

Pada tahun 2022, bekas saintis Cina Google Brain Jason Wei mula-mula mencadangkan dalam kerja perintis mengenai rantaian pemikiran bahawa CoT boleh meningkatkan keupayaan penaakulan LLM.
Tetapi walaupun dengan rantaian pemikiran, LLM kadangkala membuat kesilapan pada soalan yang sangat mudah.
Baru-baru ini, penyelidik dari Princeton University dan Google DeepMind mencadangkan rangka kerja penaakulan model bahasa baharu - "Tree of Thinking" (ToT).
ToT membuat generalisasi kaedah "rantai pemikiran" yang popular pada masa ini untuk membimbing model bahasa dan menyelesaikan langkah perantaraan masalah dengan meneroka unit teks yang koheren (berfikir).

Alamat kertas: https://arxiv.org/abs/2305.10601
Alamat projek: https://github.com/kyegomez/tree-of-thoughts
Ringkasnya, " " Thinking Tree" membenarkan LLM untuk:
· Berikan diri anda pelbagai laluan penaakulan yang berbeza
· Selepas menilai setiap satu, tentukan langkah seterusnya Pelan tindakan
· Jejak ke hadapan atau ke belakang apabila perlu untuk mencapai pembuatan keputusan global
Hasil eksperimen kertas menunjukkan bahawa ToT Memperbaiki masalah LLM dengan ketara -menyelesaikan kebolehan dalam tiga tugasan baharu (permainan 24 mata, penulisan kreatif, teka silang kata mini).
Sebagai contoh, dalam permainan 24 mata, GPT-4 hanya menyelesaikan 4% daripada tugasan, tetapi kadar kejayaan kaedah ToT mencapai 74%.
Model bahasa besar GPT dan PaLM yang digunakan untuk menjana teks kini telah terbukti mampu melaksanakan pelbagai tugas .
Asas untuk kemajuan semua model ini masih merupakan "mekanisme autoregresif" yang asalnya digunakan untuk menjana teks, membuat keputusan peringkat token satu demi satu dengan cara kiri ke kanan .

Jadi, adakah mekanisme mudah seperti itu cukup untuk mewujudkan "model bahasa untuk menyelesaikan masalah umum"? Jika tidak, apakah isu yang mencabar paradigma semasa, dan apakah mekanisme alternatif yang sebenar?
Tepatnya literatur tentang "kognisi manusia" yang memberikan beberapa petunjuk kepada isu ini.
Penyelidikan pada model "proses dwi" menunjukkan bahawa manusia mempunyai dua mod membuat keputusan: mod pantas, automatik, tidak sedarkan diri - "Sistem 1" dan mod perlahan, disengajakan, sedar - "Sistem 2".
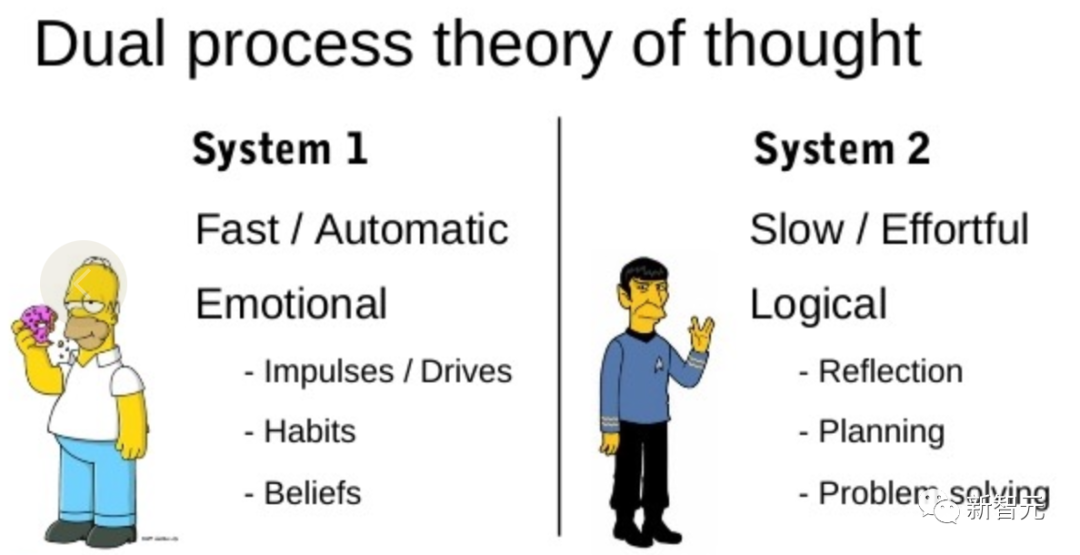
Model bahasa hanya dikaitkan dengan pemilihan peringkat token boleh mengingatkan "Sistem 1", jadi keupayaan ini mungkin Dipertingkatkan daripada proses perancangan "Sistem 2".
