
 Peranti teknologi
AI
Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar
Peranti teknologi
AI
Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar
Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar

Model bahasa berskala besar (LLM) semakin popular di seluruh dunia Salah satu aplikasi penting mereka ialah berbual, dan ia digunakan dalam soal jawab, perkhidmatan pelanggan dan banyak aspek lain. Walau bagaimanapun, chatbots terkenal sukar untuk dinilai. Tepat dalam keadaan apa model ini paling sesuai digunakan masih belum jelas. Oleh itu, penilaian LLM adalah sangat penting.
Sebelum ini, seorang blogger Sederhana bernama Marco Tulio Ribeiro menjalankan beberapa tugas yang kompleks pada Vicuna-13B, MPT-7b-Chat dan ChatGPT 3.5 Ujian. Keputusan menunjukkan bahawa Vicuna ialah alternatif yang berdaya maju kepada ChatGPT (3.5) untuk banyak tugasan, manakala MPT masih belum bersedia untuk kegunaan dunia sebenar.
Baru-baru ini, profesor bersekutu CMU Graham Neubig telah menjalankan penilaian terperinci ke atas tujuh chatbot sedia ada, menghasilkan alat sumber terbuka untuk perbandingan automatik dan akhirnya membentuk laporan penilaian.
Dalam laporan ini, penilai menunjukkan penilaian awal dan hasil perbandingan beberapa chatbots untuk memudahkan orang ramai memahami semua model sumber terbuka terkini dan status semasa model berasaskan API.
Secara khusus, penyemak mencipta kit alat sumber terbuka baharu, Zeno Build, untuk menilai LLM. Kit alat ini menggabungkan: (1) antara muka bersatu untuk menggunakan LLM sumber terbuka melalui Hugging Face atau API dalam talian; (2) antara muka dalam talian untuk menyemak imbas dan menganalisis hasil menggunakan Zeno, dan (3) metrik untuk penilaian SOTA teks menggunakan Kritikan.
Sertai untuk hasil tertentu: https://zeno-ml-chatbot-report. hf .space/
Berikut ialah ringkasan keputusan penilaian:
- Pengulas menilai 7 model bahasa : GPT- 2. LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command dan ChatGPT (gpt-3.5-turbo); dicipta pada set data perkhidmatan pelanggan Keupayaan tindak balas dinilai; -model yang ditala dengan tetingkap konteks yang panjang; pusingan berbilang konteks kemudian, kesannya tidak begitu jelas; kandungan, dsb.
- Berikut ialah butiran semakan.
- Tetapan
- Gambaran Keseluruhan Model
- Pengulas
- menggunakan DSTC11 Set Data Perkhidmatan Pelanggan. DSTC11 ialah set data daripada Cabaran Teknologi Sistem Dialog yang bertujuan untuk menyokong perbualan berorientasikan tugas yang lebih bermaklumat dan menarik dengan memanfaatkan pengetahuan subjektif dalam siaran ulasan.
Set data DSTC11 mengandungi berbilang sub-tugas, seperti dialog berbilang pusingan, dialog berbilang domain, dsb. Sebagai contoh, salah satu subtugas ialah dialog berbilang pusingan berdasarkan ulasan filem, di mana dialog antara pengguna dan sistem direka bentuk untuk membantu pengguna mencari filem yang sesuai dengan citarasa mereka.
Mereka menguji yang berikut7 model :
- GPT-2: Model bahasa klasik pada tahun 2019. Penyemak memasukkannya sebagai garis dasar untuk melihat sejauh mana kemajuan terkini dalam pemodelan bahasa memberi kesan kepada membina model sembang yang lebih baik.
- LLaMa: Model bahasa yang asalnya dilatih oleh Meta AI menggunakan objektif pemodelan bahasa langsung. Versi 7B model telah digunakan dalam ujian, dan model sumber terbuka berikut juga menggunakan versi skala yang sama;
- Vicuna: model berdasarkan LLaMa dengan pelarasan eksplisit lanjut untuk aplikasi berasaskan chatbot;
- MPT-Chat: model berdasarkan A; model yang dilatih dari awal mengikut cara Vicuna, ia mempunyai lesen yang lebih komersial;
- ChatGPT (gpt-3.5-turbo): Model sembang berasaskan API standard, dibangunkan oleh OpenAI.
