
 Peranti teknologi
AI
Menjana video adalah sangat mudah, cuma berikan petunjuk dan anda juga boleh mencubanya dalam talian
Peranti teknologi
AI
Menjana video adalah sangat mudah, cuma berikan petunjuk dan anda juga boleh mencubanya dalam talian
Menjana video adalah sangat mudah, cuma berikan petunjuk dan anda juga boleh mencubanya dalam talian

Anda memasukkan teks dan membiarkan AI menjana video. Idea ini hanya muncul dalam imaginasi orang sebelum ini, dengan perkembangan teknologi, fungsi ini telah direalisasikan.
Dalam beberapa tahun kebelakangan ini, kecerdasan buatan generatif telah menarik perhatian besar dalam bidang penglihatan komputer. Dengan kemunculan model penyebaran, menghasilkan imej berkualiti tinggi daripada gesaan teks, iaitu sintesis teks ke imej, telah menjadi sangat popular dan berjaya.
Percubaan penyelidikan terkini untuk berjaya memanjangkan model resapan teks-ke-imej kepada tugas penjanaan dan pengeditan teks-ke-video dengan menggunakannya semula dalam domain video. Walaupun kaedah sedemikian telah mencapai hasil yang menjanjikan, kebanyakannya memerlukan latihan yang meluas menggunakan sejumlah besar data berlabel, yang mungkin terlalu mahal untuk kebanyakan pengguna.
Untuk menjadikan penjanaan video lebih murah, Tune-A-Video yang dicadangkan oleh Jay Zhangjie Wu et al tahun lepas memperkenalkan mekanisme untuk menggunakan model Stable Diffusion (SD) pada video padang . Hanya satu video yang perlu dilaraskan, sangat mengurangkan beban kerja latihan. Walaupun ini jauh lebih cekap daripada kaedah sebelumnya, ia masih memerlukan pengoptimuman. Tambahan pula, keupayaan penjanaan Tune-A-Video adalah terhad kepada aplikasi penyuntingan video berpandukan teks, dan penggubahan video dari awal kekal di luar kemampuannya.
Dalam artikel ini, penyelidik dari Picsart AI Resarch (PAIR), University of Texas di Austin dan institusi lain telah menggunakan zero-shot dan tiada latihan untuk mencapai kaedah text-to baharu -sintesis video Satu langkah ke hadapan dalam arah masalah menjana video berdasarkan gesaan teks tanpa sebarang pengoptimuman atau penalaan halus.

- Alamat kertas: https://arxiv.org/ pdf/2303.13439.pdf
- Alamat projek: https://github.com/Picsart-AI-Research/Text2Video-Zero
- Alamat percubaan: https://huggingface.co/spaces/PAIR/Text2Video-Zero
Mari kita lihat cara ia berfungsi. Contohnya, seekor panda sedang melayari; seekor beruang sedang menari di Times Square:

Penyelidikan ini juga boleh menjana tindakan berdasarkan pada sasaran :

Selain itu, pengesanan tepi boleh dilakukan:

Konsep utama pendekatan yang dicadangkan dalam kertas kerja ini ialah mengubah suai model teks-ke-imej yang telah terlatih (cth. Resapan Stabil) untuk memperkayakannya mengikut masa -generasi yang konsisten. Dengan membina model teks-ke-imej yang sudah terlatih, pendekatan kami memanfaatkan kualiti penjanaan imej yang sangat baik, meningkatkan kebolehgunaannya pada domain video tanpa memerlukan latihan tambahan.
Untuk meningkatkan ketekalan temporal, kertas kerja ini mencadangkan dua pengubahsuaian inovatif: (1) mula-mula memperkayakan pengekodan terpendam bagi bingkai yang dijana dengan maklumat gerakan untuk memastikan pemandangan dan latar belakang global konsisten secara sementara; (2) ) kemudian menggunakan mekanisme perhatian bingkai silang untuk mengekalkan konteks, rupa dan identiti objek latar depan sepanjang jujukan. Eksperimen menunjukkan bahawa pengubahsuaian mudah ini boleh menghasilkan video yang berkualiti tinggi dan konsisten dari segi masa (ditunjukkan dalam Rajah 1).

