
 Peranti teknologi
AI
13948 soalan, meliputi 52 mata pelajaran seperti kalkulus dan penjanaan baris, telah diserahkan kepada Universiti Tsinghua untuk membuat set ujian untuk model besar Cina
Peranti teknologi
AI
13948 soalan, meliputi 52 mata pelajaran seperti kalkulus dan penjanaan baris, telah diserahkan kepada Universiti Tsinghua untuk membuat set ujian untuk model besar Cina
13948 soalan, meliputi 52 mata pelajaran seperti kalkulus dan penjanaan baris, telah diserahkan kepada Universiti Tsinghua untuk membuat set ujian untuk model besar Cina

Kemunculan ChatGPT telah menyedarkan masyarakat Cina tentang jurang dengan peringkat terkemuka antarabangsa. Baru-baru ini, pembangunan model besar Cina telah giat dijalankan, tetapi terdapat sedikit tanda aras penilaian Cina.
Dalam proses pembangunan siri OpenAI GPT/siri Google PaLM/siri DeepMind Chinchilla/siri Anthropic Claude, tiga set data MMLU/MATH/BBH memainkan peranan penting, kerana ia secara relatifnya meliputi keupayaan setiap dimensi model. Yang paling patut diberi perhatian ialah set data MMLU, yang mempertimbangkan keupayaan pengetahuan menyeluruh bagi 57 disiplin, daripada kemanusiaan kepada sains sosial kepada sains dan kejuruteraan. Model Gopher dan Chinchilla DeepMind hanya melihat pada skor MMLU, jadi kami ingin membina senarai penanda aras berbilang disiplin bahasa Cina yang cukup berbeza untuk membantu pembangun membangunkan model Cina yang besar.
Kami menghabiskan masa kira-kira tiga bulan untuk membina sistem yang meliputi empat hala tuju utama: kemanusiaan, sains sosial, sains dan kejuruteraan serta jurusan lain serta 52 mata pelajaran (kalkulus, penjanaan garis... ) , sejumlah 13948 soalan pengetahuan Cina dan ujian penaakulan ditetapkan dari sekolah menengah hingga peperiksaan pasca siswazah dan vokasional universiti Kami memanggilnya C-Eval untuk membantu masyarakat Cina membangunkan model besar.
Artikel ini adalah untuk merekodkan proses kami membina C-Eval dan berkongsi dengan pembangun pemikiran dan keutamaan R&D kami dari perspektif kami. Matlamat kami yang paling penting ialah membantu pembangunan model, bukan untuk menyenaraikan . Mengejar kedudukan tinggi dalam senarai secara membabi buta akan membawa banyak akibat buruk, tetapi jika C-Eval boleh digunakan secara saintifik untuk membantu lelaran model, C-Eval boleh dimaksimumkan. Oleh itu, kami mengesyorkan merawat set data dan senarai C-Eval dari perspektif pembangunan model.
- Tapak web: https://cevalbenchmark.com/
- Github: https://github.com/SJTU-LIT/ceval
- Kertas: https://arxiv.org/abs/2305.08322
Jadual daripada Kandungan

1 - Penunjuk teras kekuatan model
Pertama sekali, tukar model menjadi robot perbualan Perkara tidak sukar. Sudah ada robot perbualan seperti Alpaca, Vicuna, dan RWKV di dunia sumber terbuka Senang untuk berbual dengan mereka secara santai Tetapi jika anda benar-benar mahu model ini menjadi produktif, sembang santai tidak mencukupi. Oleh itu, masalah pertama dalam membina tanda aras penilaian adalah untuk mencari tahap pembezaan dan memikirkan jenis keupayaan yang menjadi penunjuk teras yang membezakan kekuatan model. Kami menganggap dua teras Pengetahuan dan Penaakulan.
1.1 - Pengetahuan
Mengapa keupayaan intelek adalah keupayaan teras? Terdapat hujah berikut:
- Kami berharap model itu boleh menjadi universal dan menyumbang produktiviti dalam bidang yang berbeza, yang secara semula jadi memerlukan model mengetahui pengetahuan setiap bidang.