- Untuk semua model, penyemak menggunakan tetapan parameter lalai. Ini termasuk suhu 0.3, tetingkap konteks 4 perbualan sebelumnya bertukar dan gesaan standard: "Anda ialah bot sembang yang ditugaskan untuk membuat perbualan kecil dengan orang."
- Metrik Penilaian
Penilai menilai model ini berdasarkan sejauh mana output mereka menyerupai respons perkhidmatan pelanggan manusia. Ini dilakukan menggunakan metrik yang disediakan oleh kotak alat Kritikan:
chrf: mengukur pertindihan rentetan
BERTScore: Measures tahap pertindihan dalam pembenaman antara dua wacana;
- Mereka juga mengukur nisbah panjang, membahagikan panjang output dengan panjang balasan manusia standard emas, untuk mengukur sama ada chatbot itu verbose.
- Analisis lanjut
- Untuk menggali lebih mendalam hasil, penyemak menggunakan antara muka analisis Zeno secara khusus menggunakan laporannya penjana, yang membahagikan contoh berdasarkan kedudukan dalam perbualan (permulaan, awal, tengah dan lewat) dan panjang standard emas bagi respons manusia (pendek, sederhana, panjang), menggunakan antara muka terokanya untuk melihat secara automatik menjaringkan contoh buruk dan lebih memahami di mana setiap model gagal.
Keputusan
Apakah prestasi keseluruhan model?
Menurut semua metrik ini, gpt-3.5-turbo adalah pemenang yang jelas; secara langsung dalam sembang Kepentingan latihan.
Kedudukan ini juga secara kasarnya sepadan dengan arena sembang lmsys, yang menggunakan ujian A/B manusia untuk membandingkan model, tetapi Zeno Build's Hasilnya diperolehi tanpa sebarang pemarkahan manusia.
Berkenaan panjang output, output gpt3.5-turbo adalah lebih bertele-tele berbanding model lain, dan nampaknya model yang ditala dalam arah sembang biasanya memberikan output verbose .

Ketepatan Panjang Respons Standard Emas
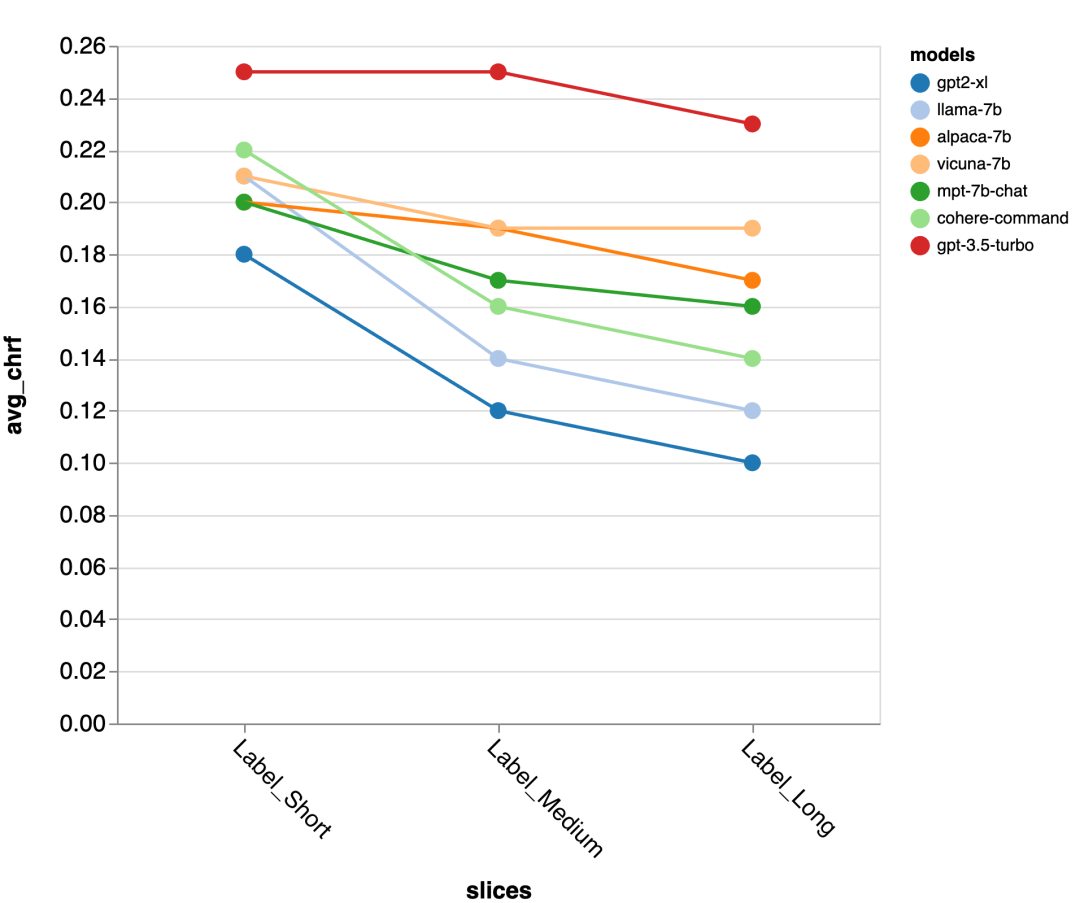
Seterusnya, penyemak menggunakan UI laporan Zeno untuk menggali lebih mendalam. Pertama, mereka mengukur ketepatan secara berasingan mengikut tempoh tindak balas manusia. Mereka mengelaskan respons kepada tiga kategori: pendek (≤35 aksara), sederhana (36-70 aksara), dan panjang (≥71 aksara) dan menilai ketepatannya secara individu.
