

Lapan isu yang menghalang kemajuan kecerdasan buatan


Kecerdasan buatan (AI) hari ini adalah terhad. Masih jauh lagi perjalanannya.
Sesetengah penyelidik AI telah menemui bahawa algoritma pembelajaran mesin, di mana komputer belajar melalui percubaan dan kesilapan, telah menjadi "kuasa misteri."
Jenis Kepintaran Buatan yang Berbeza
Kemajuan terkini dalam kecerdasan buatan (AI) meningkatkan banyak aspek kehidupan kita.
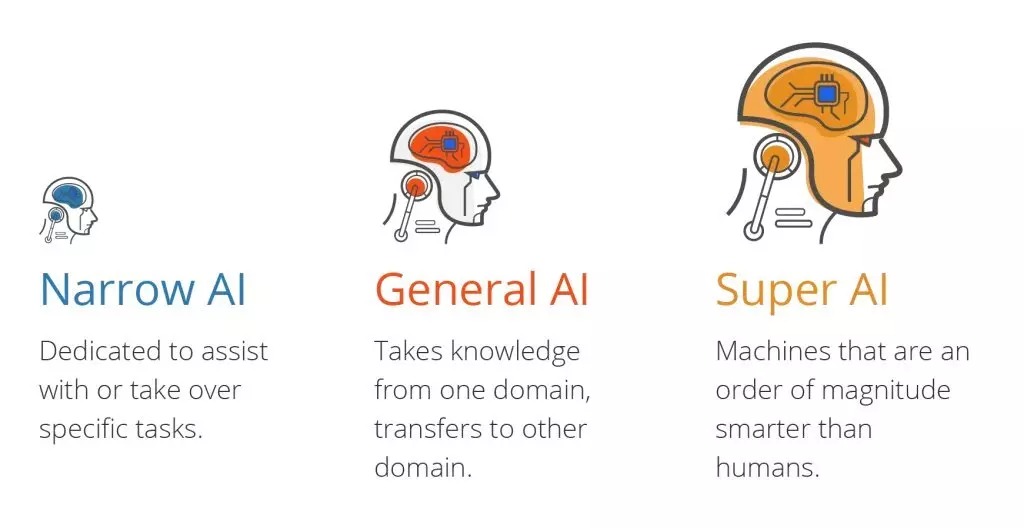
Terdapat tiga jenis kecerdasan buatan:
- Kepintaran buatan sempit (ANI), yang mempunyai skop keupayaan yang sempit.
- Kecerdasan Am Buatan (AGI), setara dengan keupayaan manusia.
- Kecerdasan Super Buatan (ASI), lebih pintar daripada manusia.
Apa yang salah dengan kecerdasan buatan hari ini?
Kecerdasan buatan hari ini didorong terutamanya oleh model dan algoritma pembelajaran statistik yang dipanggil analisis data, pembelajaran mesin, rangkaian saraf tiruan atau pembelajaran mendalam. Ia dilaksanakan sebagai gabungan infrastruktur IT (platform ML, algoritma, data, pengiraan) dan timbunan pembangunan (daripada perpustakaan kepada bahasa, IDE, aliran kerja dan visualisasi).
Ringkasnya, ia melibatkan:
- Sesetengah matematik gunaan, teori kebarangkalian dan statistik
- Sesetengah algoritma pembelajaran statistik, regresi logistik, regresi linear, pokok keputusan dan stokastik Forest
- Sesetengah algoritma pembelajaran mesin, diselia, tidak diselia dan pengukuhan
- Sesetengah rangkaian saraf tiruan, algoritma pembelajaran mendalam dan model yang menapis data input melalui berbilang lapisan untuk meramal dan mengklasifikasikan maklumat
- Sesetengah model rangkaian saraf terlatih (mampatan dan kuantisasi)
- Sesetengah model statistik dan inferens seperti Qualcomm Neural Processing SDK,
- Sesetengah bahasa pengaturcaraan seperti Python dan R.
