
 Peranti teknologi
AI
Pembahagian video akhir! Universiti Zhejiang baru-baru ini mengeluarkan SAM-Track: pembahagian video pintar universal dengan satu klik
Peranti teknologi
AI
Pembahagian video akhir! Universiti Zhejiang baru-baru ini mengeluarkan SAM-Track: pembahagian video pintar universal dengan satu klik
Pembahagian video akhir! Universiti Zhejiang baru-baru ini mengeluarkan SAM-Track: pembahagian video pintar universal dengan satu klik

Baru-baru ini, Makmal ReLER Universiti Zhejiang menggabungkan SAM secara mendalam dengan pembahagian video dan mengeluarkan Segmen-dan-Jejak Apa-apa (SAM-Track).
SAM-Track memberi SAM keupayaan untuk menjejak sasaran video dan menyokong pelbagai cara interaksi (titik, berus, teks).
Atas dasar ini, SAM-Track menyatukan berbilang tugas pembahagian video tradisional, mencapai penjejakan segmentasi satu klik bagi mana-mana sasaran dalam mana-mana video dan mengekstrapolasi pembahagian video tradisional kepada pembahagian Video universal.
SAM-Track mempunyai prestasi cemerlang dan stabil boleh menjejaki ratusan sasaran dengan kualiti tinggi dalam senario kompleks dengan hanya satu kad.

Alamat projek: https://github.com/z-x-yang/Segment-and-Track -Apa-apa sahaja
Alamat kertas: https://arxiv.org/abs/2305.06558
Paparan kesan
SAM-Track menyokong input bahasa sebagai Prompt. Contohnya, memandangkan teks kategori "Panda", pembahagian peringkat contoh satu klik boleh digunakan untuk menjejak semua sasaran yang tergolong dalam kategori "Panda".

Anda juga boleh memberikan penerangan yang lebih terperinci, seperti memasukkan teks "Panda paling kiri", SAM-Track Anda boleh mencari sasaran khusus untuk penjejakan pembahagian.

Berbanding dengan algoritma penjejakan video tradisional, satu lagi ciri hebat SAM-Track ialah ia boleh menyasarkan sejumlah besar sasaran secara serentak Laksanakan segmentasi penjejakan dan secara automatik mengesan objek yang muncul.

SAM-Track juga menyokong gabungan pelbagai kaedah interaksi dan pengguna boleh memadankannya mengikut keperluan sebenar. Contohnya, gunakan berus untuk membingkai papan selaju yang bersambung rapat dengan badan manusia untuk mengelakkan pembahagian objek berlebihan, dan kemudian gunakan klik untuk memilih badan manusia.
Pengsegmenan dan penjejakan sasaran video automatik sepenuhnya secara semula jadi adalah mudah Pelbagai senario aplikasi termasuk paparan jalanan, fotografi udara, AR, animasi, imej perubatan, dsb., yang kesemuanya boleh dibahagikan. dan dikesan secara automatik dengan satu klik Kesan objek yang muncul.

Jika anda tidak berpuas hati dengan keputusan pembahagian automatik, pengguna boleh membuat pengeditan dan pembetulan atas dasar ini, seperti seperti menggunakan klik untuk membetulkannya.

Pada masa yang sama, versi terkini SAM-Track menyokong penyemakan imbas dalam talian hasil penjejakan dan anda boleh memilih untuk membelah mana-mana bingkai di tengah Akibatnya, ubah suai dan tambah matlamat, dan jejak semula.

