

Mengapa Redis begitu pantas?

Redis ialah pangkalan data NoSQL berdasarkan pasangan nilai kunci Nilai Redis boleh terdiri daripada pelbagai struktur data dan algoritma seperti String, cincang, senarai, set, zset, Bitmaps, HyperLogLog, dll. Redis mempunyai banyak fungsi, seperti tamat tempoh kunci, menerbitkan dan melanggan, transaksi, skrip Lua, pengawal, Kluster, dsb.
Menurut data prestasi rasmi, Redis boleh melaksanakan arahan pada kelajuan yang sangat pantas, dan QPSnya boleh mencapai lebih daripada 100,000. Jadi artikel ini terutamanya memperkenalkan di mana Redis adalah pantas Perkara utama adalah seperti berikut:
1 Bahasa pembangunan
Sekarang kita semua menggunakan bahasa peringkat tinggi untuk. pengaturcaraan, seperti Java, python dll. Anda mungkin berfikir bahawa bahasa C adalah sangat lama, tetapi ia benar-benar berguna Lagipun, sistem Unix dilaksanakan dalam C, jadi bahasa C adalah bahasa yang sangat dekat dengan sistem pengendalian. Redis dibangunkan dalam bahasa C, jadi pelaksanaan akan lebih cepat.
Seperkara lagi, pelajar harus fokus pada pembelajaran bahasa C kerana ia membantu memahami sistem pengendalian komputer dengan lebih baik. Jangan fikir selepas belajar bahasa peringkat tinggi, anda tidak perlu memberi perhatian kepada lapisan bawah. Berikut ialah buku yang lebih sukar untuk dicadangkan, "Pemahaman Mendalam Sistem Pengkomputeran".
2. Akses memori tulen
Redis menggunakan memori untuk menyimpan semua data, jadi tidak perlu membaca data dari cakera untuk penyegerakan bukan data semasa operasi biasa, jadi Bilangan IO ialah 0. Masa tindak balas memori adalah kira-kira 100 nanosaat, yang merupakan asas penting untuk kelajuan pantas Redis. Mari kita lihat dahulu kelajuan CPU:
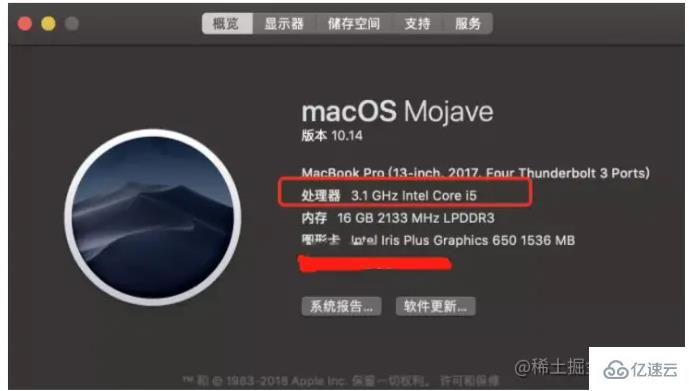
Mengambil komputer saya sebagai contoh, kekerapan utamanya ialah 3.1G, yang bermaksud ia boleh melaksanakan 3.1 bilion arahan sesaat. Kelajuan pemprosesan pandangan dunia CPU adalah sangat perlahan Sebagai perbandingan, memori adalah 100 kali lebih perlahan dan cakera adalah 1,000,000 kali lebih perlahan.
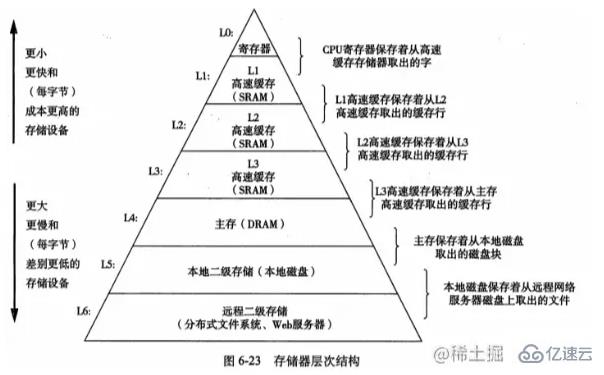
Saya meminjam gambar daripada "Pemahaman Mendalam Sistem Komputer", yang menunjukkan hierarki memori biasa Pada lapisan L0, CPU boleh mengaksesnya dalam satu kitaran jam, dan cache berasaskan SRAM diperbaharui. Mereka boleh diakses dalam beberapa kitaran jam CPU, dan kemudian memori utama berasaskan DRAM, yang boleh diakses dalam puluhan hingga ratusan kitaran jam.
