
 Peranti teknologi
AI
Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan
Peranti teknologi
AI
Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan
Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan

Pengenalan
Perwakilan pembenaman perkataan ialah asas untuk pelbagai tugas pemprosesan bahasa semula jadi seperti terjemahan mesin, menjawab soalan, klasifikasi teks, dll. Ia biasanya menyumbang 20%~90% daripada jumlah parameter model. Menyimpan dan mengakses benam ini memerlukan sejumlah besar ruang, yang tidak kondusif untuk penggunaan model dan aplikasi pada peranti dengan sumber terhad. Untuk menangani masalah ini, artikel ini mencadangkan kaedah pemampatan membenamkan perkataan MorphTE . MorphTE menggabungkan keupayaan mampatan berkuasa operasi produk tensor dengan pengetahuan morfologi bahasa terdahulu untuk mencapai pemampatan tinggi parameter pembenaman perkataan (melebihi 20 kali ) sambil mengekalkan prestasi model.

- Pautan kertas: https://arxiv.org/abs/2210.15379
- Kod sumber terbuka: https://github.com/bigganbing/Fairseq_MorphTE
Model
Ini artikel mencadangkan Kaedah pemampatan membenamkan perkataan MorphTE mula-mula membahagikan perkataan kepada unit terkecil dengan makna semantik - morfem, dan melatih perwakilan vektor berdimensi rendah untuk setiap morfem, dan kemudian menggunakan hasil tensor untuk merealisasikan perwakilan matematik keadaan terjerat kuantum rendah- vektor morfem dimensi, dengan itu memperoleh perwakilan perkataan berdimensi tinggi.
01 Komposisi morfem sesuatu perkataan
Dalam linguistik, morfem ialah unit terkecil dengan fungsi semantik atau tatabahasa tertentu. Untuk bahasa seperti bahasa Inggeris, sesuatu perkataan boleh dibahagikan kepada unit morfem yang lebih kecil seperti akar dan imbuhan. Sebagai contoh, "tidak baik" boleh dibahagikan kepada "un" untuk penafian, "baik" untuk sesuatu seperti "mesra" dan "ly" untuk kata keterangan. Untuk bahasa Cina, aksara Cina juga boleh dibahagikan kepada unit yang lebih kecil seperti radikal Contohnya, "MU" boleh dibahagikan kepada "氵" dan "木" yang mewakili air.