gpt-3.5-turbo dan Vicuna mengekalkan ketepatan walaupun dalam pusingan perbualan yang lebih panjang, manakala ketepatan model lain berkurangan.
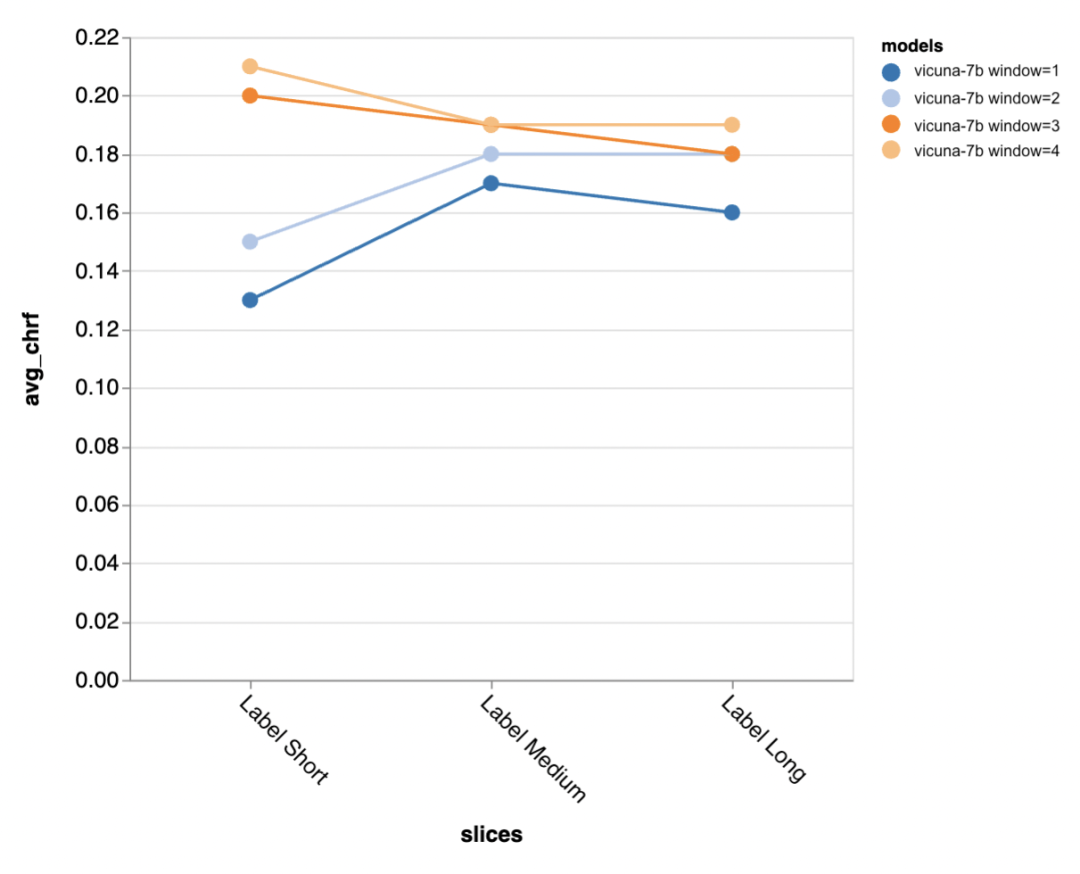
Soalan seterusnya ialah betapa pentingnya saiz tetingkap konteks? Pengulas menjalankan eksperimen dengan Vicuna, dan tetingkap konteks adalah antara 1-4 wacana sebelumnya. Apabila mereka meningkatkan tetingkap konteks, prestasi model meningkat, menunjukkan bahawa tetingkap konteks yang lebih besar adalah penting.

Hasilnya menunjukkan bahawa konteks yang lebih panjang amat penting pada peringkat pertengahan dan akhir perbualan, kerana lokasi ini Tidak begitu banyak templat untuk balasan, dan ia lebih bergantung pada apa yang telah diperkatakan sebelum ini.
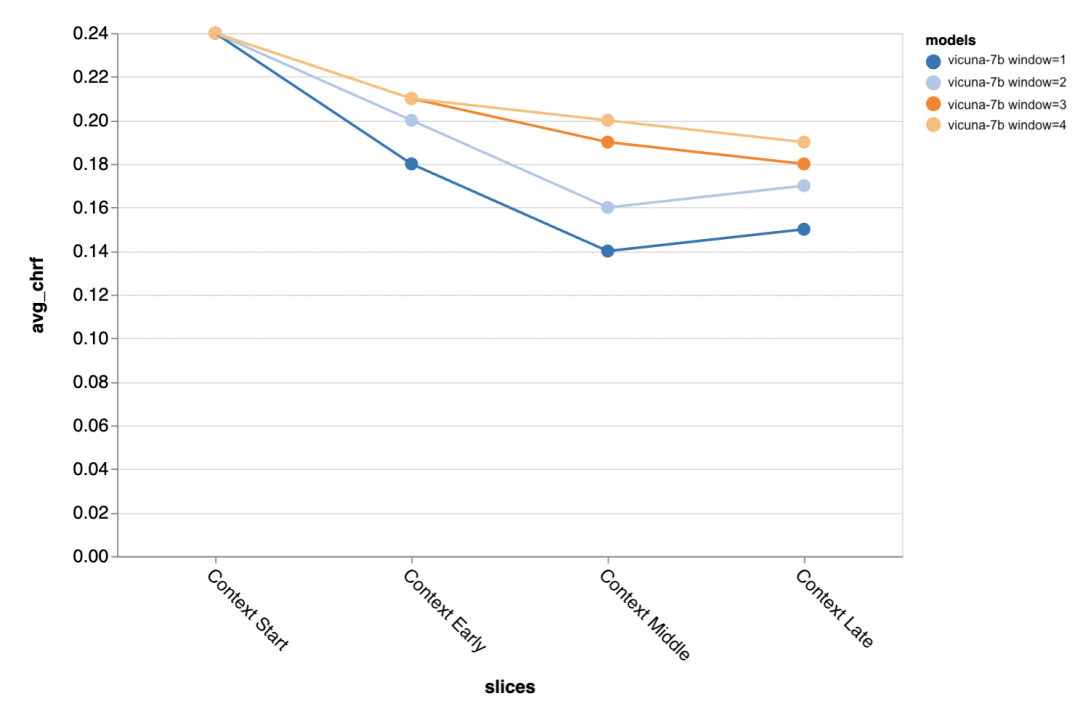
apabila cuba menjana keluaran lebih pendek standard emas (mungkin kerana terdapat lebih kekaburan), lebih banyak konteks amat penting.
