
 pembangunan bahagian belakang
Tutorial Python
Cara menggunakan Python untuk membangunkan rangka kerja web tersuai
pembangunan bahagian belakang
Tutorial Python
Cara menggunakan Python untuk membangunkan rangka kerja web tersuai
Cara menggunakan Python untuk membangunkan rangka kerja web tersuai

Membangunkan rangka kerja web tersuai
Terima permintaan sumber dinamik daripada pelayan web dan sediakan pelayan web dengan perkhidmatan untuk memproses permintaan sumber dinamik. Tentukan berdasarkan nama akhiran laluan sumber yang diminta:
Jika nama akhiran laluan sumber yang diminta ialah .html, ia adalah permintaan sumber dinamik dan diproses oleh program rangka kerja web.
Jika tidak, ia adalah permintaan sumber statik, biarkan program pelayan web mengendalikannya.
1. Bangunkan program utama pelayan Web
1 Terima permintaan HTTP klien (lapisan bawah ialah TCP)
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
from socket import *
import threading
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2 sumber statik atau sumber dinamik
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
pass
else:
"静态资源请求"
pass3. Bagaimana untuk menangani sumber statik?
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
Pengesahan permintaan sumber statik:
4 Cara menanganinya
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()5 Tutup pelayan Web
new_socket.close()
Jumlah paparan kod rangka kerja utama pelayan Web:
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import sys
import time
from socket import *
import threading
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2 rangka kerja Web
1. Mengikut laluan permintaan, balas secara dinamik kepada data yang sepadan
# -*- coding: utf-8 -*-
# @File : MyFramework.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/25 14:05
import time
# 自定义Web框架
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
response = index()
return response
else:
# 没有动态资源的数据,返回404页面
return page_not_found()
# 当前 index函数,专门处理index.html的请求
def index():
# 需求,在页面中动态显示当前系统时间
data = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
response_body = data
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
def page_not_found():
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
return response2. Jika tiada data tindak balas yang sepadan dengan laluan permintaan, halaman 404 perlu dikembalikan
3. Gunakan templat untuk memaparkan kandungan respons
1 Reka bentuk index.html templat sendiri dan gunakan data dinamik untuk menggantikannya dalam beberapa tempat
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>首页 - 电影列表</title>
<link href="/css/bootstrap.min.css" rel="stylesheet">
<script src="/js/jquery-1.12.4.min.js"></script>
<script src="/js/bootstrap.min.js"></script>
</head>
<body>
<div class="navbar navbar-inverse navbar-static-top ">
<div class="container">
<div class="navbar-header">
<button class="navbar-toggle" data-toggle="collapse" data-target="#mymenu">
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a href="#" class="navbar-brand">电影列表</a>
</div>
<div class="collapse navbar-collapse" id="mymenu">
<ul class="nav navbar-nav">
<li class="active"><a href="">电影信息</a></li>
<li><a href="">个人中心</a></li>
</ul>
</div>
</div>
</div>
<div class="container">
<div class="container-fluid">
<table class="table table-hover">
<tr>
<th>序号</th>
<th>名称</th>
<th>导演</th>
<th>上映时间</th>
<th>票房</th>
<th>电影时长</th>
<th>类型</th>
<th>备注</th>
<th>删除电影</th>
</tr>
{%datas%}
</table>
</div>
</div>
</body>
</html>2. Bagaimana untuk menggantikan dan data apa yang perlu diganti
response_body = response_body.replace('{%datas%}', data)
4 1. Untuk membangunkan fungsi sumber tindakan baharu pada masa hadapan, anda hanya perlu:
a , tambah cabang penghakiman bersyarat
b, tambah fungsi pemprosesan khas
2. Penghalaan: Ia adalah pemetaan langsung antara laluan URL yang diminta dan fungsi pemprosesan.
3. Jadual penghalaan
# 定义路由表
route_list = {
('/index.html', index),
('/user_info.html', user_info)
}
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()| 请求路径 | 处理函数 |
|---|---|
| /index.html | index函数 |
| /user_info.html | user_info函数 |
5. Gunakan penghias untuk menambah laluan
1 Gunakan penghias dengan parameter
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
# 定义路由表
route_list = []
# route_list = {
# ('/index.html', index),
# ('/user_info.html', user_info)
# }
# 定义一个带参数的装饰器
def route(request_path): # 参数就是URL请求
def add_route(func):
# 添加路由表
route_list.append((request_path, func))
@wraps(func)
def invoke(*args, **kwargs):
# 调用指定的处理函数,并返回结果
return func()
return invoke
return add_route
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
# if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
# response = index()
# return response
# elif request_path == '/user_info.html': # 个人中心的功能
# return user_info()
# else:
# # 没有动态资源的数据,返回404页面
# return page_not_found()
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()2. Tambah laluan berdasarkan sebarang fungsi pemprosesan
@route('/user_info.html')
Ringkasan: Menggunakan penghias dengan parameter, kami boleh menambah laluan kami secara automatik ke jadual penghalaan.
