
 Peranti teknologi
AI
Keterlaluan! Penyelidikan terkini: 61% kertas Bahasa Inggeris yang ditulis oleh orang Cina akan dinilai sebagai AI yang dijana oleh pengesan ChatGPT
Peranti teknologi
AI
Keterlaluan! Penyelidikan terkini: 61% kertas Bahasa Inggeris yang ditulis oleh orang Cina akan dinilai sebagai AI yang dijana oleh pengesan ChatGPT
Keterlaluan! Penyelidikan terkini: 61% kertas Bahasa Inggeris yang ditulis oleh orang Cina akan dinilai sebagai AI yang dijana oleh pengesan ChatGPT

Selepas ChatGPT menjadi popular, terdapat banyak kegunaan.
Sesetengah orang menggunakannya untuk mendapatkan nasihat kehidupan, sesetengah orang hanya menggunakannya sebagai enjin carian, dan sesetengah orang menggunakannya untuk menulis kertas kerja.
Tesis... bukan senang nak tulis.
Sesetengah universiti di Amerika Syarikat telah melarang pelajar menggunakan ChatGPT untuk menulis kerja rumah, dan juga telah membangunkan sekumpulan perisian untuk mengenal pasti dan menentukan sama ada kertas yang diserahkan oleh pelajar dihasilkan oleh GPT .
Ada masalah di sini.
Kertas seseorang ditulis dengan buruk, dan AI yang menilai teks menyangka ia ditulis oleh rakan sebaya.
Apa yang lebih menarik ialah kebarangkalian kertas Bahasa Inggeris yang ditulis oleh bahasa Cina dinilai sebagai AI yang dijana oleh AI adalah setinggi 61%.

Ini... apakah maksudnya? Menggigil!
Penutur bukan penutur asli tidak layak?
Pada masa ini, model bahasa generatif berkembang pesat dan sememangnya telah membawa kemajuan yang besar kepada komunikasi digital.
Tetapi terdapat banyak penyalahgunaan.
Walaupun penyelidik telah mencadangkan banyak kaedah pengesanan untuk membezakan AI dan kandungan yang dihasilkan manusia, keadilan dan kestabilan kaedah pengesanan ini masih perlu dipertingkatkan.
Untuk melakukan ini, penyelidik menilai prestasi beberapa pengesan GPT yang digunakan secara meluas menggunakan karya yang ditulis oleh pengarang asli dan bukan asli berbahasa Inggeris.
Hasil penyelidikan menunjukkan bahawa pengesan ini sentiasa tersilap menentukan bahawa sampel yang ditulis oleh bukan penutur asli dijana oleh AI, manakala sampel yang ditulis oleh penutur asli pada asasnya boleh dikenal pasti dengan tepat.
Selain itu, penyelidik menunjukkan bahawa berat sebelah ini boleh dikurangkan menggunakan beberapa strategi mudah dan memintas pengesan GPT dengan berkesan.
Apakah maksudnya? Ini menunjukkan bahawa pengesan GPT memandang rendah kepada pengarang yang kemahiran bahasa mereka tidak begitu baik, yang sangat menjengkelkan.
Tidak boleh tidak memikirkan permainan itu untuk menilai sama ada AI adalah orang sebenar Jika lawan adalah orang sebenar tetapi anda rasa ia adalah AI, sistem akan berkata, "Orang lain mungkin mendapati anda menyinggung perasaan."
Tidak cukup kompleks=AI dijana?
Para penyelidik memperoleh 91 esei TOEFL daripada forum pendidikan Cina, dan mengekstrak 88 esei yang ditulis oleh pelajar gred lapan Amerika daripada set data Yayasan Hewlett di Amerika Syarikat untuk mengesan 7 GPT yang digunakan secara meluas. pengesan.