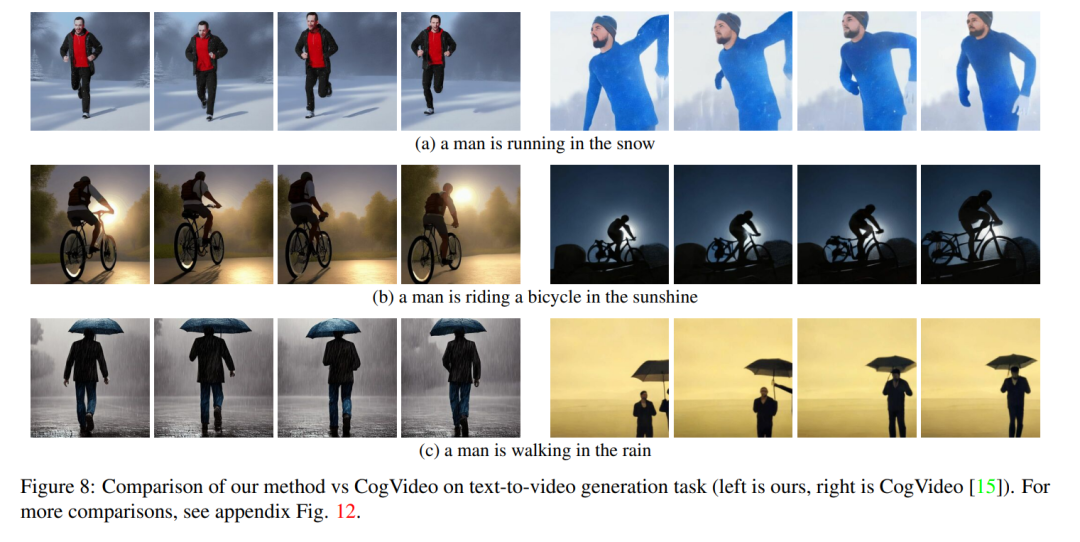
Sementara kerja orang lain dilatih pada data video berskala besar, kaedah kami mencapai prestasi yang serupa dan kadangkala lebih baik (seperti yang ditunjukkan dalam Rajah 8, 9).

Kaedah dalam artikel ini tidak terhad kepada sintesis teks-ke-video, tetapi juga sesuai untuk bersyarat (lihat Rajah 6, 5) dan penjanaan video khusus (lihat Rajah 7), serta video berpandukan arahan penyuntingan, yang boleh dipanggil Ia ialah Video Instruct-Pix2Pix yang dipacu oleh Instruct-Pix2Pix (lihat Rajah 9).


Dalam kertas ini, kertas kerja ini menggunakan keupayaan sintesis teks-ke-imej Stable Diffusion (SD) untuk mengendalikan tugasan teks-ke-video dalam situasi sifar tangkapan. Untuk keperluan penjanaan video dan bukannya penjanaan imej, SD harus menumpukan pada operasi jujukan kod asas. Pendekatan naif adalah untuk mencuba secara bebas kod potensi m daripada taburan Gaussian standard, iaitu
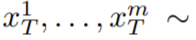
N (0, I) , dan gunakan Sampel DDIM untuk mendapatkan tensor yang sepadan
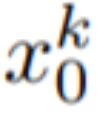
, dengan k = 1,…,m, kemudian nyahkod ke Dapatkan urutan video yang dijana 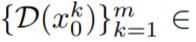
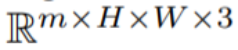
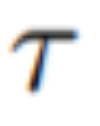

