

Apabila bekerja pada projek pembelajaran mesin, terutamanya apabila berurusan dengan pembelajaran mendalam dan rangkaian saraf, adalah lebih baik untuk bekerja dengan GPU daripada CPU kerana walaupun GPU yang sangat asas akan mengatasi prestasi CPU apabila ia berkaitan dengan rangkaian saraf.

Tetapi GPU manakah yang patut anda beli? Artikel ini akan meringkaskan faktor yang berkaitan untuk dipertimbangkan supaya anda boleh membuat pilihan termaklum berdasarkan belanjawan anda dan keperluan pemodelan khusus.
CPU (Unit Pemprosesan Pusat) adalah kerja utama komputer Ia sangat fleksibel Ia bukan sahaja perlu memproses arahan daripada pelbagai program dan perkakasan, tetapi juga mempunyai keperluan kelajuan pemprosesan tertentu. Untuk melaksanakan dengan baik dalam persekitaran berbilang tugas ini, CPU mempunyai sebilangan kecil unit pemprosesan yang fleksibel dan pantas (juga dipanggil teras).
GPU (Unit Pemprosesan Grafik) GPU tidak begitu fleksibel apabila melibatkan pelbagai tugas. Tetapi ia boleh melakukan sejumlah besar pengiraan matematik kompleks secara selari. Ini dicapai dengan mempunyai bilangan teras ringkas yang lebih besar (beribu hingga berpuluh ribu) yang boleh mengendalikan banyak pengiraan mudah secara serentak.
Keperluan untuk melakukan berbilang pengiraan secara selari adalah sesuai untuk:
Perbezaan utama antara CPU dan GPU telah diringkaskan pada blog Nvidia sendiri:
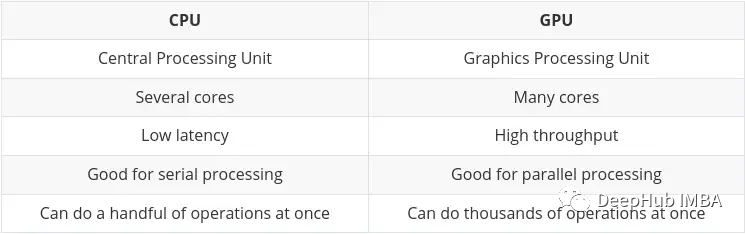
Dengan perkembangan kecerdasan buatan dan pembelajaran mesin/mendalam, kini terdapat lebih banyak teras pemprosesan khusus yang dipanggil teras tensor. Mereka lebih pantas dan lebih cekap apabila melakukan pengiraan tensor/matriks. Kerana jenis data yang kami berurusan dalam pembelajaran mesin/mendalam ialah tensor.
Walaupun terdapat TPU khusus, beberapa GPU terbaharu turut menyertakan banyak teras tensor, yang akan kami ringkaskan kemudian.
Ini akan menjadi bahagian yang agak pendek kerana jawapan kepada soalan ini pastinya Nvidia
Walaupun mungkin untuk menggunakan GPU AMD untuk mesin/pembelajaran mendalam , Tetapi setakat penulisan ini, GPU Nvidia lebih serasi dan secara amnya lebih baik disepadukan ke dalam alatan seperti TensorFlow dan PyTorch (contohnya, sokongan PyTorch untuk GPU AMD kini hanya tersedia di Linux).
Menggunakan GPU AMD memerlukan penggunaan alat tambahan (ROCm), yang memerlukan sedikit kerja tambahan dan versi mungkin tidak dikemas kini dengan cepat. Keadaan ini mungkin bertambah baik pada masa hadapan, tetapi buat masa ini, lebih baik untuk kekal dengan Nvidia.
Memilih GPU yang mencukupi untuk tugasan pembelajaran mesin anda dan bersesuaian dengan belanjawan anda pada asasnya bermuara kepada keseimbangan empat faktor utama:
Saya akan meneroka aspek ini satu demi satu di bawah, dengan harapan dapat memberi anda pemahaman yang lebih baik tentang perkara yang penting kepada anda.
Jawapannya, semakin banyak semakin baik
Ia benar-benar bergantung pada tugas anda dan seberapa besar model tersebut. Sebagai contoh, jika anda memproses imej, video atau audio, maka mengikut definisi anda akan memproses jumlah data yang agak besar, dan GPU RAM akan menjadi pertimbangan yang sangat penting.