Walaupun morfem mengandungi semantik, ia juga boleh digunakan dalam perkataan yang dikongsi antara mereka untuk menyambung perkataan yang berbeza. Selain itu, bilangan morfem yang terhad boleh digabungkan untuk membentuk bilangan perkataan yang lebih banyak.
02 Perwakilan termampat bagi benam perkataan dalam bentuk tensor terjerat
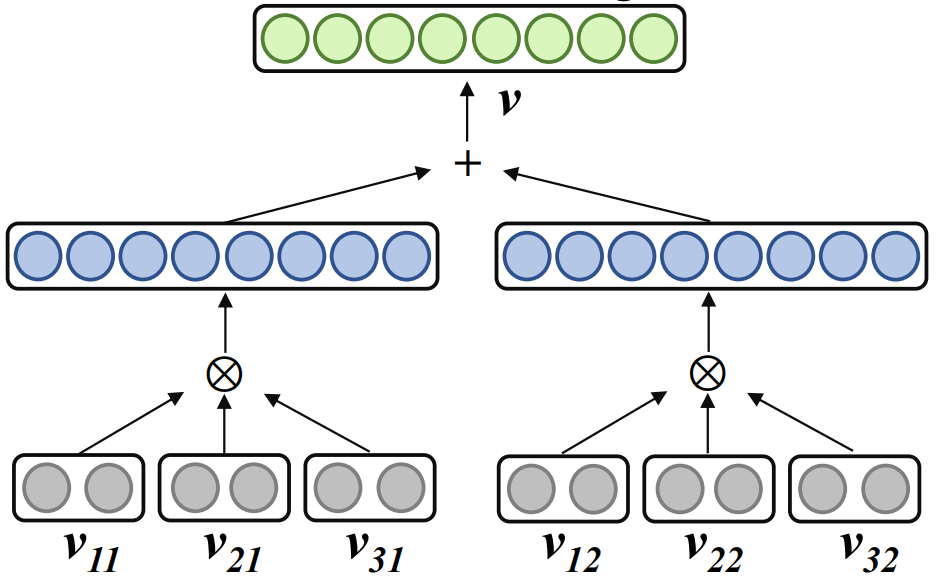
Kerja berkaitan Word2ket mewakili satu embedding perkataan sebagai The entanglement bentuk tensor beberapa vektor berdimensi rendah mempunyai formula berikut:
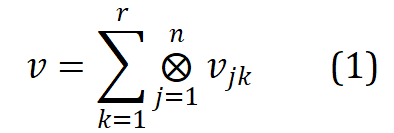
di mana , r ialah pangkat, n ialah susunan dan mewakili hasil tensor. Word2ket hanya perlu menyimpan dan menggunakan vektor dimensi rendah ini untuk membina vektor perkataan dimensi tinggi, dengan itu mencapai pengurangan parameter yang berkesan. Sebagai contoh, apabila r = 2 dan n = 3, vektor perkataan dengan dimensi 512 boleh diperolehi oleh dua kumpulan tiga tensor vektor dimensi rendah dengan dimensi 8 dalam setiap kumpulan diperlukan dikurangkan daripada 512 kepada 48 .
03 perkataan tensor dipertingkatkan morfologi membenamkan perwakilan mampatan
Melalui produk tensor, Word2ket boleh mencapai pemampatan parameter yang jelas, tetapi ia mengalami pemampatan tinggi dan terjemahan mesin Untuk lebih kompleks tugas, biasanya sukar untuk mencapai kesan sebelum pemampatan. Memandangkan vektor berdimensi rendah ialah unit asas yang membentuk tensor belitan, dan morfem ialah unit asas yang membentuk perkataan. Kajian ini mempertimbangkan pengenalan pengetahuan linguistik dan mencadangkan MorphTE, yang melatih vektor morfem berdimensi rendah dan menggunakan hasil darab tensor bagi vektor morfem yang terkandung dalam perkataan itu untuk membina perwakilan pemasukan perkataan yang sepadan.
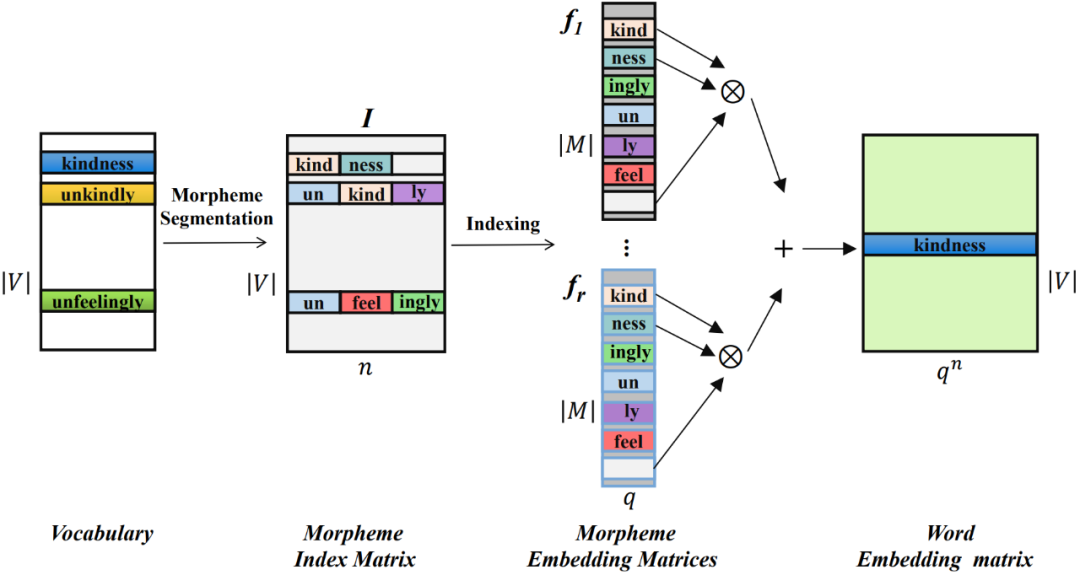
Secara khusus, mula-mula gunakan alat pembahagian morfem untuk membahagikan perkataan dalam senarai perkataan V. Morfem semua perkataan akan membentuk jadual morfem M, dan bilangan morfem akan jauh lebih rendah daripada bilangan perkataan ().
