

Bagaimana untuk mengoptimumkan pernyataan SQL dalam MySQL

1. Gambaran Keseluruhan
Semasa proses pembangunan sistem aplikasi, disebabkan jumlah data awal yang kecil, pembangun memberi lebih perhatian kepada pelaksanaan berfungsi apabila menulis pernyataan SQL, apabila sistem aplikasi dilancarkan secara rasmi. sebagai data pengeluaran Dengan pertumbuhan pesat dalam volum, banyak pernyataan SQL telah mula menunjukkan masalah prestasi secara beransur-ansur, dan kesannya terhadap persekitaran pengeluaran menjadi lebih besar dan lebih besar Pada masa ini, pernyataan SQL yang bermasalah ini telah menjadi hambatan keseluruhan prestasi sistem, jadi kita mesti mengoptimumkannya.
2. Gunakan perintah status show untuk memahami kekerapan pelaksanaan pelbagai SQL
Selepas klien MySQL berjaya disambungkan, anda boleh memberikan maklumat status pelayan melalui status [sesi|global] rancangan perintah, atau anda boleh Gunakan perintah mysqladmin extended-status pada sistem pengendalian untuk mendapatkan mesej ini. menunjukkan status [sesi|global] boleh menambah parameter "session" atau "global" seperti yang diperlukan untuk memaparkan keputusan statistik pada peringkat sesi (sambungan semasa) dan keputusan statistik di peringkat global (sejak kali terakhir pangkalan data dimulakan ). Jika tidak ditulis, parameter lalai ialah "sesi".
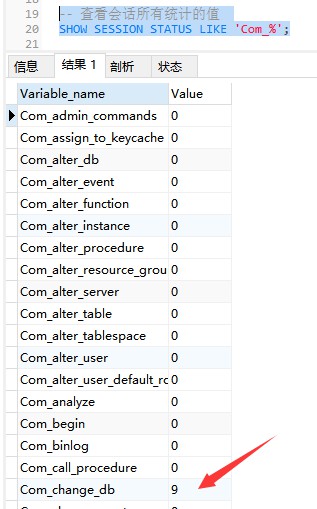
Arahan berikut memaparkan nilai semua parameter statistik dalam sesi semasa:
-- 查看会话所有统计的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
Arahan berikut memaparkan nilai semua statistik parameter dalam global semasa:
--Lihat nilai semua statistik global
SHOW GLOBAL STATUS LIKE 'Com_%';
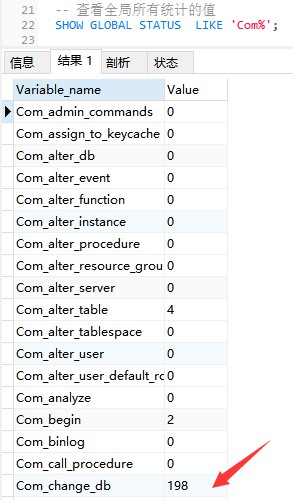
Com_xxx mewakili bilangan kali setiap pernyataan xxx dilaksanakan . Kami biasanya mengambil berat tentang Parameter statistik berikut:
Com_select: Bilangan kali untuk melakukan operasi PILIH, hanya 1 akan terkumpul untuk satu pertanyaan.
Com_insert: Bilangan kali operasi INSERT dilakukan Untuk operasi INSERT masukkan kelompok, hanya satu terkumpul.
Com_update: Bilangan kali operasi UPDATE dilakukan.
Com_delete: Bilangan kali untuk melakukan operasi DELETE.
Parameter di atas akan dikumpul untuk semua operasi jadual enjin storan. Parameter ini hanya digunakan pada enjin storan InnoDB, dan algoritma pengumpulannya sedikit berbeza.
Innodb_rows_read: Bilangan baris yang dikembalikan oleh pertanyaan SELECT.
Innodb_rows_inserted: Bilangan baris yang disisipkan dengan menjalankan operasi INSERT.
Innodb_rows_updated: Bilangan baris yang dikemas kini mengikut operasi KEMASKINI.
Innodb_rows_deleted: Bilangan baris yang dipadamkan oleh operasi DELETE.
Melalui parameter di atas, anda boleh memahami dengan mudah sama ada sistem aplikasi pangkalan data semasa terutamanya berdasarkan operasi sisipan dan kemas kini atau operasi pertanyaan, serta pelaksanaan kasar pelbagai jenis SQL Apakah nisbah. Tanpa mengira komit atau rollback, kiraan operasi kemas kini akan terkumpul dan objek kiraan ialah bilangan pelaksanaan.