Selalu ada cara untuk menyelesaikan masalah kehabisan ingatan (seperti mengurangkan saiz kelompok). Tetapi ini akan membuang masa latihan, jadi keperluan perlu diseimbangkan dengan baik.
Berdasarkan pengalaman, syor saya adalah seperti berikut:
Secara umumnya, jika kosnya sama, anda lebih baik memilih kad "lebih perlahan" dengan lebih banyak memori. Perlu diingat bahawa kelebihan GPU ialah daya pemprosesan yang tinggi, yang sangat bergantung pada RAM yang tersedia untuk memindahkan data melalui GPU.
Ini sebenarnya sangat mudah, semakin banyak semakin baik.
Pertimbangkan RAM dahulu, kemudian CUDA. Untuk pembelajaran mesin/mendalam, teras Tensor adalah lebih baik (lebih cepat, lebih cekap) daripada teras CUDA. Ini kerana ia direka dengan tepat untuk pengiraan yang diperlukan dalam bidang mesin/pembelajaran mendalam.
Tetapi itu tidak penting kerana kernel CUDA sudah cukup pantas. Jika anda boleh mendapatkan kad yang mengandungi teras Tensor, itu adalah satu kelebihan yang hebat, cuma jangan terlalu bergantung padanya.
Anda akan melihat "CUDA" disebut berkali-kali kemudian, mari kita ringkaskan dahulu:
Teras CUDA - ini adalah pemproses fizikal pada kad grafik, biasanya terdapat beribu-ribu daripadanya, 4090 adalah sudah 16,000.
CUDA 11 - Nombor mungkin berubah, tetapi ini merujuk kepada perisian/pemacu yang dipasang untuk membolehkan kad grafik berfungsi dengan baik. NV mengeluarkan versi baharu dengan kerap, dan ia boleh dipasang dan dikemas kini seperti mana-mana perisian lain.
Algebra CUDA (atau Kuasa Kira) - Ini menerangkan nama kod kad grafik dalam lelaran kemas kininya. Ini ditetapkan pada perkakasan, jadi hanya boleh ditukar dengan menaik taraf kepada kad baharu. Ia dibezakan dengan nombor dan nama kod. Contoh: 3. x[Kepler],5. x[Maxwell], 6. x [Pascal], 7. x[Turing] dan 8. x(Ampere).
Ini sebenarnya lebih penting daripada yang anda fikirkan. Kami tidak membincangkan AMD di sini, saya hanya mempunyai "Huang Lama" di mata saya.
Seperti yang telah kami katakan di atas, 30 kad siri adalah seni bina Ampere, dan 40 siri terbaharu ialah Ada Lovelace. Biasanya Huang akan menamakan seni bina itu dengan nama seorang saintis dan ahli matematik terkenal Kali ini dia memilih Ada Lovelace, anak perempuan penyair terkenal British Byron, ahli matematik wanita dan pengasas program komputer yang menubuhkan konsep gelung dan subrutin.
Untuk memahami kuasa pengkomputeran kad, kita perlu memahami dua aspek:
Terdapat banyak faedah menggunakan format nombor dengan ketepatan kurang daripada titik terapung 32-bit. Mula-mula mereka memerlukan kurang ingatan, membolehkan latihan dan penggunaan rangkaian saraf yang lebih besar. Kedua, mereka memerlukan kurang lebar jalur memori, sekali gus mempercepatkan operasi pemindahan data. Operasi matematik ketiga berjalan lebih pantas dengan ketepatan yang dikurangkan, terutamanya pada GPU dengan Teras Tensor. Latihan ketepatan campuran mencapai semua faedah ini sambil memastikan tiada kehilangan ketepatan khusus tugas berbanding latihan ketepatan penuh. Ia melakukan ini dengan mengenal pasti langkah-langkah yang memerlukan ketepatan penuh dan menggunakan titik terapung 32-bit sahaja untuk langkah tersebut dan titik terapung 16-bit di tempat lain.
Berikut ialah dokumen rasmi Nvidia Jika anda berminat, anda boleh membacanya:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index. .html
Latihan ketepatan hibrid hanya boleh dilakukan jika GPU anda mempunyai seni bina 7.x (Turing) atau lebih tinggi. Ini bermakna siri RTX 20 atau lebih tinggi pada desktop, atau siri "T" atau "A" pada pelayan.