"Sistem 1" membenarkan LLM mengekalkan dan meneroka pelbagai alternatif kepada pilihan semasa dan bukannya memilih satu sahaja, manakala "Sistem 2" menilai keadaan semasanya dan secara aktif Pandang ke hadapan dan lihat ke belakang untuk membuat keputusan yang lebih holistik.
Untuk mereka bentuk proses perancangan sedemikian, para penyelidik menelusuri kembali asal-usul kecerdasan buatan dan sains kognitif, bermula dengan proses perancangan yang diterokai oleh saintis Newell, Shaw dan Simon pada tahun 1950-an .dapat inspirasi daripada.
Newell dan rakan sekerja menerangkan penyelesaian masalah sebagai "mencari dengan menggabungkan ruang masalah", diwakili sebagai pokok.
Dalam proses menyelesaikan masalah, anda perlu berulang kali menggunakan maklumat sedia ada untuk meneroka bagi mendapatkan maklumat lanjut sehingga anda akhirnya menemui penyelesaian.

Pandangan ini menyerlahkan 2 kelemahan utama kaedah sedia ada menggunakan LLM untuk menyelesaikan masalah umum:
1. Dari perspektif tempatan, LLM tidak meneroka kesinambungan yang berbeza dalam proses pemikiran - dahan pokok.
2 Secara umumnya, LLM tidak termasuk sebarang jenis perancangan, melihat ke hadapan atau melihat ke belakang untuk membantu menilai pilihan yang berbeza ini.
Untuk menyelesaikan masalah ini, penyelidik mencadangkan rangka kerja pokok pemikiran (ToT) yang menggunakan model bahasa untuk menyelesaikan masalah umum, membolehkan LLM meneroka pelbagai laluan penaakulan pemikiran.
Pada masa ini, kaedah sedia ada, seperti IO, CoT dan CoT-SC, menyelesaikan masalah dengan mensampel urutan bahasa berterusan.
ToT secara aktif mengekalkan "pokok berfikir". Setiap kotak segi empat tepat mewakili pemikiran, dan setiap pemikiran adalah urutan lisan yang koheren yang berfungsi sebagai langkah perantaraan dalam menyelesaikan masalah.
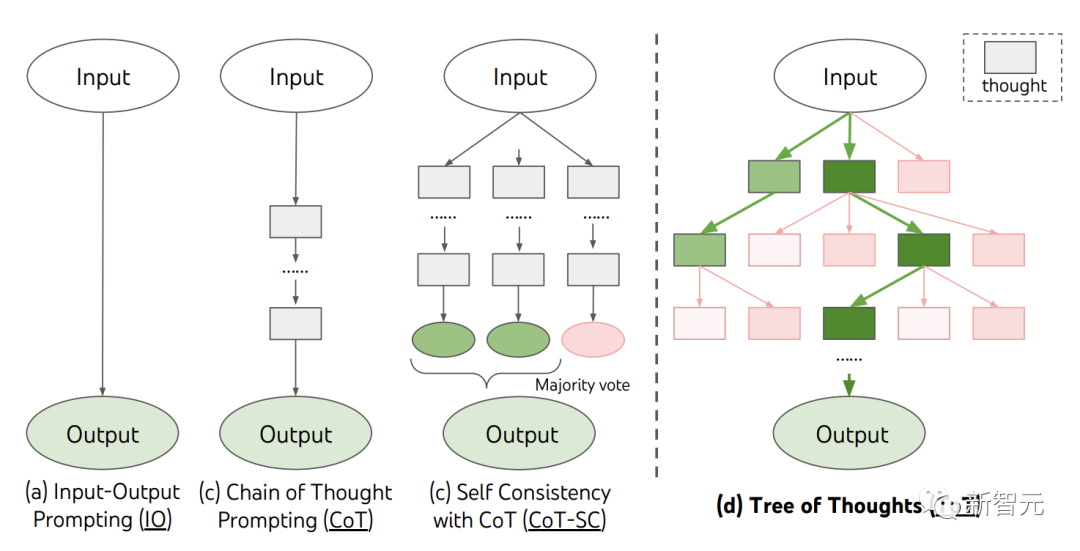
ToT mentakrifkan sebarang masalah sebagai carian pada pokok, di mana setiap nod ialah keadaan yang mewakili penyelesaian Separa bagi urutan input dan pemikiran setakat ini.