Bagi setiap perkataan, bina vektor indeks morfemnya, yang menunjukkan kedudukan morfem yang terkandung dalam setiap perkataan dalam jadual morfem. Vektor indeks morfem bagi semua perkataan membentuk matriks indeks morfem 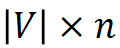 , dengan n ialah susunan MorphTE.
, dengan n ialah susunan MorphTE.
Untuk perkataan ke-j 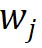 dalam perbendaharaan kata, gunakan vektor indeks morfemnya
dalam perbendaharaan kata, gunakan vektor indeks morfemnya 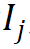 untuk meparameterkannya daripada kumpulan r Vektor morfem yang sepadan diindeks ke dalam matriks benam morfem, dan pembenaman perkataan yang sepadan diperolehi dengan perwakilan tensor terikat melalui hasil tensor Proses ini diformalkan seperti berikut:
untuk meparameterkannya daripada kumpulan r Vektor morfem yang sepadan diindeks ke dalam matriks benam morfem, dan pembenaman perkataan yang sepadan diperolehi dengan perwakilan tensor terikat melalui hasil tensor Proses ini diformalkan seperti berikut:
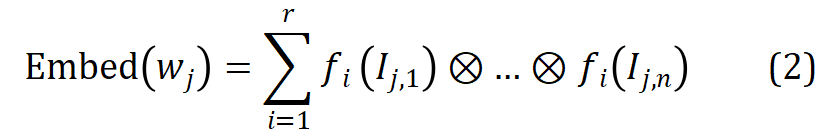
Melalui kaedah di atas, MophTE boleh menyuntik pengetahuan sedia ada linguistik berasaskan morfem ke dalam perwakilan membenamkan perkataan, dan perkongsian vektor morfem antara perkataan yang berbeza secara eksplisit boleh membina hubungan antara perkataan. Selain itu, bilangan dan dimensi vektor morfem adalah jauh lebih rendah daripada saiz dan dimensi perbendaharaan kata, dan MophTE mencapai pemampatan parameter pembenaman perkataan dari kedua-dua perspektif. Oleh itu, MophTE mampu mencapai pemampatan berkualiti tinggi bagi perwakilan pembenaman perkataan.
EksperimenArtikel ini menjalankan percubaan pada tugasan seperti terjemahan dan menjawab soalan dalam bahasa yang berbeza, dan membandingkannya dengan kaedah pemampatan pemampatan berdasarkan penguraian yang berkaitan.
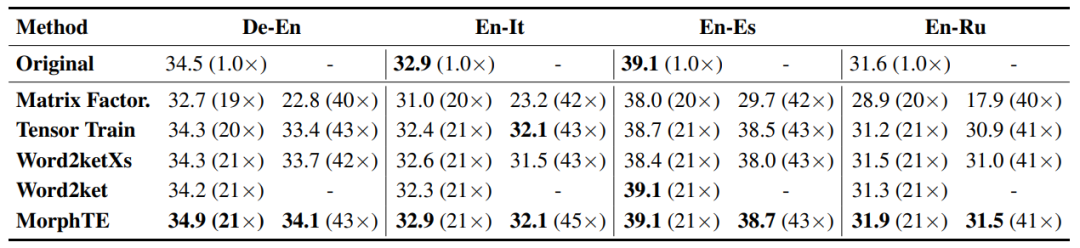
Seperti yang anda lihat daripada jadual, MorphTE boleh menyesuaikan diri dengan bahasa yang berbeza seperti bahasa Inggeris, Jerman, Itali, dsb. Pada nisbah mampatan lebih daripada 20 kali, MorphTE dapat mengekalkan kesan model asal, manakala hampir semua kaedah mampatan lain menunjukkan penurunan kesan. Selain itu, MorphTE berprestasi lebih baik daripada kaedah pemampatan lain pada set data yang berbeza pada nisbah mampatan lebih daripada 40 kali.
