

Indeks berkelompok membina pepohon B+ berdasarkan kunci utama setiap jadual, dan data rekod baris bagi keseluruhan jadual disimpan dalam nod daun.
Sebagai contoh, mari kita rasakan indeks berkelompok secara intuitif.
Buat jadual t dan benarkan setiap halaman untuk menyimpan hanya dua rekod baris (saya tidak tahu cara mengawal hanya dua rekod baris setiap halaman secara buatan):
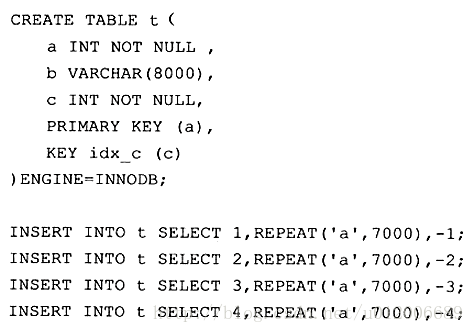
Akhirnya, pengarang "MySQL Technology Insider" memperoleh struktur kasar pokok indeks berkelompok ini melalui alat analisis seperti berikut:
Nod daun berkelompok indeks dirujuk sebagai halaman data, setiap satu daripadanya dipautkan oleh senarai pautan berganda, dan halaman data disusun mengikut susunan kunci utama..
Seperti yang ditunjukkan dalam rajah, setiap halaman data menyimpan rekod baris yang lengkap, manakala dalam halaman indeks halaman bukan data, hanya nilai kunci dan offset yang menunjuk ke halaman data yang disimpan Bukan a rekod talian lengkap.
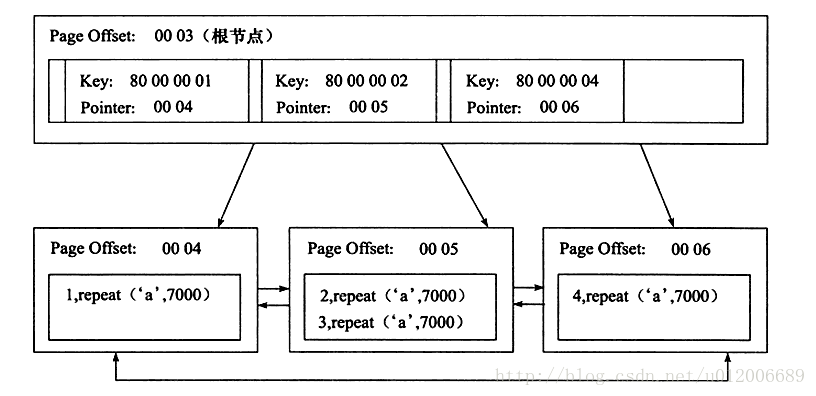
Jika kunci primer ditakrifkan, InnoDB akan menggunakan kunci primer secara automatik untuk mencipta indeks berkelompok. Apabila tiada kunci utama ditentukan, InnoDB akan memilih indeks yang unik dan tidak kosong untuk berfungsi sebagai kunci utama. InnoDB secara tersirat akan mentakrifkan kunci utama sebagai indeks berkelompok jika tiada indeks bukan nol yang unik.
Indeks tambahan, juga dipanggil indeks bukan berkelompok. Berbanding dengan indeks berkelompok, nod daun tidak mengandungi semua data rekod baris. Selain nilai kunci, baris indeks nod daun juga mengandungi penanda halaman (penanda halaman), yang digunakan untuk memberitahu InnoDB tempat untuk mencari data baris yang sepadan dengan indeks.
Mari kita gunakan contoh dalam "MySQL Technology Insider" untuk merasai secara intuitif rupa indeks tambahan.
Masih mengambil jadual t di atas sebagai contoh, buat indeks tidak berkelompok pada lajur c:
Kemudian penulis memperoleh indeks tambahan dan indeks berkelompok melalui kerja analisis Gambarajah perhubungan:
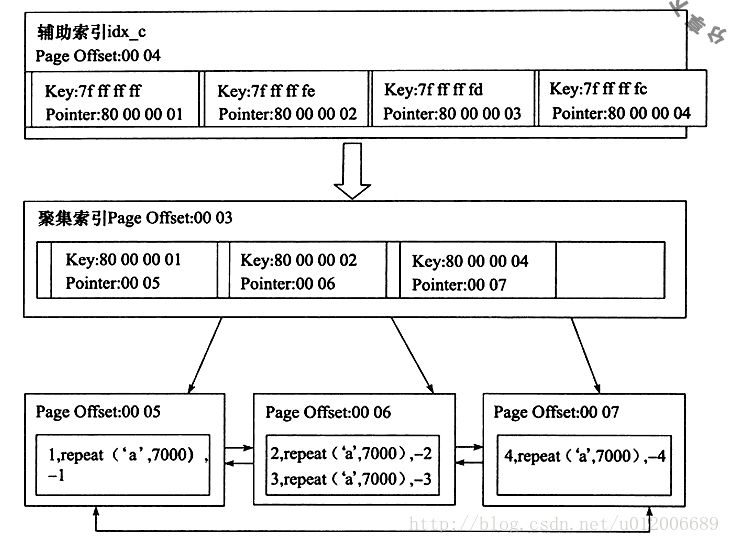
Anda dapat melihat bahawa nod daun indeks tambahan idx_c mengandungi nilai lajur c dan nilai kunci primer.
Sebagai contoh, anggap bahawa nilai Kunci ialah 0x7fffffff, di mana perwakilan binari 7 ialah 0111 dan 0 ialah nombor negatif. Nilai integer sebenar hendaklah diterbalikkan tambah 1, jadi hasilnya ialah -1, dan ini ialah nilai dalam lajur c. Nilai kunci utama ialah nombor positif 1, diwakili oleh nilai penunjuk 80000001, di mana 8 bit mewakili nombor binari 1000.
Menggunakan enjin storan InnoDB, anda boleh menutup indeks melalui indeks tambahan dan mendapatkan rekod pertanyaan secara langsung tanpa menanyakan rekod dalam indeks berkelompok.
Apakah faedah menggunakan indeks penutup?
boleh mengurangkan sebilangan besar operasi IO
Kami tahu dari gambar di atas bahawa jika kami ingin menanyakan medan yang tidak termasuk dalam bantuan indeks, kita mesti terlebih dahulu merentasi indeks Auxiliary, dan kemudian melintasi indeks berkelompok Jika nilai medan yang ingin ditanya wujud dalam indeks tambahan, tidak perlu menyemak indeks berkelompok, yang jelas akan mengurangkan operasi IO.
Sebagai contoh, dalam gambar di atas, sql berikut boleh terus menggunakan indeks tambahan,
select a from where c = -2;
membantu untuk statistik
dengan mengandaikan terdapat Seperti yang ditunjukkan dalam jadual berikut:
CREATE TABLE `student` ( `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `age` varchar(255) NOT NULL, `school` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_school_age` (`school`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Jika dilaksanakan pada jadual ini:
select count(*) from student
Apakah yang akan dilakukan oleh pengoptimum?
Pengoptimum akan memilih indeks tambahan untuk statistik, kerana walaupun keputusan boleh diperolehi dengan merentasi kedua-dua indeks berkelompok dan indeks tambahan, saiz indeks tambahan jauh lebih kecil daripada indeks berkelompok. Jalankan arahan explain:

