

RegEx atau ungkapan biasa ialah jujukan aksara yang membentuk corak carian.
RegEx boleh digunakan untuk menyemak sama ada rentetan mengandungi corak carian yang ditentukan.
Python menyediakan pakej terbina dalam yang dipanggil re yang boleh digunakan untuk memproses ungkapan biasa.
Import modul semula:
import re
Selepas mengimport modul semula, anda boleh mula menggunakan ungkapan biasa:
Contoh
Dapatkan rentetan untuk melihat sama ada ia bermula dengan "China" dan berakhir dengan "negara":
import re
txt = "China is a great country"
x = re.search("^China.*country$", txt)Jalankan instance
import re
txt = "China is a great country"
x = re.search("^China.*country$", txt)
if (x):
print("YES! We have a match!")
else:
print("No match")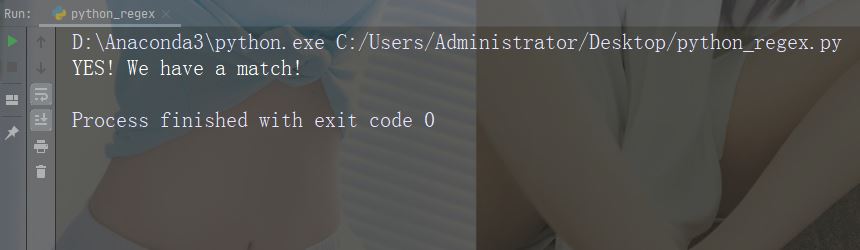
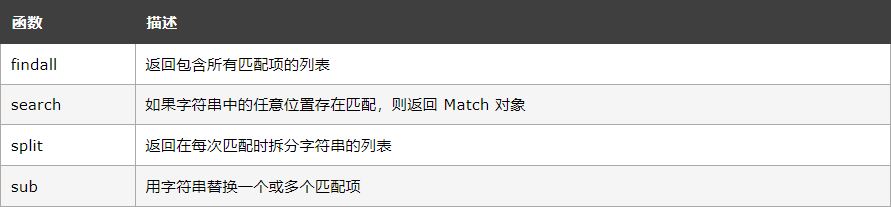
Modul semula menyediakan satu set fungsi yang membolehkan kami mendapatkan semula rentetan untuk pemadanan:
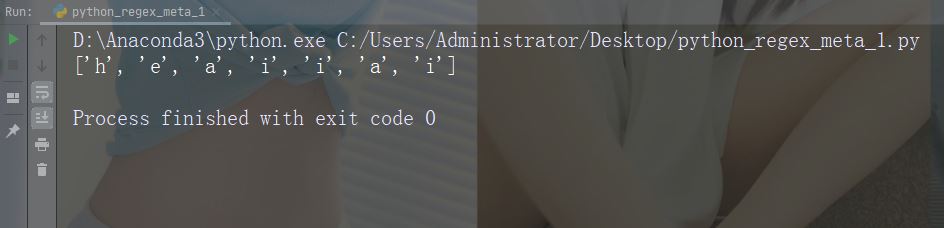
Metacharacter ialah aksara dengan makna istimewa
Aksara: [] Penerangan: Satu set aksara Contoh: "[a-m]"
import re
str = "The rain in Spain"
#Find all lower case characters alphabetically between "a" and "m":
x = re.findall("[a-m]", str)
print(x)Menjalankan contoh
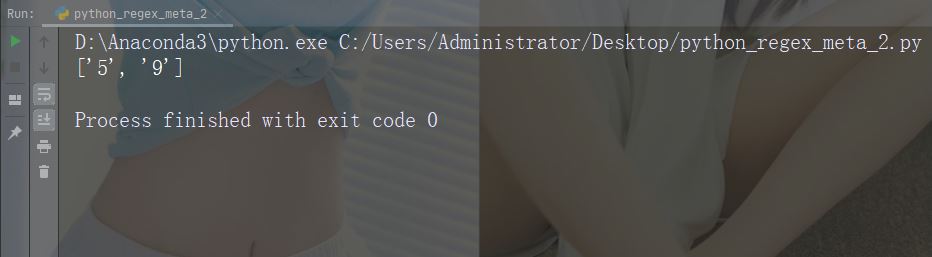
aksara: Perihalan: Menunjukkan urutan khas (juga boleh digunakan untuk melarikan diri aksara khas) Contoh: "d"
import re
str = "That will be 59 dollars"
#Find all digit characters:
x = re.findall("\d", str)