- Sesetengah platform ML, rangka kerja dan masa jalan, seperti PyTorch, ONNX, Apache MXNet, TensorFlow, Caffe2, CNTK, SciKit-Learn dan Keras,
- Sesetengah persekitaran pembangunan bersepadu (IDE), seperti PyCharm, Kod VS Microsoft, Jupyter, MATLAB, dsb.,
- Sesetengah pelayan fizikal, mesin maya, bekas, perkakasan khusus (seperti GPU), sumber pengkomputeran berasaskan awan (termasuk mesin maya, bekas dan pengkomputeran tanpa pelayan).
Kebanyakan aplikasi AI yang digunakan hari ini boleh diklasifikasikan sebagai AI sempit, dikenali sebagai AI lemah.
Kesemuanya tidak mempunyai kecerdasan buatan am dan pembelajaran mesin, yang ditakrifkan oleh tiga enjin interaksi utama:
- Mesin model dunia [perwakilan, pembelajaran dan penaakulan] atau mesin simulasi realiti ( Rangkaian Hipergraf Dunia).
- Enjin Pengetahuan Dunia (Graf Pengetahuan Global)
- Enjin Data Dunia (Rangkaian Graf Data Global)
Aplikasi/mesin/sistem AI dan ML dan DL tujuan umum Perbezaannya terletak pada memahami dunia sebagai pelbagai gambaran yang munasabah bagi keadaan dunia, mesin realitinya dan enjin pengetahuan global dan enjin data dunia.
Ia adalah komponen paling penting bagi Timbunan AI Umum/Sebenar, berinteraksi dengan enjin data dunia sebenar dan menyediakan fungsi/keupayaan pintar:
- Memproses maklumat tentang dunia
- Anggaran/kira/ketahui keadaan model dunia
- Umumkan elemen data, titik, set
- Nyatakan struktur dan jenis datanya
- Pindahkannya pembelajaran
- Kontekstualkan kandungannya
- Membentuk/menemui corak data kausal seperti corak kausal, peraturan dan keteraturan
- Simpulkan semua kemungkinan interaksi, sebab, kesan, kitaran, sistem dan sebab hubungan dalam rangkaian
- Jangka/kaji keadaan dunia pada skop dan skala yang berbeza dan pada tahap generalisasi dan spesifikasi yang berbeza
- Berinteraksi dengan, menyesuaikan diri dan mengemudi dunia dengan berkesan dan cekap Ia memanipulasi persekitarannya mengikut ramalan dan preskripsi pintarnya
Malah, ia terutamanya enjin penaakulan induktif statistik yang bergantung pada pengkomputeran data besar, inovasi algoritma dan teori pembelajaran statistik serta falsafah sambungan.
Bagi kebanyakan orang, ia hanya membina model pembelajaran mesin (ML) ringkas, melalui pengumpulan data, pengurusan, penerokaan, kejuruteraan ciri, latihan model, penilaian dan akhirnya penggunaan.