- Kami juga berharap model tidak akan bercakap kosong dan tidak tahu apa yang tidak diketahui Ini juga memerlukan meluaskan pengetahuan model supaya boleh mengatakan tidak kurang tahu.
- Dalam senarai penilaian Bahasa Inggeris HELM Stanford, kesimpulan penting ialah saiz model berkorelasi positif secara signifikan dengan kesan tugasan berintensif pengetahuan Ini kerana bilangan parameter model tersebut boleh digunakan untuk menyimpan pengetahuan.
- Seperti yang dinyatakan di atas, model penting sedia ada, seperti DeepMind’s Gopher/Chinchilla, hampir hanya melihat MMLU semasa menilai Teras MMLU ialah liputan pengetahuan model ujian.
- Dalam blog keluaran GPT-4, perkara pertama ialah menyenaraikan prestasi model pada pelbagai peperiksaan mata pelajaran sebagai ukuran keupayaan model.
Oleh itu, keupayaan berasaskan pengetahuan ialah ukuran yang baik bagi potensi model asas.
1.2 - Penaakulan
Keupayaan penaakulan ialah keupayaan untuk meningkatkan lagi berdasarkan pengetahuan Ia mewakili sama ada model itu boleh dilakukan susah, Perkara yang sangat rumit. Untuk model menjadi kukuh, pertama sekali ia memerlukan pengetahuan yang luas, dan kemudian membuat inferens berdasarkan pengetahuan.
Hujah penting untuk penaakulan ialah:
- Dalam blog keluaran GPT-4, OpenAI dengan jelas menulis "Perbezaannya datang keluar apabila kerumitan tugasan mencapai ambang yang mencukupi” (perbezaan antara GPT-3.5 dan GPT-4 hanya akan menjadi ketara selepas kerumitan tugasan mencapai tahap tertentu). Ini menunjukkan bahawa model yang kuat mempunyai keupayaan inferens yang ketara, manakala model yang lebih lemah tidak mempunyai banyak keupayaan.
- Dalam Laporan Teknologi PaLM-2, dua set data inferens BBH dan MATH disenaraikan khas untuk perbincangan dan tumpuan.
- Jika anda mahu model itu menjadi platform pengkomputeran generasi baharu dan membiak ekosistem aplikasi baharu padanya, anda perlu menjadikan model itu cukup kuat untuk menyelesaikan tugas yang rumit.
Di sini kita juga perlu menjelaskan hubungan antara penaakulan dan pengetahuan:
- Keupayaan berasaskan pengetahuan adalah asas daripada keupayaan model, keupayaan penaakulan adalah pemejalwapan selanjutnya - model perlu menaakul berdasarkan graf pengetahuan sedia ada.
- Pada senarai tugas berasaskan pengetahuan, saiz model dan skor model secara amnya berubah secara berterusan, dan tidak mungkin akan berlaku penurunan seperti tebing hanya kerana modelnya kecil - dari perspektif ini, tugasan berasaskan pengetahuan Tugas-tugas itu sedikit lebih berbeza.
- Pada senarai tugasan inferens, mungkin terdapat perubahan fasa antara saiz model dan skor model Hanya apabila model mencapai tahap tertentu (mungkin 50B dan ke atas, iaitu , LLaMA 65B) magnitud), keupayaan penaakulan model akan bertambah baik.
- Untuk tugasan berasaskan pengetahuan, kesan gesaan Rantaian Pemikiran (CoT) dan gesaan Jawab sahaja (AO) adalah hampir sama untuk tugasan penaakulan, CoT adalah ketara; lebih baik Yu AO.
- Jadi di sini anda perlu ingat bahawa CoT hanya menambah kesan penaakulan tetapi bukan kesan pengetahuan. Kami juga melihat fenomena ini dalam dataset C-Eval.