Untuk memudahkan pengalaman dalam talian pengguna, projek ini menyediakan WebUI, yang boleh digunakan dengan satu klik melalui Colab:
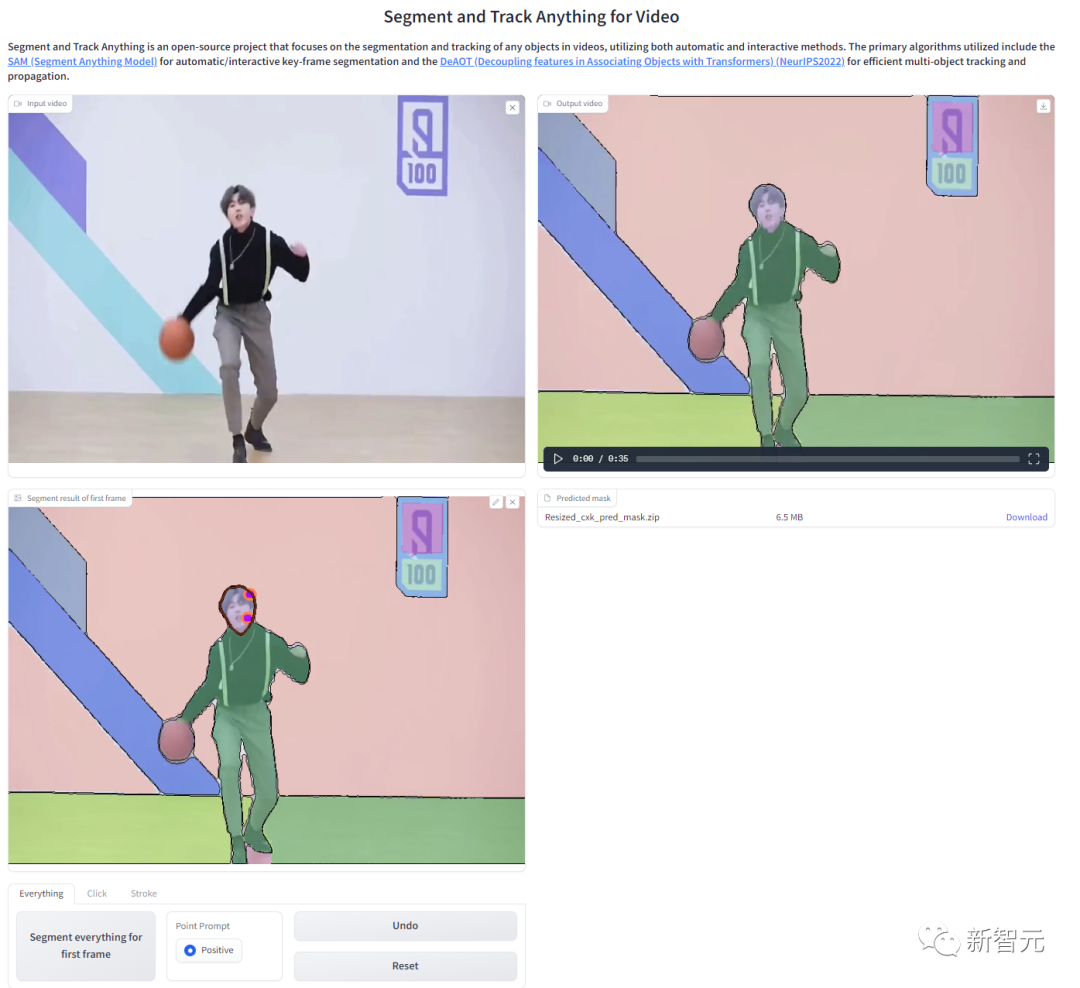
Komposisi model
Model SAM-Track adalah berdasarkan DeAOT, skim kejuaraan bagi empat trek Bengkel ECCV'22 VOT.
DeAOT ialah model VOS berbilang objektif yang cekap Memandangkan anotasi objek bingkai pertama, ia boleh menjejak dan membahagikan objek dalam baki bingkai video.
DeAOT menggunakan mekanisme pengecaman untuk membenamkan berbilang sasaran dalam video ke dalam ruang dimensi tinggi yang sama, dengan itu mencapai penjejakan serentak berbilang objek.
Prestasi kelajuan DeAOT dalam penjejakan berbilang objek adalah setanding dengan kaedah VOS lain untuk penjejakan objek tunggal.