Untuk aplikasi transaksi, Com_commit dan Com_rollback boleh digunakan untuk memahami penyerahan transaksi dan rollback Bagi pangkalan data dengan operasi rollback yang sangat kerap, ini mungkin bermakna terdapat masalah dalam penulisan aplikasi. Selain itu, parameter berikut membantu pengguna memahami situasi asas pangkalan data.
Sambungan: Bilangan percubaan untuk menyambung ke pelayan MySQL.
Masa aktif: Masa bekerja pelayan.
Slow_queries: Bilangan pertanyaan perlahan.
3 Cari pernyataan SQL dengan kecekapan pelaksanaan yang rendah
Anda boleh mencari pernyataan SQL dengan kecekapan pelaksanaan yang rendah dalam dua cara berikut.
Cari pernyataan SQL dengan kecekapan pelaksanaan yang rendah melalui log pertanyaan perlahan Apabila bermula dengan pilihan --log-slow-queries[=file_name], mysqld menulis fail yang mengandungi semua masa pelaksanaan. melebihi fail Log pernyataan SQL untuk long_query_time saat.
Log pertanyaan perlahan direkodkan selepas pertanyaan selesai, jadi apabila sistem aplikasi mencerminkan masalah kecekapan pelaksanaan, pertanyaan log pertanyaan lambat tidak dapat mengesan masalah tersebut arahan untuk melihat MySQL semasa Benang yang sedang berjalan, termasuk status benang, sama ada untuk mengunci jadual, dsb., boleh menyemak status pelaksanaan SQL dalam masa nyata, dan pada masa yang sama mengoptimumkan beberapa operasi kunci meja.
4 Analisis pelan pelaksanaan SQL yang tidak cekap melalui EXPLAIN
Selepas mencari pernyataan SQL dengan kecekapan pelaksanaan yang rendah, anda boleh menggunakan arahan EXPLAIN atau DESC untuk mendapatkan cara MySQL. dilaksanakan Maklumat pernyataan SELECT, termasuk cara jadual disambungkan dan susunan sambungan semasa pelaksanaan pernyataan SELECT Sebagai contoh, jika anda ingin mengira bilangan semua tangga inventori, anda perlu mengaitkan jadual_stok_barang dan jadual_harga_saham barang, dan lakukan operasi jumlah pada medan_harga_barangan. Pelan pelaksanaan SQL yang sepadan adalah seperti berikut:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

Seperti yang ditunjukkan dalam. rajah di atas, penjelasan ringkas bagi setiap lajur adalah seperti berikut:
select_type: mewakili jenis SELECT, nilai biasa ialah:
SIMPLE (jadual ringkas, iaitu tiada cantuman jadual atau subkueri digunakan).
PRIMER (pertanyaan utama, iaitu pertanyaan luar), UNION (pernyataan pertanyaan kedua atau seterusnya dalam UNION), ◎SUBQUERY (PILIHAN pertama dalam subquery) )tunggu.
jadual: Jadual yang mengeluarkan set hasil.
type:表示表的连接类型,性能由好到差的连接类型为:
system(表中仅有一行,即常量表)。
const(单表中最多有一个匹配行,例如primary key或者unique index)。
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
index_merge(索引合并优化)。
unique_subquery(in的后面是一个查询主键字段的子查询)。
index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
range(单表中的范围查询)。
index(对于前面的每一行,都通过查询索引来得到数据)。
all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
Extra:执行情况的说明和描述。
Using index(此值表示mysql将使用覆盖索引,以避免访问表)。
Using where(mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。“Using where”有时提示了一种可能性:查询可以从不同的索引中受益。
Using temporary(mysql 对查询结果排序时会使用临时表)。
MySQL will apply an external index sorting on the results instead of reading rows from the table in index order.。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成)。
Range checked for each record(index map: N) (没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的)。
5.确定问题并采取相应的优化措施
经过以上定位步骤,我们基本就可以分析到问题出现的原因。此时我们可以根据情况采取相应的改进措施,进行优化提高语句执行效率。
在上面的例子中,已经可以确认是goods_stock是走主键索引的,但是对goods_stock_price子表的进行了全表扫描导致效率的不理想,那么应该对goods_stock_price表的GoodsStockID字段创建索引,具体命令如下:
-- 创建索引 CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID); -- 附加删除跟查询索引语句 ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1; SHOW INDEX FROM goods_stock_price;
创建索引后,我们再看一下这条语句的执行计划,具体如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

可以发现建立索引后对goods_stock_price子表需要扫描的行数明显减少(从 3 行减少到1行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显。
Atas ialah kandungan terperinci Bagaimana untuk mengoptimumkan pernyataan SQL dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Hubungan antara pengguna dan pangkalan data MySQL
Apr 08, 2025 pm 07:15 PM
Hubungan antara pengguna dan pangkalan data MySQL
Apr 08, 2025 pm 07:15 PM
Dalam pangkalan data MySQL, hubungan antara pengguna dan pangkalan data ditakrifkan oleh kebenaran dan jadual. Pengguna mempunyai nama pengguna dan kata laluan untuk mengakses pangkalan data. Kebenaran diberikan melalui perintah geran, sementara jadual dibuat oleh perintah membuat jadual. Untuk mewujudkan hubungan antara pengguna dan pangkalan data, anda perlu membuat pangkalan data, membuat pengguna, dan kemudian memberikan kebenaran.
