

Analisis contoh pengoptimuman Redis

Dimensi Memori
Kawal panjang kunci
Kekunci biasanya menggunakan rentetan, dan struktur data asas rentetan ialah SDS Struktur SDS akan merangkumi panjang rentetan, peruntukan Metadata maklumat seperti saiz ruang. Apabila panjang rentetan kunci bertambah, metadata dalam SDS juga akan menduduki lebih banyak ruang memori Untuk mengurangkan ruang yang diduduki oleh kunci, kita boleh menggunakan singkatan bahasa Inggeris yang sepadan mengikut nama perniagaan untuk mewakilinya. Sebagai contoh, pengguna diwakili oleh u, dan mesej diwakili oleh m.
Elakkan menyimpan kunci besar
Kita perlu memberi perhatian kepada kedua-dua panjang kunci dan saiz nilai Redis menggunakan satu utas untuk membaca dan menulis data of bigkey akan menyekat benang dan mengurangkan kecekapan pemprosesan Redis.
Cara membuat pertanyaan bigkey
Kita boleh menggunakan perintah --bigkey untuk melihat maklumat bigkey yang diduduki dalam Redis Perintah khusus adalah seperti berikut:
redis-cli -h 127.0.0.1 -p 6379 -a 'xxx' --bigkeys
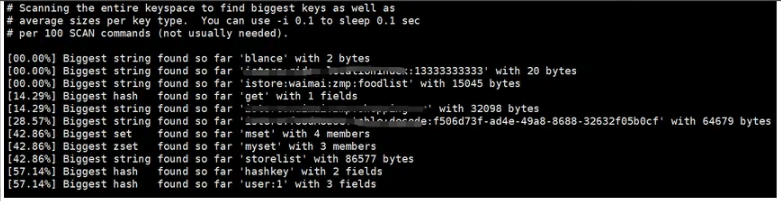
Seperti yang ditunjukkan dalam rajah di atas, kita dapat melihat bahawa kunci dalam Redis menduduki 32098 bait dan perlu dioptimumkan.
Syor:
Jika kunci daripada jenis rentetan, adalah disyorkan bahawa saiz nilai yang disimpan dalam nilai ialah kira-kira 10KB .
Jika kunci adalah jenis List/Hash/Set/ZSet, adalah disyorkan bahawa bilangan elemen yang disimpan dikawal di bawah 10,000.
Pilih jenis data yang sesuai
Redis dioptimumkan untuk jenis data yang disimpannya dan juga mengoptimumkan memori dengan sewajarnya. Untuk pengetahuan yang berkaitan tentang hasil data, anda boleh merujuk artikel sebelumnya.
Contohnya: String dan set akan menggunakan pengekodan integer apabila menyimpan data int. Hash dan ZSet akan menggunakan storan senarai (ziplist) yang dimampatkan apabila bilangan elemen agak kecil, dan akan ditukar menjadi jadual cincang dan melompat jadual apabila jumlah data yang agak besar disimpan.
Menggunakan kaedah bersiri dan mampatan yang cekap
String dalam Redis disimpan menggunakan tatasusunan bait selamat binari, jadi kami boleh mensiri data perniagaan menjadi binari dan menulisnya ke Redis , tetapi menggunakan siri yang berbeza, ruang yang diduduki adalah berbeza. Siri Protostuff adalah lebih cekap daripada siri terbina dalam Java dan mengambil sedikit ruang. Untuk mengurangkan penggunaan ruang, kami boleh memampatkan dan menyimpan format data JSON dan XML. Algoritma pemampatan pilihan termasuk Gzip dan Snappy.
Tetapkan memori maksimum Redis dan strategi penyingkiran
Kami menganggarkan saiz memori terlebih dahulu berdasarkan jumlah data perniagaan untuk mengelakkan pengembangan berterusan memori Redis dan menduduki terlalu banyak sumber.
Mengenai cara menetapkan strategi penyingkiran, anda perlu memilih berdasarkan ciri perniagaan sebenar:
volatile-lru / allkeys -lru: Utamakan data yang paling baru diakses
volatile-lfu / allkeys-lfu: Utamakan data yang paling kerap diakses
volatile-ttl: Utamakan data tamat tempoh
volatile-random/allkeys-random: Singkirkan Data secara rawak
Kawal saiz tika Redis
Saiz memori satu tika Redis disyorkan untuk ditetapkan antara 2~6GB. Oleh kerana syot kilat RDB dan penyegerakan data kluster induk-hamba boleh diselesaikan dengan cepat, pemprosesan permintaan biasa tidak akan disekat.