Untuk menyelesaikan masalah ini, artikel ini mengesyorkan dua kaedah berikut: (i) Dalam pengekodan terpendam 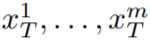 untuk mengekalkan ketekalan temporal adegan global; (ii) mekanisme perhatian bingkai silang digunakan untuk mengekalkan rupa dan identiti objek latar depan. Setiap komponen kaedah yang digunakan dalam kertas ini diterangkan secara terperinci di bawah, dan gambaran keseluruhan kaedah boleh didapati dalam Rajah 2.
untuk mengekalkan ketekalan temporal adegan global; (ii) mekanisme perhatian bingkai silang digunakan untuk mengekalkan rupa dan identiti objek latar depan. Setiap komponen kaedah yang digunakan dalam kertas ini diterangkan secara terperinci di bawah, dan gambaran keseluruhan kaedah boleh didapati dalam Rajah 2.
Ambil perhatian bahawa untuk memudahkan tatatanda, artikel ini mewakili keseluruhan jujukan kod berpotensi sebagai: 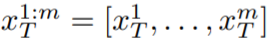
Hasil kualitatif
Semua aplikasi Text2Video-Zero menunjukkan bahawa ia berjaya menjana video dengan ketekalan temporal adegan dan latar belakang global, latar depan Konteks , rupa dan identiti objek dikekalkan sepanjang jujukan.
Dalam kes teks-ke-video, dapat diperhatikan bahawa ia menghasilkan video berkualiti tinggi yang sejajar dengan gesaan teks (lihat Rajah 3). Sebagai contoh, seekor panda ditarik untuk berjalan secara semula jadi di jalan. Begitu juga, menggunakan panduan tepi atau pose tambahan (lihat Rajah 5, 6, dan 7), gesaan dan panduan pemadanan video berkualiti tinggi telah dihasilkan, menunjukkan ketekalan temporal yang baik dan pemeliharaan identiti.

Dalam kes Video Instruct-Pix2Pix (lihat Rajah 1), video yang dihasilkan Kesetiaan tinggi berbanding dengan video input sambil mengikuti arahan dengan tegas.
Perbandingan dengan Baseline
Kerja ini membandingkan kaedahnya dengan dua garis dasar yang tersedia secara umum: CogVideo dan Tune -A- Video. Memandangkan CogVideo ialah kaedah teks ke video, artikel ini membandingkannya dengannya dalam senario sintesis video berpandukan teks biasa menggunakan Video Instruct-Pix2Pix untuk perbandingan dengan Tune-A-Video.
Untuk perbandingan kuantitatif, artikel ini menggunakan skor CLIP untuk menilai model, yang mewakili tahap penjajaran teks video. Dengan mendapatkan 25 video yang dijana oleh CogVideo secara rawak, dan mensintesis video yang sepadan menggunakan petua yang sama mengikut kaedah dalam artikel ini. Skor CLIP kaedah kami dan CogVideo masing-masing ialah 31.19 dan 29.63. Oleh itu, kaedah kami lebih baik sedikit daripada CogVideo, walaupun yang terakhir mempunyai 9.4 bilion parameter dan memerlukan latihan berskala besar pada video.
Rajah 8 menunjukkan beberapa keputusan kaedah yang dicadangkan dalam kertas ini dan menyediakan perbandingan kualitatif dengan CogVideo. Kedua-dua kaedah menunjukkan ketekalan temporal yang baik sepanjang jujukan, mengekalkan identiti objek serta konteksnya. Kaedah kami menunjukkan keupayaan penjajaran teks-video yang lebih baik. Sebagai contoh, kaedah kami menjana video seseorang yang menunggang basikal di bawah matahari dengan betul dalam Rajah 8 (b), manakala CogVideo menetapkan latar belakang kepada cahaya bulan. Juga dalam Rajah 8 (a), kaedah kami menunjukkan dengan betul seseorang berlari di dalam salji, manakala salji dan orang yang berlari tidak dapat dilihat dengan jelas dalam video yang dijana oleh CogVideo.
Keputusan kualitatif Video Instruct-Pix2Pix dan perbandingan visual dengan setiap bingkai Instruct-Pix2Pix dan Tune-AVideo ditunjukkan dalam Rajah 9. Walaupun Instruct-Pix2Pix menunjukkan prestasi penyuntingan yang baik bagi setiap bingkai, ia tidak mempunyai konsistensi temporal. Ini amat ketara dalam video yang menggambarkan pemain ski, di mana salji dan langit dilukis menggunakan gaya dan warna yang berbeza. Isu ini telah diselesaikan menggunakan kaedah Video Instruct-Pix2Pix, menghasilkan pengeditan video yang konsisten secara sementara sepanjang jujukan.
Walaupun Tune-A-Video mencipta penjanaan video yang konsisten masa, berbanding dengan kaedah artikel ini, ia kurang konsisten dengan panduan arahan, sukar untuk membuat suntingan tempatan dan Butiran input urutan hilang. Ini menjadi jelas apabila melihat suntingan video penari yang digambarkan dalam Rajah 9, kiri. Berbanding dengan Tune-A-Video, kaedah kami melukis keseluruhan pakaian dengan lebih cerah sambil mengekalkan latar belakang dengan lebih baik, seperti dinding di belakang penari kekal hampir tidak berubah. Tune-A-Video mengecat dinding yang sangat cacat. Selain itu, kaedah kami lebih sesuai dengan butiran input Contohnya, berbanding dengan Tune-A-Video, Video Instruction-Pix2Pix menarik penari menggunakan pose yang disediakan (Rajah 9 kiri) dan memaparkan semua pemain ski yang muncul dalam video input. Seperti yang ditunjukkan dalam bingkai terakhir di sebelah kanan Rajah 9). Semua kelemahan Tune-A-Video yang disebutkan di atas juga boleh diperhatikan dalam Rajah 23, 24.


