

Bagaimana untuk mengoptimumkan ruang cache Redis

Tetapan adegan
1. Kita perlu menyimpan POJO dalam cache Kelas ditakrifkan seperti berikut
public class TestPOJO implements Serializable {
private String testStatus;
private String userPin;
private String investor;
private Date testQueryTime;
private Date createTime;
private String bizInfo;
private Date otherTime;
private BigDecimal userAmount;
private BigDecimal userRate;
private BigDecimal applyAmount;
private String type;
private String checkTime;
private String preTestStatus;
public Object[] toValueArray(){
Object[] array = {testStatus, userPin, investor, testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, checkTime, preTestStatus};
return array;
}
public CreditRecord fromValueArray(Object[] valueArray){
//具体的数据类型会丢失,需要做处理
}
}2
TestPOJO pojo = new TestPOJO();
pojo.setApplyAmount(new BigDecimal("200.11"));
pojo.setBizInfo("XX");
pojo.setUserAmount(new BigDecimal("1000.00"));
pojo.setTestStatus("SUCCESS");
pojo.setCheckTime("2023-02-02");
pojo.setInvestor("ABCD");
pojo.setUserRate(new BigDecimal("0.002"));
pojo.setTestQueryTime(new Date());
pojo.setOtherTime(new Date());
pojo.setPreTestStatus("PROCESSING");
pojo.setUserPin("ABCDEFGHIJ");
pojo.setType("Y");Amalan am
System.out.println(JSON.toJSONString(pojo).length());
Gunakan JSON untuk terus bersiri dan mencetak panjang=284**, **Kaedah ini adalah cara paling mudah , yang juga merupakan kaedah yang paling biasa digunakan. Data khusus adalah seperti berikut:
{"applyAmount":200.11,"bizInfo":"XX","checkTime":"2023-02-02"," pelabur":"ABCD ","otherTime":"2023-04-10 17:45:17.717","preCheckStatus":"PROCESSING","testQueryTime":"2023-04-10 17:45:17.717"," testStatus":"SUCCESS ","type":"Y","userAmount":1000.00,"userPin":"ABCDEFGHIJ","userRate":0.002}
Kami mendapati bahawa perkara di atas mengandungi banyak data tidak berguna, termasuk nama atribut Tidak perlu menyimpannya.
Penambahbaikan 1-Alih keluar nama atribut
System.out.println(JSON.toJSONString(pojo.toValueArray()).length());
Dengan memilih struktur tatasusunan dan bukannya struktur objek, nama atribut dialih keluar, cetak panjang=144 , dan Saiz data telah dikurangkan sebanyak 50%. Data khusus adalah seperti berikut:
["SUCCESS","ABCDEFGHIJ","ABCD","2023-04-10 17:45 :17.717",null,"XX"," 2023-04-10 17:45:17.717",1000.00,0.002,200.11,"Y","2023-02-02","PROSES"]
Kami mendapati bahawa tidak ada keperluan untuk menyimpan format masa bersiri ke dalam rentetan hasil bersiri yang tidak munasabah membawa kepada pengembangan data, jadi kami harus memilih alat bersiri yang lebih baik.
Penambahbaikan 2-Gunakan alat pesiri yang lebih baik
//我们仍然选取JSON格式,但使用了第三方序列化工具 System.out.println(new ObjectMapper(new MessagePackFactory()).writeValueAsBytes(pojo.toValueArray()).length);
Pilih alat pesiri yang lebih baik untuk mencapai pemampatan medan dan format data yang munasabah, cetak** panjang=92, ruang dikurangkan sebanyak 40% berbanding dengan langkah sebelumnya.
Ini ialah sekeping data binari yang perlu dikendalikan dalam binari Selepas menukar binari kepada rentetan, cetaknya seperti berikut:
��SUCCESS�ABCDEFGHIJ�ABCD� �. j�6� �XX� �j�6� �?`bM���@i � �Q�Y�2023-02-02�PEMPROSESAN
Ikuti idea ini dengan lebih lanjut Menggali, kami mendapati bahawa kami boleh mencapai lebih banyak kesan pengoptimuman yang melampau dengan memilih jenis data secara manual Memilih untuk menggunakan jenis data yang lebih kecil akan mencapai peningkatan selanjutnya.