Sebab utama latihan ketepatan campuran mempunyai kelebihan sedemikian ialah ia mengurangkan penggunaan RAM Tensor Core akan mempercepatkan latihan ketepatan campuran Jika tidak, menggunakan FP16 juga akan menjimatkan memori video dan boleh melatih saiz kelompok yang lebih besar. secara tidak langsung meningkatkan kelajuan latihan.
Jika anda mempunyai keperluan yang sangat tinggi untuk RAM tetapi tidak mempunyai wang yang mencukupi untuk membeli kad mewah, maka anda boleh memilih GPU yang lebih lama pada yang kedua -pasaran tangan. Terdapat kelemahan yang agak besar untuk ini...kehidupan kad itu telah berakhir.
Contoh biasa ialah Tesla K80, yang mempunyai 4992 teras CUDA dan 24GB RAM. Pada tahun 2014, ia dijual pada harga kira-kira $7,000. Harga semasa berkisar antara 150 hingga 170 dolar AS! (Harga ikan masin sekitar 600-700) Anda pasti sangat teruja untuk memiliki memori yang besar dengan harga yang begitu kecil.
Tetapi ada masalah yang sangat besar. Seni bina pengkomputeran K80 ialah 3.7 (Kepler), yang tidak lagi disokong bermula dari CUDA 11 (versi CUDA semasa ialah 11.7). Ini bermakna kad itu telah tamat tempoh, sebab itu ia dijual dengan murah.
Jadi apabila memilih kad terpakai, pastikan anda menyemak sama ada ia menyokong versi terkini pemandu dan CUDA Ini adalah perkara yang paling penting.
Lao Huang pada asasnya membahagikan kad itu kepada dua bahagian. Kad grafik pengguna dan kad grafik stesen kerja/pelayan (iaitu kad grafik profesional).
Terdapat perbezaan yang jelas antara kedua-dua bahagian, untuk spesifikasi yang sama (RAM, teras CUDA, seni bina) kad grafik pengguna biasanya akan lebih murah. Tetapi kad profesional biasanya mempunyai kualiti yang lebih baik dan penggunaan tenaga yang lebih rendah (sebenarnya, bunyi turbin agak kuat, yang baik apabila diletakkan di dalam bilik komputer, tetapi agak bising apabila diletakkan di rumah atau di makmal).
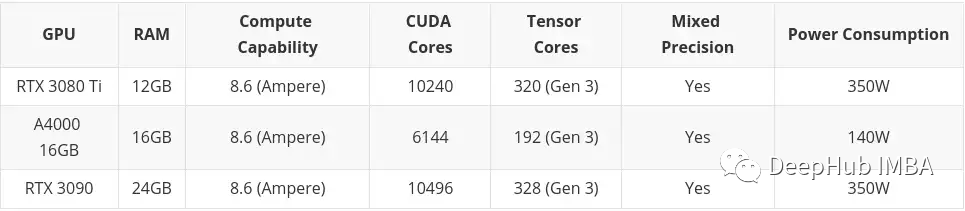
Kad profesional mewah (sangat mahal), anda mungkin perasan bahawa ia mempunyai banyak RAM (cth. RTX A6000 mempunyai 48GB, A100 mempunyai 80GB!). Ini kerana mereka biasanya menyasarkan pasaran profesional pemodelan 3D, pemaparan dan mesin/pembelajaran mendalam, yang memerlukan tahap RAM yang tinggi. Sekali lagi, jika anda mempunyai wang, beli sahaja A100! (H100 adalah versi baru A100 dan tidak boleh dinilai pada masa ini)
Tetapi saya secara peribadi berpendapat bahawa kita harus memilih kad permainan mewah pengguna, kerana jika anda tidak Jika anda tidak mempunyai wang yang mencukupi, anda tidak akan membaca artikel ini, betul
Jadi pada akhirnya saya membuat beberapa cadangan berdasarkan bajet dan keperluan. Saya membahagikannya kepada tiga bahagian:
Bajet yang tinggi tidak memerlukan apa-apa menjadi pertimbangan Di luar kad grafik pengguna mewah. Sekali lagi, jika anda mempunyai wang: beli A100 atau H100.