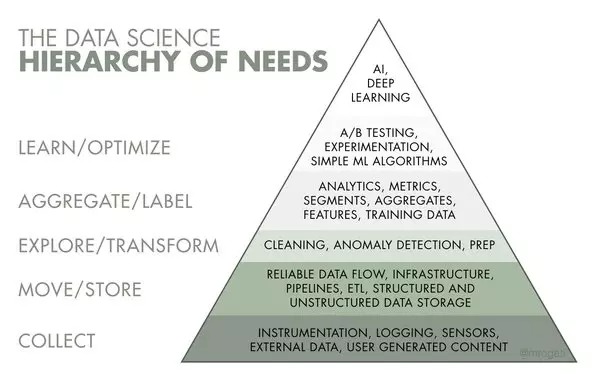
EDA: Analisis Data Penerokaan
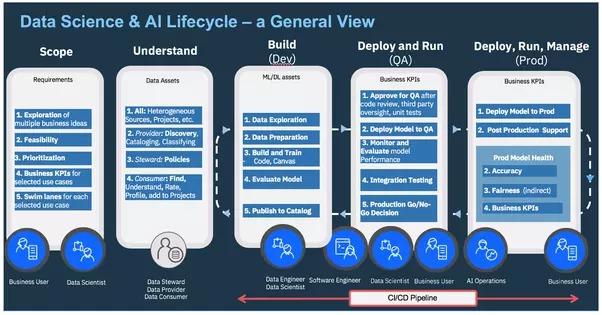
Ops AI — Menguruskan kitaran hayat hujung ke hujung AI
Keupayaan AI hari ini datang daripada "pembelajaran mesin," yang memerlukan konfigurasi dan penalaan algoritma untuk setiap senario dunia sebenar yang berbeza. Ini menjadikannya sangat manual dan memerlukan banyak masa untuk mengawasi perkembangannya. Proses manual ini juga mudah ralat, tidak cekap, dan sukar diurus. Belum lagi kekurangan kepakaran dalam dapat mengkonfigurasi dan menala pelbagai jenis algoritma.
Konfigurasi, pelarasan dan pemilihan model menjadi semakin automatik, dan semua syarikat teknologi utama seperti Google, Microsoft, Amazon dan IBM telah melancarkan platform AutoML yang serupa untuk mengautomasikan proses pembinaan model pembelajaran mesin.
AutoML melibatkan mengautomasikan tugas yang diperlukan untuk membina model ramalan berdasarkan algoritma pembelajaran mesin. Tugas-tugas ini termasuk pembersihan dan prapemprosesan data, kejuruteraan ciri, pemilihan ciri, pemilihan model dan penalaan hiperparameter, yang boleh membosankan untuk dilakukan secara manual.
SAS4485-2020.pdf
Saluran paip ML hujung ke hujung yang dibentangkan terdiri daripada 3 peringkat utama sambil kehilangan sumber semua data, dunia Itu sendiri:
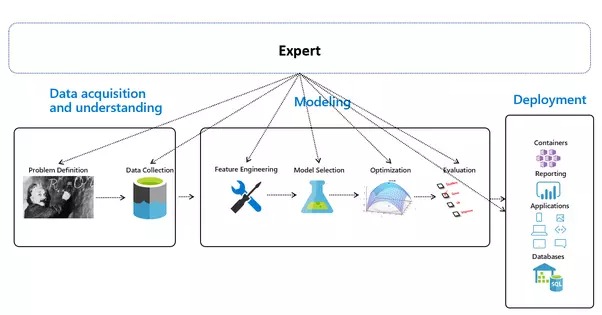
Pembelajaran Mesin Automatik - Gambaran Keseluruhan
Rahsia utama Big-Tech AI ialah Pembelajaran Mesin Mendalam Kulit sebagai rangkaian saraf dalam yang gelap, yang Model ini perlu dilatih dengan sejumlah besar data berlabel dan seni bina rangkaian saraf yang mengandungi seberapa banyak lapisan yang mungkin.
Setiap tugas memerlukan seni bina rangkaian khasnya:
- Rangkaian Neural Buatan (ANN) untuk regresi dan pengelasan
- Volume untuk penglihatan komputer Convolutional Neural Network (CNN)
- Rangkaian Neural Berulang (RNN) untuk analisis siri masa
- Peta penyusunan sendiri untuk pengekstrakan ciri
- Kedalaman untuk sistem pengesyor Mesin Boltzmann
- Pengekod Auto untuk Sistem Pengesyor
ANN diperkenalkan sebagai paradigma pemprosesan maklumat yang nampaknya diilhamkan oleh cara sistem saraf biologi/otak memproses maklumat . Dan rangkaian saraf tiruan tersebut diwakili sebagai "penghampir fungsi universal", yang boleh mempelajari/mengira pelbagai fungsi pengaktifan.
