
 Peranti teknologi
AI
Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
Peranti teknologi
AI
Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL

Model pembelajaran mendalam untuk tugas visual (seperti klasifikasi imej) biasanya dilatih hujung-ke-hujung dengan data daripada domain visual tunggal (seperti imej semula jadi atau imej yang dijana komputer).
Secara amnya, aplikasi yang melengkapkan tugasan visual untuk berbilang medan perlu membina berbilang model untuk setiap medan berasingan dan melatihnya secara bebas, tanpa berkongsi data antara medan berbeza , pada masa inferens, setiap satu model akan memproses data input khusus domain.
Walaupun ia berorientasikan kepada bidang yang berbeza, beberapa ciri lapisan awal antara model ini adalah serupa, jadi latihan bersama model ini adalah lebih cekap. Ini mengurangkan kependaman dan penggunaan kuasa, dan mengurangkan kos memori untuk menyimpan setiap parameter model Pendekatan ini dipanggil pembelajaran berbilang domain (MDL).
Selain itu, model MDL juga boleh menjadi lebih baik daripada model domain tunggal Latihan tambahan dalam satu domain boleh meningkatkan prestasi model dalam domain lain. Ini dipanggil "pengetahuan hadapan". Pemindahan", tetapi mungkin juga menghasilkan pemindahan pengetahuan negatif, bergantung pada kaedah latihan dan gabungan domain tertentu. Walaupun kerja terdahulu mengenai MDL telah menunjukkan keberkesanan tugas pembelajaran bersama merentas domain, ia melibatkan seni bina model buatan tangan yang tidak cekap apabila digunakan pada kerja lain.

Pautan kertas: https://arxiv.org/pdf/2010.04904.pdf
Untuk menyelesaikan masalah ini, dalam artikel "Rangkaian Neural Berbilang Laluan untuk Klasifikasi Visual Berbilang Domain Pada Peranti", penyelidik Google mencadangkan model MDL umum.
Artikel itu menyatakan bahawa model boleh mencapai ketepatan tinggi secara berkesan, mengurangkan pemindahan pengetahuan negatif, dan belajar untuk meningkatkan pemindahan pengetahuan yang positif, dalam menangani kesukaran dalam pelbagai bidang tertentu model boleh dioptimumkan dengan berkesan.
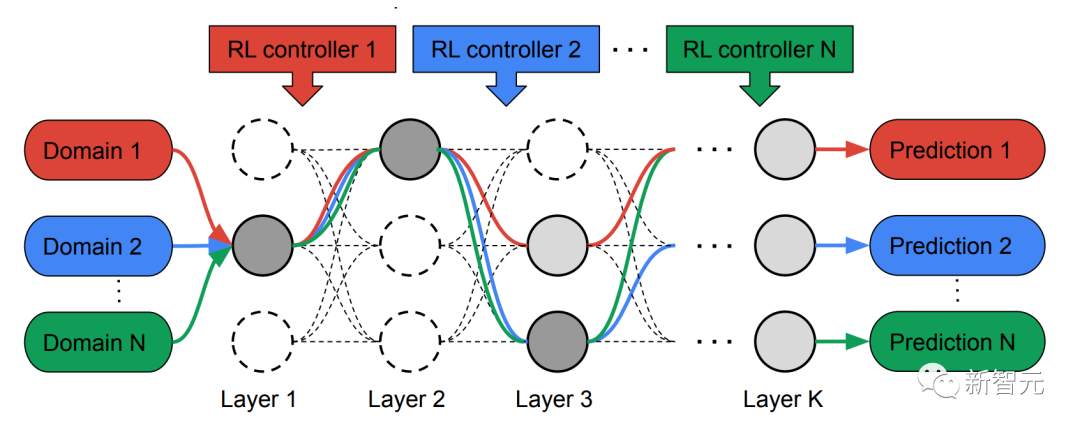
Untuk tujuan ini, penyelidik mencadangkan kaedah carian seni bina saraf berbilang laluan (MPNAS) untuk membina berbilang- domain Model bersatu dengan seni bina rangkaian heterogen.