Kosongkan serpihan memori dengan kerap
Pengubahsuaian baharu yang kerap akan membawa kepada peningkatan dalam serpihan memori, jadi serpihan memori perlu dibersihkan mengikut masa.
Redis menyediakan arahan memori Info untuk melihat maklumat penggunaan memori, seperti berikut:
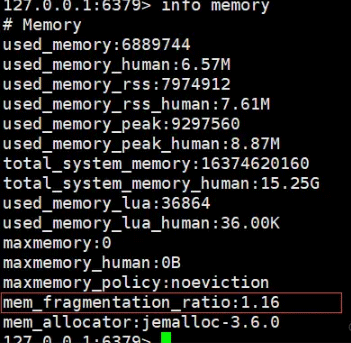
Arahan:
used_memory_rss ialah ruang memori fizikal yang sebenarnya diperuntukkan kepada Redis oleh sistem pengendalian.
used_memory ialah ruang yang sebenarnya dipohon oleh Redis untuk menyimpan data.
mem_fragmentation_ratio=used_memory_rss/ used_memory
mem_fragmentation_ratio lebih besar daripada 1 tetapi kurang daripada 1.5. Keadaan ini adalah munasabah.
Jika mem_fragmentation_ratio lebih besar daripada 1.5, bermakna kadar pemecahan memori telah mencapai lebih daripada 50%. Dalam kes ini, biasanya perlu mengambil beberapa langkah untuk mengurangkan kadar pemecahan memori. Langkah pembersihan memori khusus akan diterangkan dalam artikel seterusnya.
Dimensi Prestasi
Melarang penggunaan perintah KEYS, FLUSHALL dan FLUSHDB
KEYS padanan mengikut kandungan utama dan mengembalikan padanan yang sepadan Pasangan nilai kunci syarat ini memerlukan imbasan jadual penuh bagi jadual cincang global Redis, yang menyekat urutan utama Redis dengan serius.
FLUSHALL memadamkan semua data pada tika Redis Jika jumlah data adalah besar, ia akan menyekat urutan utama Redis dengan serius.
FLUSHDB, memadamkan data dalam pangkalan data semasa Jika jumlah data adalah besar, ia akan menyekat utas utama Redis.
Cadangan pengoptimuman
Kami perlu melumpuhkan arahan ini dalam talian. Kaedah khusus ialah pentadbir menggunakan perintah rename-command untuk menamakan semula arahan ini dalam fail konfigurasi supaya klien tidak boleh menggunakan arahan ini.
慎用全量操作的命令
对于集合类型的来说,在未清楚集合数据大小的情况下,慎用查询集合中的全量数据,例如Hash的HetALL、Set的SMEMBERS命令、LRANGE key 0 -1 或者ZRANGE key 0 -1等命令,因为这些命令会对Hash或者Set类型的底层数据进行全量扫描,当集合数据量比较大时,会阻塞Redis的主线程。
优化建议:
当元素数据量较多时,可以用SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
慎用复杂度过高命令
Redis执行复杂度过高的命令,会消耗更多的 CPU 资源,导致主线程中的其它请求只能等待。常见的复杂命令如下:SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
优化建议:
当需要执行排序、交集、并集操作时,可以在客户端完成,避免让Redis进行过多计算,从而影响Redis性能。
设置合适的过期时间
Redis通常用于保存热数据。热数据一般都有使用的时效性。因此,在数据存储的过程中,应根据业务对数据的使用时间合理地设置数据的过期时间。否则写入Redis的数据会一直占用内存,如果数据持续增增长,会达到机器的内存上限,造成内存溢出,导致服务崩溃。
采用批量命令代替个命令
当我们需要一次性操作多个key时,可以使用批量命令来处理,批量命令可以减少客户端与服务端的来回网络IO次数。
String或者Hash类型可以使用 MGET/MSET替代 GET/SET,HMGET/HMSET替代HGET/HSET
其它数据类型使用Pipeline命令,一次性打包发送多个命令到服务端执行。
Pipeline具体使用:
redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 5; i++)
{
connection.set(("test:" + i).getBytes(), "test".getBytes());
}
return null;
}
});高可用维度
按照业务部署不同的实例
不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
避免单点问题
业务上根据实际情况采用主从、哨兵、集群方案,避免单点故障,影响业务的正常使用。
合理的设置相关参数
针对主从环境,我们需要合理设置相关参数,具体内容如下:
合理的设置repl-backlog参数:如果repl-backlog设置过小,当写流量比较大的场景下,主从复制中断可能会引发全量复制数据的风险。
合理设置slave client-output-buffer-limit:当从库复制发生问题时,过小的 buffer会导致从库缓冲区溢出,从而导致复制中断。
Atas ialah kandungan terperinci Analisis contoh pengoptimuman Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Mod Redis cluster menyebarkan contoh Redis ke pelbagai pelayan melalui sharding, meningkatkan skalabilitas dan ketersediaan. Langkah -langkah pembinaan adalah seperti berikut: Buat contoh Redis ganjil dengan pelabuhan yang berbeza; Buat 3 contoh sentinel, memantau contoh redis dan failover; Konfigurasi fail konfigurasi sentinel, tambahkan pemantauan maklumat contoh dan tetapan failover; Konfigurasi fail konfigurasi contoh Redis, aktifkan mod kluster dan tentukan laluan fail maklumat kluster; Buat fail nodes.conf, yang mengandungi maklumat setiap contoh Redis; Mulakan kluster, laksanakan perintah Buat untuk membuat kluster dan tentukan bilangan replika; Log masuk ke kluster untuk melaksanakan perintah maklumat kluster untuk mengesahkan status kluster; buat
 Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Menggunakan Arahan Redis memerlukan langkah -langkah berikut: Buka klien Redis. Masukkan arahan (nilai kunci kata kerja). Menyediakan parameter yang diperlukan (berbeza dari arahan ke arahan). Tekan Enter untuk melaksanakan arahan. Redis mengembalikan tindak balas yang menunjukkan hasil operasi (biasanya OK atau -r).