3. Benang tunggal
Benang tunggal boleh memudahkan pelaksanaan algoritma, tetapi melaksanakan struktur data serentak bukan sahaja sukar tetapi juga sukar untuk diuji. Dalam pembangunan bahagian pelayan, kunci dan penukaran benang biasanya merupakan pembunuh prestasi, dan menggunakan satu utas boleh mengelakkan penggunaan yang mereka bawa. Sudah tentu, benang tunggal juga akan mempunyai kekurangannya, yang juga mimpi ngeri Redis: menyekat. Jika pelaksanaan perintah terlalu panjang, ia akan menyebabkan arahan lain disekat, yang sangat mematikan untuk Redis, jadi Redis ialah pangkalan data untuk senario pelaksanaan pantas.
Selain Redis, Node.js juga berbenang tunggal, dan Nginx juga berbenang tunggal, tetapi kedua-duanya adalah model pelayan berprestasi tinggi.
4. Mekanisme pemultipleksan I/O berbilang saluran yang tidak menyekat
Sebelum itu, mari kita bincangkan cara penyekatan tradisional I/O berfungsi: apabila menggunakan Apabila dibaca atau tulis membaca atau menulis deskriptor fail tertentu (File Descriptor FD), jika data tidak diterima, benang akan digantung sehingga data diterima.
Walaupun model penyekatan mudah difahami, ia tidak akan digunakan apabila berbilang tugasan pelanggan perlu diproses.
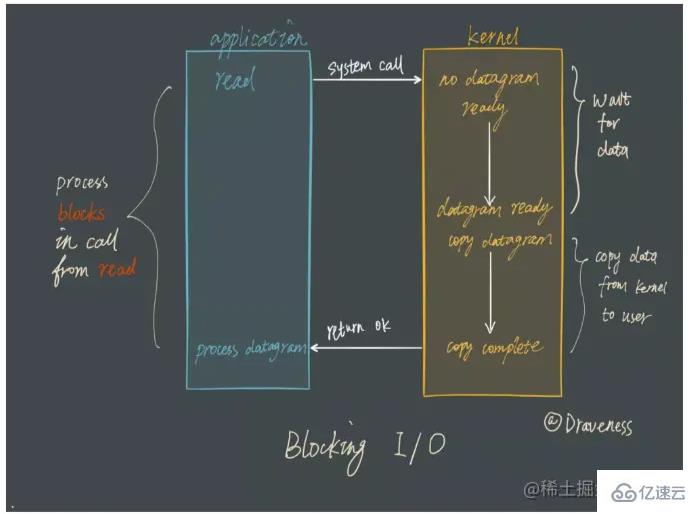
Pemultipleksan I/O sebenarnya bermakna pengurusan berbilang sambungan boleh berada dalam proses yang sama. Berbilang saluran merujuk kepada sambungan rangkaian, pemultipleksan hanyalah benang yang sama. Dalam perkhidmatan rangkaian, peranan pemultipleksan I/O adalah untuk memberitahu kod perniagaan tentang berbilang peristiwa sambungan pada satu masa Kaedah pemprosesan ditentukan oleh kod perniagaan.
Dalam model pemultipleksan I/O, panggilan fungsi yang paling penting ialah fungsi pemultipleksan I/O Kaedah ini boleh memantau pembacaan dan penulisan beberapa deskriptor fail (fd) pada masa yang sama fd boleh dibaca/boleh ditulis, kaedah ini akan mengembalikan bilangan fd boleh dibaca/ditulis.
