
 pembangunan bahagian belakang
Tutorial Python
Apakah prinsip pelaksanaan kamus dalam mesin maya Python
pembangunan bahagian belakang
Tutorial Python
Apakah prinsip pelaksanaan kamus dalam mesin maya Python
Apakah prinsip pelaksanaan kamus dalam mesin maya Python

Analisis struktur data kamus
/* The ma_values pointer is NULL for a combined table
* or points to an array of PyObject* for a split table
*/
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
PyDictKeyEntry dk_entries[1];
};
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;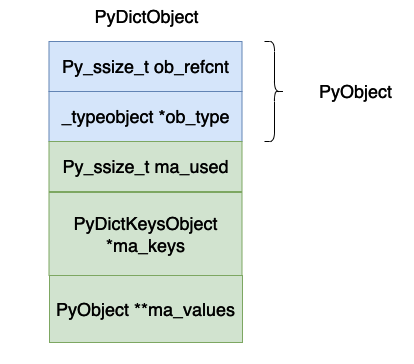
Maksud setiap medan di atas ialah:
ob_refcnt, kiraan rujukan bagi objek.
ob_type, jenis data objek.
ma_used, bilangan data dalam jadual cincang semasa.
ma_keys, menunjuk pada tatasusunan yang memegang pasangan nilai kunci.
ma_values, ini menunjukkan kepada tatasusunan nilai, tetapi nilai ini tidak semestinya digunakan dalam pelaksanaan khusus cpython, kerana objek dalam tatasusunan PyDictKeyEntry dalam _dictkeysobject juga boleh menyimpan nilai. Ini Nilai hanya boleh digunakan apabila semua kunci adalah rentetan Dalam artikel ini, nilai dalam PyDictKeyEntry digunakan terutamanya untuk membincangkan pelaksanaan kamus, jadi anda boleh mengabaikan pembolehubah ini.
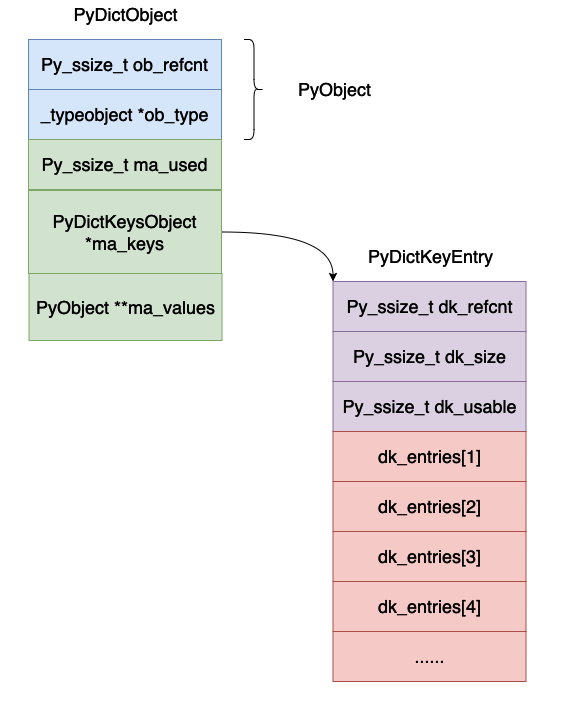
dk_refcnt, ini juga digunakan untuk mewakili pengiraan rujukan Ini berkaitan dengan paparan kamus Prinsipnya serupa dengan pengiraan rujukan, jadi kami akan mengabaikannya di sini buat masa ini.
dk_size, ini mewakili saiz jadual cincang, yang mestilah 2n Dalam kes ini, operasi modular boleh ditukar kepada operasi DAN secara bit.
dk_lookup, ini mewakili fungsi carian jadual cincang, ia ialah penunjuk fungsi.
dk_usable, menunjukkan bilangan pasangan nilai kunci tersedia dalam tatasusunan semasa.
dk_entry, jadual cincang, tempat pasangan nilai kunci sebenarnya disimpan.
Reka letak keseluruhan jadual cincang adalah kira-kira seperti yang ditunjukkan di bawah:
Buat objek kamus baharu
Ini Fungsinya agak mudah Mula-mula gunakan ruang memori, kemudian lakukan beberapa operasi pemulaan, dan gunakan jadual cincang untuk menyimpan pasangan nilai kunci.