print(x)Jalankan contoh
Watak: . Penerangan: Mana-mana watak (kecuali baris baharu) Contoh: "he…o"
import re
str = "hello world"
#Search for a sequence that starts with "he", followed by two (any) characters, and an "o":
x = re.findall("he..o", str)
print(x)Jalankan contoh
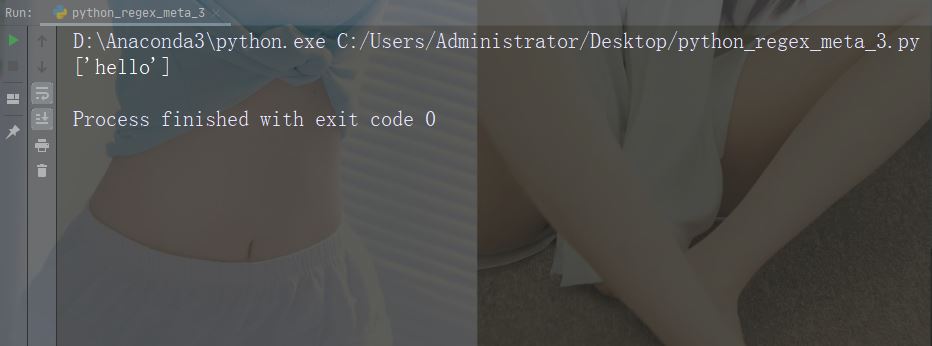
Watak: ^ Penerangan: daripada Bermula dengan contoh: "^hello"
import re
str = "hello world"
#Check if the string starts with 'hello':
x = re.findall("^hello", str)
if (x):
print("Yes, the string starts with 'hello'")
else:
print("No match")Contoh larian
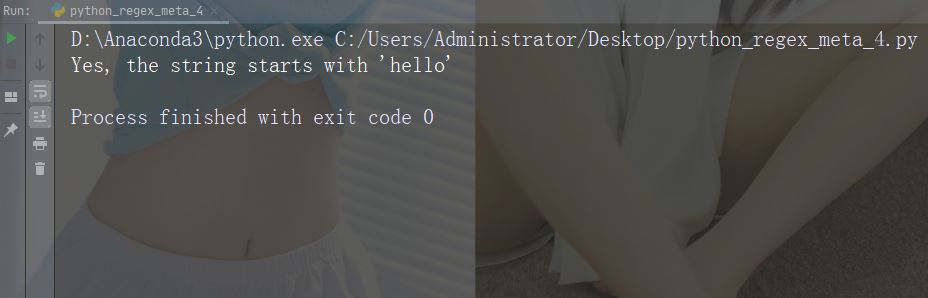
Watak: $ Penerangan: Diakhiri dengan contoh: "world$"
import re
str = "hello world"
#Check if the string ends with 'world':
x = re.findall("world$", str)
if (x):
print("Yes, the string ends with 'world'")
else:
print("No match")Contoh Run
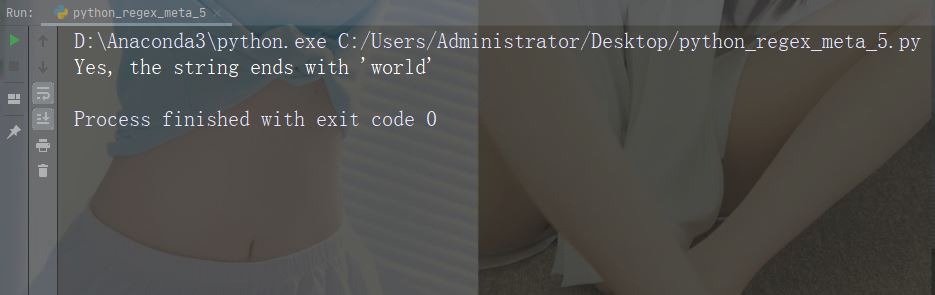
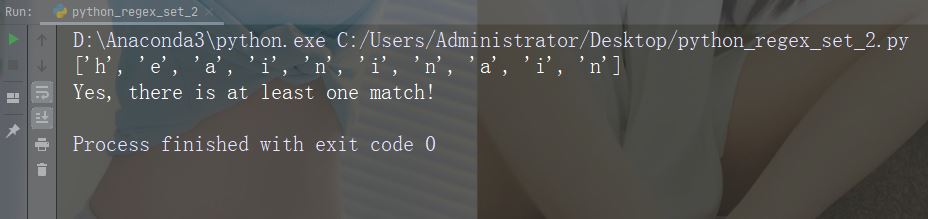
Watak: * Penerangan: Sifar atau lebih kejadian Contoh: "aix*"
import re
str = "The rain in Spain falls mainly in the plain!"
#Check if the string contains "ai" followed by 0 or more "x" characters:
x = re.findall("aix*", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Contoh Run
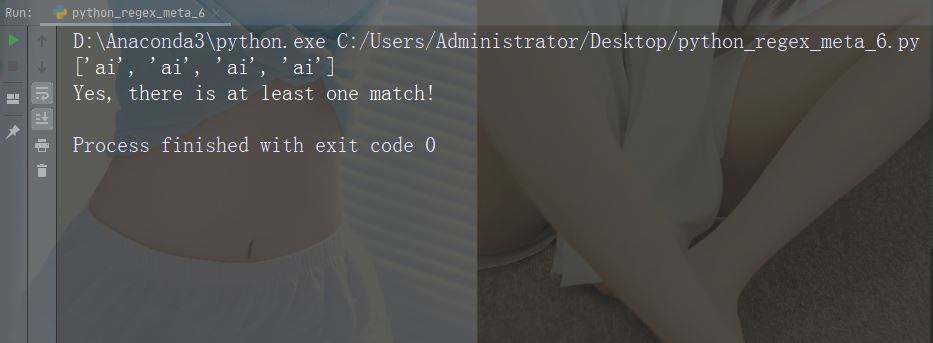
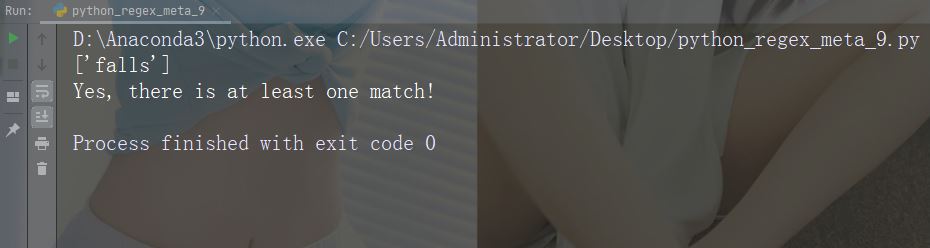
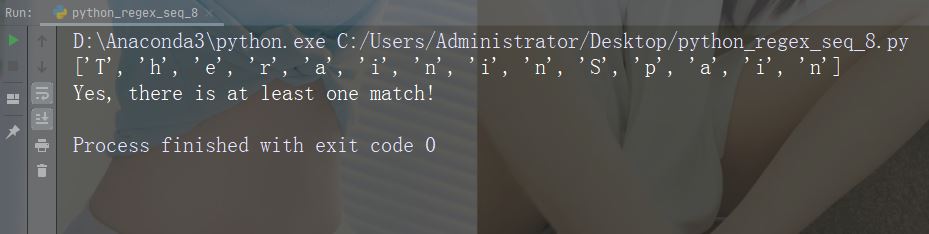
Watak: + Penerangan: Satu atau lebih kejadian Contoh: "aix+"
import re
str = "The rain in Spain falls mainly in the plain!"