Kaedah ini memanjangkan kaedah carian seni bina saraf (NAS) yang cekap daripada carian satu laluan kepada carian berbilang laluan untuk bersama-sama mencari laluan optimum bagi setiap medan. Fungsi kehilangan baharu turut diperkenalkan, dipanggil Pengutamaan Domain Seimbang Adaptif (ABDP), yang menyesuaikan diri dengan kesukaran khusus domain untuk membantu melatih model dengan cekap. Kaedah MPNAS yang terhasil adalah cekap dan berskala.
Sambil mengekalkan prestasi, model baharu ini mengurangkan saiz model dan FLOPS masing-masing sebanyak 78% dan 32% berbanding kaedah domain tunggal.
Carian struktur saraf berbilang laluan
Untuk menggalakkan pemindahan pengetahuan positif dan mengelakkan pemindahan negatif, penyelesaian tradisional adalah untuk mewujudkan model MDL supaya semua domain boleh kongsikannya Kebanyakan lapisan mempelajari ciri yang dikongsi setiap domain (dipanggil pengekstrakan ciri), dan kemudian membina beberapa lapisan khusus domain di atas. Walau bagaimanapun, kaedah pengekstrakan ciri ini tidak dapat mengendalikan domain dengan ciri yang berbeza secara ketara (seperti objek dalam imej semula jadi dan lukisan artistik). Sebaliknya, membina struktur heterogen bersatu untuk setiap model MDL memakan masa dan memerlukan pengetahuan khusus domain.
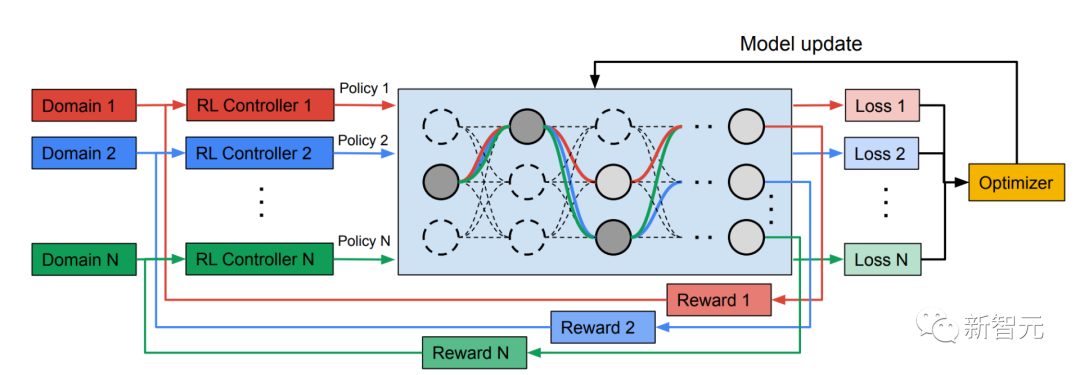
Rangka kerja seni bina carian saraf berbilang laluan NAS ialah paradigma yang berkuasa untuk mereka bentuk pembelajaran mendalam secara automatik seni bina. Ia mentakrifkan ruang carian yang terdiri daripada pelbagai blok binaan berpotensi yang mungkin menjadi sebahagian daripada model akhir.
Algoritma carian mencari seni bina calon terbaik daripada ruang carian untuk mengoptimumkan matlamat model, seperti ketepatan pengelasan. Kaedah NAS terkini seperti TuNAS meningkatkan kecekapan carian dengan menggunakan pensampelan laluan hujung ke hujung.
Diinspirasikan oleh TuNAS, MPNAS mewujudkan seni bina model MDL dalam dua peringkat: pencarian dan latihan.