Selain itu, melalui mekanisme perambatan berasaskan Transformer berlapis, DeAOT mengagregatkan maklumat jangka panjang dan jangka pendek dengan lebih baik, menunjukkan prestasi penjejakan yang sangat baik.
Memandangkan DeAOT memerlukan anotasi bingkai rujukan untuk dimulakan, untuk meningkatkan kemudahan, SAM-Track menggunakan model Segment Anything Model (SAM) yang baru-baru ini bersinar dalam bidang pembahagian imej untuk mendapatkan maklumat Label.
Menggunakan keupayaan migrasi sifar sampel yang sangat baik dan kaedah interaksi berbilang SAM, SAM-Track boleh mendapatkan maklumat anotasi bingkai rujukan berkualiti tinggi untuk DeAOT dengan cekap.
Walaupun model SAM berprestasi baik dalam bidang pembahagian imej, ia tidak dapat mengeluarkan label semantik dan pembayang teks tidak dapat menyokong Pembahagian Objek Merujuk dan tugas lain yang bergantung pada pemahaman semantik yang mendalam.
Oleh itu, model SAM-Track menyepadukan lagi Grounding-DINO untuk mencapai pembahagian video berpandukan bahasa berketepatan tinggi. Grounding DINO ialah model pengesanan objek set terbuka dengan keupayaan pemahaman bahasa yang baik.
Berdasarkan kategori input atau penerangan terperinci objek sasaran, Grounding-DINO boleh mengesan sasaran dan mengembalikan kotak lokasi.
Seni bina model SAM-Track
Seperti yang ditunjukkan dalam rajah di bawah, model SAM-Track menyokong tiga mod penjejakan objek, iaitu mod penjejakan interaktif, mod penjejakan automatik dan Mod gabungan.
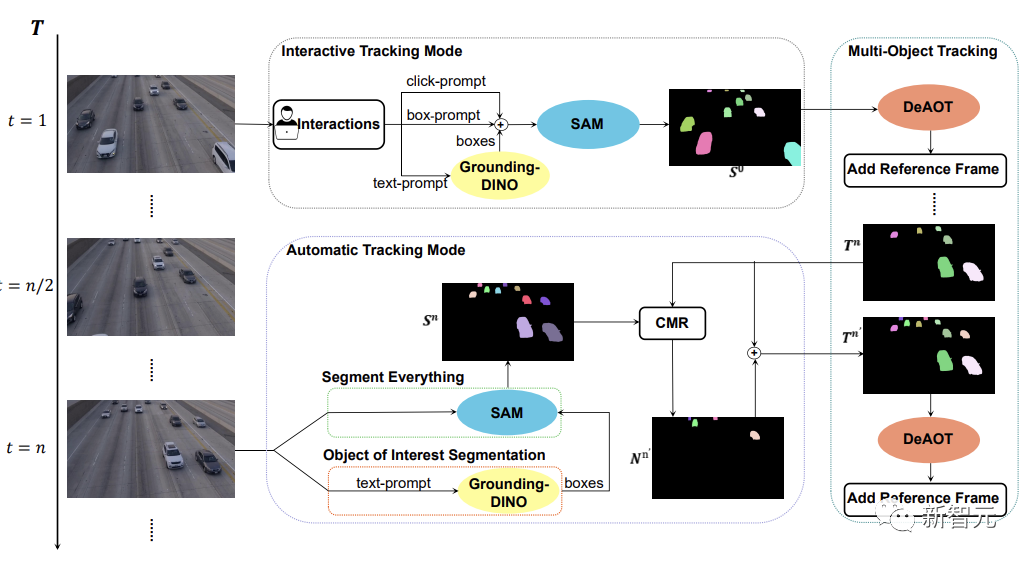
Untuk mod penjejakan interaktif, model SAM-Track terlebih dahulu menggunakan SAM, menggunakan klik atau bingkai dalam bingkai rujukan Pilih sasaran dengan cara ini sehingga hasil segmentasi interaktif yang memuaskan hati pengguna diperolehi.