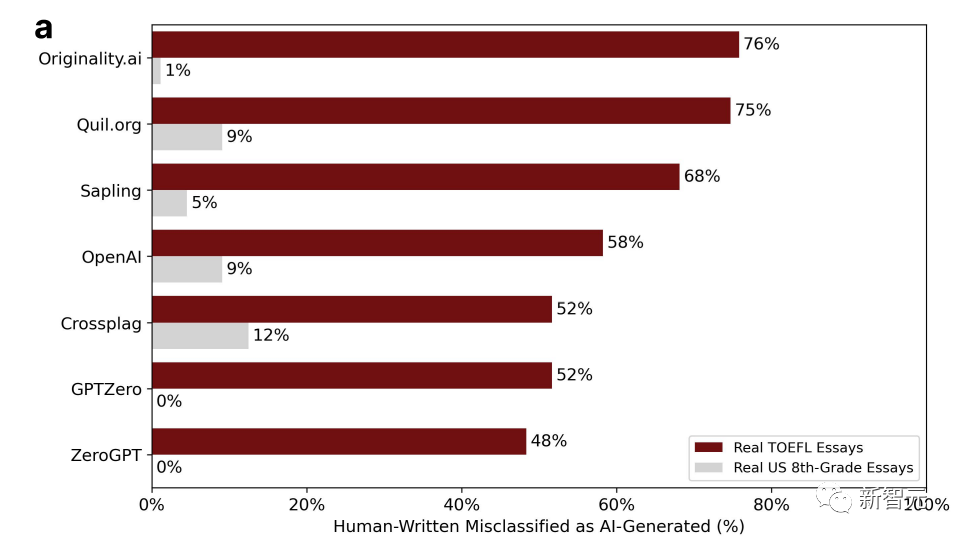
Peratusan dalam carta mewakili perkadaran "salah sangka". Iaitu, ia ditulis oleh manusia, tetapi perisian pengesanan berpendapat ia dihasilkan oleh AI.
Anda dapat melihat bahawa data adalah sangat berbeza.
Antara tujuh pengesan, kebarangkalian tertinggi untuk salah menilai untuk esei yang ditulis oleh pelajar gred lapan Amerika hanya 12%, dan terdapat dua GPT dengan sifar salah penilaian.
Pada asasnya lebih separuh daripada esei TOEFL di forum bahasa Cina disalah anggap, dengan kebarangkalian salah penilaian tertinggi mencapai 76%.
18 daripada 91 esei TOEFL sebulat suara dianggap dijana oleh AI oleh kesemua 7 pengesan GPT, manakala 89 daripada 91 esei telah tersalah jana oleh sekurang-kurangnya satu pengesan GPT.
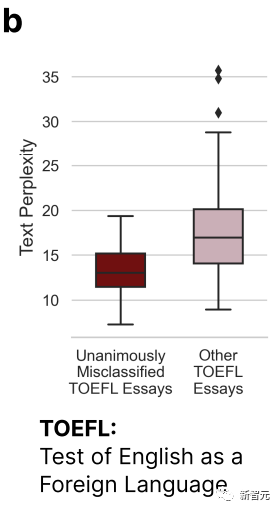
Daripada rajah di atas kita dapat lihat bahawa esei TOEFL yang disalah anggap oleh kesemua 7 GPT mempunyai kerumitan yang lebih tinggi ( Complexity) adalah jauh lebih rendah daripada kertas lain.
Ini mengesahkan kesimpulan pada permulaan - pengesan GPT akan mempunyai kecenderungan tertentu terhadap pengarang yang mempunyai keupayaan ekspresi bahasa yang terhad.
Oleh itu, penyelidik percaya bahawa pengesan GPT harus membaca lebih banyak artikel yang ditulis oleh penutur bukan asli Hanya dengan lebih banyak sampel boleh dihapuskan.
Seterusnya, penyelidik melemparkan esei TOEFL yang ditulis oleh bukan penutur asli ke dalam ChatGPT untuk memperkayakan bahasa dan meniru tabiat penggunaan perkataan penutur asli.
Pada masa yang sama, sebagai kumpulan kawalan, gubahan yang ditulis oleh kanak-kanak darjah lapan Amerika juga dilemparkan ke dalam ChatGPT, dan bahasa itu dipermudahkan untuk meniru ciri penulisan bukan asli. pembesar suara. Gambar di bawah ialah keputusan penghakiman baharu selepas pembetulan.