Dalam fasa carian, untuk bersama-sama mencari laluan optimum untuk setiap domain, MPNAS mencipta pengawal pembelajaran tetulang (RL) berasingan untuk setiap domain, yang diperoleh daripada rangkaian super (iaitu ditakrifkan oleh carian ruang Contoh laluan hujung ke hujung (dari lapisan input ke lapisan keluaran) daripada superset semua subrangkaian yang mungkin antara nod calon).
Melalui berbilang lelaran, semua pengawal RL mengemas kini laluan untuk mengoptimumkan ganjaran RL dalam semua kawasan. Pada akhir fasa carian, kami memperoleh subrangkaian untuk setiap domain. Akhir sekali, semua sub-rangkaian digabungkan untuk mencipta struktur heterogen untuk model MDL, seperti yang ditunjukkan dalam rajah di bawah.
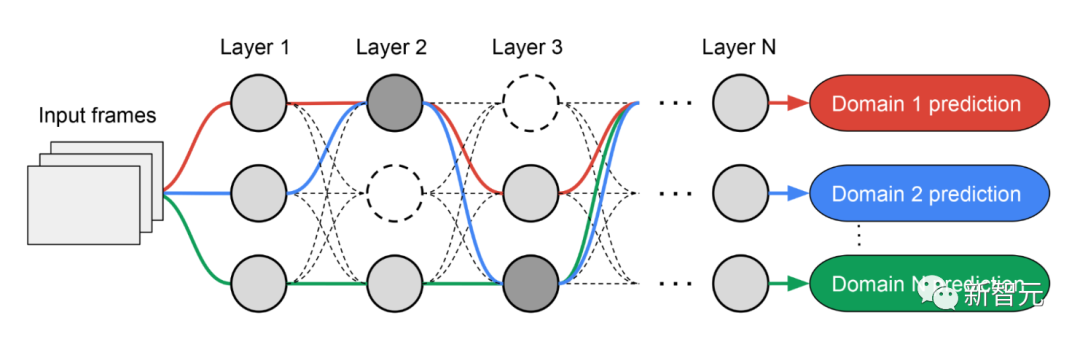
Memandangkan subrangkaian setiap domain dicari secara berasingan, setiap lapisan Komponen boleh dikongsi oleh berbilang domain (iaitu nod kelabu gelap), digunakan oleh satu domain (iaitu nod kelabu muda), atau tidak digunakan oleh mana-mana subrangkaian (iaitu nod titik).
Laluan setiap domain juga boleh melangkau mana-mana lapisan semasa proses carian. Rangkaian keluaran adalah heterogen dan cekap, memandangkan subrangkaian bebas untuk memilih blok mana yang hendak digunakan sepanjang perjalanan dengan cara yang mengoptimumkan prestasi.
Rajah berikut menunjukkan seni bina carian dua medan Visual Domain Decathlon.
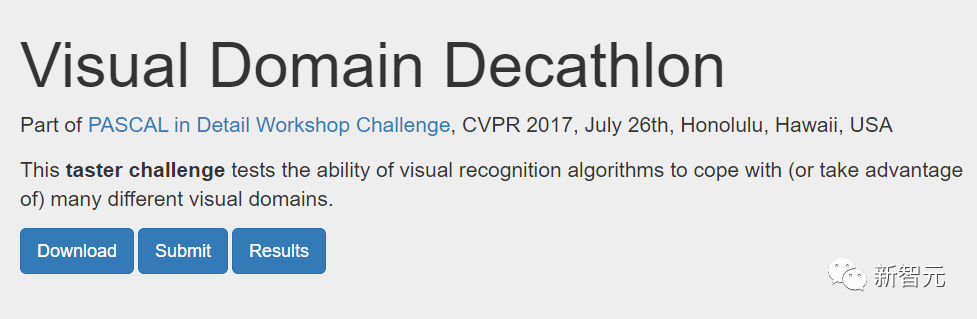
Dekatlon Domain Visual telah diuji sebagai sebahagian daripada Cabaran Bengkel Perincian PASCAL di CVPR 2017 Keupayaan algoritma pengecaman visual untuk memproses (atau mengeksploitasi) banyak domain visual yang berbeza. Seperti yang dapat dilihat, subrangkaian dua domain yang sangat berkaitan ini (satu merah, satu lagi hijau) berkongsi sebahagian besar blok binaan daripada laluan bertindih mereka, tetapi masih terdapat perbezaan di antara mereka.