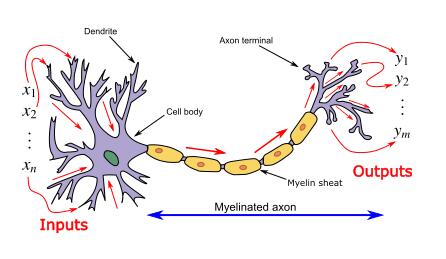
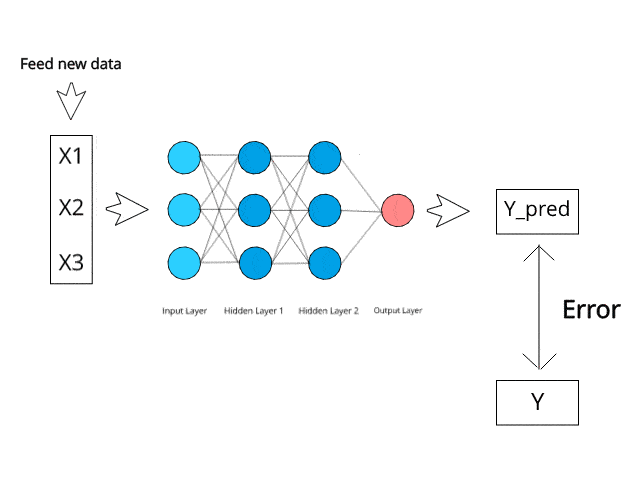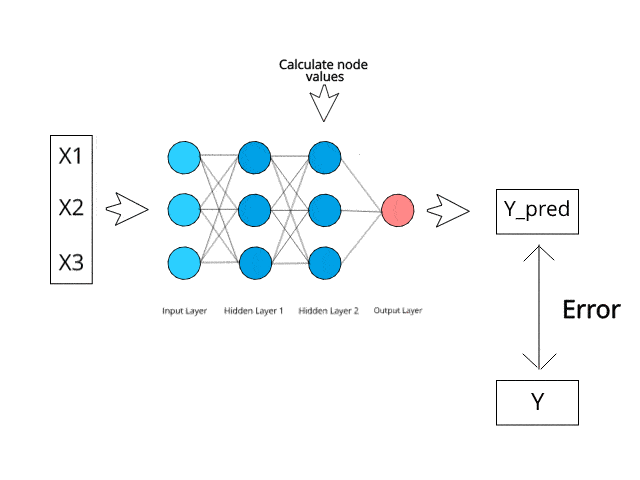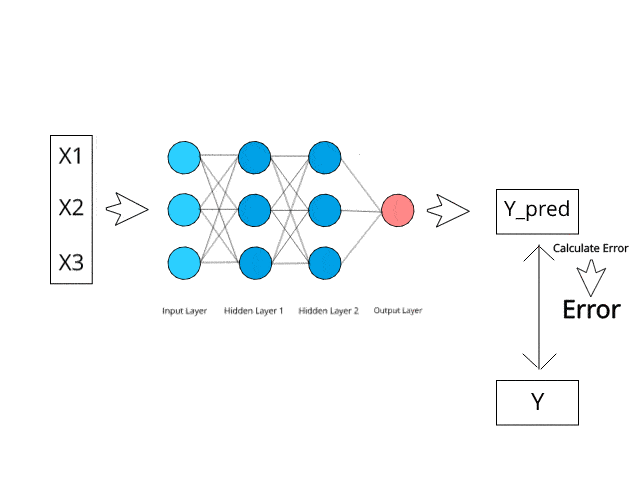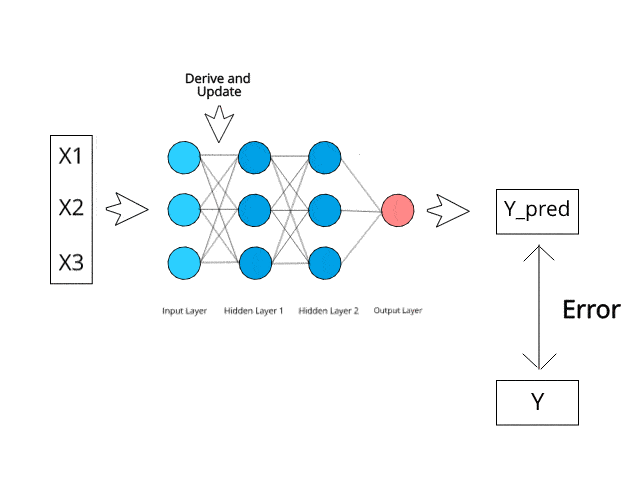
Rangkaian saraf mengira/belajar melalui perambatan belakang tertentu dan mekanisme pembetulan ralat semasa fasa ujian.