Penambahbaikan 3-Optimumkan jenis data
Dalam kes penggunaan di atas, tiga medan testStatus, preCheckStatus dan pelabur sebenarnya adalah jenis rentetan yang disenaraikan jika anda boleh Menggunakan lebih mudah jenis data (seperti bait atau int, dsb.) dan bukannya rentetan boleh menjimatkan ruang lagi. Anda boleh menggunakan jenis Long dan bukannya rentetan untuk mewakili checkTime, supaya alat pensirian mengeluarkan lebih sedikit bait.
public Object[] toValueArray(){
Object[] array = {toInt(testStatus), userPin, toInt(investor), testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, toLong(checkTime), toInt(preTestStatus)};
return array;
}Selepas pelarasan manual, jenis data yang lebih kecil digunakan dan bukannya jenis Rentetan, mencetakpanjang=69
Penambahbaikan 4-Pertimbangkan pemampatan ZIP
Selain daripada perkara di atas, anda juga boleh mempertimbangkan untuk menggunakan pemampatan ZIP untuk mendapatkan volum yang lebih kecil Apabila kandungannya besar atau berulang, kesan pemampatan ZIP adalah jelas Jika anda menyimpan Kandungan adalah tatasusunan daripada TestPOJO, mungkin sesuai untuk digunakan dengan pemampatan ZIP.
Untuk fail yang lebih kecil daripada 30 bait, pemampatan ZIP boleh meningkatkan saiz fail tetapi tidak semestinya mengurangkan saiz fail. Dalam kes kandungan yang kurang berulang, tiada peningkatan yang ketara boleh diperolehi. Dan terdapat overhed CPU.
Selepas pengoptimuman di atas, pemampatan ZIP bukan lagi pilihan yang diperlukan Ujian berdasarkan data sebenar diperlukan untuk menentukan kesan pemampatan ZIP.
Akhirnya dilaksanakan
Langkah penambahbaikan di atas mencerminkan idea pengoptimuman, tetapi proses penyahserikatan akan membawa kepada kehilangan jenis, yang lebih rumit untuk dikendalikan, jadi Kami juga perlu mengambil kira isu penyahserialisasian.
Apabila objek cache dipratentukan, kami boleh memproses sepenuhnya setiap medan secara manual Oleh itu, dalam pertempuran sebenar, adalah disyorkan untuk menggunakan siri manual untuk mencapai tujuan di atas, mencapai kawalan yang diperhalusi dan mencapai pemampatan terbaik. kesan dan overhed prestasi minimum.
Anda boleh merujuk kepada kod pelaksanaan msgpack berikut Kod ujian Sila pakejkan alat Packer dan UnPacker yang lebih baik sendiri:
<dependency>
<groupId>org.msgpack</groupId>
<artifactId>msgpack-core</artifactId>
<version>0.9.3</version>
</dependency> public byte[] toByteArray() throws Exception {
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker();
toByteArray(packer);
packer.close();
return packer.toByteArray();
}
public void toByteArray(MessageBufferPacker packer) throws Exception {
if (testStatus == null) {
packer.packNil();
}else{
packer.packString(testStatus);
}
if (userPin == null) {
packer.packNil();
}else{
packer.packString(userPin);
}
if (investor == null) {
packer.packNil();
}else{
packer.packString(investor);
}
if (testQueryTime == null) {
packer.packNil();
}else{
packer.packLong(testQueryTime.getTime());
}
if (createTime == null) {
packer.packNil();
}else{
packer.packLong(createTime.getTime());
}
if (bizInfo == null) {
packer.packNil();
}else{
packer.packString(bizInfo);
}
if (otherTime == null) {
packer.packNil();
}else{
packer.packLong(otherTime.getTime());
}
if (userAmount == null) {
packer.packNil();
}else{
packer.packString(userAmount.toString());
}
if (userRate == null) {
packer.packNil();
}else{
packer.packString(userRate.toString());
}
if (applyAmount == null) {
packer.packNil();
}else{
packer.packString(applyAmount.toString());
}
if (type == null) {