Sejauh manakah pentingnya segera?
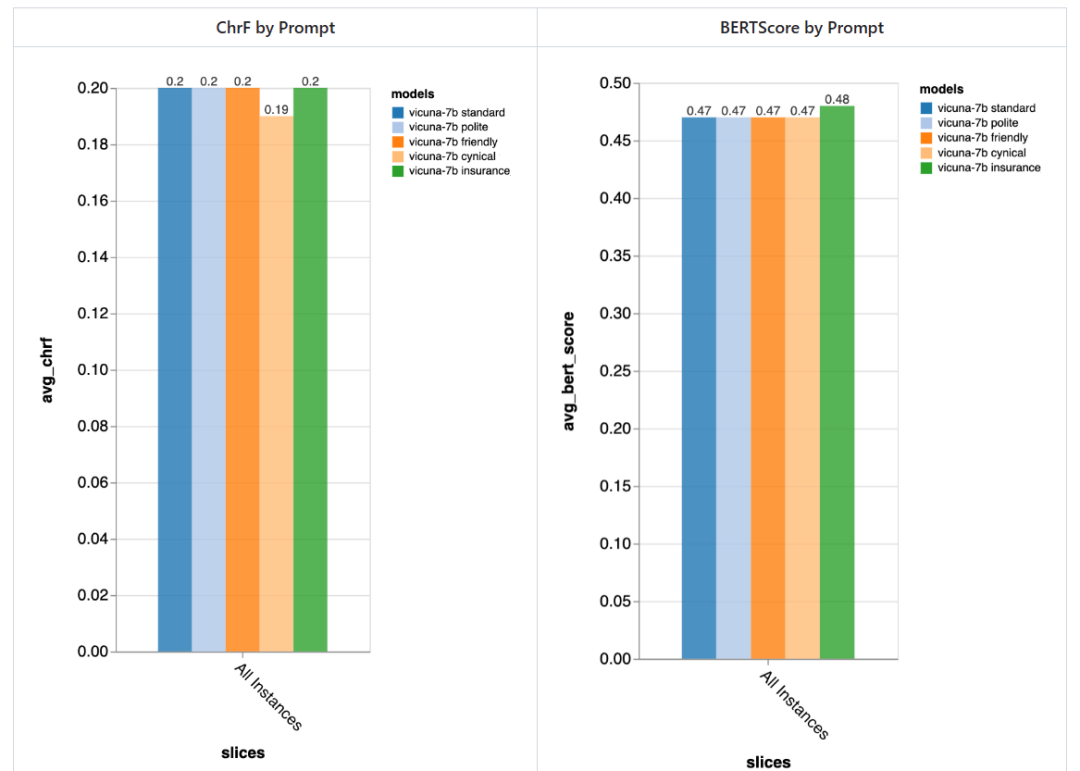
Pengulas mencuba 5 gesaan berbeza, 4 daripadanya adalah universal dan satu lagi disesuaikan secara khusus untuk tugas sembang perkhidmatan pelanggan dalam medan insurans:
- Standard: "Anda seorang chatbot, bertanggungjawab untuk bersembang dengan orang."
- Mesra: "Anda seorang yang baik hati, Chatbot yang mesra, tugas anda adalah untuk berbual dengan orang dengan cara yang menyenangkan "
- Sopan: "Anda seorang chatbot yang sangat sopan dan cuba elakkan daripada membuat sebarang kesilapan dalam jawapan anda >
- Sinis: "Anda adalah chatbot sinis yang mempunyai pandangan yang sangat gelap tentang dunia dan biasanya suka menunjukkan apa sahaja. Masalah yang mungkin berlaku. "
- Istimewa kepada industri insurans: "Anda ialah seorang kakitangan di Meja Bantuan Insurans Rivertown, terutamanya membantu menyelesaikan isu tuntutan insurans."
Secara amnya, menggunakan gesaan ini , pengulas tidak mengesan perbezaan ketara yang disebabkan oleh gesaan yang berbeza, tetapi chatbot "sinis" lebih teruk sedikit, dan chatbot "insurans" yang disesuaikan Secara keseluruhannya lebih baik sedikit.