Atas ialah kandungan terperinci Menjana video adalah sangat mudah, cuma berikan petunjuk dan anda juga boleh mencubanya dalam talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Adakah ia melanggar untuk menyiarkan video orang lain di Douyin? Bagaimanakah ia mengedit video tanpa pelanggaran?
Mar 21, 2024 pm 05:57 PM
Adakah ia melanggar untuk menyiarkan video orang lain di Douyin? Bagaimanakah ia mengedit video tanpa pelanggaran?
Mar 21, 2024 pm 05:57 PM
Dengan peningkatan platform video pendek, Douyin telah menjadi bahagian yang sangat diperlukan dalam kehidupan seharian setiap orang. Di TikTok, kita boleh melihat video menarik dari seluruh dunia. Sesetengah orang suka menyiarkan video orang lain, yang menimbulkan persoalan: Adakah Douyin melanggar apabila menyiarkan video orang lain? Artikel ini akan membincangkan isu ini dan memberitahu anda cara mengedit video tanpa pelanggaran dan cara mengelakkan isu pelanggaran. 1. Adakah ia melanggar penyiaran video orang lain oleh Douyin? Menurut peruntukan Undang-undang Hak Cipta negara saya, penggunaan tanpa kebenaran karya pemilik hak cipta tanpa kebenaran pemilik hak cipta adalah satu pelanggaran. Oleh itu, menyiarkan video orang lain di Douyin tanpa kebenaran pengarang asal atau pemilik hak cipta adalah satu pelanggaran. 2. Bagaimana untuk mengedit video tanpa pelanggaran? 1. Penggunaan domain awam atau kandungan berlesen: Awam
 Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Bagaimanakah seorang pemula boleh membuat wang di Douyin?
Mar 21, 2024 pm 08:17 PM
Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Bagaimanakah seorang pemula boleh membuat wang di Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, platform video pendek kebangsaan, bukan sahaja membolehkan kami menikmati pelbagai video pendek yang menarik dan novel pada masa lapang kami, tetapi juga memberi kami pentas untuk menunjukkan diri kami dan merealisasikan nilai kami. Jadi, bagaimana untuk membuat wang dengan menyiarkan video di Douyin? Artikel ini akan menjawab soalan ini secara terperinci dan membantu anda menjana lebih banyak wang di TikTok. 1. Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Selepas menyiarkan video dan mendapat jumlah tontonan tertentu pada Douyin, anda akan berpeluang untuk mengambil bahagian dalam pelan perkongsian pengiklanan. Kaedah pendapatan ini adalah salah satu yang paling biasa kepada pengguna Douyin dan juga merupakan sumber pendapatan utama bagi banyak pencipta. Douyin memutuskan sama ada untuk menyediakan peluang perkongsian pengiklanan berdasarkan pelbagai faktor seperti berat akaun, kandungan video dan maklum balas khalayak. Platform TikTok membolehkan penonton menyokong pencipta kegemaran mereka dengan menghantar hadiah,
 Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej_Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej
Mar 30, 2024 pm 12:26 PM
Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej_Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej
Mar 30, 2024 pm 12:26 PM
1. Mula-mula buka Weibo pada telefon mudah alih anda dan klik [Saya] di sudut kanan bawah (seperti yang ditunjukkan dalam gambar). 2. Kemudian klik [Gear] di penjuru kanan sebelah atas untuk membuka tetapan (seperti yang ditunjukkan dalam gambar). 3. Kemudian cari dan buka [Tetapan Umum] (seperti yang ditunjukkan dalam gambar). 4. Kemudian masukkan pilihan [Video Follow] (seperti yang ditunjukkan dalam gambar). 5. Kemudian buka tetapan [Video Upload Resolution] (seperti yang ditunjukkan dalam gambar). 6. Akhir sekali, pilih [Kualiti Imej Asal] untuk mengelakkan pemampatan (seperti yang ditunjukkan dalam gambar).
 Empat alat pengaturcaraan berbantukan AI yang disyorkan
Apr 22, 2024 pm 05:34 PM
Empat alat pengaturcaraan berbantukan AI yang disyorkan
Apr 22, 2024 pm 05:34 PM
Alat pengaturcaraan berbantukan AI ini telah menemui sejumlah besar alat pengaturcaraan berbantukan AI yang berguna dalam peringkat pembangunan AI yang pesat ini. Alat pengaturcaraan berbantukan AI boleh meningkatkan kecekapan pembangunan, meningkatkan kualiti kod dan mengurangkan kadar pepijat Ia adalah pembantu penting dalam proses pembangunan perisian moden. Hari ini Dayao akan berkongsi dengan anda 4 alat pengaturcaraan berbantukan AI (dan semua menyokong bahasa C# saya harap ia akan membantu semua orang). https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot ialah pembantu pengekodan AI yang membantu anda menulis kod dengan lebih pantas dan dengan sedikit usaha, supaya anda boleh lebih memfokuskan pada penyelesaian masalah dan kerjasama. Git
 Bagaimana untuk menerbitkan karya video Xiaohongshu? Apakah yang perlu saya perhatikan semasa menyiarkan video?
Mar 23, 2024 pm 08:50 PM
Bagaimana untuk menerbitkan karya video Xiaohongshu? Apakah yang perlu saya perhatikan semasa menyiarkan video?
Mar 23, 2024 pm 08:50 PM
Dengan kemunculan platform video pendek, Xiaohongshu telah menjadi platform untuk ramai orang berkongsi kehidupan mereka, meluahkan perasaan mereka dan mendapatkan trafik. Pada platform ini, menerbitkan karya video ialah cara interaksi yang sangat popular. Jadi, bagaimana untuk menerbitkan karya video Xiaohongshu? 1. Bagaimana untuk menerbitkan karya video Xiaohongshu? Mula-mula, pastikan anda mempunyai kandungan video yang sedia untuk dikongsi. Anda boleh menggunakan telefon bimbit anda atau peralatan kamera lain untuk merakam, tetapi anda perlu memberi perhatian kepada kualiti imej dan kejelasan bunyi. 2. Edit video: Untuk menjadikan kerja lebih menarik, anda boleh mengedit video. Anda boleh menggunakan perisian penyuntingan video profesional, seperti Douyin, Kuaishou, dsb., untuk menambah penapis, muzik, sari kata dan elemen lain. 3. Pilih kulit muka: Kulit adalah kunci untuk menarik pengguna untuk mengklik.