#Check if the string contains "ai" followed by 1 or more "x" characters:
x = re.findall("aix+", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Jalankan contoh
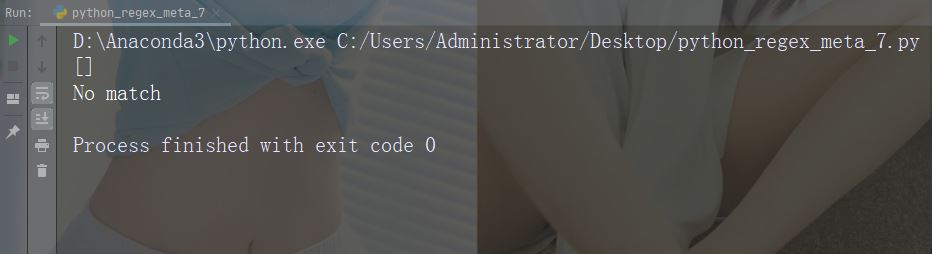
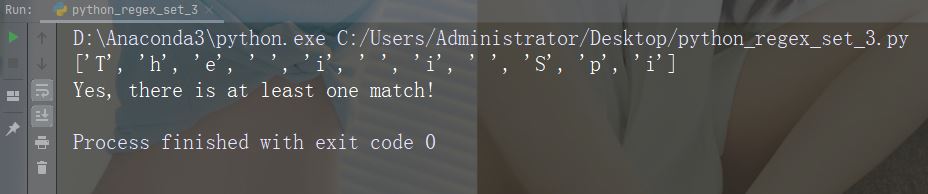
Watak :{} Penerangan: Bilangan kejadian yang dinyatakan dengan tepat Contoh: "al{2}"
import re
str = "The rain in Spain falls mainly in the plain!"
#Check if the string contains "a" followed by exactly two "l" characters:
x = re.findall("al{2}", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Contoh Larian
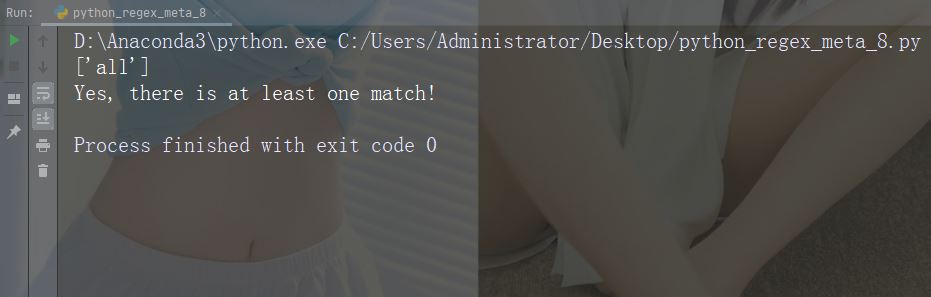
Aksara: | contoh: "jatuh|stays"
import re
str = "The rain in Spain falls mainly in the plain!"
#Check if the string contains either "falls" or "stays":
x = re.findall("falls|stays", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Jalankan contoh
aksara: () Penerangan: Tangkap dan kumpulkan
Jujukan khas merujuk kepada jujukan diikuti oleh watak dalam jadual di bawah, yang mempunyai makna istimewa.
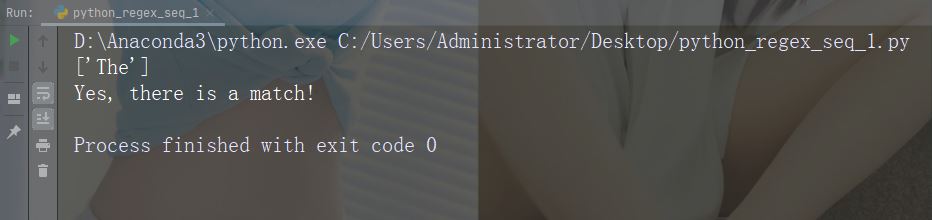
Watak: A Perihalan: Mengembalikan padanan jika aksara yang ditentukan berada pada permulaan rentetan Contoh: "ATe"
import re
str = "The rain in Spain"
#Check if the string starts with "The":
x = re.findall("\AThe", str)
print(x)
if (x):
print("Yes, there is a match!")