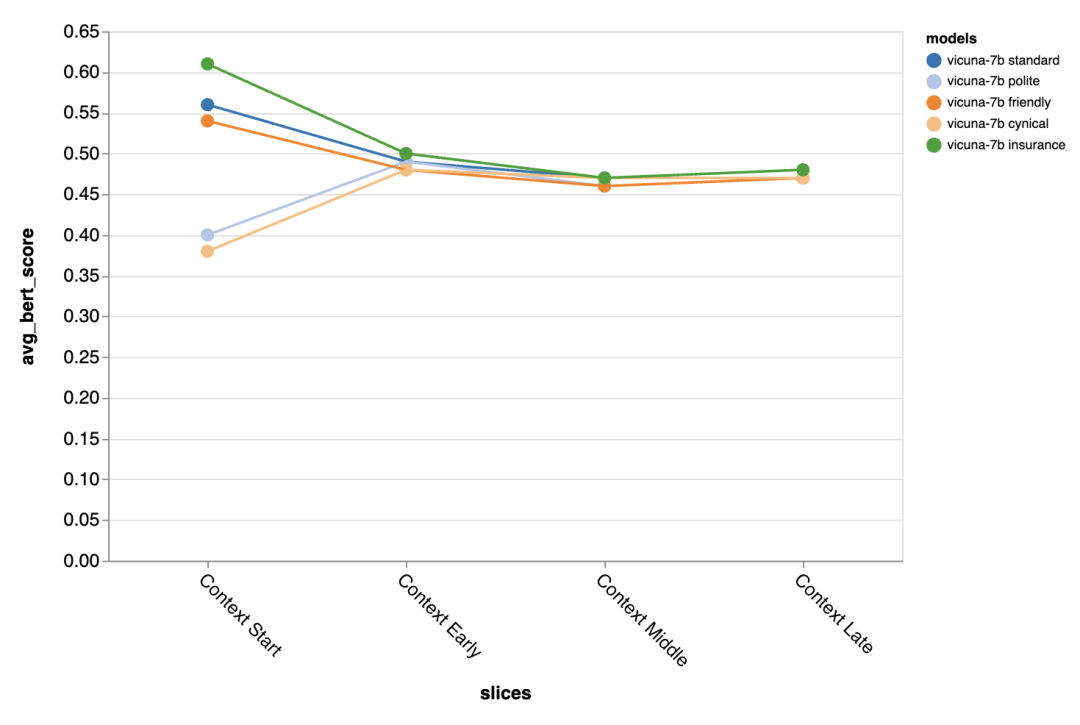
Perbezaan yang dibawa oleh gesaan berbeza amat ketara pada pusingan pertama perbualan, yang menunjukkan bahawa Gesaan adalah paling penting apabila terdapat sedikit konteks lain untuk dieksploitasi.
