

Amalan penggunaan penyetempatan Alpaca-lora model bahasa besar GPT

Pengenalan model
Model Alpaca ialah model sumber terbuka LLM (Model Bahasa Besar, bahasa besar) yang dibangunkan oleh Universiti Stanford Ia adalah model yang diperhalusi pada arahan 52K daripada LLaMA 7B (7B terbuka sumber oleh Syarikat Meta), dengan 7 bilion parameter model (lebih besar parameter model, lebih kuat keupayaan penaakulan model, dan sudah tentu lebih tinggi kos melatih model).
LoRA, nama penuh bahasa Inggeris ialah Penyesuaian Peringkat Rendah bagi Model Bahasa Besar, diterjemahkan secara literal sebagai penyesuaian tahap rendah model bahasa besar Ini adalah teknologi yang dibangunkan oleh penyelidik Microsoft untuk menyelesaikan penalaan halus model bahasa. Jika anda mahu model bahasa besar yang telah dilatih untuk dapat melaksanakan tugas dalam bidang tertentu, anda biasanya perlu melakukan penalaan halus Walau bagaimanapun, dimensi parameter model bahasa besar yang pada masa ini mahir dalam penaakulan adalah sangat, sangat besar , malah ada yang ratusan bilion dimensi Jika anda secara langsung Melakukan penalaan halus pada model bahasa yang besar akan memerlukan jumlah pengiraan yang sangat besar dan kos yang sangat tinggi.
Pendekatan LoRA adalah untuk membekukan parameter model yang telah dilatih, dan kemudian menyuntik lapisan boleh dilatih ke dalam setiap blok Transformer Memandangkan tidak ada keperluan untuk mengira semula kecerunan parameter model, ia akan mengurangkan kuantiti pengiraan. .
