
 Peranti teknologi
AI
Baidu Wenxinyiyan menduduki tempat terakhir dalam kalangan model domestik? Saya keliru
Peranti teknologi
AI
Baidu Wenxinyiyan menduduki tempat terakhir dalam kalangan model domestik? Saya keliru
Baidu Wenxinyiyan menduduki tempat terakhir dalam kalangan model domestik? Saya keliru

Xi Xiaoyao Technology Talk Original
Pengarang |. Menjual Mengjiang Sejak kebelakangan ini, komuniti akaun awam kami telah memajukan tangkapan skrin yang dipanggil ulasan SuperClue. iFlytek malah mempromosikannya di akaun rasminya:

Memandangkan model iFlytek Spark baru dikeluarkan, saya tidak memainkannya sangat yang paling berkuasa buatan China Penulis tidak berani membuat sebarang kesimpulan.
Tetapi dalam tangkapan skrin penilaian ini, Baidu Wenxinyiyan, model domestik paling popular pada masa ini, tidak dapat mengalahkan model sumber terbuka akademik kecil ChatGLM-6B. Ini bukan sahaja tidak konsisten dengan pengalaman pengarang sendiri, tetapi dalam komuniti teknologi NLP profesional kami, semua orang juga menyatakan kekeliruan:
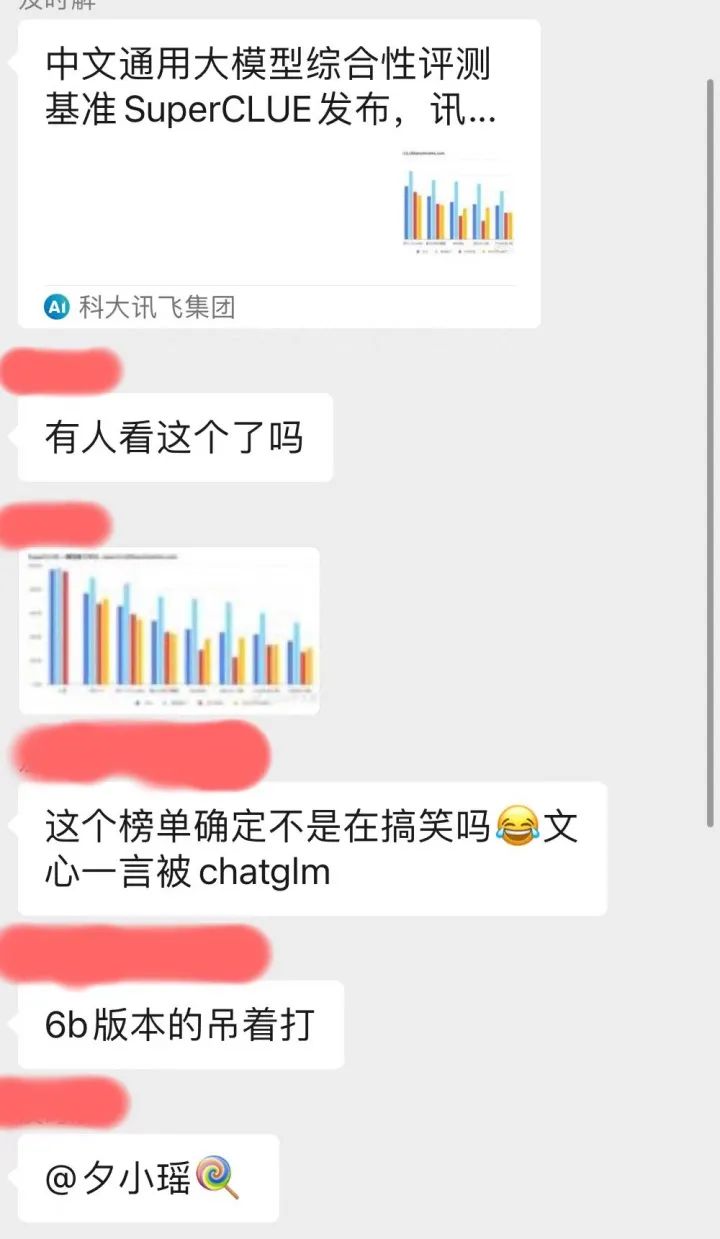
Keluar kerana ingin tahu, penulis pergi ke github senarai superclue ini untuk melihat bagaimana kesimpulan penilaian ini dicapai: https://www.php.cn/link/97c8dd44858d3568fdf9537c4b8743b2
Pertama sekali , penulis mendapati terdapat beberapa isu di bawah repo ini:
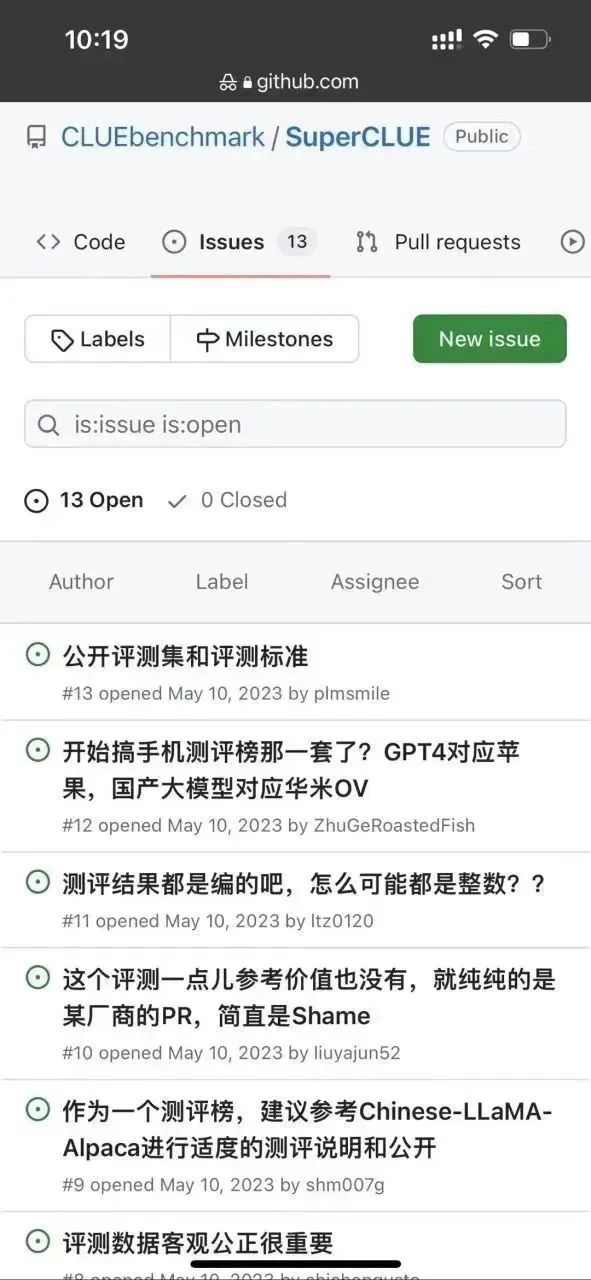
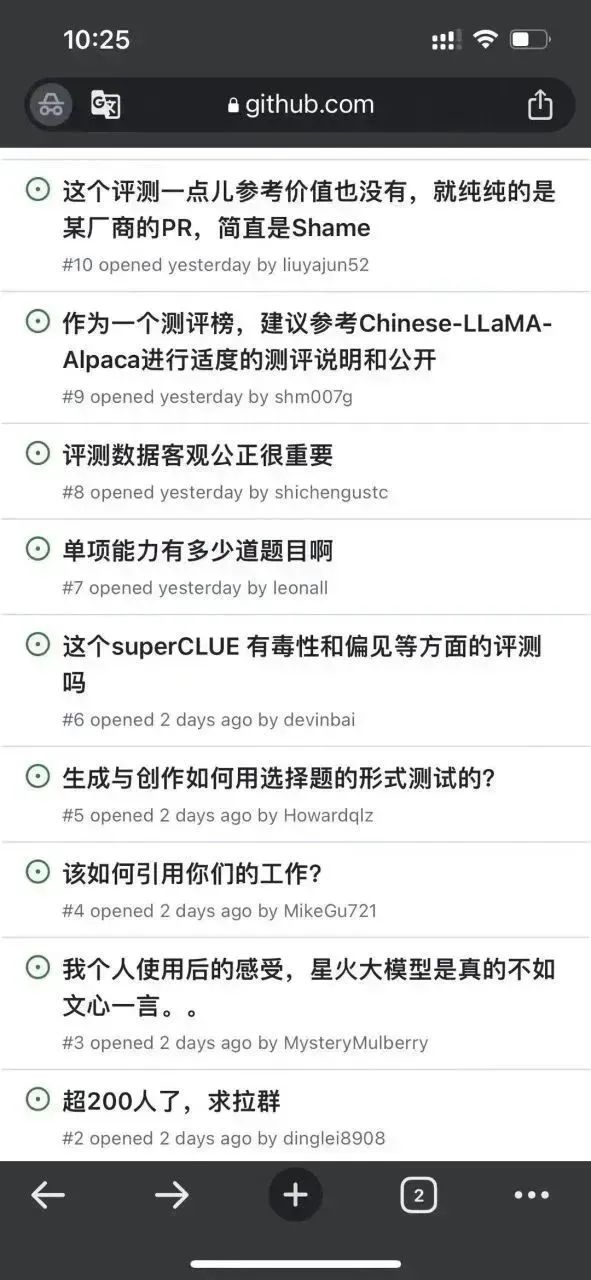
Nampaknya perasaan keterlaluan ini bukan sahaja Penulis memilikinya , dan pastinya, mata orang ramai masih tajam. . .