Jika anda ingin melaksanakan pembahagian objek video berpandukan bahasa, SAM-Track akan memanggil Grounding-DINO terlebih dahulu untuk mendapatkan bingkai kedudukan objek sasaran berdasarkan teks input dan berdasarkan mengenai ini Dapatkan keputusan segmentasi objek yang diminati melalui SAM.
Akhir sekali, DeAOT menggunakan hasil pembahagian interaktif sebagai bingkai rujukan untuk menjejaki sasaran yang dipilih. Semasa proses penjejakan, DeAOT akan menyebarkan secara hierarki pembenaman visual dan pembenaman ID berdimensi tinggi dalam bingkai lalu kepada bingkai semasa untuk mencapai penjejakan bingkai demi bingkai dan pembahagian berbilang objek sasaran. Oleh itu, SAM-Track boleh menjejak objek yang diminati dalam video tersegmen dengan menyokong interaksi berbilang modal.
Walau bagaimanapun, mod penjejakan interaktif tidak dapat mengendalikan objek yang baru muncul yang muncul dalam video. Mengehadkan penggunaan SAM-Track dalam bidang tertentu, seperti pemanduan autonomi, bandar pintar, dsb.
Untuk mengembangkan lagi skop aplikasi dan prestasi SAM-Track, SAM-Track melaksanakan mod penjejakan automatik untuk menjejak objek baharu yang muncul dalam video.
Mod penjejakan automatik menggunakan Segment Everything dan Object of Interest Segmentation untuk mendapatkan anotasi objek baharu yang muncul dalam setiap n bingkai. Untuk masalah penetapan ID objek yang baru muncul, SAM-Track menggunakan modul topeng perbandingan (CMR) untuk menentukan ID objek baharu.
Mod gabungan menggabungkan mod penjejakan interaktif dan mod penjejakan automatik. Mod penjejakan interaktif membolehkan pengguna mendapatkan anotasi dengan mudah untuk bingkai pertama video, manakala mod penjejakan automatik mengendalikan objek baharu yang tidak dipilih yang muncul dalam bingkai video berikutnya. Gabungan kaedah penjejakan mengembangkan skop aplikasi SAM-Track dan meningkatkan kepraktisan SAM-Track.
Atas ialah kandungan terperinci Pembahagian video akhir! Universiti Zhejiang baru-baru ini mengeluarkan SAM-Track: pembahagian video pintar universal dengan satu klik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Di manakah fail video disimpan dalam cache penyemak imbas?
Feb 19, 2024 pm 05:09 PM
Di manakah fail video disimpan dalam cache penyemak imbas?
Feb 19, 2024 pm 05:09 PM
Dalam folder manakah penyemak imbas menyimpan video tersebut Apabila kita menggunakan pelayar Internet setiap hari, kita sering menonton pelbagai video dalam talian, seperti menonton video muzik di YouTube atau menonton filem di Netflix. Video ini akan dicache oleh penyemak imbas semasa proses pemuatan supaya ia boleh dimuatkan dengan cepat apabila dimainkan semula pada masa hadapan. Jadi persoalannya, dalam folder manakah video yang dicache ini sebenarnya disimpan? Pelayar yang berbeza menyimpan folder video cache di lokasi yang berbeza. Di bawah ini kami akan memperkenalkan beberapa pelayar biasa dan mereka
 Adakah ia melanggar untuk menyiarkan video orang lain di Douyin? Bagaimanakah ia mengedit video tanpa pelanggaran?
Mar 21, 2024 pm 05:57 PM
Adakah ia melanggar untuk menyiarkan video orang lain di Douyin? Bagaimanakah ia mengedit video tanpa pelanggaran?