packer.packNil();
}else{
packer.packString(type);
}
if (checkTime == null) {
packer.packNil();
}else{
packer.packString(checkTime);
}
if (preTestStatus == null) {
packer.packNil();
}else{
packer.packString(preTestStatus);
}
}
public void fromByteArray(byte[] byteArray) throws Exception {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(byteArray);
fromByteArray(unpacker);
unpacker.close();
}
public void fromByteArray(MessageUnpacker unpacker) throws Exception {
if (!unpacker.tryUnpackNil()){
this.setTestStatus(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setUserPin(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setInvestor(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setTestQueryTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setCreateTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setBizInfo(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setOtherTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setUserAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setUserRate(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setApplyAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setType(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setCheckTime(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setPreTestStatus(unpacker.unpackString());
}
}Pelanjutan adegan
Andaikan kami menyimpan data untuk 200 juta pengguna Setiap pengguna mengandungi 40 medan Panjang kunci medan ialah 6 bait, dan medan diurus secara berasingan. Dalam keadaan biasa, kita akan memikirkan struktur cincang, dan struktur cincang menyimpan maklumat utama, yang akan menduduki sumber tambahan Kunci medan adalah data yang tidak diperlukan, senarai boleh digunakan dan bukannya cincang struktur. Melalui ujian alat rasmi Redis, menggunakan struktur senarai memerlukan 144G ruang, manakala menggunakan struktur cincang memerlukan 245G ruang** (Apabila lebih daripada 50% atribut kosong, ujian perlu dijalankan untuk melihat sama ada ia masih terpakai)* *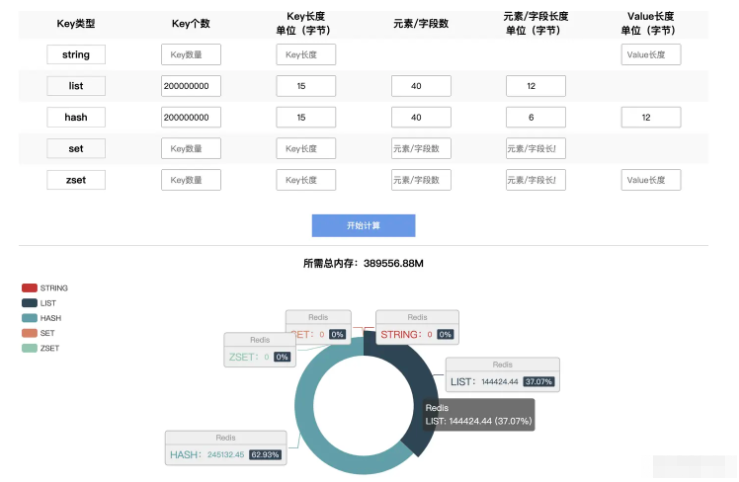
• Gunakan tatasusunan untuk menggantikan objek (jika sebilangan besar medan kosong, anda perlu menggunakan alat bersiri untuk memampatkan nol)
• Gunakan jenis data yang lebih kecil
• Pertimbangkan untuk menggunakan pemampatan ZIP
•
Atas ialah kandungan terperinci Bagaimana untuk mengoptimumkan ruang cache Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Mod Redis cluster menyebarkan contoh Redis ke pelbagai pelayan melalui sharding, meningkatkan skalabilitas dan ketersediaan. Langkah -langkah pembinaan adalah seperti berikut: Buat contoh Redis ganjil dengan pelabuhan yang berbeza; Buat 3 contoh sentinel, memantau contoh redis dan failover; Konfigurasi fail konfigurasi sentinel, tambahkan pemantauan maklumat contoh dan tetapan failover; Konfigurasi fail konfigurasi contoh Redis, aktifkan mod kluster dan tentukan laluan fail maklumat kluster; Buat fail nodes.conf, yang mengandungi maklumat setiap contoh Redis; Mulakan kluster, laksanakan perintah Buat untuk membuat kluster dan tentukan bilangan replika; Log masuk ke kluster untuk melaksanakan perintah maklumat kluster untuk mengesahkan status kluster; buat
 Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Menggunakan Arahan Redis memerlukan langkah -langkah berikut: Buka klien Redis. Masukkan arahan (nilai kunci kata kerja). Menyediakan parameter yang diperlukan (berbeza dari arahan ke arahan). Tekan Enter untuk melaksanakan arahan. Redis mengembalikan tindak balas yang menunjukkan hasil operasi (biasanya OK atau -r).