6. Kes pembangunan halaman senarai filem
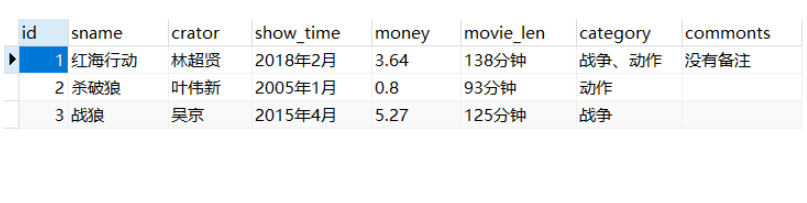 1 Data pertanyaan
1 Data pertanyaan
my_web.py
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import socket
import sys
import threading
import time
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建HTTP服务器的套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,程序退出之后不需要等待几分钟,直接释放端口
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
server_socket.bind(('', port))
server_socket.listen(128)
self.server_socket = server_socket
# 处理浏览器请求的函数
@staticmethod
def handle_browser_request(new_socket):
# 接受客户端发送过来的数据
recv_data = new_socket.recv(4096)
# 如果没有收到数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接受的字节数据,转换成字符
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print('请求路径是:', request_path)
if request_path == '/': # 如果请求路径为跟目录,自动设置为/index.html
request_path = '/index.html'
# 根据请求路径来判断是否是动态资源还是静态资源
if request_path.endswith('.html'):
'''动态资源的请求'''
# 动态资源的处理交给Web框架来处理,需要把请求参数传给Web框架,可能会有多个参数,所有采用字典机构
params = {
'request_path': request_path,
}
# Web框架处理动态资源请求之后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
'''静态资源的请求'''
response_body = None # 响应主体
response_header = None # 响应头
response_first_line = None # 响应头的第一行
# 其实就是:根据请求路径读取/static目录中静态的文件数据,响应给客户端
try:
# 读取static目录中对应的文件数据,rb模式:是一种兼容模式,可以打开图片,也可以打开js
with open('static' + request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Server: Laoxiao_Server\r\n'
except Exception as e: # 浏览器想读取的文件可能不存在
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容(字节)
# 响应头 (字符数据)
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
finally:
# 组成响应数据,发送给客户端(浏览器)
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
new_socket.close() # 关闭套接字
# 启动服务器,并且接受客户端的请求
def start(self):
# 循环并且多线程来接受客户端的请求
while True:
new_socket, ip_port = self.server_socket.accept()
print("客户端的ip和端口", ip_port)
# 一个客户端请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket,))
sub_thread.setDaemon(True) # 设置当前线程为守护线程
sub_thread.start() # 子线程要启动
# web服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()MyFramework .py
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import time
from functools import wraps
import pymysql
# 定义路由表
route_list = []
# route_list = {
# # ('/index.html',index),
# # ('/userinfo.html',user_info)
# }
# 定义一个带参数装饰器
def route(request_path): # 参数就是URL请求
def add_route(func):
# 添加路由到路由表
route_list.append((request_path, func))
@wraps(func)
def invoke(*arg, **kwargs):
# 调用我们指定的处理函数,并且返回结果
return func()
return invoke
return add_route
# 处理动态资源请求的函数
def handle_request(params):
request_path = params['request_path']
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()
# if request_path =='/index.html': # 当前的请求路径有与之对应的动态响应,当前框架,我只开发了index.html的功能
# response = index()
# return response
#
# elif request_path =='/userinfo.html': # 个人中心的功能,user_info.html
# return user_info()
# else:
# # 没有动态资源的数据,返回404页面
# return page_not_found()
# 当前user_info函数,专门处理userinfo.html的动态请求
@route('/userinfo.html')
def user_info():
# 需求:在页面中动态显示当前系统时间
date = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
# response_body =data
with open('template/user_info.html', 'r', encoding='utf-8') as f:
response_body = f.read()
response_body = response_body.replace('{%datas%}', date)
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
# 当前index函数,专门处理index.html的请求
@route('/index.html')
def index():
# 需求:从数据库中取得所有的电影数据,并且动态展示
# date = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
# response_body =data
# 1、从MySQL中查询数据
conn = pymysql.connect(host='localhost', port=3306, user='root', password='******', database='test', charset='utf8')