ToT perlu menjawab 4 soalan semasa melaksanakan tugasan tertentu:
Cara menguraikan proses perantaraan kepada langkah berfikir bagaimana untuk bermula setiap negeri Menjana idea yang berpotensi; bagaimana untuk menilai keadaan secara heuristik apa algoritma carian untuk digunakan
1 Pecahan pemikiran
CoT tidak jelas Penguraian melibatkan persampelan pemikiran yang koheren, manakala ToT menggunakan sifat masalah untuk mereka bentuk dan menguraikan langkah pemikiran pertengahan.
Bergantung pada soalan, idea boleh terdiri daripada beberapa perkataan (teka-teki silang kata), persamaan (24 mata), atau keseluruhan rancangan penulisan (penulisan kreatif).
Secara umumnya, idea harus cukup "kecil" supaya LLM boleh menghasilkan sampel yang bermakna dan pelbagai. Sebagai contoh, menghasilkan buku yang lengkap selalunya terlalu "besar" untuk menjadi koheren.
Tetapi idea juga harus cukup "besar" untuk LLM menilai prospeknya untuk menyelesaikan masalah. Sebagai contoh, menjana token selalunya terlalu "kecil" untuk dinilai.
2. Penjana pemikiran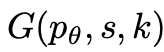
Keadaan pokok yang diberikan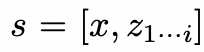 , menggunakan 2 strategi untuk menjana k calon untuk langkah pemikiran seterusnya.
, menggunakan 2 strategi untuk menjana k calon untuk langkah pemikiran seterusnya.
(a) Contoh daripada gesaan CoT 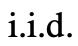 Berfikir:
Berfikir:
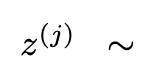
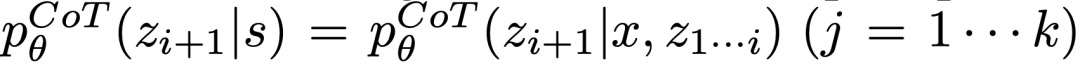
kaya dengan ruang berfikir (seperti setiap idea ialah perenggan), dan 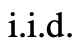 Ia berfungsi lebih baik apabila ia membawa kepada kepelbagaian.
Ia berfungsi lebih baik apabila ia membawa kepada kepelbagaian.
(b) Gunakan "proposal prompt" untuk mencadangkan idea mengikut urutan: 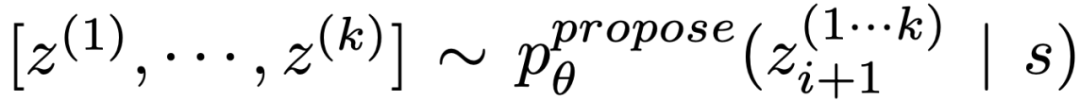
. Ini berfungsi lebih baik apabila ruang berfikir adalah terhad (cth. setiap pemikiran hanyalah satu perkataan atau baris), jadi menyampaikan idea yang berbeza dalam konteks yang sama mengelakkan pertindihan.
3.Penilai Negeri
Memandangkan sempadan negeri yang berbeza, penilai negeri menilai kemajuan mereka dalam menyelesaikan masalah, berfungsi sebagai heuristik untuk algoritma carian untuk menentukan negeri mana yang perlu diterokai dengan lebih lanjut, dan dalam susunan yang mana.
Walaupun heuristik ialah cara standard untuk menyelesaikan masalah carian, ia biasanya diprogramkan (DeepBlue) atau dipelajari (AlphaGo). Di sini, penyelidik mencadangkan pilihan ketiga untuk membuat alasan secara sedar tentang negeri melalui LLM.
Jika berkenaan, heuristik bernas sedemikian boleh menjadi lebih fleksibel daripada peraturan prosedur dan lebih cekap daripada model yang dipelajari. Dengan Penjana Pemikiran, para penyelidik juga mempertimbangkan 2 strategi untuk menilai negeri secara bebas atau bersama: memberikan nilai kepada setiap negeri secara bebas dan mengundi di seluruh negeri.
4 Algoritma Carian
Akhir sekali, dalam ToT. Dalam rangka kerja, seseorang boleh memasang dan memainkan algoritma carian yang berbeza berdasarkan struktur pokok.