else:
print("No match")Jalankan contoh
Watak: b
Penerangan: Mengembalikan padanan di mana watak yang ditentukan berada di awal atau akhir perkataan
Contoh: r"bain"
import re
str = "The rain in Spain"
#Check if "ain" is present at the beginning of a WORD:
x = re.findall(r"\bain", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Jalankan contoh
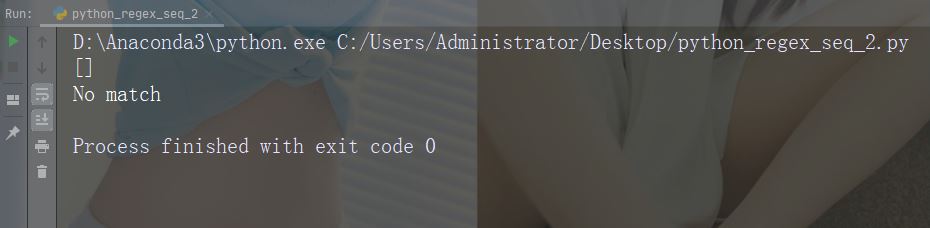
Contoh: r"ainb"
import re
str = "The rain in Spain"
#Check if "ain" is present at the end of a WORD:
x = re.findall(r"ain\b", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Jalankan contoh
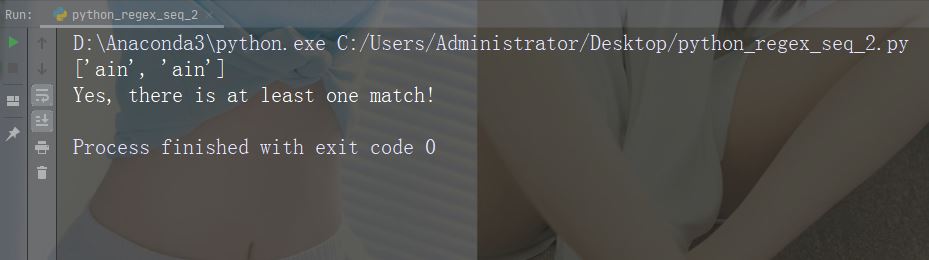
Watak : B
Penerangan: Mengembalikan padanan di mana watak yang dinyatakan wujud, tetapi bukan pada permulaan (atau akhir) perkataan
Contoh: r"Bain"
import re
str = "The rain in Spain"
#Check if "ain" is present, but NOT at the beginning of a word:
x = re.findall(r"\Bain", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Berjalan contoh
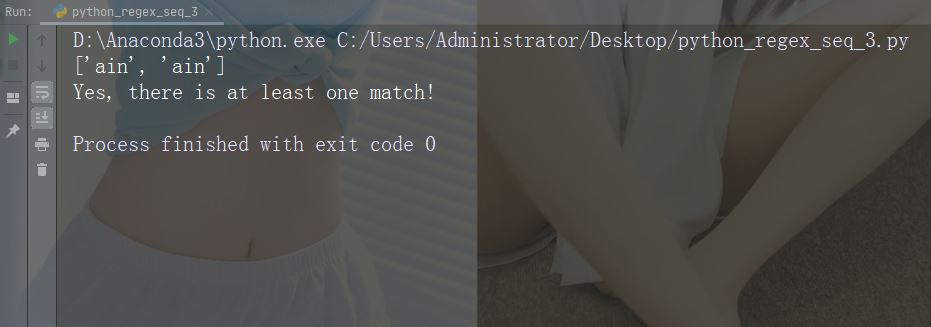
Contoh: r"ainB"
import re
str = "The rain in Spain"
#Check if "ain" is present, but NOT at the end of a word:
x = re.findall(r"ain\B", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Contoh berjalan
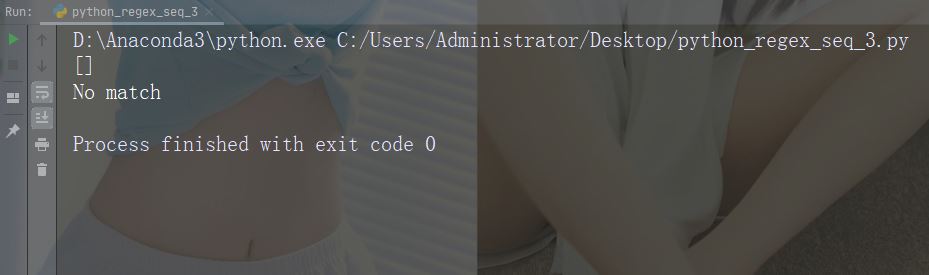
Watak: d
Penerangan: Return String mengandungi padanan untuk digit (nombor 0-9)
Contoh: "d"
import re
str = "The rain in Spain"
#Check if the string contains any digits (numbers from 0-9):
x = re.findall("\d", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Menjalankan contoh
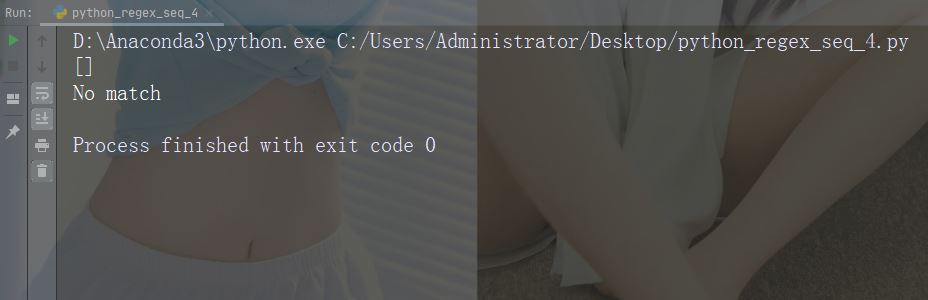
aksara: D