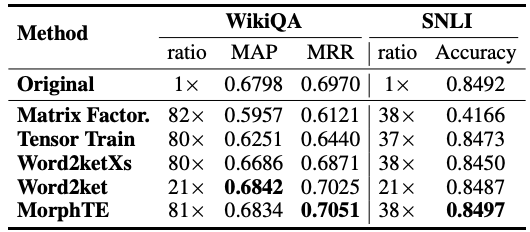
Begitu juga, MorphTE mencapai nisbah mampatan masing-masing 81 kali dan 38 kali pada tugasan soal jawab WikiQA dan tugas penaakulan bahasa semula jadi SNLI mengekalkan kesan model.
KesimpulanMorphTE menggabungkan pengetahuan bahasa morfologi priori dan keupayaan pemampatan yang berkuasa bagi produk tensor untuk mencapai pemampatan berkualiti tinggi bagi pembenaman perkataan. Eksperimen pada bahasa dan tugas yang berbeza menunjukkan bahawa MorphTE boleh mencapai 20 hingga 80 kali pemampatan parameter pembenaman perkataan tanpa merosakkan kesan model. Ini mengesahkan bahawa pengenalan pengetahuan linguistik berasaskan morfem boleh meningkatkan pembelajaran perwakilan mampat bagi benam perkataan. Walaupun pada masa ini MorphTE hanya memodelkan morfem, ia sebenarnya boleh diperluaskan kepada rangka kerja peningkatan pemampatan pemampatan umum yang secara eksplisit memodelkan lebih banyak pengetahuan linguistik priori seperti prototaip, bahagian pertuturan, penggunaan huruf besar, dsb., untuk meningkatkan lagi pemampatan pemampatan perkataan.
Atas ialah kandungan terperinci Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara menulis novel dalam aplikasi Novel Percuma Tomato Kongsi tutorial cara menulis novel dalam Novel Tomato.
Mar 28, 2024 pm 12:50 PM
Cara menulis novel dalam aplikasi Novel Percuma Tomato Kongsi tutorial cara menulis novel dalam Novel Tomato.
Mar 28, 2024 pm 12:50 PM
Novel Tomato adalah perisian membaca novel yang sangat popular Kami sering mempunyai novel dan komik baru untuk dibaca dalam Novel Tomato Setiap novel dan komik sangat menarik ingin menulis ke dalam teks. Jadi bagaimana kita menulis novel di dalamnya? Kongsi tutorial novel Tomato tentang cara menulis novel 1. Mula-mula buka aplikasi novel percuma Tomato pada telefon bimbit anda dan klik pada Pusat Peribadi - Pusat Penulis 2. Lompat ke halaman Pembantu Penulis Tomato - klik pada Buat buku baru di penghujung novel.