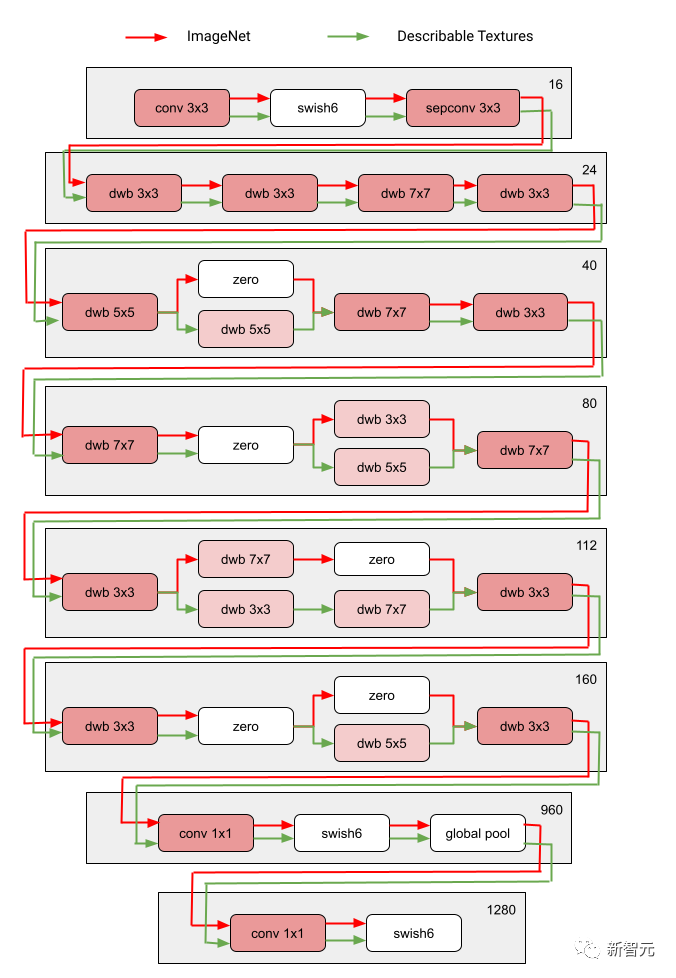
Laluan merah dan hijau dalam rajah masing-masing mewakili subrangkaian ImageNet dan Tekstur Boleh Diterangkan, dan nod merah jambu gelap mewakili blok yang dikongsi oleh berbilang domain , nod merah jambu muda mewakili blok yang digunakan oleh setiap laluan. Blok "dwb" dalam rajah mewakili blok dwbottleneck. Blok Sifar dalam rajah menunjukkan bahawa subnet melangkau blok Rajah di bawah menunjukkan persamaan laluan dalam dua kawasan yang disebutkan di atas. Persamaan diukur dengan skor persamaan Jaccard antara subnet untuk setiap domain, di mana lebih tinggi bermakna lebih banyak laluan serupa.

Gambar menunjukkan matriks kekeliruan skor persamaan Jaccard antara laluan dalam sepuluh domain. Markah berjulat dari 0 hingga 1. Lebih besar skor, lebih banyak nod yang dikongsi oleh dua laluan.
