

Indeks berkelompok ialah struktur indeks berasaskan kunci utama yang dicipta oleh innodb secara lalai dan data dalam jadual diletakkan terus dalam indeks berkelompok sebagai halaman data nod daun:
Carian data berdasarkan kunci primer: lakukan carian binari bermula dari nod akar indeks berkelompok, cari halaman data yang sepadan di sepanjang jalan dan cari terus kunci utama data sasaran berdasarkan direktori halaman.
Jika anda ingin mengindeks medan lain, atau membuat indeks bersama berdasarkan berbilang medan, apakah struktur indeksnya?
Dengan mengandaikan bahawa medan lain diindeks, seperti nama, umur, dsb., prinsip yang sama digunakan. Contohnya, apabila anda memasukkan data:
Masukkan data lengkap ke dalam halaman data nod daun indeks berkelompok dan mengekalkan indeks berkelompok pada masa yang sama
Untuk indeks yang dibuat untuk medan anda yang lain, buat semula pepohon B+
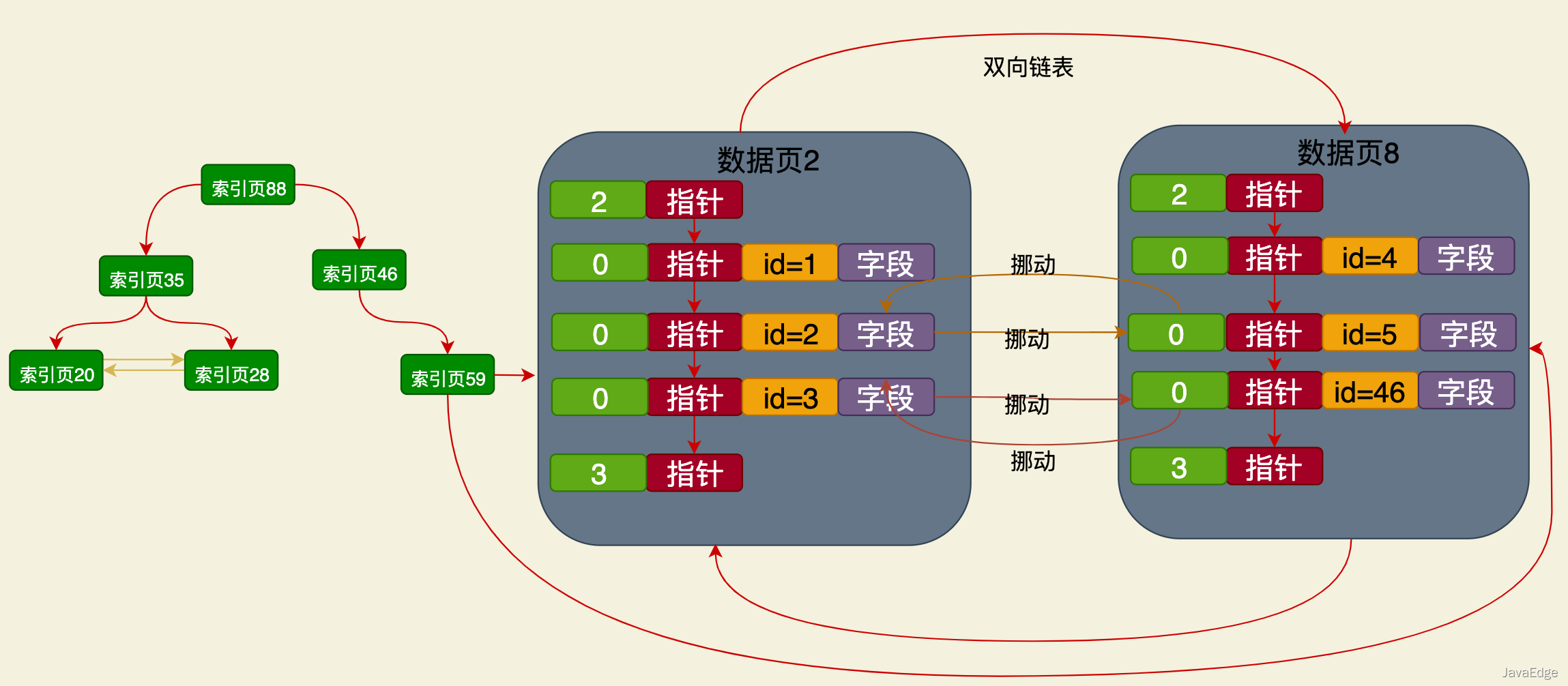