 Bagaimana untuk memasukkan bios pada papan induk Berwarna-warni? Ajar anda dua kaedah
Mar 13, 2024 pm 06:01 PM
Bagaimana untuk memasukkan bios pada papan induk Berwarna-warni? Ajar anda dua kaedah
Mar 13, 2024 pm 06:01 PM
Papan induk berwarna-warni menikmati populariti tinggi dan bahagian pasaran dalam pasaran domestik China, tetapi sesetengah pengguna papan induk Berwarna-warni masih tidak tahu cara memasukkan bios untuk tetapan? Sebagai tindak balas kepada situasi ini, editor telah membawakan anda secara khas dua kaedah untuk memasukkan bios motherboard yang berwarna-warni. Datang dan cuba! Kaedah 1: Gunakan kekunci pintasan permulaan cakera U untuk terus memasuki sistem pemasangan cakera U Kekunci pintasan untuk papan induk Berwarna untuk memulakan cakera U dengan satu klik ialah ESC atau F11 Pertama, gunakan Black Shark Installation Master untuk mencipta Black Cakera but cakera Shark U, dan kemudian hidupkan komputer Apabila anda melihat skrin permulaan, tekan terus kekunci ESC atau F11 pada papan kekunci untuk memasuki tetingkap untuk pemilihan item permulaan secara berurutan ke tempat "USB " dipaparkan, dan kemudian
 Bagaimana untuk memulihkan kenalan yang dipadam pada WeChat (tutorial mudah memberitahu anda cara memulihkan kenalan yang dipadam)
May 01, 2024 pm 12:01 PM
Bagaimana untuk memulihkan kenalan yang dipadam pada WeChat (tutorial mudah memberitahu anda cara memulihkan kenalan yang dipadam)
May 01, 2024 pm 12:01 PM
Malangnya, orang sering memadamkan kenalan tertentu secara tidak sengaja atas sebab tertentu WeChat ialah perisian sosial yang digunakan secara meluas. Untuk membantu pengguna menyelesaikan masalah ini, artikel ini akan memperkenalkan cara mendapatkan semula kenalan yang dipadam dengan cara yang mudah. 1. Fahami mekanisme pemadaman kenalan WeChat Ini memberi kita kemungkinan untuk mendapatkan semula kenalan yang dipadamkan Mekanisme pemadaman kenalan dalam WeChat mengalih keluar mereka daripada buku alamat, tetapi tidak memadamkannya sepenuhnya. 2. Gunakan fungsi "Pemulihan Buku Kenalan" terbina dalam WeChat menyediakan "Pemulihan Buku Kenalan" untuk menjimatkan masa dan tenaga Pengguna boleh mendapatkan semula kenalan yang telah dipadamkan dengan cepat melalui fungsi ini. 3. Masuk ke halaman tetapan WeChat dan klik sudut kanan bawah, buka aplikasi WeChat "Saya" dan klik ikon tetapan di sudut kanan atas untuk memasuki halaman tetapan.
 Ringkasan kaedah untuk mendapatkan hak pentadbir dalam Win11
Mar 09, 2024 am 08:45 AM
Ringkasan kaedah untuk mendapatkan hak pentadbir dalam Win11
Mar 09, 2024 am 08:45 AM
Ringkasan cara mendapatkan hak pentadbir Win11 Dalam sistem pengendalian Windows 11, hak pentadbir adalah salah satu kebenaran yang sangat penting yang membolehkan pengguna melakukan pelbagai operasi pada sistem. Kadangkala, kami mungkin perlu mendapatkan hak pentadbir untuk menyelesaikan beberapa operasi, seperti memasang perisian, mengubah suai tetapan sistem, dsb. Berikut meringkaskan beberapa kaedah untuk mendapatkan hak pentadbir Win11, saya harap ia dapat membantu anda. 1. Gunakan kekunci pintasan Dalam sistem Windows 11, anda boleh membuka gesaan arahan dengan cepat melalui kekunci pintasan.
 Bagaimana untuk menetapkan saiz fon pada telefon mudah alih (mudah melaraskan saiz fon pada telefon bimbit)
May 07, 2024 pm 03:34 PM
Bagaimana untuk menetapkan saiz fon pada telefon mudah alih (mudah melaraskan saiz fon pada telefon bimbit)
May 07, 2024 pm 03:34 PM