Penerangan: Mengembalikan padanan yang rentetan tidak mengandungi nombor
Contoh: "D"
import re
str = "The rain in Spain"
#Return a match at every no-digit character:
x = re.findall("\D", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")Jalankan contoh
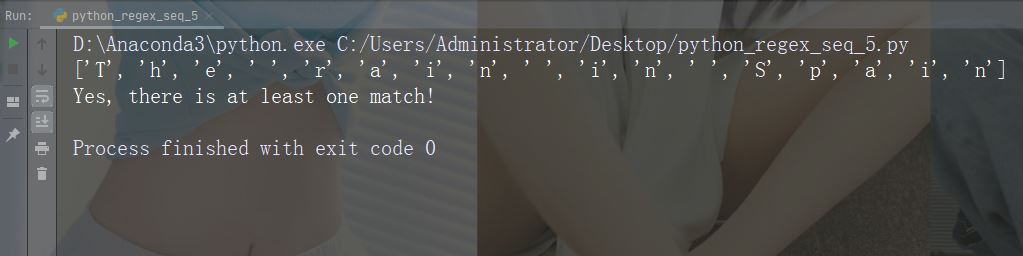
Watak: s
描述:返回字符串包含空白字符的匹配项
示例:“\s”
import re
str = "The rain in Spain"
#Return a match at every white-space character:
x = re.findall("\s", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
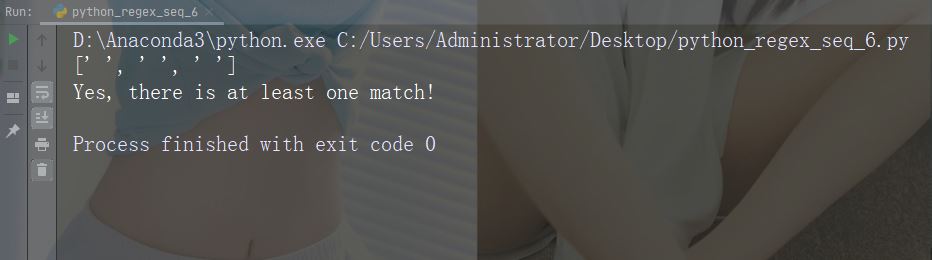
字符:\S
描述:返回字符串不包含空白字符的匹配项
示例:“\S”
import re
str = "The rain in Spain"
#Return a match at every NON white-space character:
x = re.findall("\S", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
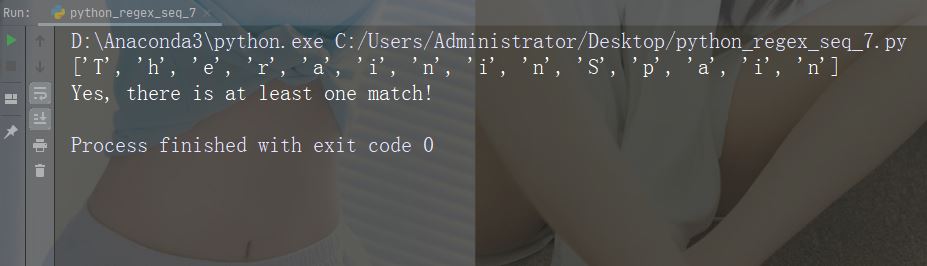
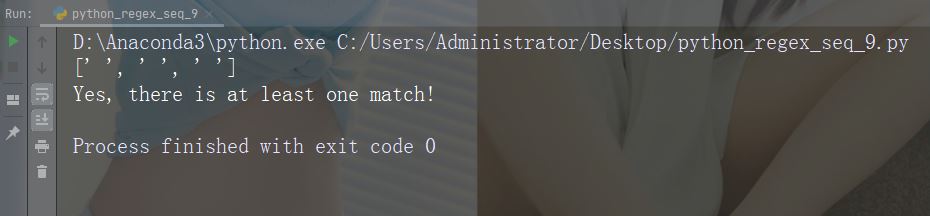
字符:\w
描述: 返回一个匹配项,其中字符串包含任何单词字符 (从 a 到 Z 的字符,从 0 到 9 的数字和下划线 _ 字符)
示例:“\w”
import re
str = "The rain in Spain"
#Return a match at every word character (characters from a to Z, digits from 0-9, and the underscore _ character):
x = re.findall("\w", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
字符:\W
描述:返回一个匹配项,其中字符串不包含任何单词字符
示例:“\W”
import re
str = "The rain in Spain"
#Return a match at every NON word character (characters NOT between a and Z. Like "!", "?" white-space etc.):
x = re.findall("\W", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
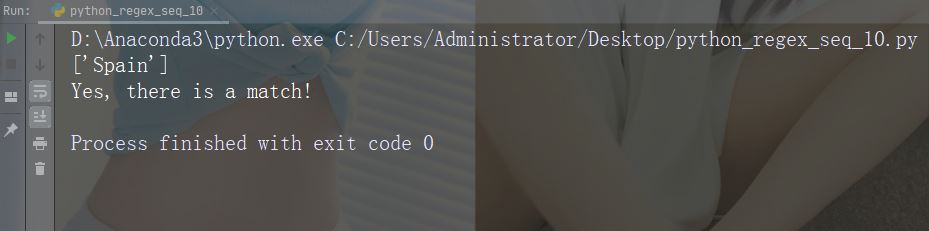
字符:\Z
描述:如果指定的字符位于字符串的末尾,则返回匹配项 。
示例:“Spain\Z”
import re
str = "The rain in Spain"
#Check if the string ends with "Spain":
x = re.findall("Spain\Z", str)
print(x)
if (x):
print("Yes, there is a match!")