Sebagai contoh, jika anda mencipta indeks berdasarkan medan nama, apabila data dimasukkan, pokok B+ akan dibuat semula , nod daun pokok B+ juga merupakan halaman data, tetapi hanya medan kunci utama dan medan nama diletakkan dalam halaman data ini:
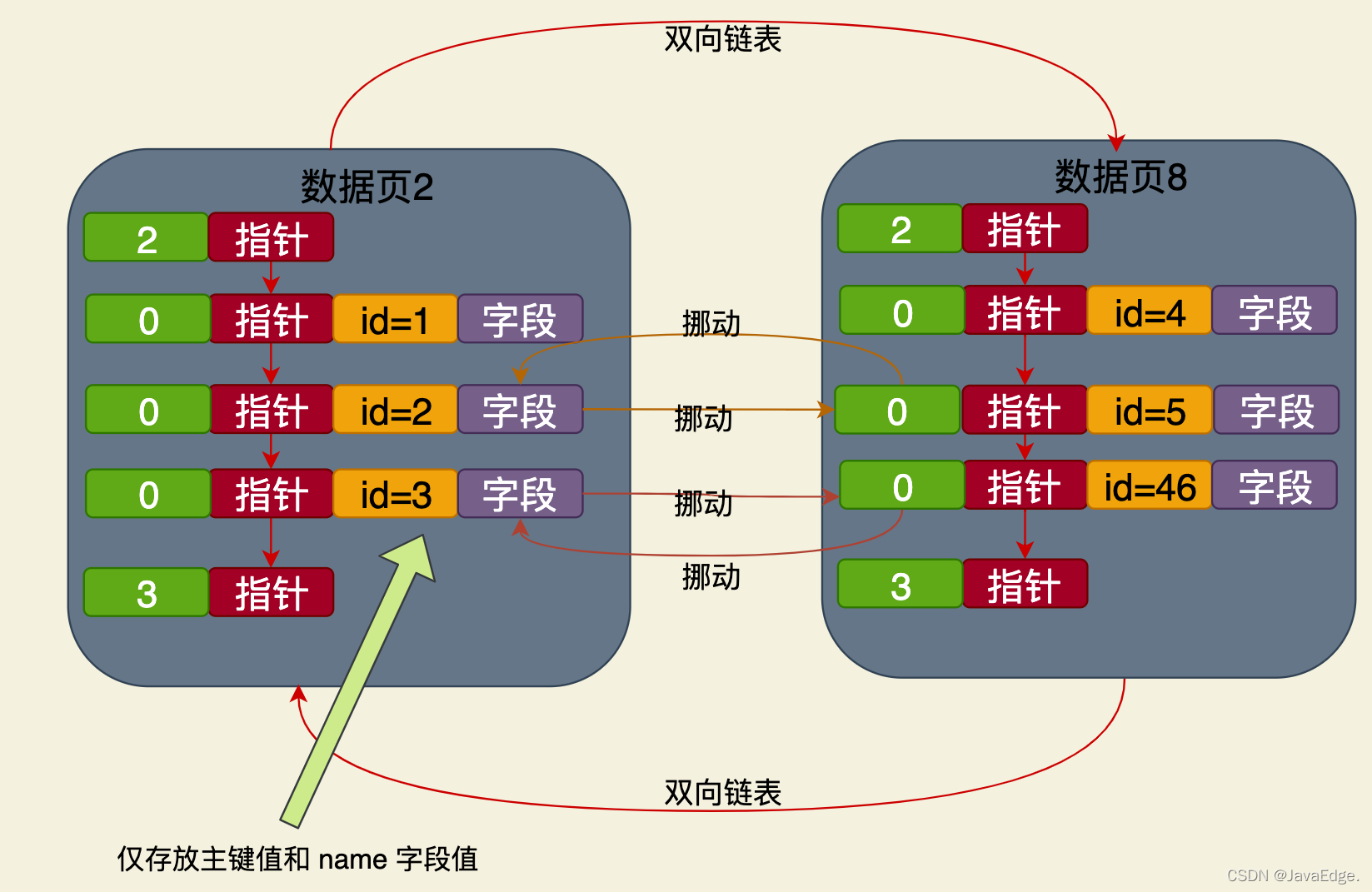
Ini ialah medan nama berdasarkan pepohon B+ yang tidak bergantung pada kluster Struktur indeks indeks kluster, data yang disimpan dalam nod daunnya hanya mengandungi nilai kunci primer dan medan nama.
Peraturan pengisihan keseluruhan adalah sama dengan peraturan pengisihan indeks berkelompok mengikut kunci utama, iaitu:
Nilai nama dalam data halaman nod daun semuanya diisih
Nilai medan nama dalam halaman data seterusnya ialah > nilai medan nama dalam halaman data sebelumnya
Pokok indeks B+ medan nama juga Halaman indeks berbilang peringkat akan dibina halaman indeks:
Nombor halaman peringkat seterusnya
<.>select * from t where name='xx'
boleh dikeluarkan. select *
Atas ialah kandungan terperinci Apakah proses pertanyaan indeks sekunder MySQL?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