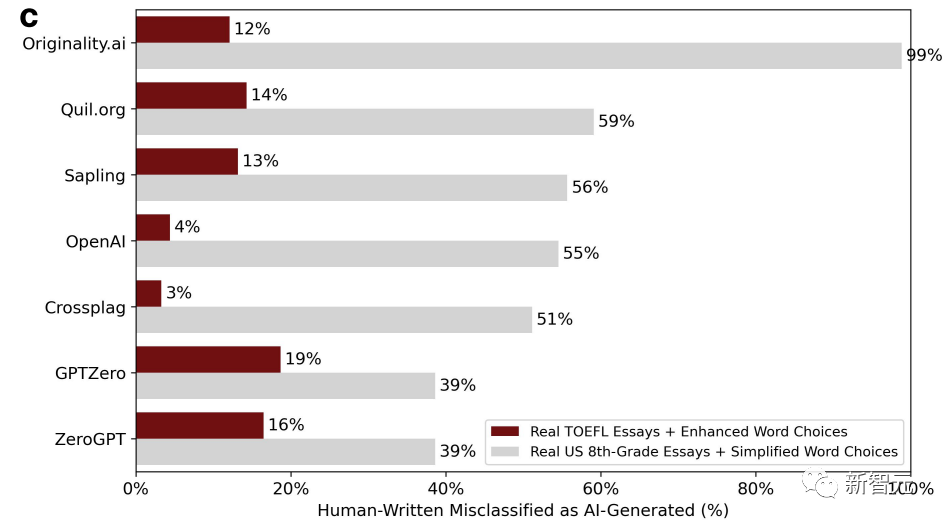
Kita dapati bahawa keadaan telah berubah secara drastik, dan kadar salah menilai esei TOEFL yang memperkaya bahasa telah menjunam. . , serendah 3%, dan setinggi 19%. Tidak seperti kadar positif palsu sebelum ini, yang pada asasnya lebih daripada separuh.
Sebaliknya, kadar salah menilai esei yang ditulis oleh kanak-kanak darjah lapan telah melonjak naik malah terdapat pengesan GPT dengan kadar salah menilai setinggi 99%, iaitu pada asasnya semuanya kesilapan.
Kerana pembolehubah kerumitan artikel telah berubah.
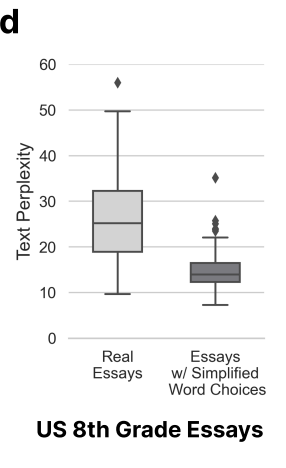
Di sini penyelidik membuat kesimpulan bahawa perkara yang ditulis oleh bukan penutur asli adalah tidak tulen, mempunyai kerumitan yang rendah dan mudah disalah anggap.
Ini juga membawa kepada isu teknikal, tetapi juga isu nilai. Menggunakan kerumitan untuk menentukan sama ada AI atau manusia adalah pengarang adalah munasabah, komprehensif dan teliti.
Hasilnya jelas tidak.
Apabila kerumitan digunakan sebagai kriteria, penutur bukan penutur asli mengalami kerugian besar kerana mereka bukan penutur asli (karut).
Pengilat AI = ditulis oleh manusia? ?
Penyelidik percaya bahawa mempertingkatkan kepelbagaian bahasa bukan sahaja dapat mengurangkan berat sebelah terhadap penutur bukan asli, tetapi juga membenarkan kandungan yang dijana GPT memintas pengesan GPT.
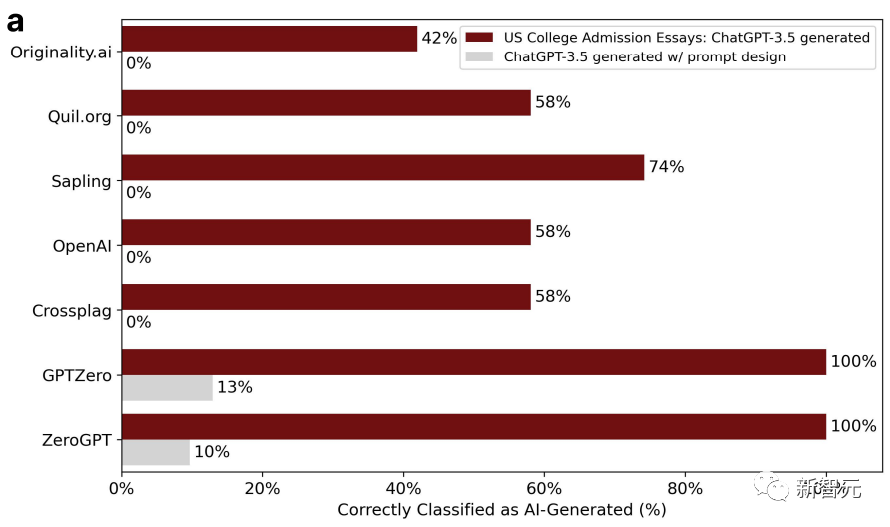
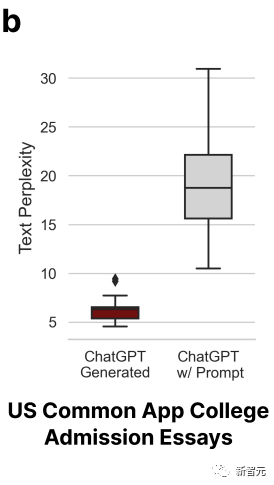
Untuk membuktikan perkara ini, penyelidik memilih topik esei kemasukan yang digunakan untuk universiti Amerika pada 2022-2023, memasukkannya ke dalam ChatGPT-3.5, dan menghasilkan sejumlah 31 esei palsu.