Bayangkan bahawa dengan meminimumkan ralat, sistem berbilang lapisan ini suatu hari nanti boleh belajar dan mengkonseptualisasikan idea sendiri.
Pengenalan kepada Rangkaian Neural Buatan (ANN)
Ringkasnya, beberapa baris kod R atau Python sudah cukup untuk melaksanakan kecerdasan mesin, dan terdapat banyak sumber dan tutorial dalam talian untuk latihan kuasi -rangkaian saraf, seperti pelbagai rangkaian Deep Forge, memanipulasi imej-video-teks audio dan tidak memahami dunia, seperti Generative Adversarial Networks, BigGAN, CycleGAN, StyleGAN, GauGAN, Artbreeder, DeOldify, dsb.
Mereka mencipta dan mengubah suai wajah, landskap, imej generik, dsb. dengan sifar pemahaman tentang perkara itu.
Menggunakan rangkaian lawan yang konsisten kitaran untuk terjemahan imej-ke-imej yang tidak berganding menjadikan 2019 era AI baharu untuk 14 penggunaan pembelajaran mendalam dan pembelajaran mesin.
Terdapat banyak alatan dan rangka kerja digital yang berfungsi dengan cara mereka sendiri:
- Bahasa terbuka - Python adalah yang paling popular, tetapi R dan Scala juga antaranya.
- Rangka kerja terbuka - Scikit-learn, XGBoost, TensorFlow, dsb.
- Kaedah dan teknik - teknik ML klasik daripada regresi kepada GAN dan RL yang canggih
- Keupayaan untuk meningkatkan produktiviti - pemodelan visual, AutoAI untuk membantu dengan kejuruteraan ciri, pemilihan algoritma dan Pengoptimuman hiperparameter
- Alat pembangunan - DataRobot, H2O, Watson Studio, Azure ML Studio, Sagemaker, Anaconda, dsb.
Memang memalukan bahawa saintis data bekerja dalam: scikit-learn, R, SparkML, Jupyter, R, Python, XGboost, Hadoop, Spark, TensorFlow, Keras, PyTorch, Docker, Plumbr. dan seterusnya.