Melatih model pelbagai domain heterogen
Dalam fasa kedua, model yang dihasilkan oleh MPNAS akan dilatih dari awal untuk semua domain. Untuk melakukan ini, adalah perlu untuk menentukan fungsi objektif bersatu untuk semua domain. Untuk berjaya mengendalikan pelbagai jenis domain, penyelidik mereka bentuk algoritma yang melaraskan sepanjang proses pembelajaran untuk mengimbangi kerugian merentas domain, yang dipanggil Adaptive Balanced Domain Prioritization (ABDP). Di bawah menunjukkan ketepatan, saiz model dan FLOPS model yang dilatih di bawah tetapan berbeza. Kami membandingkan MPNAS dengan tiga kaedah lain:
NAS bebas domain: model dicari dan dilatih secara berasingan untuk setiap domain.
Multi-Kepala Laluan Tunggal: Menggunakan model pra-latihan sebagai tulang belakang kongsi untuk semua domain, dengan kepala pengelasan berasingan untuk setiap domain.
NAS berbilang kepala: Cari seni bina tulang belakang bersatu untuk semua domain, dengan kepala pengelasan berasingan untuk setiap domain.
Daripada keputusan, kita dapat melihat bahawa NAS memerlukan membina satu set model untuk setiap domain, menghasilkan model yang besar. Walaupun NAS berbilang kepala dan berbilang kepala laluan tunggal boleh mengurangkan saiz model dan FLOPS dengan ketara, memaksa domain untuk berkongsi tulang belakang yang sama memperkenalkan pemindahan pengetahuan negatif, sekali gus mengurangkan ketepatan keseluruhan.

Sebaliknya, MPNAS boleh membina model yang kecil dan cekap sambil mengekalkan ketepatan keseluruhan yang tinggi. Purata ketepatan MPNAS malah 1.9% lebih tinggi daripada kaedah NAS bebas domain kerana model tersebut mampu mencapai pemindahan pengetahuan aktif. Rajah di bawah membandingkan ketepatan 1 teratas bagi setiap domain kaedah ini.
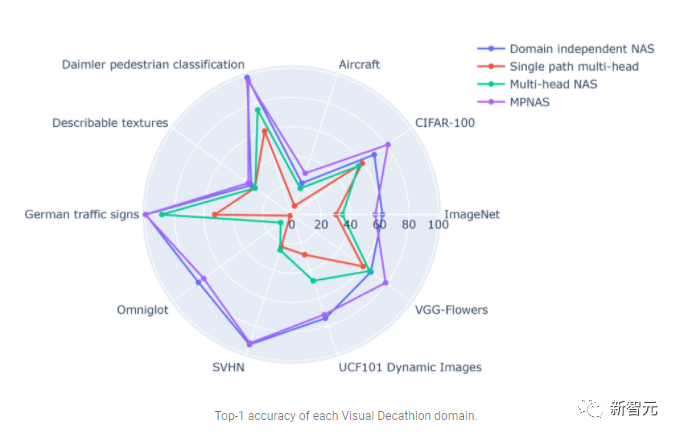
Penilaian menunjukkan bahawa dengan menggunakan ABDP sebagai sebahagian daripada fasa carian dan latihan, teratas- 1 Kadar ketepatan meningkat daripada 69.96% kepada 71.78% (kenaikan: +1.81%).
Hala Tuju Masa Depan
MPNAS akan membina rangkaian heterogen untuk menyelesaikan ketidakseimbangan data, kepelbagaian domain, migrasi negatif, ketersediaan domain strategi perkongsian parameter yang mungkin dalam penyelesaian Cekap MDL untuk kebolehskalaan dan ruang carian yang besar. Dengan menggunakan ruang carian seperti MobileNet, model yang dihasilkan juga mesra mudah alih. Untuk tugasan yang tidak serasi dengan algoritma carian sedia ada, penyelidik terus memperluaskan MPNAS untuk pembelajaran berbilang tugas dan berharap dapat menggunakan MPNAS untuk membina model berbilang domain bersatu.
