
 pembangunan bahagian belakang
Tutorial Python
Cara menggunakan tracemalloc dalam Python3 untuk menjejaki perubahan memori mmap
pembangunan bahagian belakang
Tutorial Python
Cara menggunakan tracemalloc dalam Python3 untuk menjejaki perubahan memori mmap
Cara menggunakan tracemalloc dalam Python3 untuk menjejaki perubahan memori mmap

Latar Belakang Teknikal
Dalam blog sebelum ini kami memperkenalkan beberapa kaedah menggunakan python3 untuk memproses data jadual, yang memberi tumpuan kepada pemprosesan data berskala besar seperti vaex Pelan pemprosesan data. Penyelesaian pemprosesan data ini berdasarkan teknologi peta memori Dengan mencipta fail yang dipetakan memori, kami mengelakkan masalah penggunaan memori berskala besar yang disebabkan oleh memuatkan data sumber secara langsung dalam memori Ini membolehkan kami menggunakan saiz memori komputer tempatan yang bukan Proses berskala besar data dalam keadaan yang sangat besar. Dalam Python 3, terdapat perpustakaan yang dipanggil mmap yang boleh digunakan untuk mencipta fail dipetakan memori secara langsung.
Gunakan tracemalloc untuk menjejaki penggunaan memori program python
Di sini kami berharap dapat membandingkan penggunaan memori sebenar teknologi pemetaan memori, jadi kami perlu memperkenalkan alat pengesan memori berasaskan python: tracemalloc. Mari kita ambil contoh mudah dahulu, iaitu, cipta tatasusunan rawak, dan kemudian perhatikan saiz memori yang diduduki oleh tatasusunan
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)Hasil output adalah seperti berikut:
[dechin @dechin-manjaro mmap ]$ python3 tracem.py
[10 Teratas]
tracem.py:8: size=78.2 KiB, count=2, average=39.1 KiB
Jika kami menggunakan arahan atas Jika anda ingin mengesan memori secara langsung, tidak syak lagi bahawa Google Chrome mempunyai nisbah memori tertinggi:
, penggunaan memori proses kanak-kanak dijejaki mengikut nombor proses Ini adalah perkara utama menggunakan tracemalloc Di sini kita dapati bahawa jejak ingatan vektor numpy bersaiz 10,000 adalah kira-kira 39.1 KiB, yang sebenarnya selaras dengan. jangkaan kami:atas - 10:04:08 ke atas 6 hari, 15:18 , 5 pengguna, purata beban: 0.23 , 0.33, 0.27
tugas: 309 jumlah, 1 berlari, 264 tidur, 23 berhenti, 21 zombi
%Cpu(s): 0.6 us, 0.2 sy, 0.0 ni, 99. id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem: 39913.6 jumlah, 25450.8 percuma, 1875.7 terpakai, 12587.1 buff/cache
MiB Swap: 16384, 0.384 percuma 8 manfaat Mem
nombor proses PENGGUNA PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
286734 dechin 20 0 36.6g 175832 117544 S 4.0 0 .4 1:02.32 chromium
Dalam [3]: 39.1* 1024/4Kerana ini hampir jejak memori 10,000 float32 nombor titik terapung, yang menunjukkan bahawa semua elemen telah disimpan dalam ingatan. Gunakan tracemalloc untuk menjejaki perubahan memori Dalam bab sebelumnya kami memperkenalkan penggunaan syot kilat memori, kemudian kami boleh dengan mudah memikirkan "mengambil" dua syot kilat memori dan kemudian membandingkannya. t kita mendapat saiz perubahan memori dengan melihat perubahan dalam syot kilat? Seterusnya, buat percubaan mudah:Keluar[3]: 10009.6