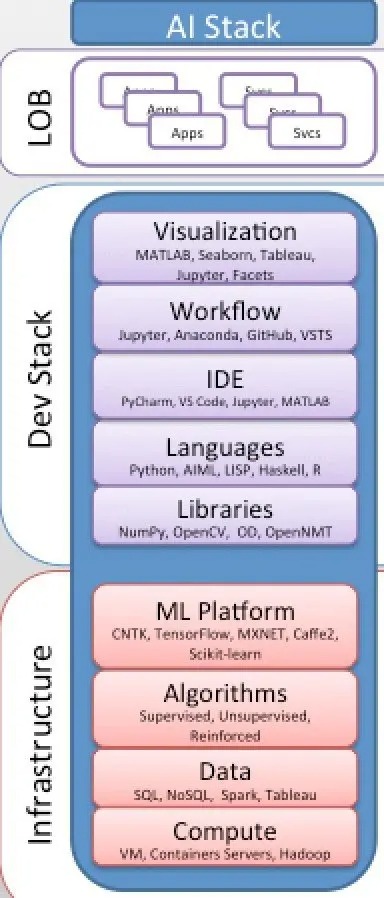
Timbunan AI moden dan model penggunaan AI-sebagai-perkhidmatan
Membina tindanan AI
Berpura-pura menjadi kecerdasan buatan, Sebenarnya, ia adalah kecerdasan buatan palsu. Yang terbaik ialah teknik pembelajaran automatik, pengecam corak ML/DL/NN, bersifat matematik dan statistik, tidak dapat bertindak secara intuitif atau memodelkan persekitarannya, dengan kecerdasan sifar, pembelajaran sifar dan pemahaman sifar.
Masalah yang menghalang kemajuan kecerdasan buatan
Walaupun banyak kelebihannya, kecerdasan buatan tidak sempurna. Berikut ialah 8 masalah dan kesilapan asas yang menghalang kemajuan kecerdasan buatan:
1 Kekurangan data
Kecerdasan buatan memerlukan set data yang besar untuk latihan, dan set data ini hendaklah inklusif/. tidak berat sebelah, dan kualitinya bagus. Kadang-kadang mereka perlu menunggu data baharu dijana.
2. Memakan masa
Kecerdasan buatan memerlukan masa yang cukup untuk algoritma untuk belajar dan membangunkan cukup untuk mencapai tujuannya dengan tahap ketepatan dan perkaitan yang agak tinggi. Ia juga memerlukan sumber yang besar untuk berfungsi. Ini mungkin bermakna keperluan tambahan pada kebolehan komputer anda.
3. Tafsiran keputusan yang lemah
Satu lagi cabaran utama ialah keupayaan untuk mentafsir keputusan yang dihasilkan oleh algoritma dengan tepat juga mesti dipilih dengan teliti mengikut tujuannya.
4. Sangat terdedah kepada ralat
Kecerdasan buatan adalah autonomi, tetapi sangat terdedah kepada ralat. Katakan algoritma dilatih pada set data yang cukup kecil untuk menjadikannya tidak inklusif. Anda berakhir dengan ramalan berat sebelah daripada set latihan berat sebelah. Dalam kes pembelajaran mesin, kesilapan langkah sedemikian boleh mencetuskan ralat yang tidak dapat dikesan untuk masa yang lama. Apabila mereka mendapat perhatian, ia boleh mengambil sedikit masa untuk mengenal pasti punca masalah, dan lebih lama untuk membetulkannya.
5. Isu Etika
Idea untuk mempercayai data dan algoritma berbanding pertimbangan kita sendiri mempunyai kelebihan dan kekurangannya. Jelas sekali, kami mendapat manfaat daripada algoritma ini, jika tidak, kami tidak akan menggunakannya sejak awal. Algoritma ini membolehkan kami mengautomasikan proses dengan membuat pertimbangan termaklum menggunakan data yang tersedia. Walau bagaimanapun, kadangkala ini bermakna menggantikan tugas seseorang dengan algoritma, yang mempunyai akibat etika. Tambahan pula, jika berlaku masalah, siapa yang harus kita salahkan?
6. Kekurangan sumber teknikal
Kecerdasan buatan masih merupakan teknologi yang agak baharu. Pakar pembelajaran mesin diperlukan untuk mengekalkan proses, daripada kod permulaan kepada penyelenggaraan dan pemantauan proses. Industri kecerdasan buatan dan pembelajaran mesin masih agak baharu dalam pasaran. Mencari sumber yang mencukupi dalam bentuk manusia juga sukar. Oleh itu, terdapat kekurangan wakil berbakat untuk membangunkan dan mengurus bahan saintifik pembelajaran mesin. Penyelidik data sering memerlukan gabungan cerapan spatial, serta pengetahuan matematik, teknikal dan saintifik dari awal hingga akhir.