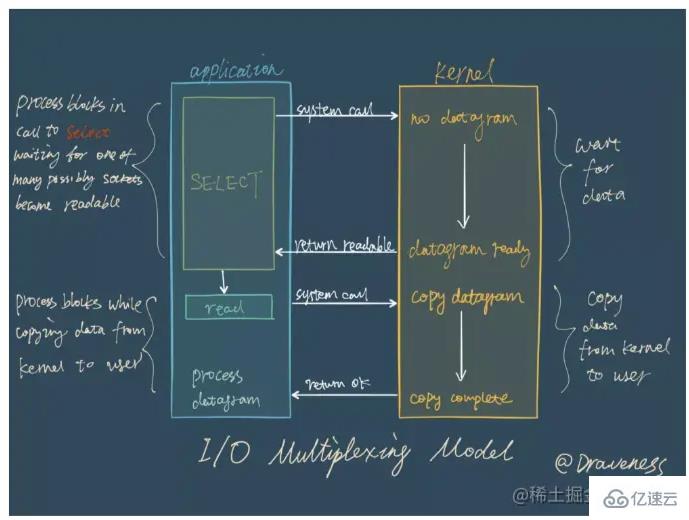
Redis menggunakan epoll sebagai pelaksanaan teknologi pemultipleksan I/O, dan model pemprosesan acara Redis sendiri menukar acara baca, tulis, tutup, dsb. epoll tanpa membuang terlalu banyak masa pada rangkaian I/O. Realisasikan pemantauan berbilang bacaan dan tulis FD untuk meningkatkan prestasi.
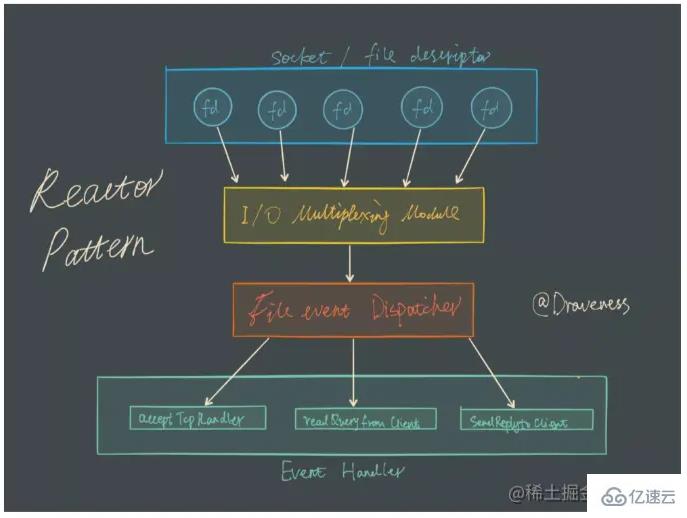
Mari kita berikan contoh yang jelas. Sebagai contoh, pelayan tcp mengendalikan 20 soket pelanggan.
Pelan A: Pemprosesan berurutan Jika soket pertama lambat membaca data disebabkan kad rangkaian, sebaik sahaja ia disekat, selebihnya akan menjadi kacau.
Pelan B: Buat sub-proses klon untuk setiap permintaan soket Apatah lagi setiap proses menggunakan banyak sumber sistem dengan hanya menukar proses sudah cukup untuk meletihkan sistem pengendalian.
Skim C (model pemultipleksan I/O, epoll): Daftarkan fd yang sepadan dengan soket pengguna ke dalam epoll (sebenarnya apa yang dihantar antara pelayan dan sistem pengendalian bukanlah fd soket tetapi struktur data fd_set ), dan kemudian epoll Hanya beritahu soket yang perlu dibaca/ditulis, dan hanya perlu memproses fd soket yang aktif dan berubah itu.
Dengan cara ini, keseluruhan proses hanya akan disekat apabila epoll dipanggil, dan penghantaran serta penerimaan mesej pelanggan tidak akan disekat.