Para penyelidik meneroka 2 algoritma carian yang agak mudah di sini:
Algoritma 1 - Breadth First Search (BFS), setiap satu Mengekalkan keadaan yang paling menjanjikan daripada set b dalam satu langkah.
Algoritma 2 - Depth First Search (DFS), mula-mula terokai keadaan yang paling menjanjikan sehingga output akhir dicapai, atau penilai keadaan menganggap mustahil untuk menyelesaikan daripada soalan ambang semasa. Dalam kedua-dua kes, DFS berundur ke keadaan induk s untuk meneruskan penerokaan.

Daripada perkara di atas, kaedah LLM untuk melaksanakan carian heuristik melalui penilaian kendiri dan membuat keputusan secara sedar adalah sesuatu yang baru.
EksperimenUntuk tujuan ini, pasukan mencadangkan tiga tugasan untuk ujian - malah model bahasa terkini GPT-4, di bawah gesaan IO standard atau Ia sangat mencabar apabila didorong oleh Rantaian Pemikiran (CoT).

24 mata ialah Permainan penaakulan matematik di mana matlamatnya adalah untuk mendapatkan 24 menggunakan 4 nombor dan operasi aritmetik asas (+-*/).
Sebagai contoh, diberi input "4 9 10 13", output jawapan mungkin "(10-4)*(13-9)=24".
Persediaan ToT
Pasukan memecahkan proses pemikiran model kepada 3 langkah, setiap langkah adalah persamaan perantaraan.
Seperti yang ditunjukkan dalam Rajah 2(a), pada setiap nod, ekstrak nombor di "kiri" dan gesa LLM untuk menjana langkah seterusnya yang mungkin. ("Gesaan cadangan" yang diberikan pada setiap langkah adalah sama)
Antaranya, pasukan melakukan carian pertama luas (BFS) dalam ToT dan mengekalkan b= terbaik pada setiap langkah 5 calon.
Seperti yang ditunjukkan dalam Rajah 2(b), LLM digesa untuk menilai setiap calon yang berfikir sebagai "pasti/mungkin/mustahil" sehingga 24. Hapuskan penyelesaian separa yang mustahil berdasarkan akal sehat "terlalu besar/terlalu kecil" dan kekalkan item "kemungkinan" yang selebihnya.
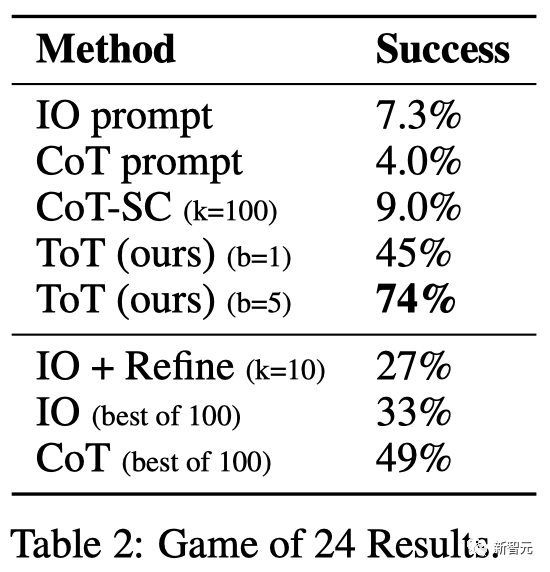
Hasilnya
ditunjukkan dalam Jadual 2 Telah ditunjukkan bahawa kaedah penggerak IO, CoT dan CoT-SC menunjukkan prestasi yang lemah dalam tugasan, dengan kadar kejayaan hanya 7.3%, 4.0% dan 9.0%. Sebagai perbandingan, ToT telah mencapai kadar kejayaan sebanyak 45% apabila keluasannya ialah b=1, dan 74% apabila b=5.