Pengarang lebih lanjut melihat kaedah penilaian senarai ini:

Lelaki yang baik, ternyata ujian model besar generatif yang dipanggil semua tentang membiarkan Model membuat soalan aneka pilihan. . .
Jelas sekali, kaedah penilaian aneka pilihan ini ditujukan kepada model AI yang diskriminatif pada era BERT Pada masa itu, model AI umumnya tidak mempunyai keupayaan untuk menjana, tetapi hanya mempunyai keupayaan untuk mendiskriminasi (seperti dapat menentukan kepunyaan sekeping teks) Kategori, antara pilihan yang manakah merupakan jawapan yang betul kepada soalan, menilai sama ada semantik dua keping teks adalah konsisten, dsb.).
Penilaian model generatif agak berbeza daripada penilaian model diskriminatif.
Sebagai contoh, untuk tugas penjanaan khas seperti terjemahan mesin, penunjuk penilaian seperti BLEU biasanya digunakan untuk mengesan "liputan perbendaharaan kata dan frasa" antara respons yang dijana oleh model dan respons rujukan. Walau bagaimanapun, terdapat sangat sedikit tugas generatif dengan respons rujukan seperti terjemahan mesin, dan sebahagian besar penilaian generatif memerlukan penilaian manual.
Contohnya, tugas penjanaan seperti penjanaan dialog gaya sembang, pemindahan gaya teks, penjanaan bab, penjanaan tajuk, ringkasan teks, dll. memerlukan setiap model dinilai untuk menjana respons secara bebas, dan kemudian membandingkan secara manual respons yang dihasilkan oleh model yang berbeza ini, atau pertimbangan manusia sama ada keperluan tugas dipenuhi.
Pusingan pertandingan AI semasa ialah persaingan untuk keupayaan penjanaan model, bukan persaingan untuk keupayaan diskriminasi model. Perkara yang paling berkuasa untuk dinilai ialah reputasi pengguna sebenar, bukan senarai akademik yang dingin lagi. Lebih-lebih lagi, ia adalah senarai yang tidak menguji keupayaan penjanaan model sama sekali.
Mengimbas kembali beberapa tahun yang lalu -
Pada tahun 2019, apabila OpenAI mengeluarkan GPT-2, kami telah mengumpulkan helah untuk meningkatkan kedudukan
Pada tahun 2020, OpenAI dikeluarkan Semasa GPT-3, kami sedang mengumpulkan helah untuk menyegarkan senarai;
Pada 2021-2022, apabila penalaan arahan dan RLHF berfungsi seperti FLAN, T0, InstructGPT dan sebagainya, kami masih mempunyai banyak pasukan berkeras untuk menimbun helah untuk menyegarkan senarai...
Saya harap kami tidak akan mengulangi kesilapan yang sama dalam gelombang perlumbaan senjata model generatif ini.
Jadi bagaimanakah model AI generatif harus diuji?
Maaf, saya katakan sebelum ini bahawa jika anda ingin melakukan ujian yang tidak berat sebelah, ia sangat, sangat sukar, malah lebih sukar daripada membangunkan model generatif sendiri. Apakah kesukaran? Beberapa soalan khusus:
- Bagaimana untuk membahagikan dimensi penilaian? Dengan pemahaman, ingatan, penaakulan, ekspresi? Mengikut bidang kepakaran? Atau menggabungkan tugas penilaian generatif NLP tradisional?