7. Infrastruktur yang tidak mencukupi
Kecerdasan buatan memerlukan banyak keupayaan pemprosesan data. Rangka kerja warisan tidak dapat mengendalikan tanggungjawab dan kekangan di bawah tekanan. Infrastruktur harus diperiksa untuk melihat sama ada ia boleh menangani isu dalam AI Jika tidak, ia harus ditingkatkan sepenuhnya dengan perkakasan yang baik dan storan yang boleh disesuaikan.
8. Keputusan yang perlahan dan berat sebelah
Kecerdasan buatan sangat memakan masa. Disebabkan oleh data dan permintaan yang berlebihan, keputusan mengambil masa lebih lama daripada yang dijangkakan untuk dihantar. Memfokuskan pada ciri khusus dalam pangkalan data untuk menyamaratakan keputusan adalah perkara biasa dalam model pembelajaran mesin, yang boleh membawa kepada berat sebelah.
Kesimpulan
Kecerdasan buatan telah mengambil alih banyak aspek kehidupan kita. Walaupun tidak sempurna, kecerdasan buatan adalah bidang yang semakin berkembang dan mendapat permintaan tinggi. Ia memberikan hasil masa nyata menggunakan data sedia ada dan diproses tanpa campur tangan manusia. Ia membantu menganalisis dan menilai sejumlah besar data, selalunya dengan membangunkan model dipacu data. Walaupun terdapat banyak masalah dengan kecerdasan buatan, ia adalah bidang yang berkembang. Daripada diagnosis perubatan dan pembangunan vaksin kepada algoritma dagangan lanjutan, kecerdasan buatan telah menjadi kunci kepada kemajuan saintifik.
Atas ialah kandungan terperinci Lapan isu yang menghalang kemajuan kecerdasan buatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, Ketua Arkitek SonyinterActiveEntainment (SIE, Sony Interactive Entertainment), telah mengeluarkan lebih banyak butiran perkakasan dari PlayStation5Pro hos generasi akan datang (PS5Pro), termasuk GPU seni bina AMDRDNA2.x yang dinamakan, dan Kod Arsitektur AMDRDNA2.x yang dinamakan. Tumpuan peningkatan prestasi PS5Pro masih pada tiga tiang, termasuk GPU yang lebih kuat, jejak sinar maju dan fungsi resolusi super PSSR yang berkuasa AI. GPU mengamalkan seni bina AmdrDNA2 yang disesuaikan, yang Sony menamakan RDNA2.x, dan ia mempunyai beberapa seni bina RDNA3.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Akhirnya berubah! Fungsi carian Microsoft Windows akan membawa kemas kini baru
Apr 13, 2025 pm 11:42 PM
Akhirnya berubah! Fungsi carian Microsoft Windows akan membawa kemas kini baru
Apr 13, 2025 pm 11:42 PM
Penambahbaikan Microsoft ke fungsi carian Windows telah diuji pada beberapa saluran Windows Insider di EU. Sebelum ini, fungsi carian Windows bersepadu dikritik oleh pengguna dan mempunyai pengalaman yang buruk. Kemas kini ini membahagikan fungsi carian ke dalam dua bahagian: carian tempatan dan carian web berasaskan Bing untuk meningkatkan pengalaman pengguna. Versi baru antara muka carian melakukan carian fail tempatan secara lalai. Jika anda perlu mencari dalam talian, anda perlu mengklik tab "Microsoft Bingwebsearch" untuk menukar. Selepas bertukar, bar carian akan memaparkan "Microsoft Bingwebsearch:", di mana pengguna boleh memasukkan kata kunci. Langkah ini berkesan mengelakkan pencampuran hasil carian tempatan dengan hasil carian Bing
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