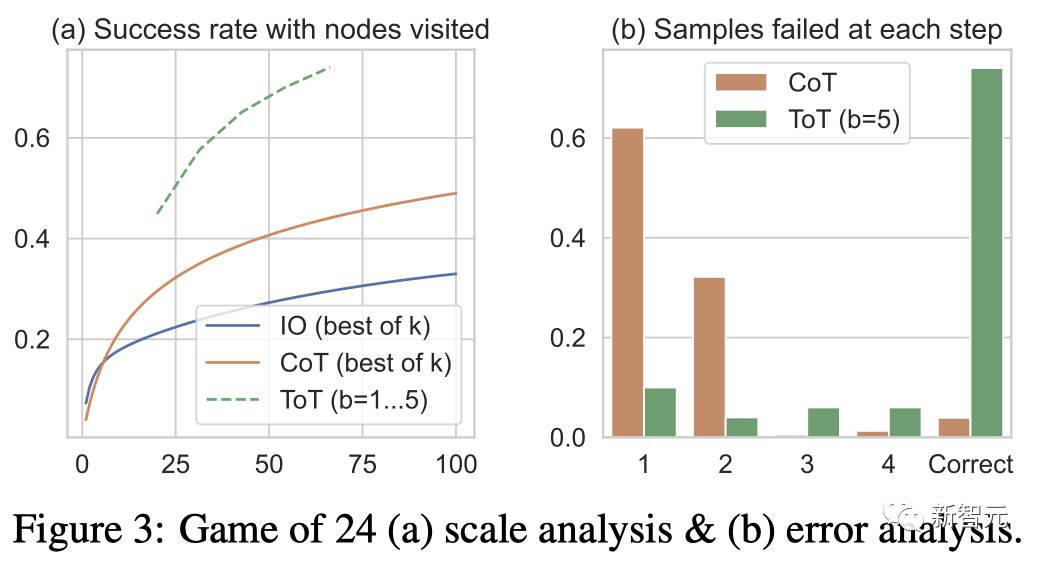
Pasukan juga mempertimbangkan tetapan ramalan IO/CoT dengan menggunakan sampel k terbaik (1≤k≤100) untuk mengira kadar kejayaan, dan dalam Rajah 3(a) 5 kadar kejayaan diplot.
Seperti yang dijangkakan, skala CoT lebih baik daripada IO, dengan 100 sampel CoT terbaik mencapai kadar kejayaan 49%, tetapi masih meneroka lebih banyak nod daripada dalam ToT ( b>1) Menjadi miskin .
Analisis Ralat
Rajah 3 ( b) Dianalisis pada langkah mana sampel CoT dan ToT gagal dalam tugasan, iaitu pemikiran (dalam CoT) atau semua pemikiran b (dalam ToT) adalah tidak sah atau tidak dapat mencapai 24.
Perlu diambil perhatian bahawa kira-kira 60% daripada sampel CoT telah gagal dalam langkah pertama, atau dengan kata lain, tiga perkataan pertama (seperti "4+9").
Seterusnya, pasukan mereka bentuk tugasan penulisan kreatif.
Antaranya, input ialah empat ayat rawak, dan outputnya hendaklah perenggan yang koheren, setiap perenggan berakhir dengan empat ayat input masing-masing. Tugas-tugas tersebut bersifat terbuka dan meneroka, pemikiran kreatif yang mencabar dan perancangan lanjutan.
Perlu diambil perhatian bahawa pasukan juga menggunakan kaedah pengoptimuman berulang (k≤5) pada sampel IO rawak bagi setiap tugas, di mana LLM adalah berdasarkan kekangan input dan yang terakhir dihasilkan Tentukan sama ada perenggan itu "koheren sepenuhnya", dan jika tidak, jana perenggan yang dioptimumkan.
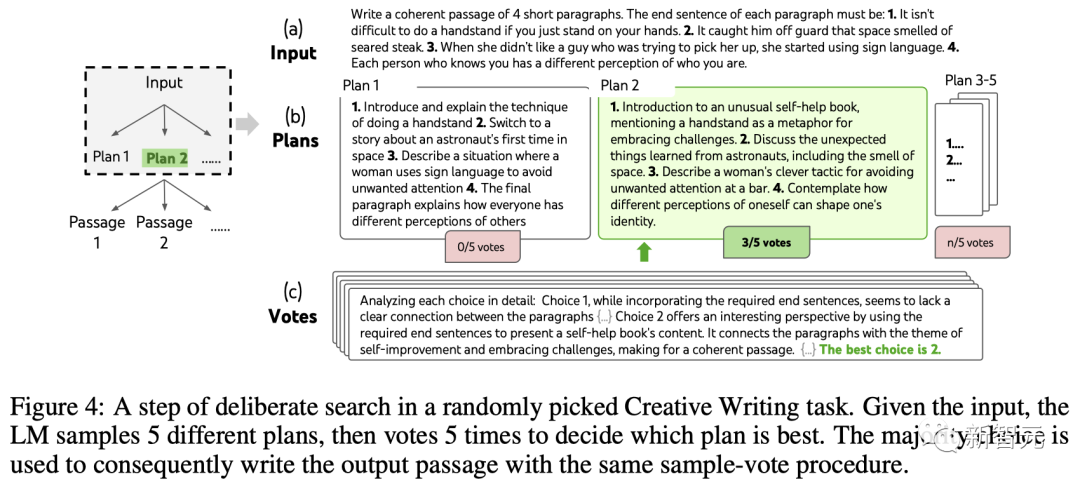
Tetapan ToT
Pembinaan pasukan A ToT dengan kedalaman 2 (hanya 1 langkah pemikiran pertengahan).