- Bagaimana untuk melatih penilai? Untuk soalan ujian dengan ambang profesional yang sangat tinggi seperti pengekodan, penyahpepijatan, terbitan matematik dan Soal Jawab kewangan, undang-undang dan perubatan, bagaimanakah anda merekrut orang untuk menguji?
- Bagaimana untuk menentukan kriteria penilaian untuk soalan ujian yang sangat subjektif (seperti menghasilkan penulisan salinan gaya Xiaohongshu)?
- Bolehkah bertanya beberapa soalan penulisan umum mewakili keupayaan penjanaan/penulisan teks model?
- Periksa sub-keupayaan penjanaan teks model Adakah penjanaan bab, penjanaan soal jawab, terjemahan, ringkasan dan pemindahan gaya diliputi? Adakah perkadaran setiap tugas adalah sama? Adakah kriteria penghakiman jelas? Penting secara statistik?
- Dalam sub-tugas penjanaan soal jawab di atas, adakah semua kategori menegak seperti sains, penjagaan perubatan, kereta, ibu dan bayi, kewangan, kejuruteraan, politik, ketenteraan, hiburan, dsb. Adakah perkadaran itu sekata?
- Bagaimana untuk menilai kemahiran perbualan? Bagaimana untuk mereka bentuk tugas pemeriksaan untuk ketekalan, kepelbagaian, kedalaman topik, dan personifikasi dialog?
- Untuk ujian kebolehan yang sama, adakah soalan mudah, soalan kesukaran sederhana dan soalan jangka panjang yang kompleks diliputi? Bagaimana untuk menentukan? Apakah perkadaran yang mereka kira?
Ini hanyalah beberapa masalah asas yang perlu diselesaikan Dalam proses reka bentuk penanda aras sebenar, kita perlu menghadapi sejumlah besar masalah yang jauh lebih sukar daripada masalah di atas.
Oleh itu, sebagai seorang pengamal AI, penulis menyeru semua orang untuk melihat kedudukan pelbagai model AI secara rasional. Malah tidak ada tanda aras ujian yang tidak berat sebelah, jadi apa gunanya kedudukan ini?
Seperti pepatah yang sama, pengguna sebenar mempunyai keputusan akhir sama ada model generatif itu bagus atau tidak.
Tidak kira betapa tinggi kedudukan model dalam senarai, jika model itu tidak dapat menyelesaikan masalah yang anda ambil berat, model itu akan menjadi model biasa kepada anda. Dalam erti kata lain, jika model yang berada di kedudukan bawah sangat kuat dalam senario yang anda bimbangkan, maka model itu adalah model harta karun untuk anda.
Di sini, penulis mendedahkan set ujian kes keras (kes sukar) yang diperkaya dan ditulis oleh pasukan kami. Set ujian ini memfokuskan kepada keupayaan model untuk menyelesaikan masalah/arahan yang sukar.
Set ujian yang sukar ini memfokuskan pada pemahaman bahasa model, pemahaman dan mengikut arahan yang kompleks, penjanaan teks, penjanaan kandungan kompleks, pelbagai pusingan dialog, pengesanan percanggahan, penaakulan akal, penaakulan matematik, penaakulan kontrafaktual dan bahaya Pengenalan maklumat, kesedaran undang-undang dan etika, pengetahuan kesusasteraan Cina, keupayaan merentas bahasa dan keupayaan pengekodan, dsb.
Saya menekankan sekali lagi bahawa ini adalah set kes yang dibuat oleh pasukan pengarang untuk menguji keupayaan model generatif untuk menyelesaikan contoh yang sukar jauh daripada mewakili kesimpulan ujian yang tidak berat sebelah Jika anda mahukan kesimpulan ujian yang tidak berat sebelah, sila jawab soalan penilaian yang dinyatakan di atas dahulu, dan kemudian tentukan tanda aras ujian yang berwibawa.