kunci dan Tambahan menunjukkan bahawa indeks tambahan idx_name digunakan.
Juga, anggap sql berikut dilaksanakan:
select * from student where age > 10 and age < 15
Oleh kerana susunan medan indeks bersama idx_school_age ialah sekolah pertama dan kemudian umur, pertanyaan bersyarat adalah berdasarkan umur, biasanya tanpa pengindeksan :

Walau bagaimanapun, jika syarat kekal tidak berubah, tanya semua medan daripada menanyakan bilangan entri:
select count(*) from student where age > 10 and age < 15
Pengoptimum akan memilih indeks bersama ini:

Indeks bersama merujuk kepada pengindeksan berbilang lajur pada jadual.
Berikut ialah contoh mencipta indeks bersama idx_a_b:

Struktur dalaman indeks sendi:
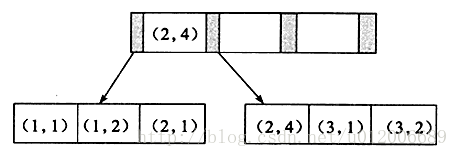
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较a再比较b的顺序排列。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select * from table where a=xxx and b=xxx ; select * from table where a=xxx;
但是对于下面的sql是不能使用这个联合索引的,因为叶子节点的b值,1,2,1,4,1,2显然不是排序的。
select * from table where b=xxx
联合索引的第二个好处是对第二个键值已经做了排序。举个例子:
create table buy_log(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
insert into buy_log values(1, '2009-01-01');
insert into buy_log values(2, '2009-02-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid, buy_date);当执行
select * from buy_log where user_id = 2;
时,优化器会选择key(userid);但是当执行以下sql:
select * from buy_log where user_id = 2 order by buy_date desc;
时,优化器会选择key(userid, buy_date),因为buy_date是在userid排序的基础上做的排序。
如果把key(userid,buy_date)删除掉,再执行:
select * from buy_log where user_id = 2 order by buy_date desc;
优化器会选择key(userid),但是对查询出来的结果会进行一次filesort,即按照buy_date重新排下序。所以联合索引的好处在于可以避免filesort排序。
Atas ialah kandungan terperinci Cara menggunakan indeks berkelompok, indeks tambahan, indeks meliputi dan indeks bersama dalam mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