Mar 21, 2024 pm 05:57 PM
Dengan peningkatan platform video pendek, Douyin telah menjadi bahagian yang sangat diperlukan dalam kehidupan seharian setiap orang. Di TikTok, kita boleh melihat video menarik dari seluruh dunia. Sesetengah orang suka menyiarkan video orang lain, yang menimbulkan persoalan: Adakah Douyin melanggar apabila menyiarkan video orang lain? Artikel ini akan membincangkan isu ini dan memberitahu anda cara mengedit video tanpa pelanggaran dan cara mengelakkan isu pelanggaran. 1. Adakah ia melanggar penyiaran video orang lain oleh Douyin? Menurut peruntukan Undang-undang Hak Cipta negara saya, penggunaan tanpa kebenaran karya pemilik hak cipta tanpa kebenaran pemilik hak cipta adalah satu pelanggaran. Oleh itu, menyiarkan video orang lain di Douyin tanpa kebenaran pengarang asal atau pemilik hak cipta adalah satu pelanggaran. 2. Bagaimana untuk mengedit video tanpa pelanggaran? 1. Penggunaan domain awam atau kandungan berlesen: Awam
 Bagaimana untuk membuang tera air video dalam Wink
Feb 23, 2024 pm 07:22 PM
Bagaimana untuk membuang tera air video dalam Wink
Feb 23, 2024 pm 07:22 PM
Bagaimana untuk membuang tera air daripada video dalam Wink? Terdapat alat untuk membuang tera air daripada video dalam winkAPP, tetapi kebanyakan rakan tidak tahu bagaimana untuk membuang tera air daripada video dalam Wink dibawa oleh editor Teks tutorial, pengguna yang berminat datang dan lihat! Cara membuang tera air video dalam Wink 1. Buka APP wink dahulu dan pilih fungsi [Remove Watermark] di kawasan halaman utama 2. Kemudian pilih video yang ingin anda keluarkan watermark dalam album 3. Kemudian pilih video dan klik sudut kanan atas selepas mengedit video [√];4 Akhir sekali, klik [Pencetakan satu klik] seperti yang ditunjukkan dalam rajah di bawah dan kemudian klik [Proses].
 Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Bagaimanakah seorang pemula boleh membuat wang di Douyin?
Mar 21, 2024 pm 08:17 PM
Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Bagaimanakah seorang pemula boleh membuat wang di Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, platform video pendek kebangsaan, bukan sahaja membolehkan kami menikmati pelbagai video pendek yang menarik dan novel pada masa lapang kami, tetapi juga memberi kami pentas untuk menunjukkan diri kami dan merealisasikan nilai kami. Jadi, bagaimana untuk membuat wang dengan menyiarkan video di Douyin? Artikel ini akan menjawab soalan ini secara terperinci dan membantu anda menjana lebih banyak wang di TikTok. 1. Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Selepas menyiarkan video dan mendapat jumlah tontonan tertentu pada Douyin, anda akan berpeluang untuk mengambil bahagian dalam pelan perkongsian pengiklanan. Kaedah pendapatan ini adalah salah satu yang paling biasa kepada pengguna Douyin dan juga merupakan sumber pendapatan utama bagi banyak pencipta. Douyin memutuskan sama ada untuk menyediakan peluang perkongsian pengiklanan berdasarkan pelbagai faktor seperti berat akaun, kandungan video dan maklum balas khalayak. Platform TikTok membolehkan penonton menyokong pencipta kegemaran mereka dengan menghantar hadiah,
 MobileSAM: Model pembahagian imej berprestasi tinggi dan ringan untuk peranti mudah alih
Jan 05, 2024 pm 02:50 PM
MobileSAM: Model pembahagian imej berprestasi tinggi dan ringan untuk peranti mudah alih
Jan 05, 2024 pm 02:50 PM
1. Pengenalan Dengan pempopularan peranti mudah alih dan peningkatan kuasa pengkomputeran, teknologi pembahagian imej telah menjadi tumpuan penyelidikan. MobileSAM (MobileSegmentAnythingModel) ialah model pembahagian imej yang dioptimumkan untuk peranti mudah alih. Ia bertujuan untuk mengurangkan kerumitan pengiraan dan penggunaan memori sambil mengekalkan hasil pembahagian yang berkualiti tinggi, supaya berjalan dengan cekap pada peranti mudah alih dengan sumber terhad. Artikel ini akan memperkenalkan prinsip, kelebihan dan senario aplikasi MobileSAM secara terperinci. 2. Idea reka bentuk model MobileSAM Idea reka bentuk model MobileSAM terutamanya merangkumi aspek berikut: Model ringan: Untuk menyesuaikan diri dengan had sumber peranti mudah alih, model MobileSAM menggunakan model ringan.
 Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej_Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej
Mar 30, 2024 pm 12:26 PM
Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej_Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej
Mar 30, 2024 pm 12:26 PM
1. Mula-mula buka Weibo pada telefon mudah alih anda dan klik [Saya] di sudut kanan bawah (seperti yang ditunjukkan dalam gambar). 2. Kemudian klik [Gear] di penjuru kanan sebelah atas untuk membuka tetapan (seperti yang ditunjukkan dalam gambar). 3. Kemudian cari dan buka [Tetapan Umum] (seperti yang ditunjukkan dalam gambar). 4. Kemudian masukkan pilihan [Video Follow] (seperti yang ditunjukkan dalam gambar). 5. Kemudian buka tetapan [Video Upload Resolution] (seperti yang ditunjukkan dalam gambar). 6. Akhir sekali, pilih [Kualiti Imej Asal] untuk mengelakkan pemampatan (seperti yang ditunjukkan dalam gambar).
 2 Cara untuk Alih Keluar Slow Motion daripada Video pada iPhone
Mar 04, 2024 am 10:46 AM
2 Cara untuk Alih Keluar Slow Motion daripada Video pada iPhone
Mar 04, 2024 am 10:46 AM
Pada peranti iOS, apl Kamera membolehkan anda merakam video gerak perlahan, atau 240 bingkai sesaat jika anda mempunyai iPhone terkini. Keupayaan ini membolehkan anda menangkap aksi berkelajuan tinggi dengan terperinci yang kaya. Tetapi kadangkala, anda mungkin mahu memainkan video gerak perlahan pada kelajuan biasa supaya anda boleh menghargai butiran dan tindakan dalam video dengan lebih baik. Dalam artikel ini, kami akan menerangkan semua kaedah untuk mengalih keluar gerakan perlahan daripada video sedia ada pada iPhone. Cara Mengalih Keluar Gerak Perlahan daripada Video pada iPhone [2 Kaedah] Anda boleh menggunakan Apl Foto atau Apl iMovie untuk mengalih keluar gerakan perlahan daripada video pada peranti anda. Kaedah 1: Buka pada iPhone menggunakan aplikasi Photos
 Bagaimana untuk menerbitkan karya video Xiaohongshu? Apakah yang perlu saya perhatikan semasa menyiarkan video?
Mar 23, 2024 pm 08:50 PM
Bagaimana untuk menerbitkan karya video Xiaohongshu? Apakah yang perlu saya perhatikan semasa menyiarkan video?
Mar 23, 2024 pm 08:50 PM
Dengan kemunculan platform video pendek, Xiaohongshu telah menjadi platform untuk ramai orang berkongsi kehidupan mereka, meluahkan perasaan mereka dan mendapatkan trafik. Pada platform ini, menerbitkan karya video ialah cara interaksi yang sangat popular. Jadi, bagaimana untuk menerbitkan karya video Xiaohongshu? 1. Bagaimana untuk menerbitkan karya video Xiaohongshu? Mula-mula, pastikan anda mempunyai kandungan video yang sedia untuk dikongsi. Anda boleh menggunakan telefon bimbit anda atau peralatan kamera lain untuk merakam, tetapi anda perlu memberi perhatian kepada kualiti imej dan kejelasan bunyi. 2. Edit video: Untuk menjadikan kerja lebih menarik, anda boleh mengedit video. Anda boleh menggunakan perisian penyuntingan video profesional, seperti Douyin, Kuaishou, dsb., untuk menambah penapis, muzik, sari kata dan elemen lain. 3. Pilih kulit muka: Kulit adalah kunci untuk menarik pengguna untuk mengklik.