Seperti yang ditunjukkan dalam rajah di bawah, idea teras adalah untuk menambah pintasan pada model asal yang telah dilatih dan melakukan pengurangan dimensi dan kemudian operasi dimensi. Semasa latihan, parameter model pra-latihan adalah tetap, dan hanya matriks pengurangan dimensi A dan matriks peningkatan dimensi B dilatih. Dimensi input dan output model kekal tidak berubah, dan BA dan parameter model bahasa pra-latihan ditindih pada output.
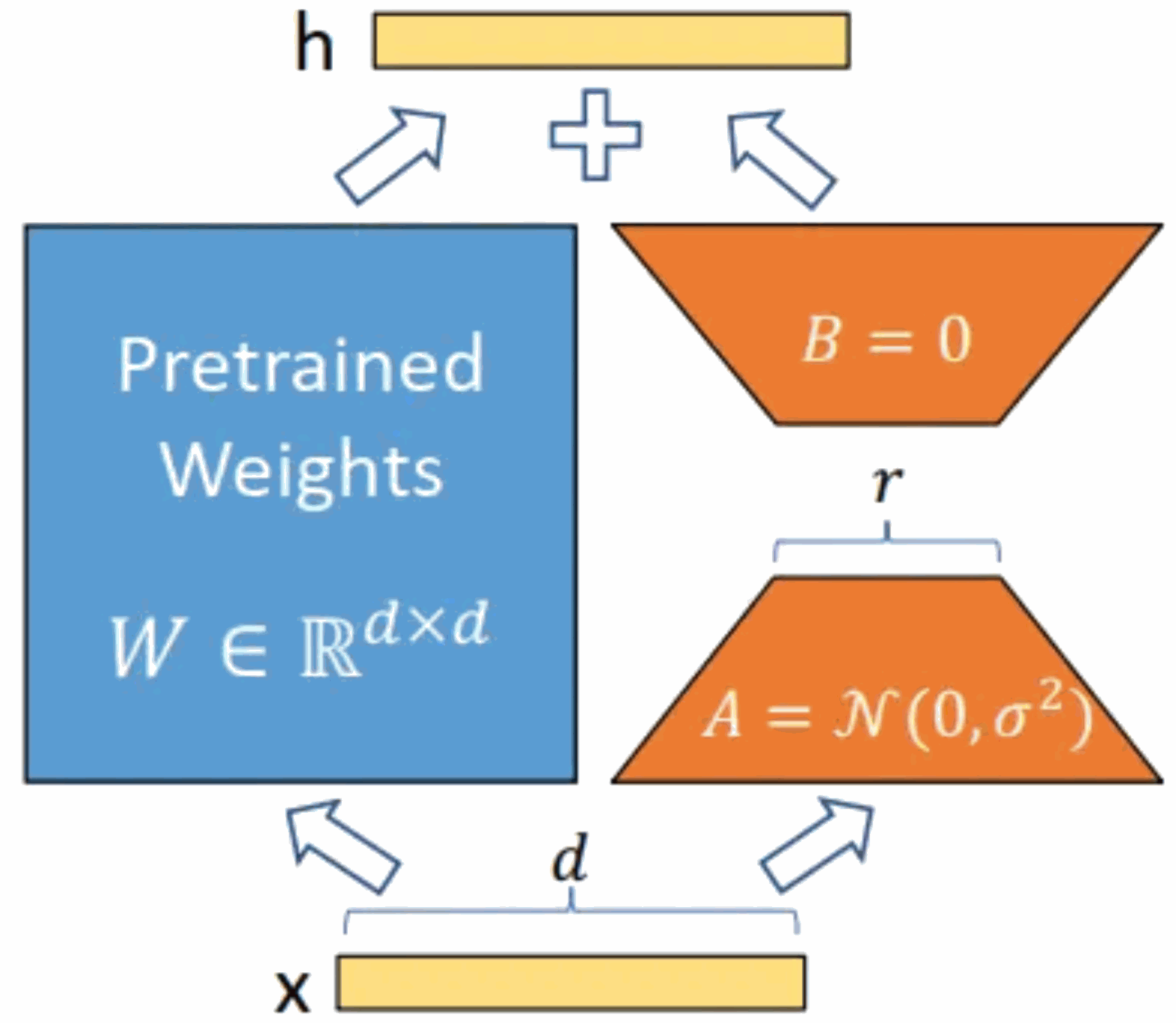
Mulakan A dengan taburan Gaussian rawak dan mulakan B dengan matriks 0. Ini memastikan bahawa BA=0 pintasan baharu semasa latihan, dengan itu tidak memberi kesan kepada keputusan model. Semasa penaakulan, hasil bahagian kiri dan kanan ditambah bersama, iaitu, h=Wx+BAx=(W+BA)x Oleh itu, tambahkan sahaja produk matriks BA selepas latihan dan matriks berat asal W sebagai yang baharu berat. Parameter boleh digantikan dengan W model bahasa asal yang telah dilatih, dan tiada sumber pengkomputeran tambahan akan ditambahkan. Kelebihan terbesar LoRA ialah ia melatih lebih cepat dan menggunakan kurang memori.
Model Alpaca-lora yang digunakan untuk amalan penggunaan setempat dalam artikel ini ialah versi tersuai tertib rendah bagi model Alpaca. Artikel ini akan mempraktikkan proses penempatan penyetempatan, penalaan halus dan inferens model Alpaca-lora dan menerangkan langkah-langkah yang berkaitan.
Pengaturan persekitaran pelayan GPU
Pelayan GPU yang digunakan dalam artikel ini mempunyai 4 GPU bebas, modelnya ialah P40 dan satu P40 mempunyai pengkomputeran yang sama kuasa sebagai 60 Kuasa pengkomputeran CPU dengan frekuensi utama yang sama.

