti berikut:
2
5
14
37
Jika teks yang kami masukkan tidak mematuhi peraturan tatabahasa:
print(e.parse("2 + (3 + * 4)")), a Pengecualian SyntaxError akan dilemparkan: Expected NUMBER or LPAREN.
Ringkasnya, dapat dilihat bahawa algoritma penilaian ekspresi kami berjalan dengan betul.
2. Hasilkan pokok ekspresi
Di atas kita mendapat hasil ungkapan, tetapi bagaimana jika kita ingin menganalisis struktur ungkapan dan menjana pokok penghuraian ungkapan yang mudah? Kemudian kita perlu membuat pengubahsuaian tertentu kepada kaedah kelas di atas:
class ExpressionTreeBuilder(ExpressionEvaluator):
def expr(self):
""" 对应规则: expression ::= term { ('+'|'-') term }* """
exprval = self.term() # 取第一项
while self._accept("PLUS") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.term()
if op == "PLUS":
exprval = ('+', exprval, right)
elif op == "MINUS":
exprval -= ('-', exprval, right)
return exprval
def term(self):
""" 对应规则: term ::= factor { ('*'|'/') factor }* """
termval = self.factor() # 取第一项
while self._accept("TIMES") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.factor()
if op == "TIMES":
termval = ('*', termval, right)
elif op == "DIVIDE":
termval = ('/', termval, right)
return termval
def factor(self):
""" 对应规则: factor ::= NUM | ( expr ) """
if self._accept("NUM"): # 递归出口
return int(self.tok.value) # 字符串转整形
elif self._accept("LPAREN"):
exprval = self.expr() # 继续递归下去求表达式值
self._except("RPAREN") # 别忘记检查是否有右括号,没有则抛出异常
return exprval
else:
raise SyntaxError("Expected NUMBER or LPAREN")Masukkan ungkapan berikut untuk menguji:
print(e.parse("2+3"))
print(e.parse("2+3*4"))
print(e.parse("2+(3+4)*5"))
print(e.parse('2+3+4'))Berikut ialah hasil yang dijana:
('+ ', 2, 3)
('+', 2, ('*', 3, 4))
('+', 2, ('*', ('+' , 3, 4) , 5))
('+', ('+', 2, 3), 4)
Anda dapat melihat bahawa pokok ungkapan dijana dengan betul.
Contoh kami di atas adalah sangat mudah, tetapi penghurai keturunan rekursif juga boleh digunakan untuk melaksanakan penghurai yang agak kompleks Contohnya, kod Python dihuraikan melalui penghurai keturunan rekursif. Jika anda berminat dengan ini, anda boleh menyemak fail Grammar dalam kod sumber Python untuk mengetahui. Walau bagaimanapun, seperti yang akan kita lihat di bawah, menulis parser sendiri datang dengan pelbagai perangkap dan cabaran.
Rekursi kiri dan perangkap keutamaan pengendali
Sebarang peraturan tatabahasa yang melibatkan bentuk rekursi kiri tidak boleh diselesaikan oleh penghurai keturunan rekursif. Apa yang dipanggil rekursi kiri bermaksud bahawa simbol paling kiri di sebelah kanan ungkapan peraturan ialah pengepala peraturan Contohnya, untuk peraturan berikut:
items ::= items ',' item
| itemUntuk melengkapkan analisis, anda boleh mentakrifkan kaedah berikut. :
def items(self):
itemsval = self.items() # 取第一项,然而此处会无穷递归!
if itemsval and self._accept(','):
itemsval.append(self.item())
else:
itemsval = [self.item()] Ini akan Dalam baris pertama, self.items() dipanggil tak terhingga, mengakibatkan ralat pengulangan tak terhingga.
Terdapat juga ralat dalam peraturan tatabahasa itu sendiri, seperti keutamaan pengendali. Jika kita mengabaikan keutamaan pengendali, kita boleh secara langsung memudahkan ungkapan seperti berikut:
expr ::= factor { ('+'|'-'|'*'|'/') factor }*
factor ::= '(' expr ')'
| NUMPYTHON Salin skrin penuh
Sintaks ini boleh dilaksanakan secara teknikal, tetapi konvensyen susunan pengiraan tidak diikuti, mengakibatkan "3+4 *5" menilai kepada 35 dan bukannya 23 yang dijangkakan. Oleh itu, peraturan expr dan istilah yang berasingan diperlukan untuk memastikan ketepatan keputusan pengiraan.
Atas ialah kandungan terperinci Bagaimana untuk melaksanakan Parser keturunan rekursif dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1206
24
52
1206
24

 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
 PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP berasal pada tahun 1994 dan dibangunkan oleh Rasmuslerdorf. Ia pada asalnya digunakan untuk mengesan pelawat laman web dan secara beransur-ansur berkembang menjadi bahasa skrip sisi pelayan dan digunakan secara meluas dalam pembangunan web. Python telah dibangunkan oleh Guidovan Rossum pada akhir 1980 -an dan pertama kali dikeluarkan pada tahun 1991. Ia menekankan kebolehbacaan dan kesederhanaan kod, dan sesuai untuk pengkomputeran saintifik, analisis data dan bidang lain.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