2 - Matlamat C-Eval
Dengan penerangan dan penaakulan di atas, kami memutuskan untuk membina set data bermula daripada berasaskan pengetahuan tugas Menguji keupayaan pengetahuan model adalah bersamaan dengan menanda aras set data MMLU pada masa yang sama, kami juga berharap untuk membawa beberapa kandungan berkaitan penaakulan untuk mengukur lagi keupayaan tertib tinggi model, jadi kami memasukkan subjek yang memerlukan; penaakulan kukuh dalam C-Eval (Micro Integral, algebra linear, kebarangkalian...) diekstrak khas dan dinamakan C-Eval Hard subset, yang digunakan untuk mengukur keupayaan penaakulan model, yang bersamaan dengan menanda aras set data MATH .
Pada C-Eval Hard, model pertama perlu mempunyai pengetahuan berkaitan matematik, dan kemudian perlu mempunyai idea langkah demi langkah untuk menyelesaikan masalah, dan kemudian perlu memanggil Wolfram Alpha/Mathematica/Matlab semasa proses penyelesaian masalah Keupayaan untuk melakukan pengiraan berangka dan simbolik/pembezaan dan kamiran, dan menyatakan proses pengiraan dan keputusan dalam format Lateks. Bahagian soalan ini sangat sukar.
C-Eval berharap untuk menanda aras MMLU secara keseluruhan (set data ini digunakan untuk pembangunan GPT-3.5, GPT-4, PaLM, PaLM-2, Gopher, Chinchilla) , dengan harapan untuk menanda aras MATH pada bahagian Keras (set data ini digunakan dalam pembangunan GPT-4, PaLM-2, Minerva dan Galactica).
Perlu dinyatakan di sini bahawa matlamat kami yang paling penting adalah untuk membantu pembangunan model, bukan untuk menyenaraikan . Mengejar kedudukan tinggi dalam senarai secara membabi buta akan membawa banyak akibat buruk, yang akan kami jelaskan sebentar lagi tetapi jika anda boleh menggunakan C-Eval secara saintifik untuk membantu lelaran model, anda akan mendapat manfaat yang besar. Kami mengesyorkan merawat set data dan senarai C-Eval dari perspektif pembangunan model.
2.1 - Matlamatnya adalah untuk membantu pembangunan model
Dalam penyelidikan sebenar dan proses pembangunan, Banyak kali kita perlu mengetahui kualiti penyelesaian tertentu atau kualiti model tertentu Pada masa ini kita memerlukan set data untuk membantu kita menguji. Berikut ialah dua adegan klasik:
- Senario 1, carian hiperparameter tambahan : Kami mempunyai beberapa skim pencampuran data pra-latihan, tidak pasti yang mana lebih sesuai Okay, jadi kita membandingkan satu sama lain pada C-Eval untuk menentukan skema pencampuran data pra-latihan yang optimum.
- Senario 2, fasa latihan model perbandingan : Saya mempunyai pusat pemeriksaan pra-latihan dan pusat pemeriksaan yang ditala arahan, dan kemudian saya Jika saya ingin mengukur keberkesanan penalaan arahan saya, saya boleh membandingkan kedua-dua pusat pemeriksaan antara satu sama lain pada C-Eval untuk mengukur kualiti relatif pra-latihan dan penalaan arahan.
2.2 - Kedudukan bukan matlamat
Kita perlu tekankan mengapa kita tidak sepatutnya mengikut kedudukan ranking Sebagai matlamat:
- Jika anda mengambil ranking sebagai matlamat, adalah mudah untuk melebihkan senarai untuk skor tinggi, tetapi kehilangan serba boleh - ini adalah ahli akademik NLP sebelum ini GPT-3.5 Dunia mempelajari pelajaran penting tentang finetune Bert.
- Senarai itu sendiri hanya mengukur potensi model, bukan pengalaman pengguna sebenar - jika model itu benar-benar disukai pengguna, ia masih memerlukan banyak penilaian manual
- Jika matlamatnya adalah ranking, mudah untuk mengambil jalan pintas untuk skor tinggi dan kehilangan kualiti dan semangat penyelidikan saintifik yang mantap.
Oleh itu, jika C-Eval digunakan sebagai alat untuk membantu pembangunan, peranan positifnya boleh dimaksimumkan tetapi jika ia digunakan sebagai ranking senarai, Terdapat a risiko besar penyalahgunaan C-Eval, dan terdapat kebarangkalian tinggi bahawa tidak akan ada hasil yang baik pada akhirnya.