Jika anda merasakan bahawa kad fizikal terlalu mahal hanya untuk ujian, anda juga boleh menggunakan "versi pengganti" - pelayan awan GPU. Berbanding dengan kad fizikal, membina pelayan awan GPU bukan sahaja dapat memastikan pengkomputeran berprestasi tinggi yang fleksibel, tetapi juga mempunyai faedah ini -
- Prestasi kos tinggi: dibilkan mengikut jam, hanya sedozen yuan sejam , anda boleh Deploy mengikut keperluan anda pada bila-bila masa dengan kelebihan pengkomputeran awan seperti pengurusan sumber yang fleksibel, kebolehskalaan dan penskalaan elastik, anda boleh dengan cepat melaraskan sumber pengkomputeran mengikut keperluan latihan perniagaan atau peribadi untuk memenuhi latihan dan penggunaan model keperluan;
- Ciri Terbuka: Keterbukaan pengkomputeran awan memudahkan pengguna untuk berkongsi dan bekerjasama dalam sumber, menyediakan peluang kerjasama yang lebih luas untuk penyelidikan dan aplikasi model AI
- API yang Kaya dan SDK: Vendor pengkomputeran awan menyediakan API Kaya dan SDK membolehkan pengguna mengakses pelbagai perkhidmatan dan fungsi platform awan dengan mudah untuk pembangunan dan penyepaduan tersuai.
Hos awan GPU JD Cloud sedang melakukan 618 aktiviti, yang sangat menjimatkan kos
https://www.php.cn/link/5d3145e1226fd39ee3b3039bfa90c95d
