
 Peranti teknologi
AI
Ma Guoning, Timbalan Pengurus Besar Teknologi Taifan: Memetakan segala-galanya, daripada Königsberg hingga memperkasakan semua industri
Peranti teknologi
AI
Ma Guoning, Timbalan Pengurus Besar Teknologi Taifan: Memetakan segala-galanya, daripada Königsberg hingga memperkasakan semua industri
Ma Guoning, Timbalan Pengurus Besar Teknologi Taifan: Memetakan segala-galanya, daripada Königsberg hingga memperkasakan semua industri

Pada 6 dan 7 Ogos 2022, Persidangan Teknologi Kecerdasan Buatan Global AIsummit akan diadakan seperti yang dijadualkan. Di sub-forum "Amalan Memperkasakan Industri AI" yang diadakan pada petang ke-7, Ma Guoning, timbalan pengurus besar Teknologi Taifan, berkongsi tema "Memetakan Segala-galanya, dari Königsberg kepada Memperkasakan Semua Industri" dan berkongsi peta pengetahuan dalam terperinci Pemerkasaan dalam beribu-ribu industri.
Jika Yu Gong seorang AI, bolehkah dia memindahkan gunung?
Jika Yu Gong dianggap sebagai AI, bolehkah dia memindahkan gunung? Bagaimana untuk memindahkan gunung?
Ma Guoning berkata dalam industri kecerdasan buatan, setiap medan menegak adalah gunung yang besar. Sebagai contoh, dalam kewangan, industri, hal ehwal kerajaan dan industri lain, apabila menggunakan algoritma untuk menyelesaikan masalah khusus industri, anda akan mendapati bahawa ia sentiasa berbeza daripada reka bentuk dan pelaksanaan asal Sebab utamanya ialah logik algoritma kami mungkin tidak semestinya sepadan dengan perniagaan industri. Cara awal untuk menyelesaikan masalah ini adalah dengan menggunakan kecerdasan data dan kecerdasan pengkomputeran untuk melatih berdasarkan jumlah data timbunan Walau bagaimanapun, kaedah ini juga akan menyebabkan beberapa kesesakan di peringkat kemudian. Untuk tujuan ini, kami telah mula menggunakan kaedah kecerdasan persepsi seperti pengecaman muka dan pengecaman suara untuk menyelesaikan masalah yang timbul dalam beberapa senario.
Apabila kecerdasan persepsi juga menghadapi kesesakan, cara terkini ialah menggunakan algoritma kecerdasan kognitif untuk menyelesaikannya. Jadi, bolehkah kecerdasan kognitif mensimulasikan pemikiran dan proses kognitif manusia untuk menyelesaikan masalah yang kompleks dan sukar?
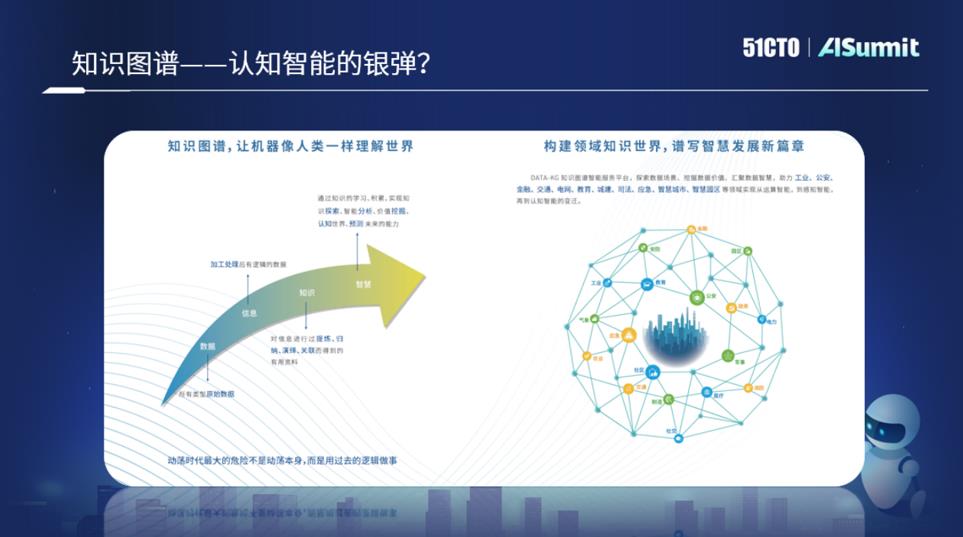
Dalam bidang kecerdasan kognitif, Google telah lama mencuba menggunakan graf pengetahuan untuk meletakkan semua pengetahuan ke dalam graf yang sama , meniru manusia pemikiran dan proses penaakulan dan deduksi. Walau bagaimanapun, sejak Google mencadangkan idea ini, sekurang-kurangnya setakat ini, masih tiada cara untuk mensimulasikan sepenuhnya proses pemikiran manusia. Walaupun proses pembinaan peta tidak rumit, apabila jumlah data cukup besar, pelbagai masalah akan dihadapi. Sebagai contoh, WolframAlpha mempunyai lebih daripada 1 bilion entiti, DBpedia mempunyai lebih daripada 3 bilion tiga kali ganda, Google pada masa ini mempunyai lebih daripada 500 juta entiti, dan lebih daripada 10 bilion sambungan perhubungan Microsoft Probase mempunyai berpuluh juta konsep sahaja. Dalam kes ini, apatah lagi aplikasi, sudah sukar untuk hanya melakukan analisis carian dan pertanyaan.