Pengesan GPT berfungsi dengan baik pada mulanya, tetapi tidak pada pusingan kedua. Ini kerana, pada pusingan kedua, penyelidik melemparkan kertas-kertas ini ke dalam ChatGPT dan menggilapnya, menggunakan beberapa bahasa sastera untuk meningkatkan kualiti teks.
Akibatnya, ketepatan pengesan GPT menurun daripada 100% kepada 0%. Seperti yang ditunjukkan di bawah:
Kerumitan artikel yang digilap juga telah meningkat dengan sewajarnya.
Pada masa yang sama, penyelidik menggunakan 145 topik laporan projek akhir dari Universiti Stanford untuk membenarkan ChatGPT menjana abstrak .
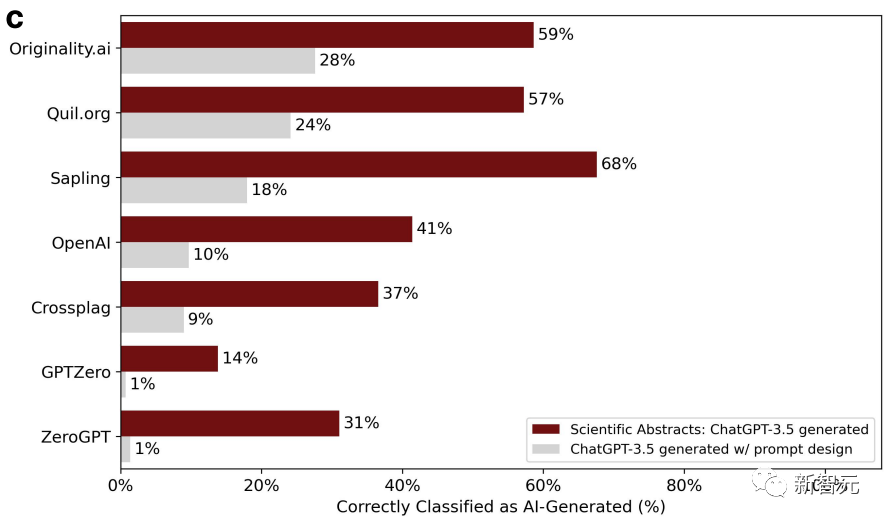
Selepas ringkasan digilap, ketepatan penghakiman pengesan terus menurun.
Para penyelidik sekali lagi membuat kesimpulan bahawa artikel yang digilap mudah disalah anggap dan dijana oleh AI. Dua pusingan adalah lebih baik daripada satu.
Pengesan GPT? Masih kurang amalan
Ringkasnya, secara keseluruhannya, pelbagai pengesan GPT masih nampaknya gagal menangkap hubungan antara penjanaan AI dan tulisan manusia.
Tulisan manusia juga terbahagi kepada tiga, enam atau sembilan peringkat Tidaklah munasabah untuk menilai berdasarkan kerumitan sahaja.
Mengetepikan faktor berat sebelah, teknologi itu sendiri juga memerlukan penambahbaikan.
Atas ialah kandungan terperinci Keterlaluan! Penyelidikan terkini: 61% kertas Bahasa Inggeris yang ditulis oleh orang Cina akan dinilai sebagai AI yang dijana oleh pengesan ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