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)[dechin@dechin-manjaro mmap]$ python3 comp_tracem.pyAnda dapat melihat bahawa purata perbezaan saiz memori sebelum dan selepas syot kilat ini ialah Pada 39.1 KiB, jika kita menukar dimensi vektor kepada 1000000:[Perbezaan 10 teratas ]
comp_tracem.py:9: size=78.2 KiB (+78.2 KiB), count=2 (+2), average=39.1 KiB
length=1000000
[dechin@dechin- manjaro mmap]$ python3 comp_tracem.pyKami mendapati Hasilnya ialah 3906, yang bersamaan dengan dibesarkan 100 kali ganda, yang lebih sesuai dengan jangkaan. Sudah tentu, jika kita mengiranya dengan teliti:[Perbezaan 10 teratas]
comp_tracem.py:9: size=7813 KiB (+7813 KiB), count=2 (+2), purata=3906 KiB
Dalam [4]: 3906*1024/4Kami dapati bahawa tidak ada Ia bukan jenis float32 sepenuhnya Berbanding dengan jenis float32 yang lengkap, sebahagian daripada saiz memori tidak ada. Walau bagaimanapun, isu ini bukan perkara yang ingin kami fokuskan. Kami terus menguji keluk perubahan memori ke bawah. Keluk penggunaan memoriMeneruskan kandungan dua bab sebelumnya, kami terutamanya menguji ruang memori yang diperlukan oleh tatasusunan rawak dimensi berbeza Berdasarkan modul kod di atas, a untuk Gelung:Keluar[4]: 999936.0
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')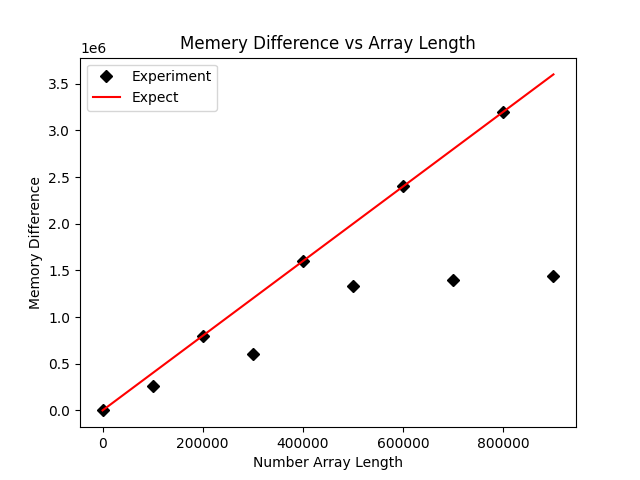
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')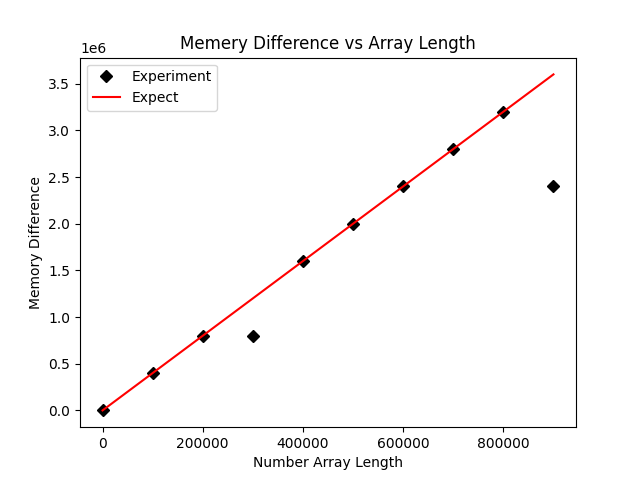
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
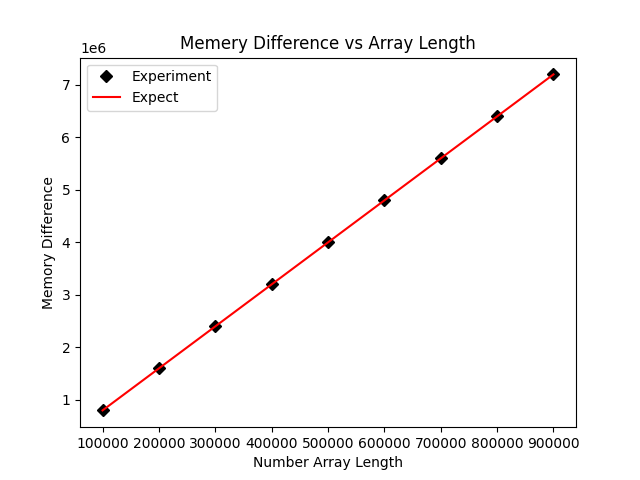
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
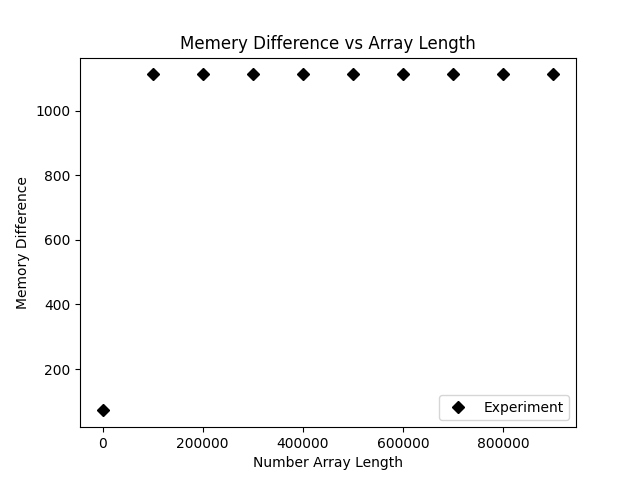
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。
Atas ialah kandungan terperinci Cara menggunakan tracemalloc dalam Python3 untuk menjejaki perubahan memori mmap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Penyimpanan Objek Minio: Penyebaran berprestasi tinggi di bawah CentOS System Minio adalah prestasi tinggi, sistem penyimpanan objek yang diedarkan yang dibangunkan berdasarkan bahasa Go, serasi dengan Amazons3. Ia menyokong pelbagai bahasa pelanggan, termasuk Java, Python, JavaScript, dan GO. Artikel ini akan memperkenalkan pemasangan dan keserasian minio pada sistem CentOS. Keserasian versi CentOS Minio telah disahkan pada pelbagai versi CentOS, termasuk tetapi tidak terhad kepada: CentOS7.9: Menyediakan panduan pemasangan lengkap yang meliputi konfigurasi kluster, penyediaan persekitaran, tetapan fail konfigurasi, pembahagian cakera, dan mini
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
 Cara Memilih Versi PyTorch di CentOS
Apr 14, 2025 pm 06:51 PM
Cara Memilih Versi PyTorch di CentOS
Apr 14, 2025 pm 06:51 PM
Apabila memasang pytorch pada sistem CentOS, anda perlu dengan teliti memilih versi yang sesuai dan pertimbangkan faktor utama berikut: 1. Keserasian Persekitaran Sistem: Sistem Operasi: Adalah disyorkan untuk menggunakan CentOS7 atau lebih tinggi. CUDA dan CUDNN: Versi Pytorch dan versi CUDA berkait rapat. Sebagai contoh, Pytorch1.9.0 memerlukan CUDA11.1, manakala Pytorch2.0.1 memerlukan CUDA11.3. Versi CUDNN juga mesti sepadan dengan versi CUDA. Sebelum memilih versi PyTorch, pastikan anda mengesahkan bahawa versi CUDA dan CUDNN yang serasi telah dipasang. Versi Python: Cawangan Rasmi Pytorch
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