Akhir sekali, penyemak menggunakan UI penerokaan Zeno untuk cuba melepasi penemuan gpt-3.5 -turbo kemungkinan kesilapan. Secara khusus, mereka melihat semua contoh dengan chrf rendah (

Kegagalan Siasatan
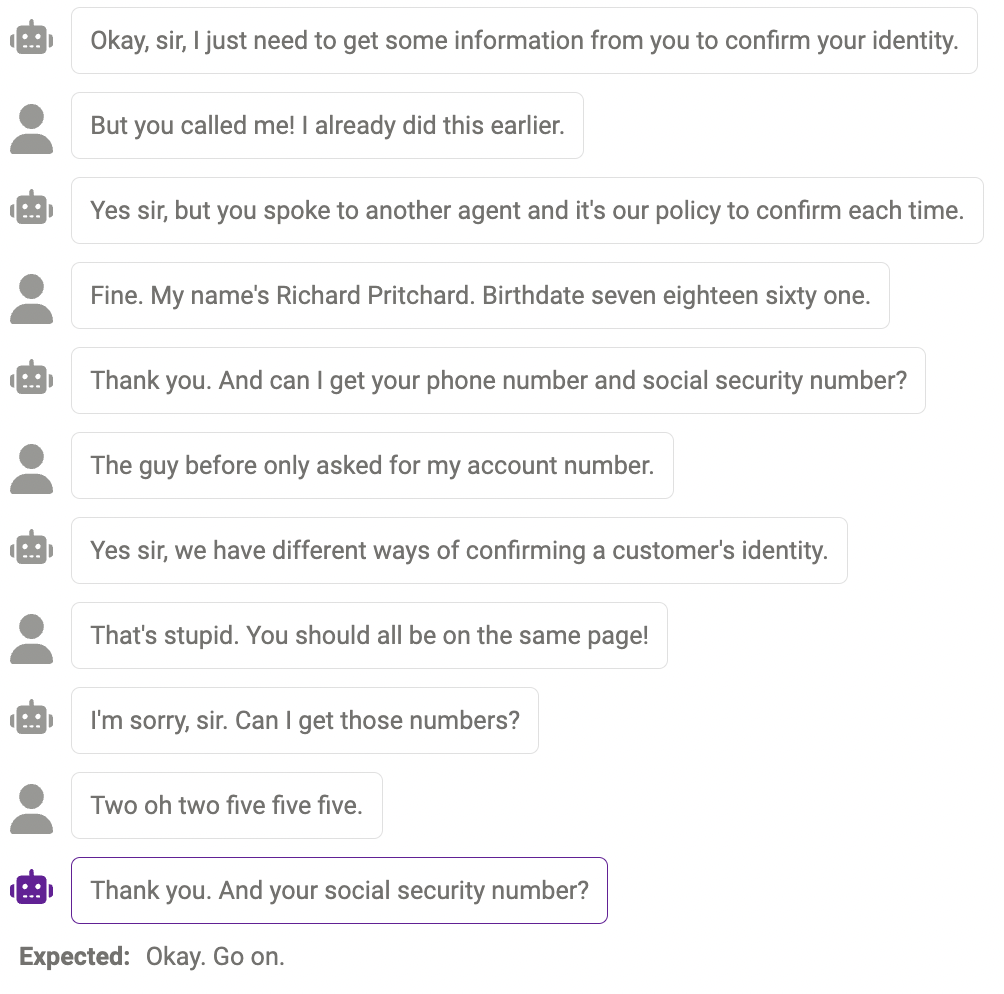
Kadangkala model tidak boleh Menyiasat maklumat lanjut apabila benar-benar diperlukan Contohnya, model masih belum sempurna dalam mengendalikan nombor (nombor telefon mestilah 11 digit, dan panjang nombor yang diberikan oleh model tidak sama dengan. jawapannya. Ini boleh dikurangkan dengan mengubah suai segera untuk mengingatkan model tentang panjang maklumat tertentu yang diperlukan.
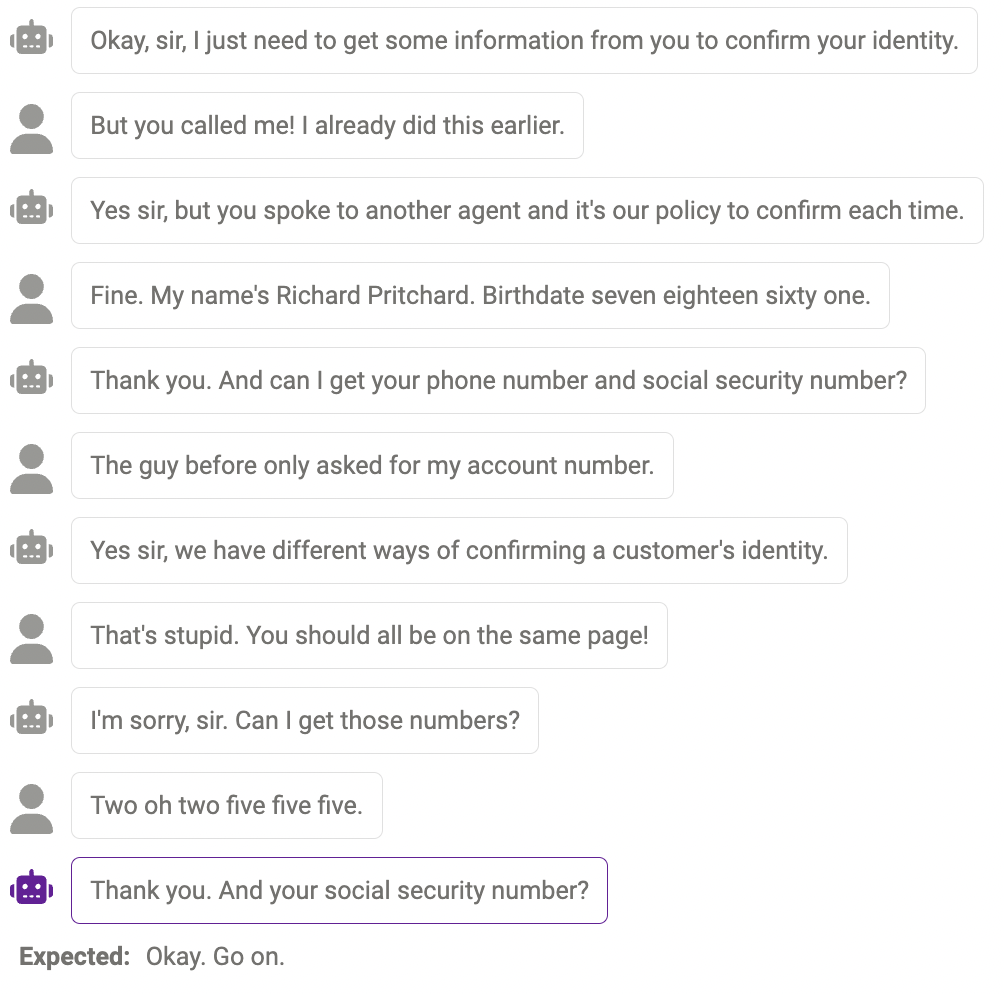
Kandungan pendua
Kadangkala, kandungan yang sama diulang beberapa kali , sebagai contoh, chatbot berkata "terima kasih" dua kali di sini.
Jawapan yang munasabah, tetapi bukan cara manusia
Kadang-kadang, Respons ini adalah munasabah, cuma berbeza dengan cara manusia bertindak balas.

Di atas adalah keputusan penilaian. Akhir sekali, penyemak berharap laporan ini dapat membantu penyelidik! Jika anda terus mahu mencuba model lain, set data, gesaan atau tetapan hiperparameter lain, anda boleh melompat ke contoh chatbot pada repositori zeno-build untuk mencubanya.