Rakan-rakan yang ingin menilai dan mengesahkan sendiri boleh membalas kata laluan [AI Evaluation] di latar belakang akaun awam ini "Xi Xiaoyao Technology" untuk memuat turun fail ujian
Berikut ialah keputusan penilaian bagi tiga model paling kontroversi dalam senarai superclue: iFlytek Spark, Wenxin Yiyan dan ChatGPT:



Kadar penyelesaian Kes Sukar:
- ChatGPT (GPT-3.5-turbo): 11/24=45.83%
- Wen Xinyi Yan ( versi 2023.5.10): 13/24=54.16%
- iFlytek Spark (versi 2023.5.10): 7/24=29.16%
Ini untuk menunjukkan bukti Isn' t Feixinghuo sebaik Wen Xinyiyan? Jika anda membaca artikel sebelum ini dengan teliti, anda akan faham apa yang penulis ingin katakan.
Sesungguhnya, walaupun model Spark tidak sehebat Wen Xinyiyan dalam set kes sukar dalam pasukan kami, ini tidak bermakna yang satu pasti lebih baik daripada yang lain secara agregat. Ia hanya menunjukkan bahawa dalam kes sukar dalam pasukan kami Pada set ujian, Wenxinyiyan melakukan yang terbaik, malah menyelesaikan dua kes yang lebih sukar daripada ChatGPT.
Untuk soalan mudah, sebenarnya tidak banyak perbezaan antara model domestik dan ChatGPT. Untuk masalah yang sukar, setiap model mempunyai kekuatannya sendiri. Berdasarkan pengalaman komprehensif pasukan pengarang, Wen Xinyiyan sudah cukup untuk mengalahkan model sumber terbuka seperti ChatGLM-6B untuk ujian akademik Sesetengah keupayaan adalah lebih rendah daripada ChatGPT, dan beberapa keupayaan mengatasi ChatGPT.
Hal yang sama berlaku untuk model domestik yang dikeluarkan oleh pengeluar utama lain seperti Alibaba Tongyi Qianwen dan iFlytek Spark.
Seperti yang saya katakan sebelum ini, tiada tanda aras ujian yang tidak berat sebelah, jadi apa gunanya kedudukan model?
Daripada mempertikaikan tentang pelbagai ranking berat sebelah, lebih baik buat set ujian yang anda ambil berat seperti yang dilakukan oleh pasukan saya.
Model yang boleh menyelesaikan masalah anda ialah model yang bagus.
Atas ialah kandungan terperinci Baidu Wenxinyiyan menduduki tempat terakhir dalam kalangan model domestik? Saya keliru. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Baidu Apollo mengeluarkan Apollo ADFM, model besar pertama di dunia yang menyokong pemanduan autonomi L4
Jun 04, 2024 pm 08:01 PM
Baidu Apollo mengeluarkan Apollo ADFM, model besar pertama di dunia yang menyokong pemanduan autonomi L4
Jun 04, 2024 pm 08:01 PM
Pada 15 Mei, Baidu Apollo mengadakan Hari Apollo 2024 di Wuhan Baidu Carrot Auto Robot Zhixing Valley, secara menyeluruh menunjukkan kemajuan utama Baidu dalam pemanduan autonomi sepanjang sepuluh tahun yang lalu, membawa lonjakan teknologi berdasarkan model besar dan definisi baharu keselamatan penumpang rangkaian operasi kenderaan autonomi terbesar di dunia, Baidu telah menjadikan pemanduan autonomi lebih selamat daripada pemanduan manusia. Terima kasih kepada ini, kaedah perjalanan yang lebih selamat, lebih selesa, hijau dan rendah karbon bertukar daripada ideal kepada realiti. Wang Yunpeng, naib presiden Kumpulan Baidu dan presiden Kumpulan Perniagaan Pemanduan Pintar, berkata di tempat kejadian: "Niat asal kami membina kenderaan autonomi adalah untuk memuaskan keinginan orang ramai untuk perjalanan yang lebih baik. Kepuasan orang ramai adalah penggerak kami. Kerana keselamatan, Begitu cantik, kami gembira melihat
 DeepSeek Web Versi Pintu Masuk Laman Web Rasmi DeepSeek
Feb 19, 2025 pm 04:54 PM
DeepSeek Web Versi Pintu Masuk Laman Web Rasmi DeepSeek
Feb 19, 2025 pm 04:54 PM
DeepSeek adalah alat carian dan analisis pintar yang kuat yang menyediakan dua kaedah akses: versi web dan laman web rasmi. Versi web adalah mudah dan cekap, dan boleh digunakan tanpa pemasangan; Sama ada individu atau pengguna korporat, mereka dapat dengan mudah mendapatkan dan menganalisis data besar-besaran melalui DeepSeek untuk meningkatkan kecekapan kerja, membantu membuat keputusan dan menggalakkan inovasi.
 Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Siri penanda aras YOLO sistem pengesanan sasaran sekali lagi menerima peningkatan besar. Sejak pengeluaran YOLOv9 pada Februari tahun ini, baton siri YOLO (YouOnlyLookOnce) telah diserahkan kepada penyelidik di Universiti Tsinghua. Hujung minggu lalu, berita pelancaran YOLOv10 menarik perhatian komuniti AI. Ia dianggap sebagai rangka kerja terobosan dalam bidang penglihatan komputer dan terkenal dengan keupayaan pengesanan objek hujung ke hujung masa nyata, meneruskan legasi siri YOLO dengan menyediakan penyelesaian berkuasa yang menggabungkan kecekapan dan ketepatan. Alamat kertas: https://arxiv.org/pdf/2405.14458 Alamat projek: https://github.com/THU-MIG/yo
 Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Pada bulan Februari tahun ini, Google melancarkan model besar berbilang modal Gemini 1.5, yang telah meningkatkan prestasi dan kelajuan dengan sangat baik melalui pengoptimuman kejuruteraan dan infrastruktur, seni bina MoE dan strategi lain. Dengan konteks yang lebih panjang, keupayaan penaakulan yang lebih kukuh dan pengendalian kandungan merentas modal yang lebih baik. Jumaat ini, Google DeepMind secara rasmi mengeluarkan laporan teknikal Gemini 1.5, yang merangkumi versi Flash dan peningkatan terkini yang lain Dokumen itu sepanjang 153 halaman. Pautan laporan teknikal: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dalam laporan ini, Google memperkenalkan Gemini1
 Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Ditulis di atas & pemahaman peribadi pengarang: Baru-baru ini, dengan perkembangan dan penemuan teknologi pembelajaran mendalam, model asas berskala besar (Model Asas) telah mencapai hasil yang ketara dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer. Aplikasi model asas dalam pemanduan autonomi juga mempunyai prospek pembangunan yang hebat, yang boleh meningkatkan pemahaman dan penaakulan senario. Melalui pra-latihan tentang bahasa yang kaya dan data visual, model asas boleh memahami dan mentafsir pelbagai elemen dalam senario pemanduan autonomi dan melakukan penaakulan, menyediakan arahan bahasa dan tindakan untuk memacu membuat keputusan dan perancangan. Model asas boleh ditambah data dengan pemahaman senario pemanduan untuk menyediakan ciri-ciri yang jarang berlaku dalam pengedaran ekor panjang yang tidak mungkin ditemui semasa pemanduan rutin dan pengumpulan data.
 Adakah set data yang berbeza mempunyai undang-undang penskalaan yang berbeza? Dan anda boleh meramalkannya dengan algoritma pemampatan
Jun 07, 2024 pm 05:51 PM
Adakah set data yang berbeza mempunyai undang-undang penskalaan yang berbeza? Dan anda boleh meramalkannya dengan algoritma pemampatan
Jun 07, 2024 pm 05:51 PM
Secara umumnya, lebih banyak pengiraan yang diperlukan untuk melatih rangkaian saraf, lebih baik prestasinya. Apabila menskalakan pengiraan, keputusan mesti dibuat: meningkatkan bilangan parameter model atau meningkatkan saiz set data—dua faktor yang mesti ditimbang dalam belanjawan pengiraan tetap. Kelebihan menambah bilangan parameter model ialah ia boleh meningkatkan kerumitan dan keupayaan ekspresi model, dengan itu lebih sesuai dengan data latihan. Walau bagaimanapun, terlalu banyak parameter boleh menyebabkan pemasangan berlebihan, menjadikan model berprestasi buruk pada data yang tidak kelihatan. Sebaliknya, mengembangkan saiz set data boleh meningkatkan keupayaan generalisasi model dan mengurangkan masalah overfitting. Biar kami memberitahu anda: Selagi anda memperuntukkan parameter dan data dengan sewajarnya, anda boleh memaksimumkan prestasi dalam belanjawan pengkomputeran tetap. Banyak kajian terdahulu telah meneroka Scalingl model bahasa saraf.