Apabila kami mendapat pelayan GPU, kami mula-mula memasang pemacu kad grafik dan pemacu CUDA (iaitu platform pengkomputeran yang dilancarkan oleh pengeluar kad grafik NVIDIA. CUDA ialah seni bina pengkomputeran selari am dilancarkan oleh NVIDIA, yang membolehkan Keupayaan GPU menyelesaikan masalah pengiraan yang kompleks).
Pemandu kad grafik perlu pergi ke tapak web rasmi NVIDIA untuk mencari model kad grafik yang sepadan dan versi CUDA yang disesuaikan:
https://www.nvidia.com/Download/index.aspx , pilih Anda boleh memuat turun fail pemacu untuk kad grafik dan versi CUDA yang sepadan.
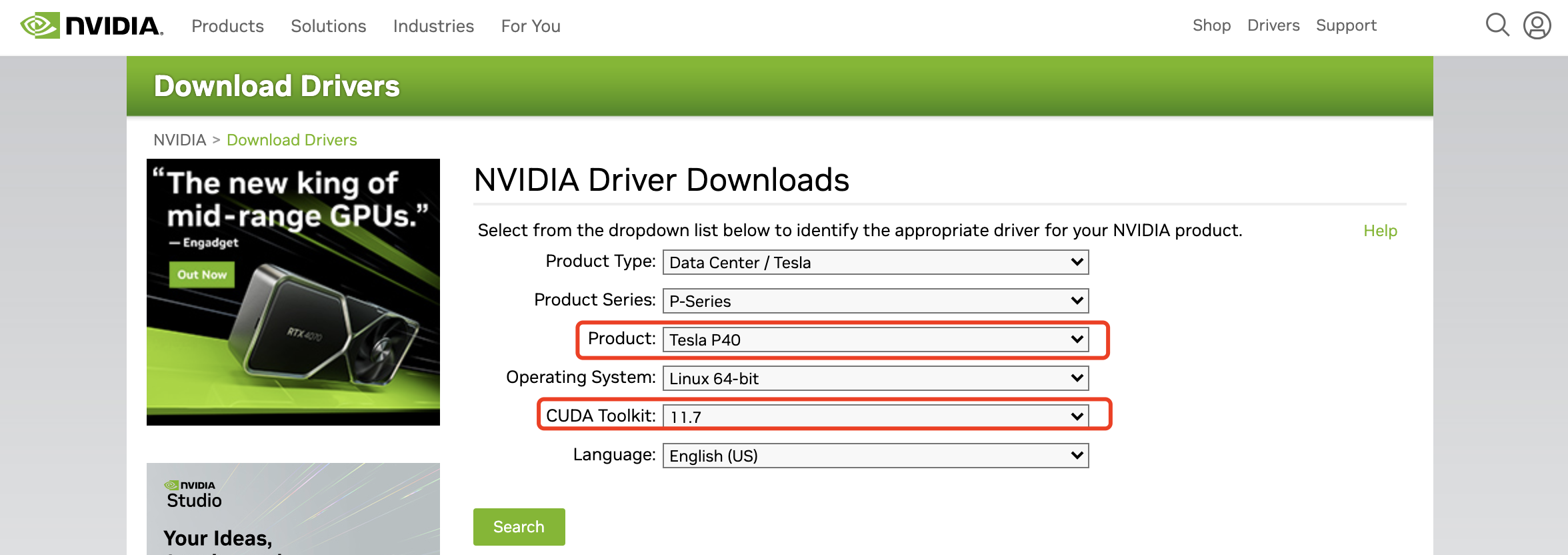
Fail yang saya muat turun ialah
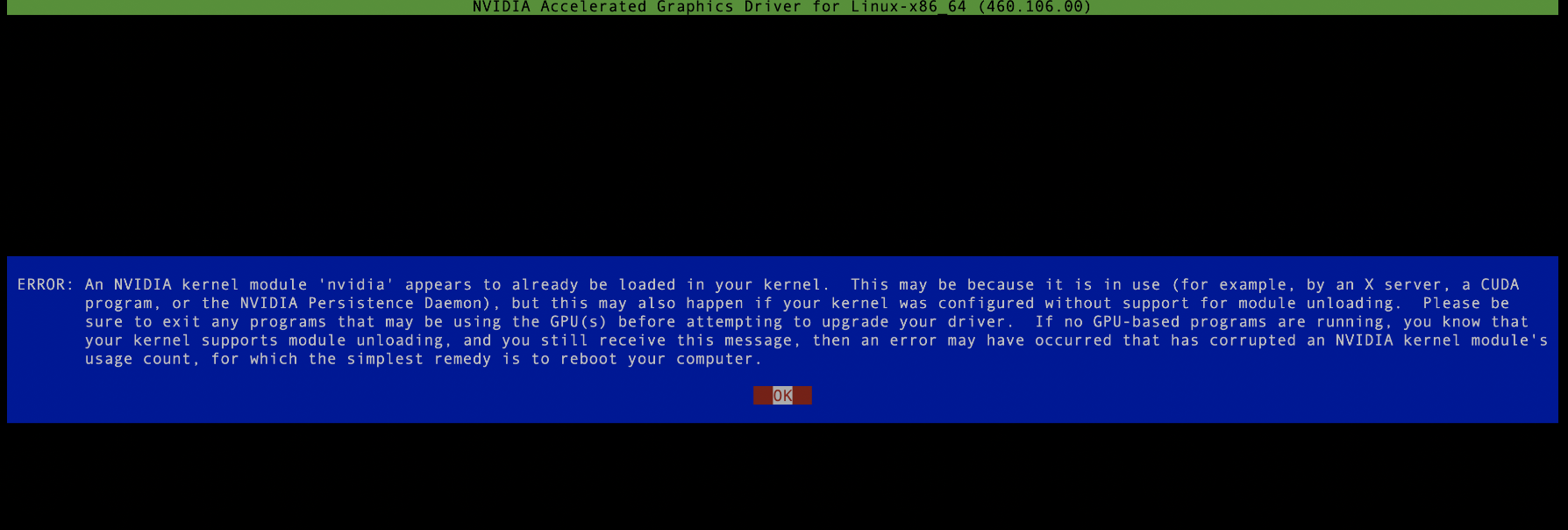
NVIDIA-Linux-x86_64-515.105.01.run, ini adalah fail boleh laku, anda boleh melaksanakannya dengan kebenaran root Ambil perhatian bahawa proses nvidia tidak boleh dijalankan semasa proses pemasangan pemacu. jika tidak, ia akan Pemasangan gagal, seperti yang ditunjukkan dalam rajah di bawah:
Kemudian teruskan ke seterusnya Jika tiada ralat dilaporkan, pemasangan berjaya. Untuk menyemak sumber kad grafik kemudian, lebih baik memasang alat pemantauan kad grafik lain, seperti nvitop, hanya gunakan pip install nvitop Perhatikan di sini bahawa kerana versi ular sawa pelayan berbeza adalah yang terbaik untuk memasang anaconda untuk menggunakan ruang ular sawa peribadi anda untuk mengelakkan Pelbagai ralat pelik berlaku semasa menjalankan:
1. Pasang anaconda /archive/Anaconda3-5.3.0-Linux-x86_64 .sh. Arahan pemasangan: sh Anaconda3-5.3.0-Linux-x86_64.sh Masukkan "ya" untuk setiap langkah pemasangan, dan akhirnya selesaikan pemasangan selepas conda init, supaya setiap kali anda memasuki sesi pengguna pemasangan, anda akan terus memasuki sesi anda sendiri persekitaran python. Jika anda memilih tidak dalam langkah terakhir pemasangan, iaitu conda init tidak dilakukan, anda kemudian boleh memasuki persekitaran python peribadi melalui sumber /home/jd_ad_sfxn/anaconda3/bin/activate.
https://files.pythonhosted.org/packages/26/e5/9897eee1100b166a61f91f91b69528c91b68528c91b68528c91b69528c91b68528c91b68528c91b68528c91b94b9f9b8b8c8c9fbf 4b79/alat persediaan -40.5.0 .zip arahan pemasangan: unzip setuptools-40.5.0.zip cd setuptools-40.5.0/ python setup.py install
https:// files.pythonhosted. org/packages/45/ae/8a0ad77defb7cc903f09e551d88b443304a9bd6e6f124e75c0fbbf6de8f7/pip-18.1.tar.gz Arahan pemasangan: pittar -xz8fcd.piptar. .py pasang
conda create -n alpaca pythnotallow=3.9conda activate alpaca

https://github.com/tloen/alpaca-lora, keseluruhan model adalah sumber terbuka, yang sangat bagus! Mula-mula, muat turun fail model secara tempatan dan laksanakan git clone https://github.com/tloen/alpaca-lora.git.
pip install -r requirements.txt
https://github.com/LC1332/Chinese-alpaca-lora/ blob/main/data/trans_chinese_alpaca_data .json?raw=true, muat turun korpus yang digunakan untuk latihan model kemudian ke direktori akar alpaca-lora (untuk kemudahan penggunaan kemudian).