else:
print("No match")运行示例
集合(Set)是一对方括号 [] 内的一组字符,具有特殊含义。
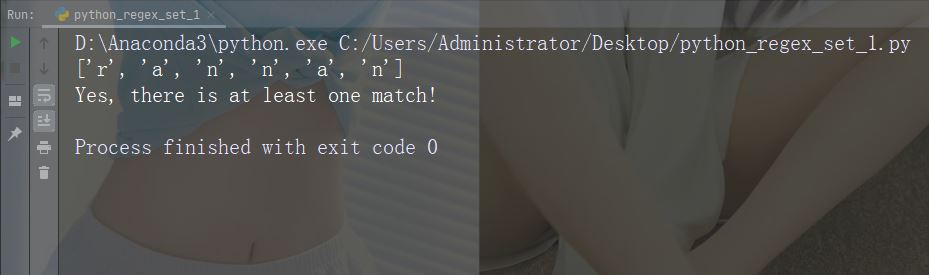
字符:[arn]
描述:返回一个匹配项,其中存在指定字符(a,r 或 n)之一
示例
import re
str = "The rain in Spain"
#Check if the string has any a, r, or n characters:
x = re.findall("[arn]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
字符:[a-n]
描述:返回字母顺序 a 和 n 之间的任意小写字符匹配项
示例
import re
str = "The rain in Spain"
#Check if the string has any characters between a and n:
x = re.findall("[a-n]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
字符:[^arn]
描述:返回除 a、r 和 n 之外的任意字符的匹配项
示例
import re
str = "The rain in Spain"
#Check if the string has other characters than a, r, or n:
x = re.findall("[^arn]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
字符:[0123]
描述:返回存在任何指定数字(0、1、2 或 3)的匹配项
示例
import re
str = "The rain in Spain"
#Check if the string has any 0, 1, 2, or 3 digits:
x = re.findall("[0123]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
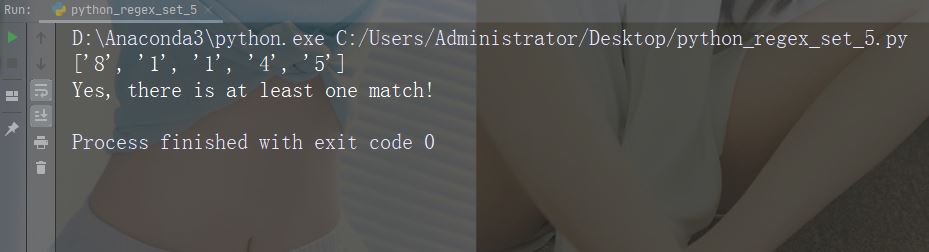
字符:[0-9]
描述:返回 0 与 9 之间任意数字的匹配
示例
import re
str = "8 times before 11:45 AM"
#Check if the string has any digits:
x = re.findall("[0-9]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
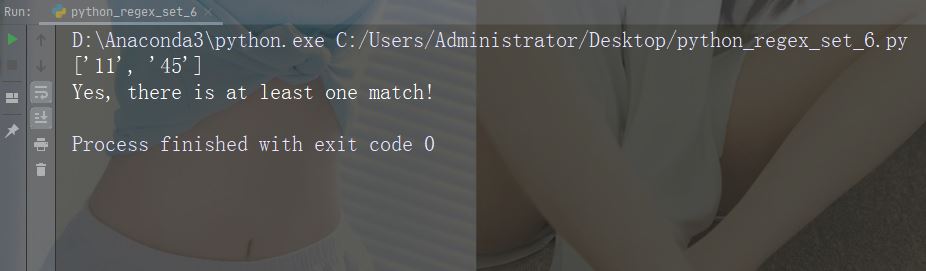
字符:[0-5][0-9]
描述:返回介于 0 到 9 之间的任何数字的匹配项
示例
import re
str = "8 times before 11:45 AM"
#Check if the string has any two-digit numbers, from 00 to 59:
x = re.findall("[0-5][0-9]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
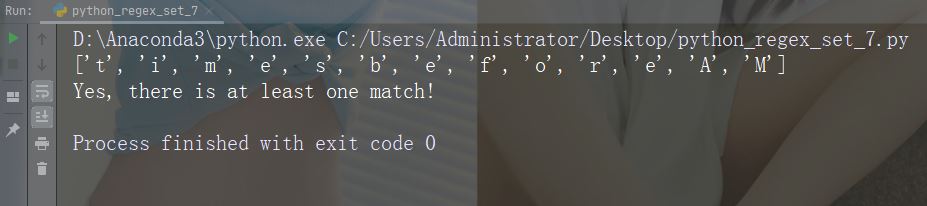
字符:[a-zA-Z]
描述:返回字母顺序 a 和 z 之间的任何字符的匹配,小写或大写
示例
import re
str = "8 times before 11:45 AM"
#Check if the string has any characters from a to z lower case, and A to Z upper case:
x = re.findall("[a-zA-Z]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
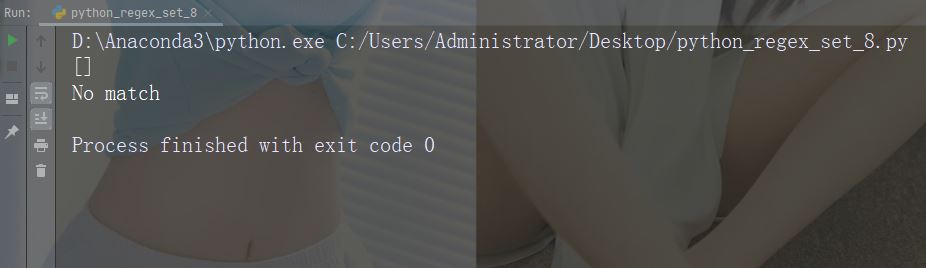
字符:[+]
描述:在集合中,+、*、.、|、()、$、{} 没有特殊含义,因此 [+] 表示:返回字符串中任何 + 字符的匹配项。
示例
import re
str = "8 times before 11:45 AM"
#Check if the string has any + characters:
x = re.findall("[+]", str)
print(x)
if (x):
print("Yes, there is at least one match!")