Menetapkan saiz fon telah menjadi keperluan pemperibadian yang penting kerana telefon mudah alih menjadi alat penting dalam kehidupan seharian manusia. Untuk memenuhi keperluan pengguna yang berbeza, artikel ini akan memperkenalkan cara meningkatkan pengalaman penggunaan telefon mudah alih dan melaraskan saiz fon telefon mudah alih melalui operasi mudah. Mengapa anda perlu melaraskan saiz fon telefon mudah alih anda - Melaraskan saiz fon boleh menjadikan teks lebih jelas dan mudah dibaca - Sesuai untuk keperluan membaca pengguna yang berbeza umur - Mudah untuk pengguna yang kurang penglihatan menggunakan saiz fon fungsi tetapan sistem telefon mudah alih - Cara memasukkan antara muka tetapan sistem - Dalam Cari dan masukkan pilihan "Paparan" dalam antara muka tetapan - cari pilihan "Saiz Fon" dan laraskan saiz fon dengan pihak ketiga aplikasi - muat turun dan pasang aplikasi yang menyokong pelarasan saiz fon - buka aplikasi dan masukkan antara muka tetapan yang berkaitan - mengikut individu
 Rahsia penetasan telur naga mudah alih terbongkar (langkah demi langkah untuk mengajar anda cara berjaya menetas telur naga mudah alih)
May 04, 2024 pm 06:01 PM
Rahsia penetasan telur naga mudah alih terbongkar (langkah demi langkah untuk mengajar anda cara berjaya menetas telur naga mudah alih)
May 04, 2024 pm 06:01 PM
Permainan mudah alih telah menjadi sebahagian daripada kehidupan orang ramai dengan perkembangan teknologi. Ia telah menarik perhatian ramai pemain dengan imej telur naga yang comel dan proses penetasan yang menarik, dan salah satu permainan yang telah menarik perhatian ramai ialah versi mudah alih Dragon Egg. Untuk membantu pemain memupuk dan mengembangkan naga mereka sendiri dengan lebih baik dalam permainan, artikel ini akan memperkenalkan kepada anda cara menetas telur naga dalam versi mudah alih. 1. Pilih jenis telur naga yang sesuai Pemain perlu berhati-hati memilih jenis telur naga yang mereka suka dan sesuai dengan diri mereka, berdasarkan pelbagai jenis sifat dan kebolehan telur naga yang disediakan dalam permainan. 2. Tingkatkan tahap mesin pengeraman Pemain perlu meningkatkan tahap mesin pengeraman dengan menyelesaikan tugasan dan mengumpul prop Tahap mesin pengeraman menentukan kelajuan penetasan dan kadar kejayaan penetasan. 3. Kumpul sumber yang diperlukan untuk penetasan Pemain perlu berada dalam permainan
 Penjelasan terperinci tentang kaedah pertanyaan versi Oracle
Mar 07, 2024 pm 09:21 PM
Penjelasan terperinci tentang kaedah pertanyaan versi Oracle
Mar 07, 2024 pm 09:21 PM
Penjelasan terperinci tentang kaedah pertanyaan versi Oracle Oracle ialah salah satu sistem pengurusan pangkalan data hubungan yang paling popular di dunia Ia menyediakan fungsi yang kaya dan prestasi yang berkuasa dan digunakan secara meluas dalam perusahaan. Dalam proses pengurusan dan pembangunan pangkalan data, adalah sangat penting untuk memahami versi pangkalan data Oracle. Artikel ini akan memperkenalkan secara terperinci cara untuk menanyakan maklumat versi pangkalan data Oracle dan memberikan contoh kod khusus. Tanya versi pangkalan data pernyataan SQL dalam pangkalan data Oracle dengan melaksanakan pernyataan SQL yang mudah
 Kuasai dengan cepat: Bagaimana untuk membuka dua akaun WeChat pada telefon bimbit Huawei didedahkan!
Mar 23, 2024 am 10:42 AM
Kuasai dengan cepat: Bagaimana untuk membuka dua akaun WeChat pada telefon bimbit Huawei didedahkan!
Mar 23, 2024 am 10:42 AM
Dalam masyarakat hari ini, telefon bimbit telah menjadi sebahagian daripada kehidupan kita. Sebagai alat penting untuk komunikasi harian, kerja dan kehidupan kita, WeChat sering digunakan. Walau bagaimanapun, mungkin perlu untuk memisahkan dua akaun WeChat apabila mengendalikan transaksi yang berbeza, yang memerlukan telefon mudah alih untuk menyokong log masuk ke dua akaun WeChat pada masa yang sama. Sebagai jenama domestik yang terkenal, telefon bimbit Huawei digunakan oleh ramai orang Jadi apakah kaedah untuk membuka dua akaun WeChat pada telefon bimbit Huawei? Mari kita dedahkan rahsia kaedah ini. Pertama sekali, anda perlu menggunakan dua akaun WeChat pada masa yang sama pada telefon mudah alih Huawei anda Cara paling mudah ialah