Atas ialah kandungan terperinci Mengapa Redis begitu pantas?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Mod Redis cluster menyebarkan contoh Redis ke pelbagai pelayan melalui sharding, meningkatkan skalabilitas dan ketersediaan. Langkah -langkah pembinaan adalah seperti berikut: Buat contoh Redis ganjil dengan pelabuhan yang berbeza; Buat 3 contoh sentinel, memantau contoh redis dan failover; Konfigurasi fail konfigurasi sentinel, tambahkan pemantauan maklumat contoh dan tetapan failover; Konfigurasi fail konfigurasi contoh Redis, aktifkan mod kluster dan tentukan laluan fail maklumat kluster; Buat fail nodes.conf, yang mengandungi maklumat setiap contoh Redis; Mulakan kluster, laksanakan perintah Buat untuk membuat kluster dan tentukan bilangan replika; Log masuk ke kluster untuk melaksanakan perintah maklumat kluster untuk mengesahkan status kluster; buat
 Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Menggunakan Arahan Redis memerlukan langkah -langkah berikut: Buka klien Redis. Masukkan arahan (nilai kunci kata kerja). Menyediakan parameter yang diperlukan (berbeza dari arahan ke arahan). Tekan Enter untuk melaksanakan arahan. Redis mengembalikan tindak balas yang menunjukkan hasil operasi (biasanya OK atau -r).
 Cara membersihkan data redis
Apr 10, 2025 pm 10:06 PM
Cara membersihkan data redis
Apr 10, 2025 pm 10:06 PM
Cara Mengosongkan Data Redis: Gunakan perintah Flushall untuk membersihkan semua nilai utama. Gunakan perintah flushdb untuk membersihkan nilai utama pangkalan data yang dipilih sekarang. Gunakan Pilih untuk menukar pangkalan data, dan kemudian gunakan FlushDB untuk membersihkan pelbagai pangkalan data. Gunakan perintah DEL untuk memadam kunci tertentu. Gunakan alat REDIS-CLI untuk membersihkan data.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Cara membaca kod sumber redis
Apr 10, 2025 pm 08:27 PM
Cara membaca kod sumber redis
Apr 10, 2025 pm 08:27 PM
Cara terbaik untuk memahami kod sumber REDIS adalah dengan langkah demi langkah: Dapatkan akrab dengan asas -asas Redis. Pilih modul atau fungsi tertentu sebagai titik permulaan. Mulakan dengan titik masuk modul atau fungsi dan lihat baris kod mengikut baris. Lihat kod melalui rantaian panggilan fungsi. Berhati -hati dengan struktur data asas yang digunakan oleh REDIS. Kenal pasti algoritma yang digunakan oleh Redis.
 Cara Melihat Semua Kekunci di Redis
Apr 10, 2025 pm 07:15 PM
Cara Melihat Semua Kekunci di Redis
Apr 10, 2025 pm 07:15 PM
Untuk melihat semua kunci di Redis, terdapat tiga cara: Gunakan perintah kunci untuk mengembalikan semua kunci yang sepadan dengan corak yang ditentukan; Gunakan perintah imbasan untuk melangkah ke atas kunci dan kembalikan satu set kunci; Gunakan arahan maklumat untuk mendapatkan jumlah kunci.
 Cara melaksanakan redis yang mendasari
Apr 10, 2025 pm 07:21 PM
Cara melaksanakan redis yang mendasari
Apr 10, 2025 pm 07:21 PM
Redis menggunakan jadual hash untuk menyimpan data dan menyokong struktur data seperti rentetan, senarai, jadual hash, koleksi dan koleksi yang diperintahkan. Redis berterusan data melalui snapshots (RDB) dan menambah mekanisme tulis sahaja (AOF). Redis menggunakan replikasi master-hamba untuk meningkatkan ketersediaan data. Redis menggunakan gelung acara tunggal untuk mengendalikan sambungan dan arahan untuk memastikan atom dan konsistensi data. Redis menetapkan masa tamat tempoh untuk kunci dan menggunakan mekanisme memadam malas untuk memadamkan kunci tamat tempoh.
 Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Untuk membaca giliran dari Redis, anda perlu mendapatkan nama giliran, membaca unsur -unsur menggunakan arahan LPOP, dan memproses barisan kosong. Langkah-langkah khusus adalah seperti berikut: Dapatkan nama giliran: Namakannya dengan awalan "giliran:" seperti "giliran: my-queue". Gunakan arahan LPOP: Keluarkan elemen dari kepala barisan dan kembalikan nilainya, seperti LPOP Queue: My-Queue. Memproses Baris kosong: Jika barisan kosong, LPOP mengembalikan nihil, dan anda boleh menyemak sama ada barisan wujud sebelum membaca elemen.