LLM mula-mula menjana k=5 pelan dan mengundi untuk yang terbaik (Rajah 4), kemudian menjana k=5 perenggan berdasarkan pelan terbaik, dan kemudian mengundi untuk yang terbaik .
Gesaan pengundian sifar pukulan mudah ("Analisis pilihan berikut dan tentukan yang paling berkemungkinan melaksanakan arahan itu") digunakan untuk menarik 5 undi dalam dua langkah.
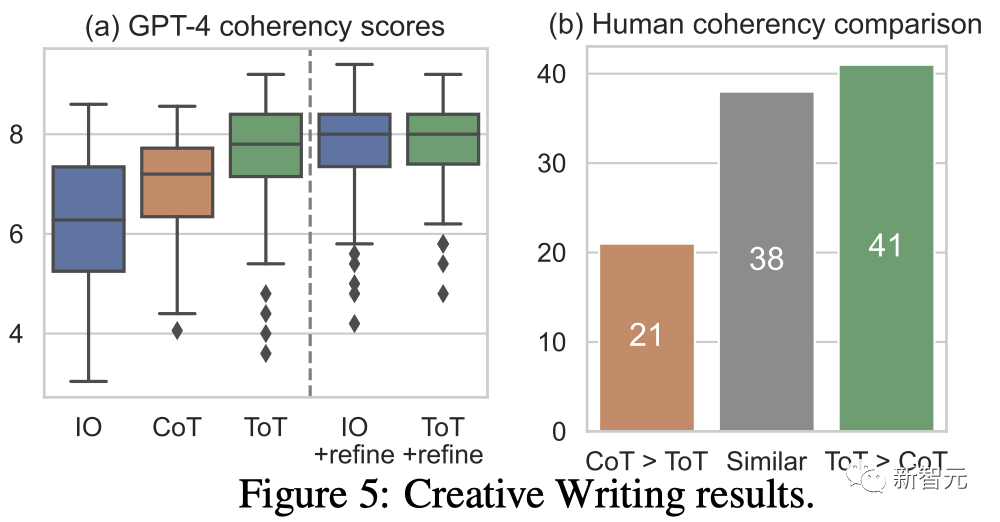
Keputusan
Rajah 5(a) menunjukkan 100 tugasan GPT- 4 skor purata dalam , di mana ToT (7.56) dianggap menjana perenggan yang lebih koheren secara purata daripada IO (6.19) dan CoT (6.93).
Walaupun ulasan automatik sedemikian mungkin bising, Rajah 5(b) menunjukkan ini dengan menunjukkan bahawa manusia lebih suka ToT untuk 41 daripada 100 pasangan perenggan dan hanya 21 untuk CoT (38 pasangan lain dianggap "sama koheren") untuk mengesahkan penemuan ini.
Akhir sekali, pengoptimuman berulang lebih berkesan pada tugas bahasa semula jadi ini - meningkatkan skor koheren IO daripada 6.19 kepada 7.67 dan skor koheren ToT daripada 7.56 kepada 7.91.
Pasukan percaya bahawa ia boleh dilihat sebagai kaedah ketiga untuk menjana pemikiran di bawah kerangka ToT Pemikiran baharu boleh dijana dengan mengoptimumkan pemikiran lama, bukannya i.i.d atau generasi berurutan.
Dalam permainan 24 mata dan penulisan kreatif, ToT adalah agak cetek - ia memerlukan sehingga 3 langkah berfikir untuk menyelesaikan Output boleh diselesaikan.
Akhirnya, pasukan memutuskan untuk menetapkan soalan yang lebih sukar melalui teka silang kata mini 5×5.
Sekali lagi, matlamatnya bukan hanya untuk menyelesaikan tugas, tetapi untuk mengkaji had LLM sebagai penyelesai masalah umum. Bimbing penerokaan anda dengan mengintip ke dalam fikiran anda sendiri dan menggunakan penaakulan bertujuan sebagai inspirasi.