static PyObject *
dict_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *self;
PyDictObject *d;
assert(type != NULL && type->tp_alloc != NULL);
// 申请内存空间
self = type->tp_alloc(type, 0);
if (self == NULL)
return NULL;
d = (PyDictObject *)self;
/* The object has been implicitly tracked by tp_alloc */
if (type == &PyDict_Type)
_PyObject_GC_UNTRACK(d);
// 因为还没有增加数据 因此哈希表当中 ma_used = 0
d->ma_used = 0;
// 申请保存键值对的数组 PyDict_MINSIZE_COMBINED 是一个宏定义 值为 8 表示哈希表数组的最小长度
d->ma_keys = new_keys_object(PyDict_MINSIZE_COMBINED);
// 如果申请失败返回 NULL
if (d->ma_keys == NULL) {
Py_DECREF(self);
return NULL;
}
return self;
}
// new_keys_object 函数如下所示
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t i;
PyDictKeyEntry *ep0;
assert(size >= PyDict_MINSIZE_SPLIT);
assert(IS_POWER_OF_2(size));
// 这里是申请内存的位置真正申请内存空间的大小为 PyDictKeysObject 的大小加上 size-1 个PyDictKeyEntry的大小
// 这里你可能会有一位为啥不是 size 个 PyDictKeyEntry 的大小 因为在结构体 PyDictKeysObject 当中已经申请了一个 PyDictKeyEntry 对象了
dk = PyMem_MALLOC(sizeof(PyDictKeysObject) +
sizeof(PyDictKeyEntry) * (size-1));
if (dk == NULL) {
PyErr_NoMemory();
return NULL;
}
// 下面主要是一些初始化的操作 dk_refcnt 设置成 1 因为目前只有一个字典对象使用 这个 PyDictKeysObject 对象
DK_DEBUG_INCREF dk->dk_refcnt = 1;
dk->dk_size = size; // 哈希表的大小
// 下面这行代码主要是表示哈希表当中目前还能存储多少个键值对 在 cpython 的实现当中允许有 2/3 的数组空间去存储数据 超过这个数则需要进行扩容
dk->dk_usable = USABLE_FRACTION(size); // #define USABLE_FRACTION(n) ((((n) << 1)+1)/3)
ep0 = &dk->dk_entries[0];
/* Hash value of slot 0 is used by popitem, so it must be initialized */
ep0->me_hash = 0;
// 将所有的键值对初始化成 NULL
for (i = 0; i < size; i++) {
ep0[i].me_key = NULL;
ep0[i].me_value = NULL;
}
dk->dk_lookup = lookdict_unicode_nodummy;
return dk;
}Mekanisme pengembangan jadual cincang
Pertama sekali, mari kita fahami mekanisme pengembangan jadual cincang dalam pelaksanaan kamus Apabila kita terus menambah data baharu pada kamus, kamus akan masuk ia akan mencapai 23 daripada panjang tatasusunan Pada masa ini, ia perlu dikembangkan Saiz tatasusunan selepas pengembangan dikira seperti berikut:
#define GROWTH_RATE(d) (((d)->ma_used*2)+((d)->ma_keys->dk_size>>1))
Saiz tatasusunan baharu adalah sama dengan bilangan kunci asal. -pasangan nilai didarab dengan 2 tambah separuh panjang tatasusunan asal.
Secara amnya, terdapat tiga langkah utama untuk pengembangan:
Kira saiz tatasusunan baharu.
Buat tatasusunan baharu.
Tambahkan data dalam jadual cincang asal pada tatasusunan baharu (iaitu, proses pencincangan semula).
Kod pelaksanaan khusus adalah seperti berikut:
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}
static int
dictresize(PyDictObject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
PyDictKeysObject *oldkeys;
PyObject **oldvalues;
Py_ssize_t i, oldsize;
// 下面的代码的主要作用就是计算得到能够大于等于 minused 最小的 2 的整数次幂
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE_COMBINED;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
oldkeys = mp->ma_keys;
oldvalues = mp->ma_values;
/* Allocate a new table. */
// 创建新的数组
mp->ma_keys = new_keys_object(newsize);
if (mp->ma_keys == NULL) {
mp->ma_keys = oldkeys;
return -1;
}
if (oldkeys->dk_lookup == lookdict)
mp->ma_keys->dk_lookup = lookdict;
oldsize = DK_SIZE(oldkeys);
mp->ma_values = NULL;
/* If empty then nothing to copy so just return */
if (oldsize == 1) {
assert(oldkeys == Py_EMPTY_KEYS);
DK_DECREF(oldkeys);
return 0;
}
/* Main loop below assumes we can transfer refcount to new keys
* and that value is stored in me_value.