else:
print("No match")运行示例
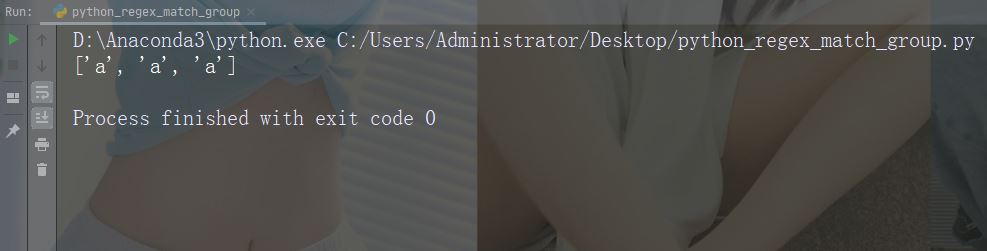
findall() 函数返回包含所有匹配项的列表。
实例
打印所有匹配的列表
import re
str = "China is a great country"
x = re.findall("a", str)
print(x)运行实例
这个列表以被找到的顺序包含匹配项。
如果未找到匹配项,则返回空列表。
实例
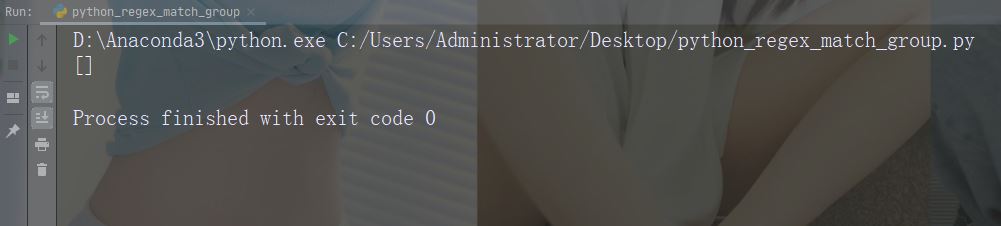
如果未找到匹配,则返回空列表:
import re
str = "China is a great country"
x = re.findall("USA", str)
print(x)运行实例
search() 函数搜索字符串中的匹配项,如果存在匹配则返回 Match 对象。
如果有多个匹配,则仅返回首个匹配项。
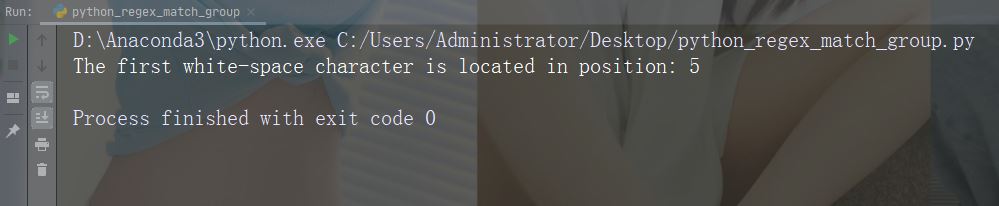
实例
在字符串中搜索第一个空白字符
import re
str = "China is a great country"
x = re.search("\s", str)
print("The first white-space character is located in position:", x.start())运行实例
如果未找到匹配,则返回值 None:
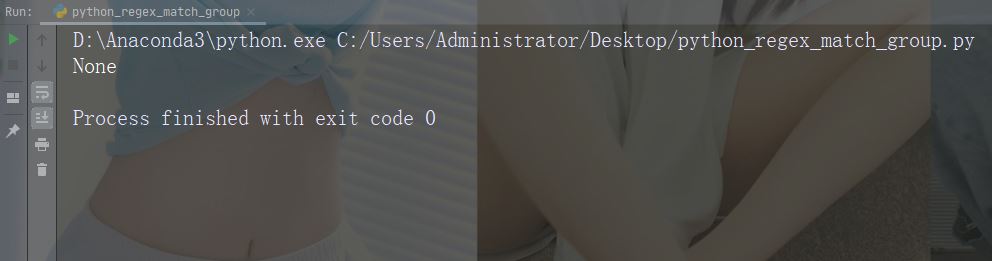
实例
进行不返回匹配的检索
import re
str = "China is a great country"
x = re.search("USA", str)
print(x)运行实例
split() 函数返回一个列表,其中字符串在每次匹配时被拆分。
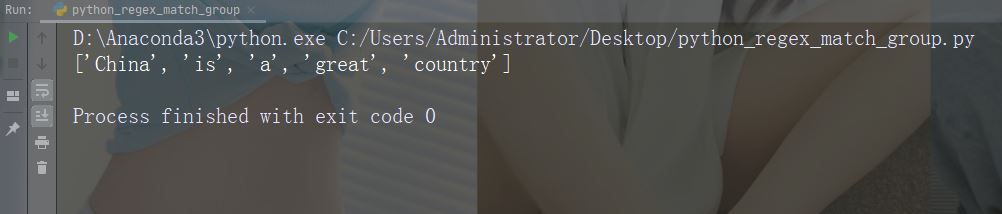
实例
在每个空白字符处进行拆分
import re
str = "China is a great country"
x = re.split("\s", str)
print(x)运行实例
可以通过指定 maxsplit 参数来控制出现次数:
实例
仅在首次出现时拆分字符串:
import re
str = "China is a great country"
x = re.split("\s", str, 1)
print(x)运行实例
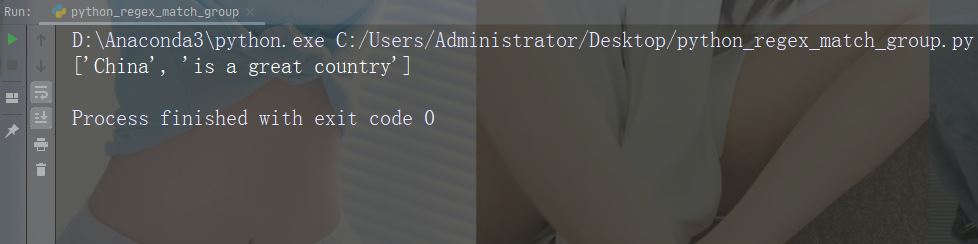
sub() 函数把匹配替换为您选择的文本
实例
用数字 9 替换每个空白字符
import re
str = "China is a great country"