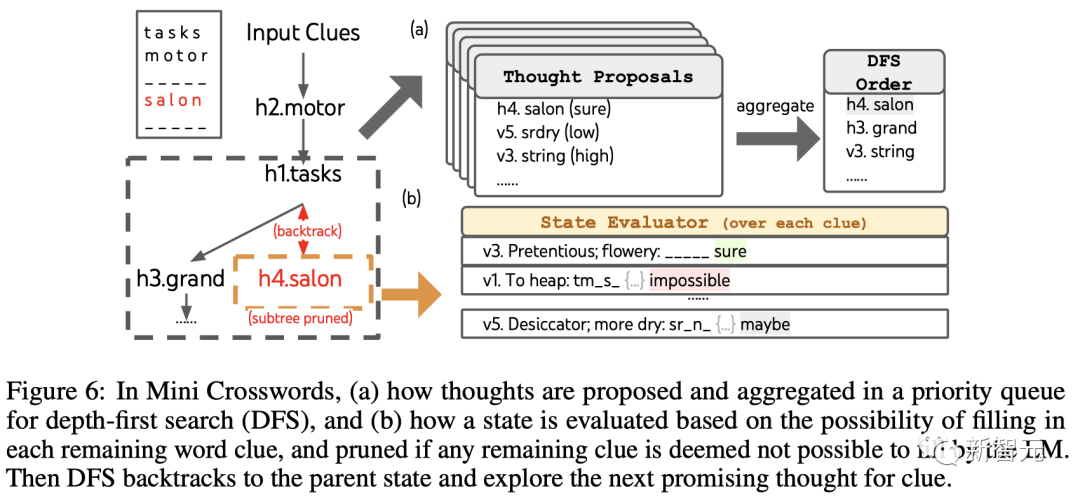
Tetapan ToT
Kedalaman Penggunaan Pasukan Carian yang diutamakan terus meneroka petunjuk perkataan berikutnya yang berkemungkinan besar berjaya sehingga keadaan tidak lagi menjanjikan, kemudian berundur ke negeri induk untuk meneroka idea alternatif.
Untuk menjadikan carian dapat dilaksanakan, pemikiran seterusnya dihadkan daripada menukar mana-mana perkataan atau huruf yang diisi, supaya ToT mempunyai maksimum 10 langkah perantaraan.
Untuk penjanaan pemikiran, pasukan menggabungkan semua pemikiran sedia ada di setiap negeri (contohnya, "h2.motor; h1.tasks" untuk keadaan dalam Rajah 6(a)) Tukar kepada had huruf bagi petunjuk yang tinggal (contohnya, "v1.To heap: tm___;..."), dengan itu memperoleh calon untuk mengisi kedudukan dan kandungan perkataan seterusnya.
Yang penting, pasukan juga menggesa LLM untuk memberikan tahap keyakinan untuk idea yang berbeza dan mengagregatkannya dalam cadangan untuk mendapatkan senarai kedudukan idea untuk diterokai seterusnya (Rajah 6(a) ) ).
Untuk penilaian status, pasukan juga menukar setiap status kepada had huruf untuk baki petunjuk, dan kemudian menilai sama ada setiap petunjuk mungkin diisi dalam had yang diberikan.
Jika mana-mana petunjuk yang tinggal dianggap "mustahil" (cth., "v1. To heap: tm_s_"), maka penerokaan subpokok negeri itu dipangkas dan DFS berundur ke arahnya nod induk untuk meneroka kemungkinan calon seterusnya.
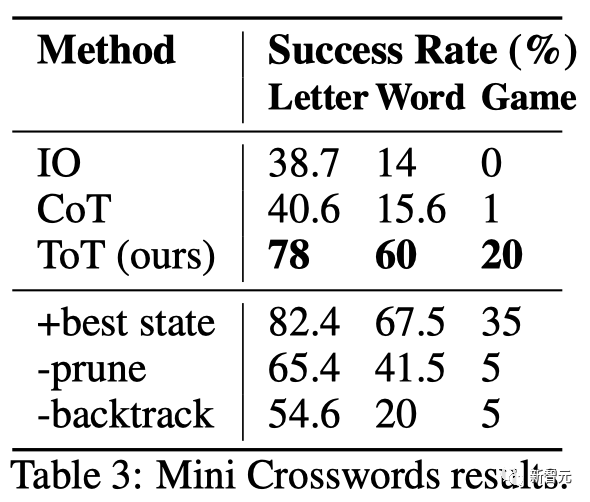
Hasilnya
ditunjukkan dalam Jadual 3 menunjukkan bahawa kaedah dorongan IO dan CoT berprestasi buruk pada kadar kejayaan peringkat perkataan, di bawah 16%, manakala ToT telah meningkatkan semua metrik dengan ketara, mencapai kadar kejayaan peringkat perkataan sebanyak 60% dan menyelesaikan 4 daripada 20 permainan .