* Increment ref-counts and copy values here to compensate
* This (resizing a split table) should be relatively rare */
if (oldvalues != NULL) {
for (i = 0; i < oldsize; i++) {
if (oldvalues[i] != NULL) {
Py_INCREF(oldkeys->dk_entries[i].me_key);
oldkeys->dk_entries[i].me_value = oldvalues[i];
}
}
}
/* Main loop */
// 将原来数组当中的元素加入到新的数组当中
for (i = 0; i < oldsize; i++) {
PyDictKeyEntry *ep = &oldkeys->dk_entries[i];
if (ep->me_value != NULL) {
assert(ep->me_key != dummy);
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
// 更新一下当前哈希表当中能够插入多少数据
mp->ma_keys->dk_usable -= mp->ma_used;
if (oldvalues != NULL) {
/* NULL out me_value slot in oldkeys, in case it was shared */
for (i = 0; i < oldsize; i++)
oldkeys->dk_entries[i].me_value = NULL;
assert(oldvalues != empty_values);
free_values(oldvalues);
DK_DECREF(oldkeys);
}
else {
assert(oldkeys->dk_lookup != lookdict_split);
if (oldkeys->dk_lookup != lookdict_unicode_nodummy) {
PyDictKeyEntry *ep0 = &oldkeys->dk_entries[0];
for (i = 0; i < oldsize; i++) {
if (ep0[i].me_key == dummy)
Py_DECREF(dummy);
}
}
assert(oldkeys->dk_refcnt == 1);
DK_DEBUG_DECREF PyMem_FREE(oldkeys);
}
return 0;
}Sisipkan data ke dalam kamus
Apabila kami terus memasukkan data ke dalam kamus, kami berkemungkinan hingga Apabila konflik cincang ditemui, kaedah kamus mengendalikan konflik cincang pada asasnya adalah sama dengan kaedah yang digunakan oleh koleksi untuk mengendalikan konflik cincang Kedua-duanya menggunakan kaedah alamat pembangunan ini adalah agak rumit. Prosedur khusus adalah seperti berikut:
static void
insertdict_clean(PyDictObject *mp, PyObject *key, Py_hash_t hash,
PyObject *value)
{
size_t i;
size_t perturb;
PyDictKeysObject *k = mp->ma_keys;
// 首先得到 mask 的值
size_t mask = (size_t)DK_SIZE(k)-1;
PyDictKeyEntry *ep0 = &k->dk_entries[0];
PyDictKeyEntry *ep;
i = hash & mask;
ep = &ep0[i];
for (perturb = hash; ep->me_key != NULL; perturb >>= PERTURB_SHIFT) {
// 下面便是遇到哈希冲突时的处理办法
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
}
assert(ep->me_value == NULL);
ep->me_key = key;
ep->me_hash = hash;
ep->me_value = value;
}Atas ialah kandungan terperinci Apakah prinsip pelaksanaan kamus dalam mesin maya Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Menggunakan Log Debian Apache Untuk Meningkatkan Prestasi Laman Web
Apr 12, 2025 pm 11:36 PM
Cara Menggunakan Log Debian Apache Untuk Meningkatkan Prestasi Laman Web
Apr 12, 2025 pm 11:36 PM
Artikel ini akan menerangkan bagaimana untuk meningkatkan prestasi laman web dengan menganalisis log Apache di bawah sistem Debian. 1. Asas Analisis Log Apache Log merekodkan maklumat terperinci semua permintaan HTTP, termasuk alamat IP, timestamp, url permintaan, kaedah HTTP dan kod tindak balas. Dalam sistem Debian, log ini biasanya terletak di direktori/var/log/apache2/access.log dan /var/log/apache2/error.log. Memahami struktur log adalah langkah pertama dalam analisis yang berkesan. 2. Alat Analisis Log Anda boleh menggunakan pelbagai alat untuk menganalisis log Apache: Alat baris arahan: grep, awk, sed dan alat baris arahan lain.
 Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Peranan Sniffer Debian dalam Pengesanan Serangan DDOS
Apr 12, 2025 pm 10:42 PM
Peranan Sniffer Debian dalam Pengesanan Serangan DDOS
Apr 12, 2025 pm 10:42 PM
Artikel ini membincangkan kaedah pengesanan serangan DDoS. Walaupun tiada kes permohonan langsung "debiansniffer" ditemui, kaedah berikut boleh digunakan untuk pengesanan serangan DDOS: Teknologi Pengesanan Serangan DDo Sebagai contoh, skrip Python yang digabungkan dengan perpustakaan Pyshark dan Colorama boleh memantau trafik rangkaian dalam masa nyata dan mengeluarkan makluman. Pengesanan berdasarkan analisis statistik: dengan menganalisis ciri statistik trafik rangkaian, seperti data
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Artikel ini akan membimbing anda tentang cara mengemas kini sijil NginxSSL anda pada sistem Debian anda. Langkah 1: Pasang Certbot terlebih dahulu, pastikan sistem anda mempunyai pakej CertBot dan Python3-CertBot-Nginx yang dipasang. Jika tidak dipasang, sila laksanakan arahan berikut: sudoapt-getupdateudoapt-getinstallcertbotpython3-certbot-nginx Langkah 2: Dapatkan dan konfigurasikan sijil Gunakan perintah certbot untuk mendapatkan sijil let'Sencrypt dan konfigurasikan nginx: sudoCertBot-ninx ikuti
 Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Mengkonfigurasi pelayan HTTPS pada sistem Debian melibatkan beberapa langkah, termasuk memasang perisian yang diperlukan, menghasilkan sijil SSL, dan mengkonfigurasi pelayan web (seperti Apache atau Nginx) untuk menggunakan sijil SSL. Berikut adalah panduan asas, dengan mengandaikan anda menggunakan pelayan Apacheweb. 1. Pasang perisian yang diperlukan terlebih dahulu, pastikan sistem anda terkini dan pasang Apache dan OpenSSL: sudoaptDateSudoaptgradesudoaptinsta