x = re.sub("\s", "9", str)
print(x)运行实例
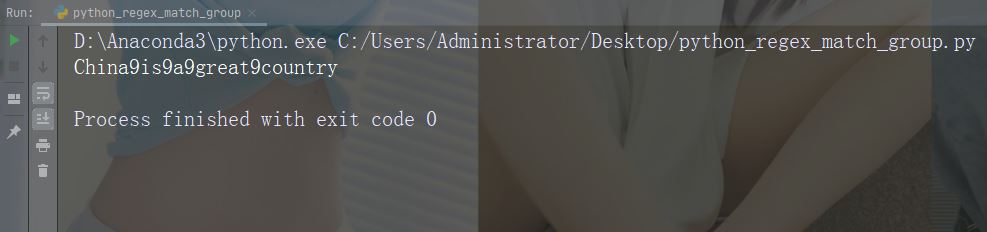
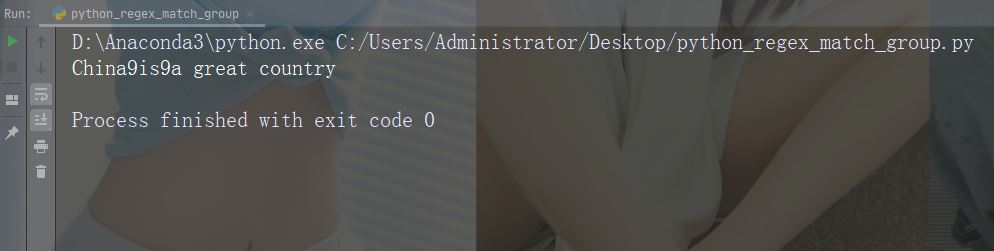
可以通过指定 count 参数来控制替换次数:
实例
替换前两次出现
import re
str = "China is a great country"
x = re.sub("\s", "9", str, 2)
print(x)运行实例
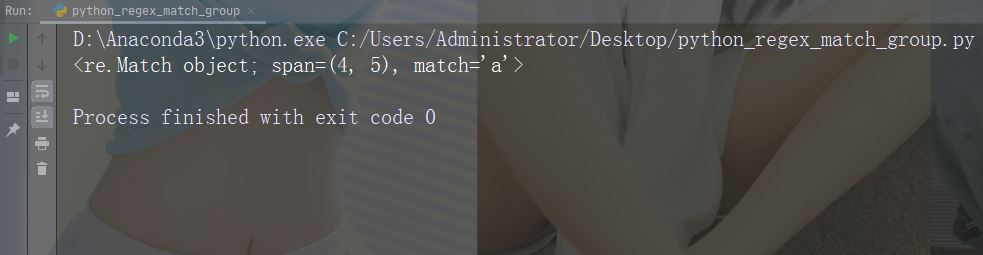
Match 对象是包含有关搜索和结果信息的对象。
注释:如果没有匹配,则返回值 None,而不是 Match 对象。
实例
执行会返回 Match 对象的搜索:
import re
str = "China is a great country"
x = re.search("a", str)
print(x) # 将打印一个对象运行实例
Match 对象提供了用于取回有关搜索及结果信息的属性和方法:
span() 返回的元组包含了匹配的开始和结束位置
.string 返回传入函数的字符串
group() 返回匹配的字符串部分
实例
打印首个匹配出现的位置(开始和结束位置)。
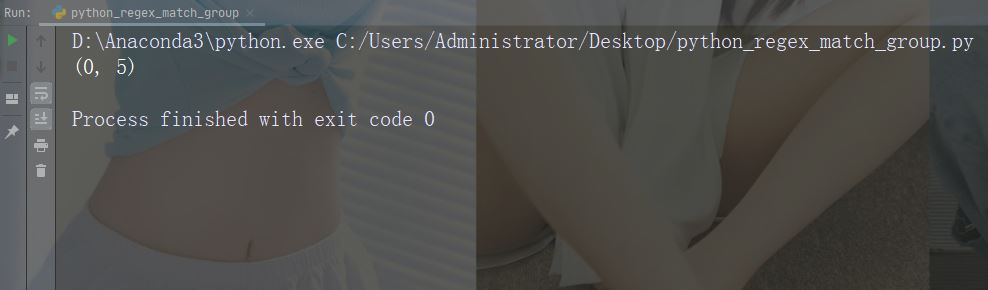
正则表达式查找以大写 “C” 开头的任何单词:
import re str = "China is a great country" x = re.search(r"\bC\w+", str) print(x.span())
运行实例
实例
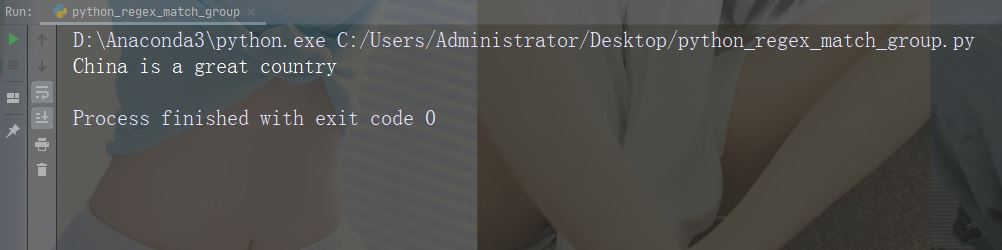
打印传入函数的字符串
import re str = "China is a great country" x = re.search(r"\bC\w+", str) print(x.string)
运行实例
实例
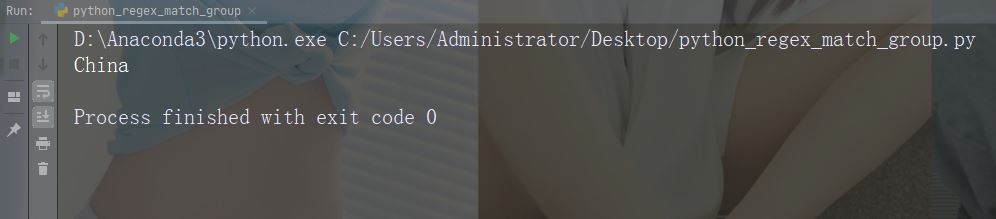
打印匹配的字符串部分
正则表达式查找以大写 “C” 开头的任何单词:
import re str = "China is a great country" x = re.search(r"\bC\w+", str) print(x.group())
运行实例
注释:如果没有匹配项,则返回值 None,而不是 Match 对象。
Atas ialah kandungan terperinci Cara menggunakan ungkapan biasa RegEx Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