Jadi sekali lagi, kami mengesyorkan agar set data C-Eval dan senaraikan daripada perspektif pembangunan model.
2.3 - Lelaran berterusan daripada maklum balas pembangun
Kerana kami mahu model itu cekap seperti pembangun Sokongan yang mungkin, jadi kami memilih untuk berkomunikasi secara terus dengan pembangun dan terus belajar dan mengulangi maklum balas pembangun - ini juga membolehkan kami belajar banyak perkara seperti model besar ialah Pembelajaran Pengukuhan daripada Maklum Balas Manusia, pasukan pembangunan C-Eval; ialah Teruskan Belajar daripada Maklum Balas Pembangun
Khususnya, semasa proses penyelidikan dan pembangunan, kami menjemput syarikat seperti ByteDance, SenseTime dan Shenyan untuk menyambungkan ujian C-Eval Go dalam mereka. aliran kerja sendiri, dan kemudian berkomunikasi antara satu sama lain tentang perkara yang mencabar dalam proses ujian. Proses ini membolehkan kami mempelajari banyak perkara yang tidak kami jangkakan pada mulanya:
- Banyak pasukan ujian, walaupun dalam syarikat yang sama, tidak mempunyai cara untuk mengetahui apa-apa maklumat yang berkaitan tentang model yang sedang diuji (pengujian kotak hitam), kami tidak tahu sama ada model ini telah melalui penalaan arahan, jadi kami perlu menyokong pembelajaran dalam konteks dan gesaan sifar
- Oleh kerana sesetengah model berwarna hitam Untuk ujian kotak, tidak ada cara untuk mendapatkan logit, tetapi tanpa logit untuk model kecil, lebih sukar untuk menentukan jawapannya, jadi kita perlu menentukan penyelesaian untuk menentukan jawapan dengan model kecil.
- Terdapat banyak model ujian model, seperti pembelajaran dalam konteks dan gesaan sifar; Terdapat banyak jenis pusat pemeriksaan, seperti pusat pemeriksaan terlatih dan pusat pemeriksaan diperhalusi arahan, jadi kita perlu memahami kesan dan interaksi masing-masing faktor ini.
- Model ini sangat sensitif terhadap gesaan, sama ada kejuruteraan segera diperlukan dan sama ada kejuruteraan segera menjejaskan keadilan.
- Apakah yang perlu GPT-3.5 / GPT-4 / Claude / PaLM kejuruteraan segera lakukan, dan kemudian belajar daripada pengalaman mereka.
Isu di atas ditemui melalui maklum balas daripada pembangun semasa interaksi kami dengan mereka. Masalah ini telah diselesaikan dalam dokumentasi dan kod github versi awam semasa C-Eval.
Proses di atas juga membuktikan bahawa merawat set dan senarai data C-Eval dari perspektif pembangunan model boleh membantu semua orang membangunkan model Cina yang besar.
Kami mengalu-alukan semua pembangun untuk menyerahkan isu dan menarik permintaan ke GitHub kami untuk memberitahu kami cara untuk membantu anda dengan lebih baik:)
3 - Cara untuk. memastikan kualiti
Dalam bab ini kita membincangkan kaedah yang kami gunakan untuk memastikan kualiti set data semasa proses pengeluaran. Rujukan kami yang paling penting di sini ialah dua set data MMLU dan MATH Oleh kerana empat pasukan model besar yang paling penting, OpenAI, Google, DeepMind dan Anthropic, semuanya menumpukan pada MMLU dan MATH, jadi kami berharap dapat menyumbang kepada kedua-dua ini. set data. Selepas penyelidikan awal kami dan beberapa siri perbincangan, kami membuat dua keputusan penting, satu adalah untuk membuat tangan set data dari awal dan satu lagi adalah kepada Perkara UtamaHalang soalan daripada dirangkak ke dalam latihan yang ditetapkan oleh perangkak.