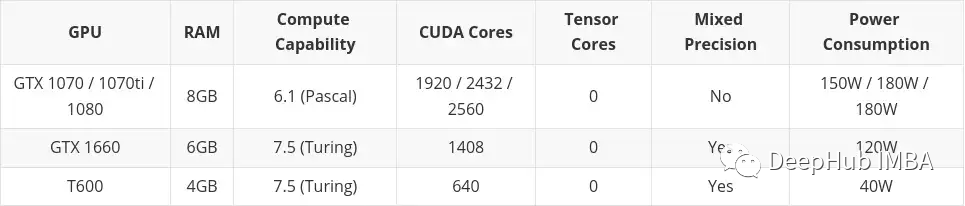
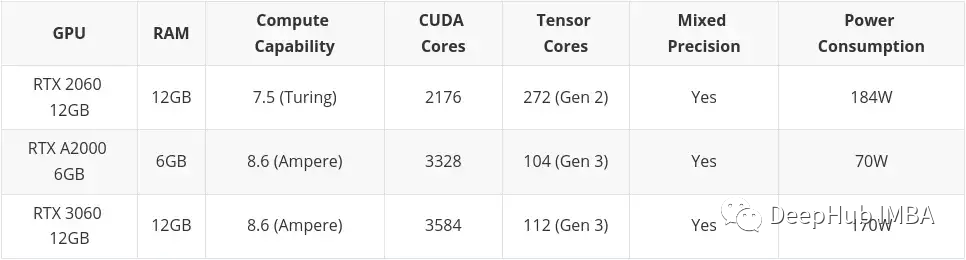
Artikel ini akan memasukkan kad yang dibeli di pasaran terpakai. Ini adalah terutamanya kerana saya fikir barangan terpakai adalah sesuatu yang perlu dipertimbangkan jika anda mempunyai bajet yang rendah. Kad Siri Desktop Profesional (T600, A2000 dan A4000) turut disertakan di sini, kerana beberapa konfigurasinya lebih buruk sedikit daripada kad grafik pengguna yang serupa, tetapi penggunaan kuasa adalah lebih baik dengan ketara.
Jika anda memutuskan bahawa membelanjakan wang pada kad grafik bukan untuk anda, anda boleh memanfaatkan Google Colab, yang membolehkan anda menggunakan GPU secara percuma.
Tetapi ada had masa, jika anda menggunakan GPU terlalu lama mereka akan menendang anda keluar dan kembali ke CPU. Ia juga akan mengambil kembali GPU jika ia tidak aktif terlalu lama, mungkin semasa anda menulis kod. GPU juga diperuntukkan secara automatik, jadi anda tidak boleh memilih GPU tepat yang anda mahukan (anda juga boleh mendapatkan Colab Pro dengan harga $9.99 sebulan, yang secara peribadi saya fikir adalah lebih baik daripada bajet rendah, tetapi memerlukan tangga, dan $49.99 Colab Pro+ agak Mahal, tidak disyorkan).
Pada masa penulisan, GPU berikut tersedia melalui Colab:
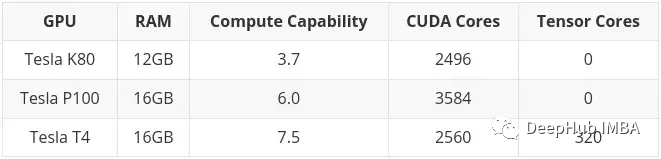
Seperti yang dinyatakan sebelum ini, K80 mempunyai 24GB RAM dan 4992 teras CUDA, Ia pada asasnya dua kad K40 dipautkan bersama. Ini bermakna apabila anda menggunakan K80 dalam Colab, anda sebenarnya mempunyai akses kepada separuh kad, jadi itu hanya teras 12GB dan 2496 CUDA.
Akhirnya, 4090 masih dalam keadaan monyet pada asasnya, anda perlu tergesa-gesa untuk membelinya atau mencari scalper pada harga yang lebih tinggi
Tetapi 16384. CUDA + 24GB, berbanding 10496 CUDA daripada 3090, ia benar-benar Sangat wangi.
Jika harga 4080 16G 9728CUDA boleh mencecah dalam lingkungan 7000, ia sepatutnya menjadi pilihan yang sangat kos efektif. Jangan anggap 12G 4080, ia tidak layak diberi nama.
7900XTX AMD juga sepatutnya menjadi pilihan yang baik, tetapi keserasian adalah isu besar Jika sesiapa mengujinya, anda boleh meninggalkan mesej.
40 siri Lao Huang telah bermain monyet, jadi jika anda tidak tergesa-gesa, anda boleh menunggu sedikit lagi:
Anda tidak membelinya, saya tidak' t beli, dan ia akan dikurangkan sebanyak 200 esok
Atas ialah kandungan terperinci Memilih GPU terbaik untuk pembelajaran mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