Ramai sarjana percaya bahawa satu titik atau gugusan tidak dapat menyelesaikan masalah ini, maka mereka menggunakan dua gugusan atau bahkan sedozen gugusan untuk menyelesaikan masalah ini. Sebenarnya, sukar untuk melakukan pengelompokan timbunan dalam graf pengetahuan Sebab utama ialah apabila sebilangan besar entiti dan nod dikaitkan, sukar untuk memisahkan data.
AI memperkasakan industri, siapa yang memperkasakan AI?
Pada asalnya saya ingin menggunakan AI untuk memperkasakan industri, tetapi daripada kecerdasan pengiraan kepada kecerdasan persepsi dan kecerdasan kognitif, AI kini juga memerlukan seseorang untuk memperkasakannya. Apa yang perlu dilakukan?
Ma Guoning percaya bahawa caranya adalah dengan berdiri di atas bahu gergasi.
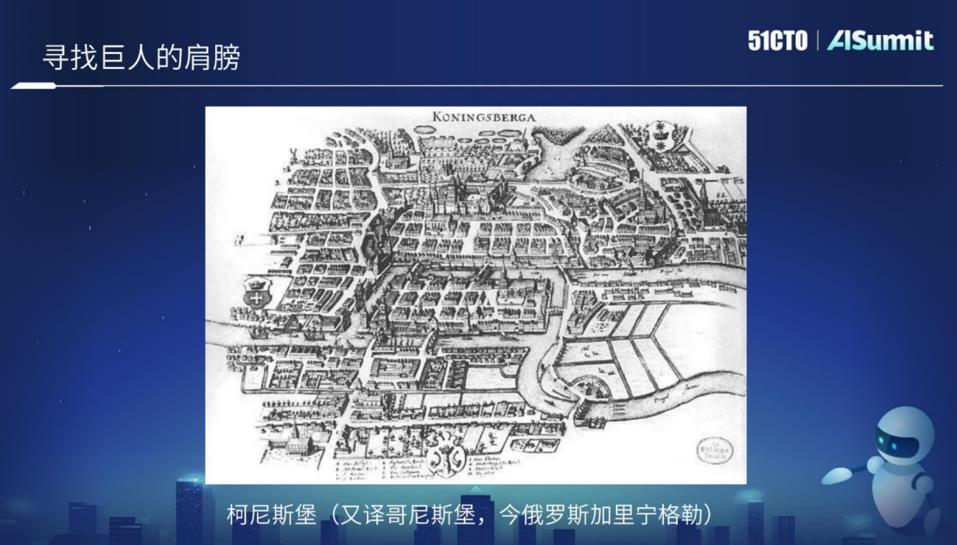
Königsberg dalam gambar di atas adalah sebuah bandar kecil, tetapi ia sangat terkenal dalam komuniti matematik atau dalam komuniti teori graf, terutamanya kerana seorang ahli matematik yang hebat Euler Pull, menyelesaikan Masalah Tujuh Jambatan Königsberg pada tahun 1736 dan mencipta cabang baru matematik, teori graf. Apabila graf pengetahuan digunakan dalam kelompok atau persekitaran teragih, masalah ini perlu diselesaikan berdasarkan teori matematik.
Oleh itu, apabila masalah komputer diselesaikan pada tahap tertentu, ia akan dikurangkan kepada masalah matematik Apabila berurusan dengan graf pengetahuan berskala besar, adalah perlu untuk membahagikan graf pengetahuan dan menggunakan semula kuasa pengkomputeran untuk menyelesaikan teragih. masalah. Jadi, dalam proses pembahagian, bagaimana untuk meminimumkan korelasi antara graf pengetahuan yang dipisahkan? Untuk tujuan ini, kita perlu menggunakan algoritma yang mantap atau canggih dalam industri untuk memenuhi pembahagian graf sambil memenuhi keperluan skala data dan pengedaran.

Walau bagaimanapun, algoritma yang dilaksanakan secara terbuka atau direkodkan pada masa ini tidak dapat menyelesaikan semua masalah sepenuhnya. Kerana sukar untuk secara serentak memenuhi pengimbangan beban dan isu kos komunikasi antara setiap mesin sambil meminimumkan bilangan tepi pemotong atau bucu.
Bagaimana untuk menyelesaikan masalah ini? Pendekatan kami adalah untuk mengurangkan kerumitan kepada pemalar dalam eksponen untuk graf mudah tanpa pemberat. Pada graf berwajaran, mengurangkan satu daripada indeks kepada kerumitan yang berterusan ialah hasil penyelidikan yang agak canggih. Dalam bidang hipergraf, masalah pemotongan hipergraf akhirnya mesti dianggap sebagai kes khas subbrane k-bahagian Apabila nilai K ditentukan, tiada masalah untuk menyelesaikannya.