 Cara membersihkan data redis
Apr 10, 2025 pm 10:06 PM
Cara membersihkan data redis
Apr 10, 2025 pm 10:06 PM
Cara Mengosongkan Data Redis: Gunakan perintah Flushall untuk membersihkan semua nilai utama. Gunakan perintah flushdb untuk membersihkan nilai utama pangkalan data yang dipilih sekarang. Gunakan Pilih untuk menukar pangkalan data, dan kemudian gunakan FlushDB untuk membersihkan pelbagai pangkalan data. Gunakan perintah DEL untuk memadam kunci tertentu. Gunakan alat REDIS-CLI untuk membersihkan data.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Cara membaca kod sumber redis
Apr 10, 2025 pm 08:27 PM
Cara membaca kod sumber redis
Apr 10, 2025 pm 08:27 PM
Cara terbaik untuk memahami kod sumber REDIS adalah dengan langkah demi langkah: Dapatkan akrab dengan asas -asas Redis. Pilih modul atau fungsi tertentu sebagai titik permulaan. Mulakan dengan titik masuk modul atau fungsi dan lihat baris kod mengikut baris. Lihat kod melalui rantaian panggilan fungsi. Berhati -hati dengan struktur data asas yang digunakan oleh REDIS. Kenal pasti algoritma yang digunakan oleh Redis.
 Cara Melihat Semua Kekunci di Redis
Apr 10, 2025 pm 07:15 PM
Cara Melihat Semua Kekunci di Redis
Apr 10, 2025 pm 07:15 PM
Untuk melihat semua kunci di Redis, terdapat tiga cara: Gunakan perintah kunci untuk mengembalikan semua kunci yang sepadan dengan corak yang ditentukan; Gunakan perintah imbasan untuk melangkah ke atas kunci dan kembalikan satu set kunci; Gunakan arahan maklumat untuk mendapatkan jumlah kunci.
 Cara melaksanakan redis yang mendasari
Apr 10, 2025 pm 07:21 PM
Cara melaksanakan redis yang mendasari
Apr 10, 2025 pm 07:21 PM
Redis menggunakan jadual hash untuk menyimpan data dan menyokong struktur data seperti rentetan, senarai, jadual hash, koleksi dan koleksi yang diperintahkan. Redis berterusan data melalui snapshots (RDB) dan menambah mekanisme tulis sahaja (AOF). Redis menggunakan replikasi master-hamba untuk meningkatkan ketersediaan data. Redis menggunakan gelung acara tunggal untuk mengendalikan sambungan dan arahan untuk memastikan atom dan konsistensi data. Redis menetapkan masa tamat tempoh untuk kunci dan menggunakan mekanisme memadam malas untuk memadamkan kunci tamat tempoh.
 Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Untuk membaca giliran dari Redis, anda perlu mendapatkan nama giliran, membaca unsur -unsur menggunakan arahan LPOP, dan memproses barisan kosong. Langkah-langkah khusus adalah seperti berikut: Dapatkan nama giliran: Namakannya dengan awalan "giliran:" seperti "giliran: my-queue". Gunakan arahan LPOP: Keluarkan elemen dari kepala barisan dan kembalikan nilainya, seperti LPOP Queue: My-Queue. Memproses Baris kosong: Jika barisan kosong, LPOP mengembalikan nihil, dan anda boleh menyemak sama ada barisan wujud sebelum membaca elemen.