3.1 - Buatan Tangan
Inspirasi penting daripada proses pembangunan GPT ialah dalam bidang kecerdasan buatan , terdapat Kepintaran yang sama seperti kecerdasan buatan Ini juga dicerminkan dengan baik dalam proses penubuhan C-Eval Secara khusus, daripada sumber soalan:
- <.>C-Eval Kebanyakan soalan di dalamnya diperoleh daripada fail format pdf dan perkataan seperti itu memerlukan pemprosesan tambahan dan pembersihan (manual) sebelum boleh digunakan. Ini kerana terdapat terlalu banyak pelbagai soalan di Internet Soalan yang wujud secara langsung dalam bentuk teks halaman web berkemungkinan telah digunakan dalam pra-latihan model
Kemudian terdapat soalan pemprosesan:
- Selepas mengumpul soalan, mula-mula mendigitalkan fail pdf dengan OCR, dan kemudian satukan format ke dalam Markdown, dan bahagian matematik disatukan dalam format Lateks
- Memproses formula adalah perkara yang menyusahkan: pertama sekali, OCR mungkin tidak dapat mengenalinya dengan betul, dan kemudian OCR tidak dapat mengenalinya secara langsung sebagai pendekatan kami di sini adalah untuk menukarnya secara automatik kepada Lateks jika boleh, tetapi tidak Pelajar dipindahkan secara automatik untuk menaip secara manual
- Keputusan akhir ialah semua kandungan berkaitan simbol (termasuk formula matematik dan formula kimia, seperti H2O) dalam lebih daripada 13,000 soalan telah diselesaikan oleh kami. Pelajar dalam pasukan projek telah mengesahkannya satu demi satu 🎜> Jadi sekarang soalan kami boleh ditulis dalam markdown yang sangat indah dibentangkan dalam bentuk, di sini kami memberikan contoh kalkulus. 🎜>
Kesukaran seterusnya ialah cara membina gesaan rantaian pemikiran rasmi Perkara utama di sini ialah kita perlukan untuk memastikan bahawa CoT kami adalah betul. Pendekatan awal kami adalah untuk membiarkan GPT-4 menjana Rantaian pemikiran untuk setiap contoh dalam konteks, tetapi kemudian kami mendapati bahawa ini tidak boleh dilaksanakan Pertama, yang dijana adalah terlalu panjang (lebih daripada 2048 token). panjang beberapa model mungkin tidak disokong; yang lain ialah kadar ralat terlalu tinggi. Adalah lebih baik untuk menyemak setiap satu sendiri

 Semua orang juga boleh merasakan mengapa soalan sukar, gesaan rantaian pemikiran adalah sangat panjang, dan mengapa model itu perlu dapat melakukan pengiraan simbolik dan berangka bagi kalkulus
Semua orang juga boleh merasakan mengapa soalan sukar, gesaan rantaian pemikiran adalah sangat panjang, dan mengapa model itu perlu dapat melakukan pengiraan simbolik dan berangka bagi kalkulus
3.2 - Mengelakkan soalan kami daripada dicampur ke dalam set latihan
Demi penilaian saintifik, kami telah mempertimbangkan satu siri mekanisme untuk menghalang soalan kami daripada dicampur ke dalam set latihan
- Pertama sekali, set ujian kami hanya mendedahkan soalan tetapi bukan jawapannya Anda boleh menggunakan model anda sendiri untuk menjalankan jawapan secara tempatan dan menyerahkannya di tapak web, dan kemudian markah akan diberikan di latar belakang
- Kemudian, semua soalan dalam C-Eval adalah soalan olok-olok soalan sebenar peperiksaan kebangsaan tersedia secara meluas dalam talian dan sangat mudah Dirangkak ke dalam set latihan model
Sudah tentu, di sebalik usaha kita, ia tidak dapat tidak berlaku bahawa bank soalan. boleh dicari pada topik halaman web tertentu, tetapi kami percaya situasi ini sepatutnya jarang berlaku. Dan berdasarkan keputusan yang kami ada, soalan C-Eval masih cukup dibezakan, terutamanya bahagian Sukar.