Peningkatan ini tidak menghairankan memandangkan IO dan CoT kekurangan mekanisme untuk mencuba petunjuk yang berbeza, mengubah keputusan atau mundur.
ToT ialah rangka kerja yang membolehkan LLM membuat keputusan dan menyelesaikan masalah dengan lebih autonomi dan bijak.
Ia meningkatkan kebolehtafsiran keputusan model dan peluang penjajaran dengan manusia kerana jadual perwakilan yang dihasilkan oleh ToT adalah dalam bentuk penaakulan bahasa peringkat tinggi yang boleh dibaca dan bukannya tersirat , rendah -nilai token peringkat.
ToT mungkin tidak diperlukan untuk tugasan yang GPT-4 sudah sangat mahir.
Selain itu, kaedah carian seperti ToT memerlukan lebih banyak sumber (seperti kos API GPT-4) untuk meningkatkan prestasi tugasan, tetapi fleksibiliti modular ToT membolehkan pengguna menyesuaikan keseimbangan kos prestasi ini.
Walau bagaimanapun, memandangkan LLM digunakan dalam lebih banyak aplikasi membuat keputusan dunia sebenar (seperti pengaturcaraan, analisis data, robotik, dll.), ToT boleh menyediakan asas untuk mengkaji lebih banyak masalah yang akan datang yang kompleks dan menyediakan peluang baru.
Pengenalan Pengarang
Shunyu Yao (姚顺雨)
Hala tuju penyelidikannya adalah untuk mewujudkan interaksi antara agen bahasa dan dunia, seperti bermain permainan kata (CALM), membeli-belah dalam talian (WebShop), dan melayari Wikipedia untuk alasan (ReAct) , atau, berdasarkan idea yang sama, gunakan sebarang alat untuk menyelesaikan sebarang tugas.
Dalam kehidupan, dia suka membaca, bola keranjang, biliard, melancong dan rap.
Dian Yu
Dian Yu ialah Seorang saintis penyelidikan di Google DeepMind. Sebelum ini, beliau memperoleh PhD dari UC Davis dan BA dari New York University, pengkhususan dua kali ganda dalam sains komputer dan kewangan (dan sedikit lakonan). 
Minat penyelidikannya ialah perwakilan atribut bahasa, serta pemahaman berbilang bahasa dan pelbagai mod, terutamanya memfokuskan pada penyelidikan perbualan (termasuk domain terbuka dan berorientasikan tugas).
Yuan Cao
Yuan Cao juga seorang saintis penyelidikan di Google DeepMind. Sebelum ini, beliau menerima ijazah sarjana muda dan sarjana dari Universiti Shanghai Jiao Tong dan PhD dari Universiti Johns Hopkins. Beliau juga berkhidmat sebagai ketua arkitek Baidu.
Jeffrey Zhao
Jeffrey Zhao ialah Jurutera Perisian di Google DeepMind. Sebelum ini, beliau menerima ijazah sarjana muda dan sarjana dari Universiti Carnegie Mellon. 
Atas ialah kandungan terperinci Penaakulan GPT-4 bertambah baik sebanyak 1750%! Alumnus kelas Princeton Tsinghua Yao mencadangkan rangka kerja 'Thinking Tree ToT' baharu, membolehkan LLM berfikir berulang kali. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memulakan perkhidmatan mysql
Bagaimana untuk memulakan perkhidmatan mysql
 Bagaimana untuk melangkau sambungan rangkaian semasa pemasangan win11
Bagaimana untuk melangkau sambungan rangkaian semasa pemasangan win11
 Bagaimana untuk menyelesaikan masalah bahawa port phpstudy diduduki
Bagaimana untuk menyelesaikan masalah bahawa port phpstudy diduduki
 Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
 xserver
xserver
 Adakah Code Red virus komputer?
Adakah Code Red virus komputer?
 stackoverflowatline1
stackoverflowatline1
 Bagaimana untuk membatalkan akaun Douyin di Douyin
Bagaimana untuk membatalkan akaun Douyin di Douyin
 Apakah perbezaan antara nombor versi Eclipse?
Apakah perbezaan antara nombor versi Eclipse?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