 Cara Melihat Semua Kekunci di Redis
Apr 10, 2025 pm 07:15 PM
Cara Melihat Semua Kekunci di Redis
Apr 10, 2025 pm 07:15 PM
Untuk melihat semua kunci di Redis, terdapat tiga cara: Gunakan perintah kunci untuk mengembalikan semua kunci yang sepadan dengan corak yang ditentukan; Gunakan perintah imbasan untuk melangkah ke atas kunci dan kembalikan satu set kunci; Gunakan arahan maklumat untuk mendapatkan jumlah kunci.
 Cara melaksanakan redis yang mendasari
Apr 10, 2025 pm 07:21 PM
Cara melaksanakan redis yang mendasari
Apr 10, 2025 pm 07:21 PM
Redis menggunakan jadual hash untuk menyimpan data dan menyokong struktur data seperti rentetan, senarai, jadual hash, koleksi dan koleksi yang diperintahkan. Redis berterusan data melalui snapshots (RDB) dan menambah mekanisme tulis sahaja (AOF). Redis menggunakan replikasi master-hamba untuk meningkatkan ketersediaan data. Redis menggunakan gelung acara tunggal untuk mengendalikan sambungan dan arahan untuk memastikan atom dan konsistensi data. Redis menetapkan masa tamat tempoh untuk kunci dan menggunakan mekanisme memadam malas untuk memadamkan kunci tamat tempoh.
 Cara Melaksanakan Kaunter Redis
Apr 10, 2025 pm 10:21 PM
Cara Melaksanakan Kaunter Redis
Apr 10, 2025 pm 10:21 PM
Kaunter Redis adalah satu mekanisme yang menggunakan penyimpanan pasangan nilai utama REDIS untuk melaksanakan operasi pengiraan, termasuk langkah-langkah berikut: mewujudkan kekunci kaunter, meningkatkan tuduhan, mengurangkan tuduhan, menetapkan semula, dan mendapatkan tuduhan. Kelebihan kaunter Redis termasuk kelajuan cepat, konkurensi tinggi, ketahanan dan kesederhanaan dan kemudahan penggunaan. Ia boleh digunakan dalam senario seperti pengiraan akses pengguna, penjejakan metrik masa nyata, skor permainan dan kedudukan, dan pengiraan pemprosesan pesanan.
 Cara menggunakan kunci redis
Apr 10, 2025 pm 08:39 PM
Cara menggunakan kunci redis
Apr 10, 2025 pm 08:39 PM
Menggunakan REDIS untuk mengunci operasi memerlukan mendapatkan kunci melalui arahan SETNX, dan kemudian menggunakan perintah luput untuk menetapkan masa tamat tempoh. Langkah-langkah khusus adalah: (1) Gunakan arahan SETNX untuk cuba menetapkan pasangan nilai utama; (2) Gunakan perintah luput untuk menetapkan masa tamat tempoh untuk kunci; (3) Gunakan perintah DEL untuk memadam kunci apabila kunci tidak lagi diperlukan.
 Apa yang perlu dilakukan sekiranya pelayan redis tidak dapat dijumpai
Apr 10, 2025 pm 06:54 PM
Apa yang perlu dilakukan sekiranya pelayan redis tidak dapat dijumpai
Apr 10, 2025 pm 06:54 PM
Langkah-langkah untuk menyelesaikan masalah yang tidak dapat dijumpai oleh Redis-Server: periksa pemasangan untuk memastikan Redis dipasang dengan betul; Tetapkan pembolehubah persekitaran redis_host dan redis_port; Mulakan Redis Server Redis-server; Semak sama ada pelayan sedang menjalankan ping redis-cli.
 Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Langkah -langkah untuk memulakan pelayan Redis termasuk: Pasang Redis mengikut sistem operasi. Mulakan perkhidmatan Redis melalui Redis-server (Linux/macOS) atau redis-server.exe (Windows). Gunakan redis-cli ping (linux/macOS) atau redis-cli.exe ping (windows) perintah untuk memeriksa status perkhidmatan. Gunakan klien Redis, seperti redis-cli, python, atau node.js untuk mengakses pelayan.