Atas ialah kandungan terperinci Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
Kaedah pembelajaran mendalam hari ini memberi tumpuan kepada mereka bentuk fungsi objektif yang paling sesuai supaya keputusan ramalan model paling hampir dengan situasi sebenar. Pada masa yang sama, seni bina yang sesuai mesti direka bentuk untuk mendapatkan maklumat yang mencukupi untuk ramalan. Kaedah sedia ada mengabaikan fakta bahawa apabila data input mengalami pengekstrakan ciri lapisan demi lapisan dan transformasi spatial, sejumlah besar maklumat akan hilang. Artikel ini akan menyelidiki isu penting apabila menghantar data melalui rangkaian dalam, iaitu kesesakan maklumat dan fungsi boleh balik. Berdasarkan ini, konsep maklumat kecerunan boleh atur cara (PGI) dicadangkan untuk menghadapi pelbagai perubahan yang diperlukan oleh rangkaian dalam untuk mencapai pelbagai objektif. PGI boleh menyediakan maklumat input lengkap untuk tugas sasaran untuk mengira fungsi objektif, dengan itu mendapatkan maklumat kecerunan yang boleh dipercayai untuk mengemas kini berat rangkaian. Di samping itu, rangka kerja rangkaian ringan baharu direka bentuk
 'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer
Jun 14, 2023 pm 01:43 PM
'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer
Jun 14, 2023 pm 01:43 PM
Beberapa ketika dahulu, tweet yang menunjukkan ketidakkonsistenan antara gambar rajah seni bina Transformer dan kod dalam kertas kerja pasukan Google Brain "AttentionIsAllYouNeed" mencetuskan banyak perbincangan. Sesetengah orang berpendapat bahawa penemuan Sebastian adalah kesilapan yang tidak disengajakan, tetapi ia juga mengejutkan. Lagipun, memandangkan populariti kertas Transformer, ketidakkonsistenan ini sepatutnya disebut seribu kali. Sebastian Raschka berkata sebagai tindak balas kepada komen netizen bahawa kod "paling asli" sememangnya konsisten dengan gambar rajah seni bina, tetapi versi kod yang diserahkan pada 2017 telah diubah suai, tetapi gambar rajah seni bina tidak dikemas kini pada masa yang sama. Ini juga punca perbincangan "tidak konsisten".
 Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
May 28, 2023 pm 02:12 PM
Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
May 28, 2023 pm 02:12 PM
Model pembelajaran mendalam untuk tugas penglihatan (seperti klasifikasi imej) biasanya dilatih hujung ke hujung dengan data daripada domain visual tunggal (seperti imej semula jadi atau imej yang dijana komputer). Secara amnya, aplikasi yang menyelesaikan tugas penglihatan untuk berbilang domain perlu membina berbilang model untuk setiap domain yang berasingan dan melatihnya secara berasingan Data tidak dikongsi antara domain yang berbeza, setiap model akan mengendalikan data input tertentu. Walaupun ia berorientasikan kepada bidang yang berbeza, beberapa ciri lapisan awal antara model ini adalah serupa, jadi latihan bersama model ini adalah lebih cekap. Ini mengurangkan kependaman dan penggunaan kuasa, dan mengurangkan kos memori untuk menyimpan setiap parameter model Pendekatan ini dipanggil pembelajaran berbilang domain (MDL). Selain itu, model MDL juga boleh mengatasi prestasi tunggal
 Apakah seni bina dan prinsip kerja Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Apakah seni bina dan prinsip kerja Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA adalah berdasarkan seni bina JPA dan berinteraksi dengan pangkalan data melalui pemetaan, ORM dan pengurusan transaksi. Repositorinya menyediakan operasi CRUD, dan pertanyaan terbitan memudahkan akses pangkalan data. Selain itu, ia menggunakan pemuatan malas untuk hanya mendapatkan semula data apabila perlu, sekali gus meningkatkan prestasi.