4 - Kaedah untuk meningkatkan kedudukan
Seterusnya kami menganalisis kaedah yang boleh digunakan untuk meningkatkan kedudukan model. Kami mula-mula menyenaraikan pintasan untuk anda, termasuk menggunakan LLaMA, yang tidak tersedia secara komersial, dan menggunakan data yang dijana oleh GPT, serta kelemahan kaedah ini, kemudian kami membincangkan apakah laluan yang sukar tetapi betul .
4.1 - Apakah jalan pintas yang boleh diambil?
Berikut ialah pintasan yang boleh anda ambil:
- Gunakan LLaMA sebagai model asas : Dalam projek penilaian model Bahasa Inggeris kami yang lain yang berkaitan dengan Hab Rantaian, kami menunjukkan bahawa model 65B LLaMA adalah model asas yang lebih lemah sedikit daripada GPT-3.5 Jika ia dilatih dengan data bahasa Cina, keupayaan bahasa Inggerisnya yang kukuh boleh dipindahkan secara automatik ke bahasa Cina.
- Tetapi kelemahan melakukan ini, ialah had atas keupayaan R&D dikunci oleh LLaMA 65B , tidak Ia mungkin melebihi GPT-3.5, apatah lagi GPT-4 Sebaliknya, LLaMA tidak tersedia untuk tujuan komersial secara langsung akan melanggar peraturan
- Dijana menggunakan Data GPT-4 : Terutamanya bahagian C-Eval Hard, biarkan GPT-4 melakukannya semula, dan kemudian suapkan jawapan GPT-4 kepada model anda sendiri
- Penyulingan daripada GPT-4 akan memburukkan lagi fenomena karut model Ini kerana RLHF menggalakkan model mengetahui perkara yang diketahuinya apabila memperhalusi keupayaan penolakan model saya tidak tahu kerana saya tidak tahu tetapi jika anda terus menyalin GPT-4, model lain mungkin tidak tahu apa yang GPT-4 tahu, yang akan menggalakkan model bercakap kosong. . Fenomena ini telah diketengahkan dalam ceramah baru-baru ini oleh John Schulman di Berkeley.
4.2 - Jalan yang sukar tetapi betul
Cara terbaik adalah menjadi diri sendiri bergantung dan berdikari, dibangunkan dari awal. Perkara ini sukar, mengambil masa, dan memerlukan kesabaran, tetapi ia adalah cara yang betul.
Secara khusus, kita perlu memberi tumpuan kepada kertas kerja daripada institusi berikut
- OpenAI - Tidak ada keraguan tentang ini, semua artikel mesti dihafal sepenuhnya
- Anthropic - Apa yang OpenAI tidak beritahu anda, Anthropic akan beritahu anda
- Google DeepMind - Google lebih kepada tipu muslihat, memberitahu anda semua teknologi secara jujur, tidak seperti OpenAI yang menyembunyikan segala-galanya
Semasa proses pembangunan, adalah disyorkan untuk memberi perhatian kepada kandungan berikut:
4.3 - Jangan tergesa-gesa Model besar adalah perkara yang memakan masa ujian komprehensif keupayaan industri kecerdasan buatan: Oleh itu, tidak perlu tergesa-gesa ke ranking, tidak perlu melihat keputusan esok, tidak perlu online lusa - ambil masa, langkah demi langkah. Banyak kali, jalan yang sukar tetapi betul sebenarnya adalah jalan terpantas. Dalam artikel ini, kami memperkenalkan matlamat pembangunan, proses dan pertimbangan utama C-Eval. Matlamat kami adalah untuk membantu pembangun membangunkan model besar Cina dengan lebih baik dan mempromosikan penggunaan saintifik C-Eval dalam akademik dan industri untuk membantu lelaran model. Kami tidak tergesa-gesa untuk melihat hasilnya, kerana model besar itu sendiri adalah perkara yang sangat sukar. Kami tahu jalan pintas yang boleh kami ambil, tetapi kami juga tahu bahawa jalan yang sukar tetapi betul sebenarnya adalah jalan terpantas. Kami berharap kerja ini dapat mempromosikan ekosistem R&D model besar Cina dan membolehkan orang ramai merasai kemudahan yang dibawa oleh teknologi ini lebih awal. Lampiran 1: Subjek termasuk dalam C-Eval
5 - Kesimpulan
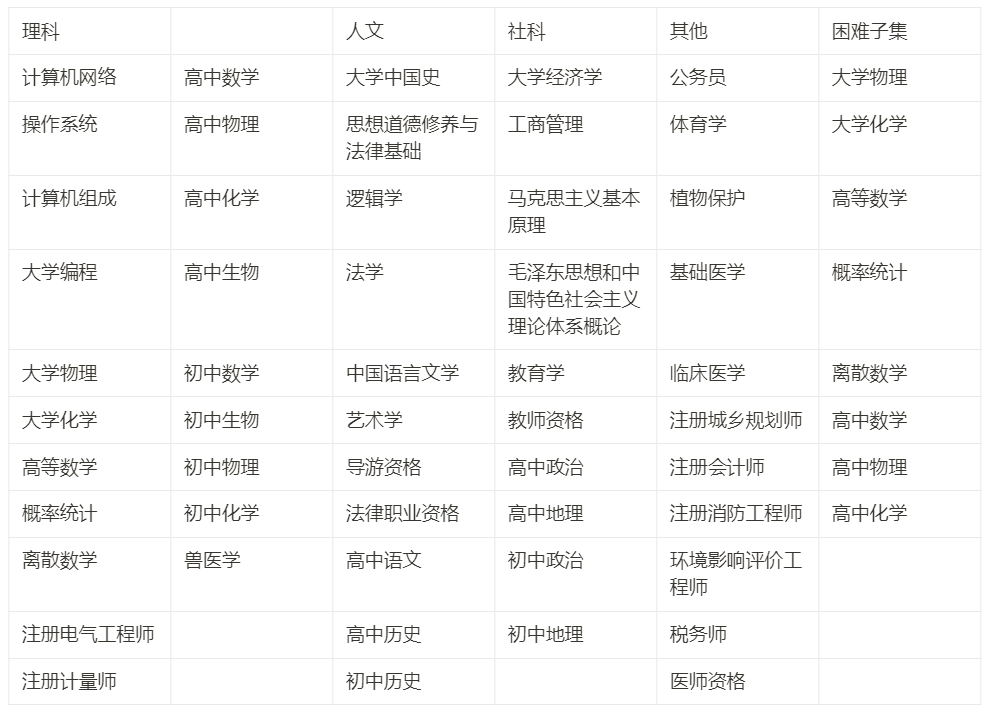
Lampiran 2: Sumbangan ahli projek

Nota: Dalam teks URL yang sepadan bagi kertas cadangan boleh didapati pada halaman asal.
Atas ialah kandungan terperinci 13948 soalan, meliputi 52 mata pelajaran seperti kalkulus dan penjanaan baris, telah diserahkan kepada Universiti Tsinghua untuk membuat set ujian untuk model besar Cina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Docker melengkapkan penggunaan tempatan model besar sumber terbuka LLama3 dalam masa tiga minit
Apr 26, 2024 am 10:19 AM
Docker melengkapkan penggunaan tempatan model besar sumber terbuka LLama3 dalam masa tiga minit
Apr 26, 2024 am 10:19 AM
Gambaran Keseluruhan LLaMA-3 (LargeLanguageModelMetaAI3) ialah model kecerdasan buatan generatif sumber terbuka berskala besar yang dibangunkan oleh Syarikat Meta. Ia tidak mempunyai perubahan besar dalam struktur model berbanding LLaMA-2 generasi sebelumnya. Model LLaMA-3 dibahagikan kepada versi skala yang berbeza, termasuk kecil, sederhana dan besar, untuk memenuhi keperluan aplikasi dan sumber pengkomputeran yang berbeza. Saiz parameter model kecil ialah 8B, saiz parameter model sederhana ialah 70B, dan saiz parameter model besar mencapai 400B. Walau bagaimanapun, semasa latihan, matlamatnya adalah untuk mencapai kefungsian berbilang modal dan berbilang bahasa, dan hasilnya dijangka setanding dengan GPT4/GPT4V. Pasang OllamaOllama ialah model bahasa besar sumber terbuka (LL