 Integrasi RDS MySQL dengan Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Integrasi RDS MySQL dengan Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Penyederhanaan Integrasi Data: AmazonRDSMYSQL dan Integrasi Data Integrasi Zero ETL Redshift adalah di tengah-tengah organisasi yang didorong oleh data. Proses tradisional ETL (ekstrak, menukar, beban) adalah kompleks dan memakan masa, terutamanya apabila mengintegrasikan pangkalan data (seperti Amazonrdsmysql) dengan gudang data (seperti redshift). Walau bagaimanapun, AWS menyediakan penyelesaian integrasi ETL sifar yang telah mengubah keadaan ini sepenuhnya, menyediakan penyelesaian yang mudah, hampir-sebenar untuk penghijrahan data dari RDSMYSQL ke redshift. Artikel ini akan menyelam ke integrasi RDSMYSQL Zero ETL dengan redshift, menjelaskan bagaimana ia berfungsi dan kelebihan yang dibawa kepada jurutera dan pemaju data.
 Cara Mengisi Nama Pengguna dan Kata Laluan MySQL
Apr 08, 2025 pm 07:09 PM
Cara Mengisi Nama Pengguna dan Kata Laluan MySQL
Apr 08, 2025 pm 07:09 PM
Untuk mengisi nama pengguna dan kata laluan MySQL: 1. Tentukan nama pengguna dan kata laluan; 2. Sambungkan ke pangkalan data; 3. Gunakan nama pengguna dan kata laluan untuk melaksanakan pertanyaan dan arahan.
 Pengoptimuman pertanyaan di MySQL adalah penting untuk meningkatkan prestasi pangkalan data, terutama ketika berurusan dengan set data yang besar
Apr 08, 2025 pm 07:12 PM
Pengoptimuman pertanyaan di MySQL adalah penting untuk meningkatkan prestasi pangkalan data, terutama ketika berurusan dengan set data yang besar
Apr 08, 2025 pm 07:12 PM
1. Gunakan indeks yang betul untuk mempercepatkan pengambilan data dengan mengurangkan jumlah data yang diimbas memilih*frommployeesWherElast_name = 'Smith'; Jika anda melihat lajur jadual beberapa kali, buat indeks untuk lajur tersebut. Jika anda atau aplikasi anda memerlukan data dari pelbagai lajur mengikut kriteria, buat indeks komposit 2. Elakkan pilih * Hanya lajur yang diperlukan, jika anda memilih semua lajur yang tidak diingini, ini hanya akan memakan lebih banyak pelayan dan menyebabkan pelayan melambatkan pada masa yang tinggi atau kekerapan misalnya, jadual anda
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Cara menyalin dan tampal mysql
Apr 08, 2025 pm 07:18 PM
Cara menyalin dan tampal mysql
Apr 08, 2025 pm 07:18 PM
Salin dan tampal di MySQL termasuk langkah -langkah berikut: Pilih data, salin dengan Ctrl C (Windows) atau Cmd C (Mac); Klik kanan di lokasi sasaran, pilih Paste atau gunakan Ctrl V (Windows) atau CMD V (MAC); Data yang disalin dimasukkan ke dalam lokasi sasaran, atau menggantikan data sedia ada (bergantung kepada sama ada data sudah ada di lokasi sasaran).
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
 Cara Melihat MySQL
Apr 08, 2025 pm 07:21 PM
Cara Melihat MySQL
Apr 08, 2025 pm 07:21 PM
Lihat pangkalan data MySQL dengan arahan berikut: Sambungkan ke pelayan: MySQL -U Pengguna Nama -P Kata Laluan Run Show pangkalan data; Perintah untuk mendapatkan semua pangkalan data yang sedia ada Pilih pangkalan data: Gunakan nama pangkalan data; Lihat Jadual: Tunjukkan Jadual; Lihat Struktur Jadual: Huraikan nama jadual; Lihat data: pilih * dari nama jadual;