 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
Alamat kertas: https://arxiv.org/abs/2307.09283 Alamat kod: https://github.com/THU-MIG/RepViTRepViT berprestasi baik dalam seni bina ViT mudah alih dan menunjukkan kelebihan yang ketara. Seterusnya, kami meneroka sumbangan kajian ini. Disebutkan dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala (MSHA) mereka yang membolehkan model mempelajari perwakilan global. Walau bagaimanapun, perbezaan seni bina antara ViT ringan dan CNN ringan belum dikaji sepenuhnya. Dalam kajian ini, penulis menyepadukan ViT ringan ke dalam yang berkesan
 Seberapa curam keluk pembelajaran seni bina rangka kerja golang?
Jun 05, 2024 pm 06:59 PM
Seberapa curam keluk pembelajaran seni bina rangka kerja golang?
Jun 05, 2024 pm 06:59 PM
Keluk pembelajaran seni bina rangka kerja Go bergantung pada kebiasaan dengan bahasa Go dan pembangunan bahagian belakang serta kerumitan rangka kerja yang dipilih: pemahaman yang baik tentang asas bahasa Go. Ia membantu untuk mempunyai pengalaman pembangunan bahagian belakang. Rangka kerja yang berbeza dalam kerumitan membawa kepada perbezaan dalam keluk pembelajaran.
 Adakah anda tahu bahawa pengaturcara akan merosot dalam beberapa tahun?
Nov 08, 2023 am 11:17 AM
Adakah anda tahu bahawa pengaturcara akan merosot dalam beberapa tahun?
Nov 08, 2023 am 11:17 AM
Majalah "ComputerWorld" pernah menulis artikel yang mengatakan bahawa "pengaturcaraan akan hilang menjelang 1960" kerana IBM membangunkan bahasa baharu FORTRAN, yang membolehkan jurutera menulis formula matematik yang mereka perlukan dan kemudian menyerahkannya kepada komputer, jadi pengaturcaraan tamat. Beberapa tahun kemudian, kami mendengar pepatah baru: mana-mana ahli perniagaan boleh menggunakan istilah perniagaan untuk menerangkan masalah mereka dan memberitahu komputer apa yang perlu dilakukan Menggunakan bahasa pengaturcaraan yang dipanggil COBOL ini, syarikat tidak lagi memerlukan pengaturcara. Kemudian, dikatakan bahawa IBM membangunkan bahasa pengaturcaraan baharu yang dipanggil RPG yang membolehkan pekerja mengisi borang dan menjana laporan, jadi kebanyakan keperluan pengaturcaraan syarikat dapat diselesaikan melaluinya.
 Meneroka rangkaian Siam menggunakan kehilangan kontrastif untuk perbandingan persamaan imej
Apr 02, 2024 am 11:37 AM
Meneroka rangkaian Siam menggunakan kehilangan kontrastif untuk perbandingan persamaan imej
Apr 02, 2024 am 11:37 AM
Pengenalan Dalam bidang penglihatan komputer, mengukur kesamaan imej dengan tepat adalah tugas kritikal dengan pelbagai aplikasi praktikal. Daripada enjin carian imej kepada sistem pengecaman muka dan sistem pengesyoran berasaskan kandungan, keupayaan untuk membandingkan dan mencari imej serupa dengan cekap adalah penting. Rangkaian Siam digabungkan dengan kehilangan kontras menyediakan rangka kerja yang kuat untuk mempelajari persamaan imej dalam cara yang dipacu data. Dalam catatan blog ini, kami akan menyelami butiran rangkaian Siam, meneroka konsep kehilangan kontras dan meneroka cara kedua-dua komponen ini berfungsi bersama untuk mencipta model persamaan imej yang berkesan. Pertama, rangkaian Siam terdiri daripada dua subrangkaian yang sama yang berkongsi berat dan parameter yang sama. Setiap sub-rangkaian mengekod imej input ke dalam vektor ciri, yang