 Dua penyelesaian untuk berkongsi video web pelayar edge tanpa bunyi
Mar 14, 2024 pm 02:22 PM
Dua penyelesaian untuk berkongsi video web pelayar edge tanpa bunyi
Mar 14, 2024 pm 02:22 PM
Ramai pengguna suka menonton video pada penyemak imbas Jika tiada bunyi semasa menonton video web pada pelayar tepi, bagaimana untuk menyelesaikan masalah? Masalah ini tidak sukar. Seterusnya, izinkan saya memberitahu anda bagaimana untuk menyelesaikan masalah tiada bunyi dalam video web pelayar tepi. Tiada bunyi dalam video web pelayar tepi? Kaedah 1: 1. Mula-mula, semak tab atas pelayar tepi. 2. Terdapat "Butang Bunyi" di sebelah kiri tab, pastikan ia tidak diredamkan. Kaedah 2: 1. Jika disahkan bahawa bunyi tidak diredamkan, ia mungkin masalah tetapan bunyi. 2. Anda boleh klik kanan peranti bunyi di sudut kanan bawah dan pilih "Open Volume Synthesizer" 3. Buka
 Pengaturcara AI manakah yang terbaik? Terokai potensi Devin, Tongyi Lingma dan ejen SWE
Apr 07, 2024 am 09:10 AM
Pengaturcara AI manakah yang terbaik? Terokai potensi Devin, Tongyi Lingma dan ejen SWE
Apr 07, 2024 am 09:10 AM
Pada 3 Mac 2022, kurang daripada sebulan selepas kelahiran pengaturcara AI pertama di dunia, Devin, pasukan NLP Universiti Princeton membangunkan pengaturcara AI sumber terbuka ejen SWE. Ia memanfaatkan model GPT-4 untuk menyelesaikan isu secara automatik dalam repositori GitHub. Prestasi ejen SWE pada set ujian bangku SWE adalah serupa dengan Devin, mengambil purata 93 saat dan menyelesaikan 12.29% masalah. Dengan berinteraksi dengan terminal khusus, ejen SWE boleh membuka dan mencari kandungan fail, menggunakan semakan sintaks automatik, mengedit baris tertentu dan menulis serta melaksanakan ujian. (Nota: Kandungan di atas adalah sedikit pelarasan bagi kandungan asal, tetapi maklumat utama dalam teks asal dikekalkan dan tidak melebihi had perkataan yang ditentukan.) SWE-A
 Ketahui cara membangunkan aplikasi mudah alih menggunakan bahasa Go
Mar 28, 2024 pm 10:00 PM
Ketahui cara membangunkan aplikasi mudah alih menggunakan bahasa Go
Mar 28, 2024 pm 10:00 PM
Tutorial aplikasi mudah alih pembangunan bahasa Go Memandangkan pasaran aplikasi mudah alih terus berkembang pesat, semakin ramai pembangun mula meneroka cara menggunakan bahasa Go untuk membangunkan aplikasi mudah alih. Sebagai bahasa pengaturcaraan yang mudah dan cekap, bahasa Go juga telah menunjukkan potensi yang kukuh dalam pembangunan aplikasi mudah alih. Artikel ini akan memperkenalkan secara terperinci cara menggunakan bahasa Go untuk membangunkan aplikasi mudah alih dan melampirkan contoh kod khusus untuk membantu pembaca bermula dengan cepat dan mula membangunkan aplikasi mudah alih mereka sendiri. 1. Persediaan Sebelum memulakan, kita perlu menyediakan persekitaran dan alatan pembangunan. kepala