cursor = conn.cursor()
cursor.execute('select * from t_movies')
result = cursor.fetchall()
# print(result)
datas = ""
for row in result:
datas += '''<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s 亿人民币</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td> <input type='button' value='删除'/> </td>
</tr>
''' % row
print(datas)
# 把查询的数据,转换成动态内容
with open('template/index.html', 'r', encoding='utf-8') as f:
response_body = f.read()
response_body = response_body.replace('{%datas%}', datas)
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
# 处理没有找到对应的动态资源
def page_not_found():
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容(字节)
# 响应头 (字符数据)
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
return response2 Dapatkan kandungan dinamik berdasarkan data yang ditanya
Atas ialah kandungan terperinci Cara menggunakan Python untuk membangunkan rangka kerja web tersuai. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Menggunakan Log Debian Apache Untuk Meningkatkan Prestasi Laman Web
Apr 12, 2025 pm 11:36 PM
Cara Menggunakan Log Debian Apache Untuk Meningkatkan Prestasi Laman Web
Apr 12, 2025 pm 11:36 PM
Artikel ini akan menerangkan bagaimana untuk meningkatkan prestasi laman web dengan menganalisis log Apache di bawah sistem Debian. 1. Asas Analisis Log Apache Log merekodkan maklumat terperinci semua permintaan HTTP, termasuk alamat IP, timestamp, url permintaan, kaedah HTTP dan kod tindak balas. Dalam sistem Debian, log ini biasanya terletak di direktori/var/log/apache2/access.log dan /var/log/apache2/error.log. Memahami struktur log adalah langkah pertama dalam analisis yang berkesan. 2. Alat Analisis Log Anda boleh menggunakan pelbagai alat untuk menganalisis log Apache: Alat baris arahan: grep, awk, sed dan alat baris arahan lain.
 Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Peranan Sniffer Debian dalam Pengesanan Serangan DDOS
Apr 12, 2025 pm 10:42 PM
Peranan Sniffer Debian dalam Pengesanan Serangan DDOS
Apr 12, 2025 pm 10:42 PM
Artikel ini membincangkan kaedah pengesanan serangan DDoS. Walaupun tiada kes permohonan langsung "debiansniffer" ditemui, kaedah berikut boleh digunakan untuk pengesanan serangan DDOS: Teknologi Pengesanan Serangan DDo Sebagai contoh, skrip Python yang digabungkan dengan perpustakaan Pyshark dan Colorama boleh memantau trafik rangkaian dalam masa nyata dan mengeluarkan makluman. Pengesanan berdasarkan analisis statistik: dengan menganalisis ciri statistik trafik rangkaian, seperti data
 Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Artikel ini akan membimbing anda tentang cara mengemas kini sijil NginxSSL anda pada sistem Debian anda. Langkah 1: Pasang Certbot terlebih dahulu, pastikan sistem anda mempunyai pakej CertBot dan Python3-CertBot-Nginx yang dipasang. Jika tidak dipasang, sila laksanakan arahan berikut: sudoapt-getupdateudoapt-getinstallcertbotpython3-certbot-nginx Langkah 2: Dapatkan dan konfigurasikan sijil Gunakan perintah certbot untuk mendapatkan sijil let'Sencrypt dan konfigurasikan nginx: sudoCertBot-ninx ikuti
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Mengkonfigurasi pelayan HTTPS pada sistem Debian melibatkan beberapa langkah, termasuk memasang perisian yang diperlukan, menghasilkan sijil SSL, dan mengkonfigurasi pelayan web (seperti Apache atau Nginx) untuk menggunakan sijil SSL. Berikut adalah panduan asas, dengan mengandaikan anda menggunakan pelayan Apacheweb. 1. Pasang perisian yang diperlukan terlebih dahulu, pastikan sistem anda terkini dan pasang Apache dan OpenSSL: sudoaptDateSudoaptgradesudoaptinsta