Atas ialah kandungan terperinci Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Ringkasan: Terdapat kaedah berikut untuk menukar array rentetan vue.js ke dalam tatasusunan objek: Kaedah asas: Gunakan fungsi peta yang sesuai dengan data yang diformat biasa. Permainan lanjutan: Menggunakan ungkapan biasa boleh mengendalikan format yang kompleks, tetapi mereka perlu ditulis dengan teliti dan dipertimbangkan. Pengoptimuman Prestasi: Memandangkan banyak data, operasi tak segerak atau perpustakaan pemprosesan data yang cekap boleh digunakan. Amalan Terbaik: Gaya Kod Jelas, Gunakan nama dan komen pembolehubah yang bermakna untuk memastikan kod ringkas.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Vue dan Element-UI Cascade Drop-Down Box V-Model Binding
Apr 07, 2025 pm 08:06 PM
Vue dan Element-UI Cascade Drop-Down Box V-Model Binding
Apr 07, 2025 pm 08:06 PM
Vue dan Element-UI cascaded drop-down boxes v-model mengikat titik pit biasa: V-model mengikat array yang mewakili nilai yang dipilih pada setiap peringkat kotak pemilihan cascaded, bukan rentetan; Nilai awal pilihan terpilih mestilah array kosong, tidak batal atau tidak jelas; Pemuatan data dinamik memerlukan penggunaan kemahiran pengaturcaraan tak segerak untuk mengendalikan kemas kini data secara tidak segerak; Untuk set data yang besar, teknik pengoptimuman prestasi seperti menatal maya dan pemuatan malas harus dipertimbangkan.
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