Sebagai contoh, untuk graf ringkas, terdapat tiga baris pemotongan Dalam amalan sebenar, ia boleh difahami secara ringkas sebagai membahagikan keseluruhan graf pengetahuan kepada tiga kelompok. Antaranya, nod pengetahuan S2 dipotong secara bebas, dan S2 di sisi lain ialah potongan bebas minimum Ini adalah penerangan visual mudah yang kami gunakan untuk memudahkan semua orang memahami mengapa graf ini dipisahkan.
Dari segi kesan, seperti algoritma METIS, ia lebih seimbang dalam meminimumkan bilangan bucu merentas sekatan dan masa perlombongan pengetahuan berikutnya seperti algoritma Hash, atau algoritma JA-BE-JA; antaranya Di satu pihak, prestasi mungkin tidak memuaskan, tetapi prestasi algoritma METIS agak seimbang.
Graf Pengetahuan dan Pemerkasaan Semua Industri
Berdasarkan teknologi dan penyelidikan industri, Teknologi Taifan telah membina platform graf pengetahuan, dengan lapisan atas adalah sistem perkhidmatan aplikasi , termasuk mendapatkan semula , pertanyaan visual pengetahuan, soalan dan jawapan pintar, dan lapisan bawah membina "organ penting" graf pengetahuan. Sebenarnya, graf pada asalnya adalah masalah semantik dan dibangunkan berdasarkan Web Semantik. Pengurusan pangkalan data semantik, termasuk cara mengemas kini pengetahuan, betapa terperinci kemas kini, berapa banyak entiti yang perlu diliputi dalam bidang berkaitan, berapa banyak perhubungan pemetaan harus diliputi, dsb., Teknologi Taifan akan memasukkannya ke dalam rangka kerja keseluruhan. Oleh itu, ini adalah platform rangka kerja yang sangat serba boleh yang boleh digunakan dalam semua lapisan masyarakat.

Selain itu, keseluruhan rangka kerja juga menyepadukan fungsi yang diperlukan untuk aplikasi praktikal, seperti merealisasikan pengurusan keseluruhan kitaran hayat pangkalan pengetahuan, termasuk pengesyoran dan pengambilan semula pintar. , skalabiliti, ini semua adalah isu yang mesti dipertimbangkan dalam amalan pelaksanaan industri. Di samping itu, banyak penerokaan hubungan dan perlombongan boleh diselesaikan dengan bergantung pada perlombongan pengetahuan.
Pada masa berikutnya, Ma Guoning memperkenalkan secara terperinci aplikasi praktikal Zhimapu dalam pelbagai industri melalui kes senario seperti taman pintar, bangunan pintar, pengangkutan pintar, penerbangan pintar dan analisis data saintifik pintar.
"Lautan berbintang inovasi teknologi dan kemungkinan masa depan yang tidak terhingga adalah lebih mengujakan. Saya amat percaya perkara ini," katanya pengamal yang berminat untuk menyertai industri ini, boleh menggunakan teknologi kecerdasan buatan dengan lebih yakin untuk memperkasakan ribuan industri.
Atas ialah kandungan terperinci Ma Guoning, Timbalan Pengurus Besar Teknologi Taifan: Memetakan segala-galanya, daripada Königsberg hingga memperkasakan semua industri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Pengekodan Vibe membentuk semula dunia pembangunan perisian dengan membiarkan kami membuat aplikasi menggunakan bahasa semulajadi dan bukannya kod yang tidak berkesudahan. Diilhamkan oleh penglihatan seperti Andrej Karpathy, pendekatan inovatif ini membolehkan Dev
 Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Februari 2025 telah menjadi satu lagi bulan yang berubah-ubah untuk AI generatif, membawa kita beberapa peningkatan model yang paling dinanti-nantikan dan ciri-ciri baru yang hebat. Dari Xai's Grok 3 dan Anthropic's Claude 3.7 Sonnet, ke Openai's G
 Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Yolo (anda hanya melihat sekali) telah menjadi kerangka pengesanan objek masa nyata yang terkemuka, dengan setiap lelaran bertambah baik pada versi sebelumnya. Versi terbaru Yolo V12 memperkenalkan kemajuan yang meningkatkan ketepatan
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast: AI Revolusioner untuk Peramalan Cuaca Peramalan cuaca telah menjalani transformasi dramatik, bergerak dari pemerhatian asas kepada ramalan berkuasa AI yang canggih. Google Deepmind's Gencast, tanah air
 AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
Artikel ini membincangkan model AI yang melampaui chatgpt, seperti Lamda, Llama, dan Grok, menonjolkan kelebihan mereka dalam ketepatan, pemahaman, dan kesan industri. (159 aksara)
 O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
Openai's O1: Hadiah 12 Hari Bermula dengan model mereka yang paling berkuasa Ketibaan Disember membawa kelembapan global, kepingan salji di beberapa bahagian dunia, tetapi Openai baru sahaja bermula. Sam Altman dan pasukannya melancarkan mantan hadiah 12 hari
 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