好的,到现在为止,万里长征已经走完2/3了,别着急训练模型,我们现在验证一下GPU环境和CUDA版本信息,还记得之前我们安装的nvitop嘛,现在就用上了,在本地直接执行nvitop,我们就可以看到GPU环境和CUDA版本信息了,如下图:
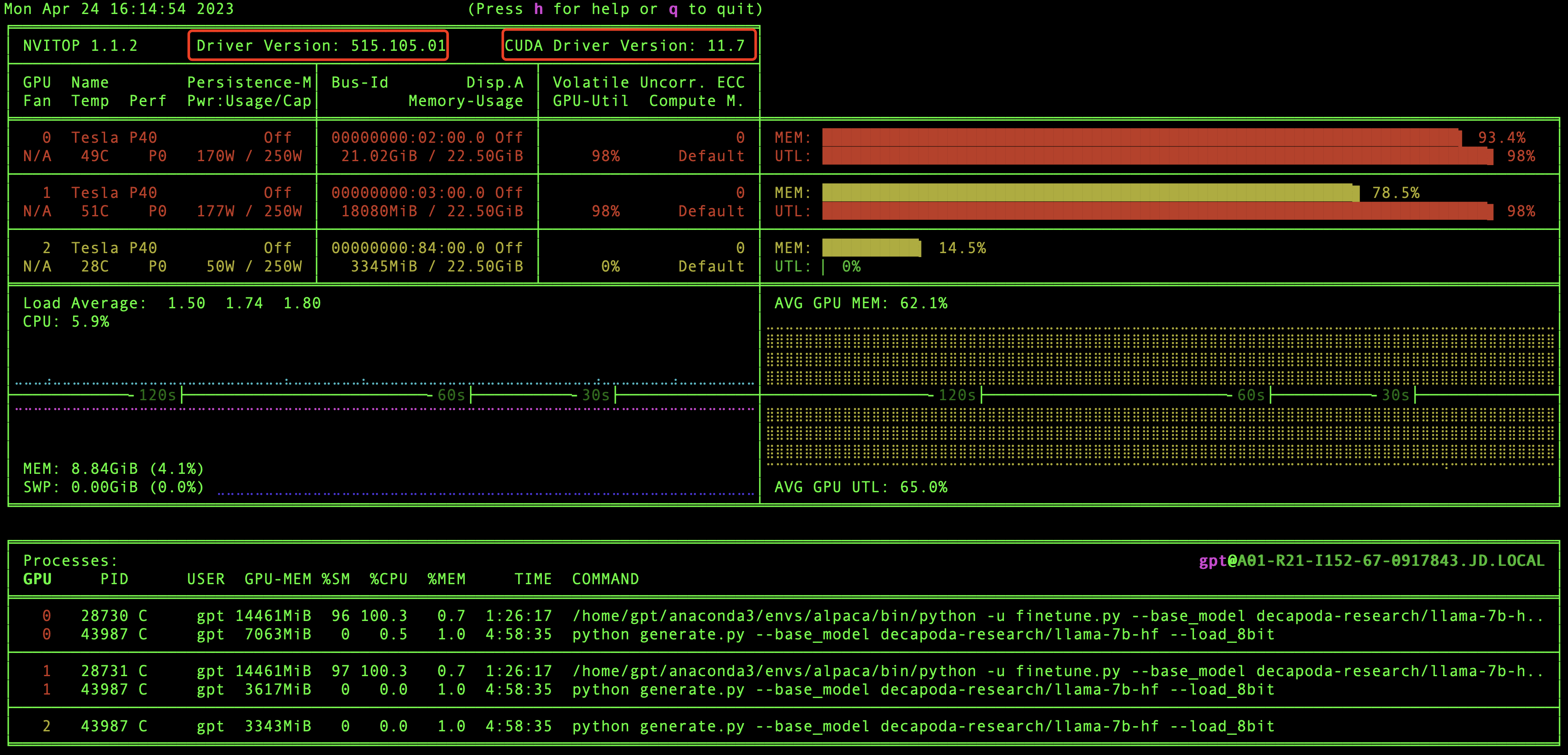
在这里我们能够看到有几块显卡,驱动版本和CUDA版本等信息,当然最重要的我们还能看到GPU资源的实时使用情况。
怎么还没到模型训练呢,别着急呀,这就来啦。
我们先到根目录下然后执行训练模型命令:
如果是单个GPU,那么执行命令即可:
python finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果是多个GPU,则执行:
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun \--nproc_per_node=2 \--master_port=1234 \finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果可以看到进度条在走,说明模型已经启动成功啦。
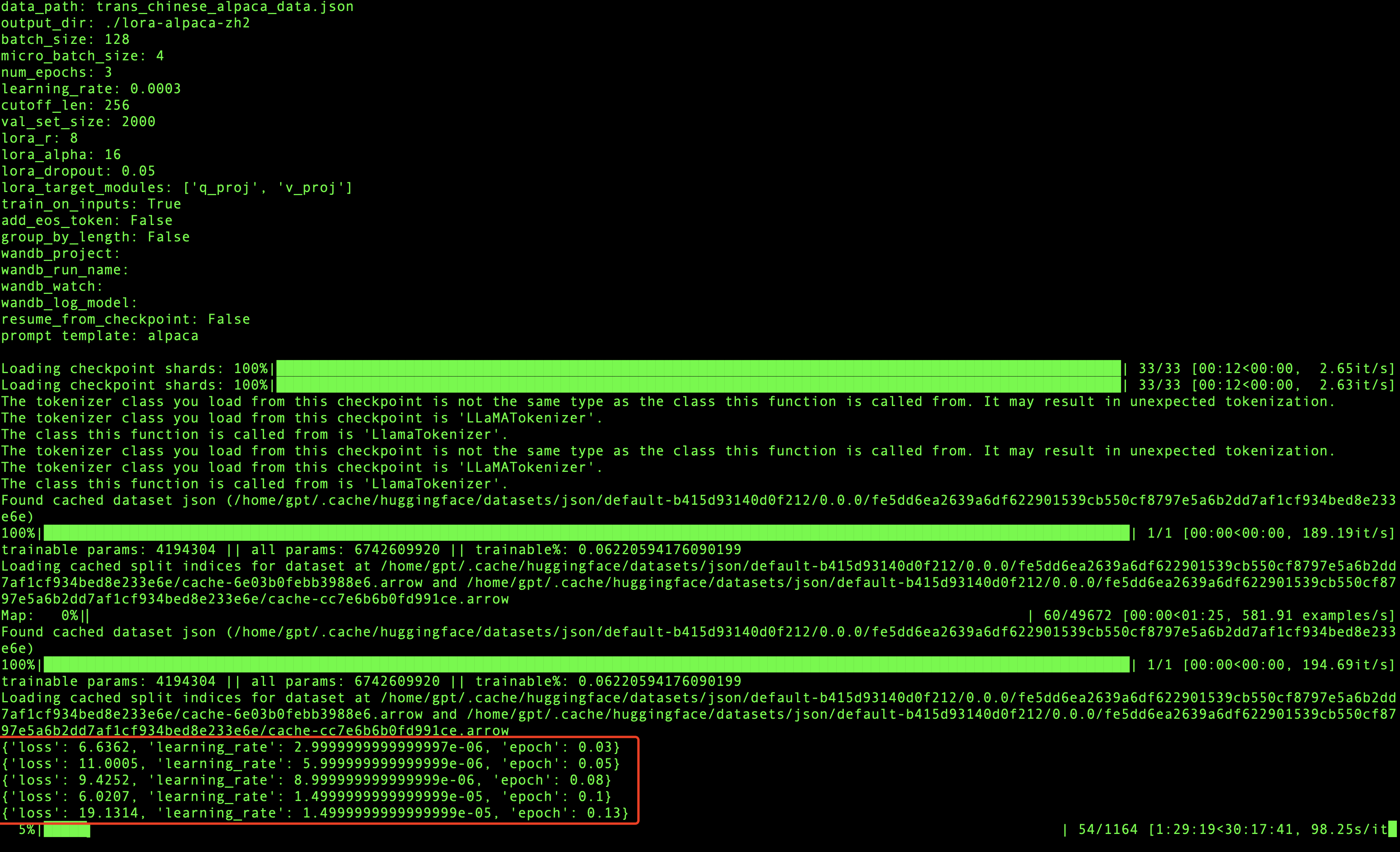
在模型训练过程中,每迭代一定数量的数据就会打印相关的信息,会输出损失率,学习率和代信息,如上图所示,当loss波动较小时,模型就会收敛,最终训练完成。
我用的是2块GPU显卡进行训练,总共训练了1904分钟,也就是31.73个小时,模型就收敛了,模型训练是个漫长的过程,所以在训练的时候我们可以适当的放松一下,做点其他的事情:)。
模型推理
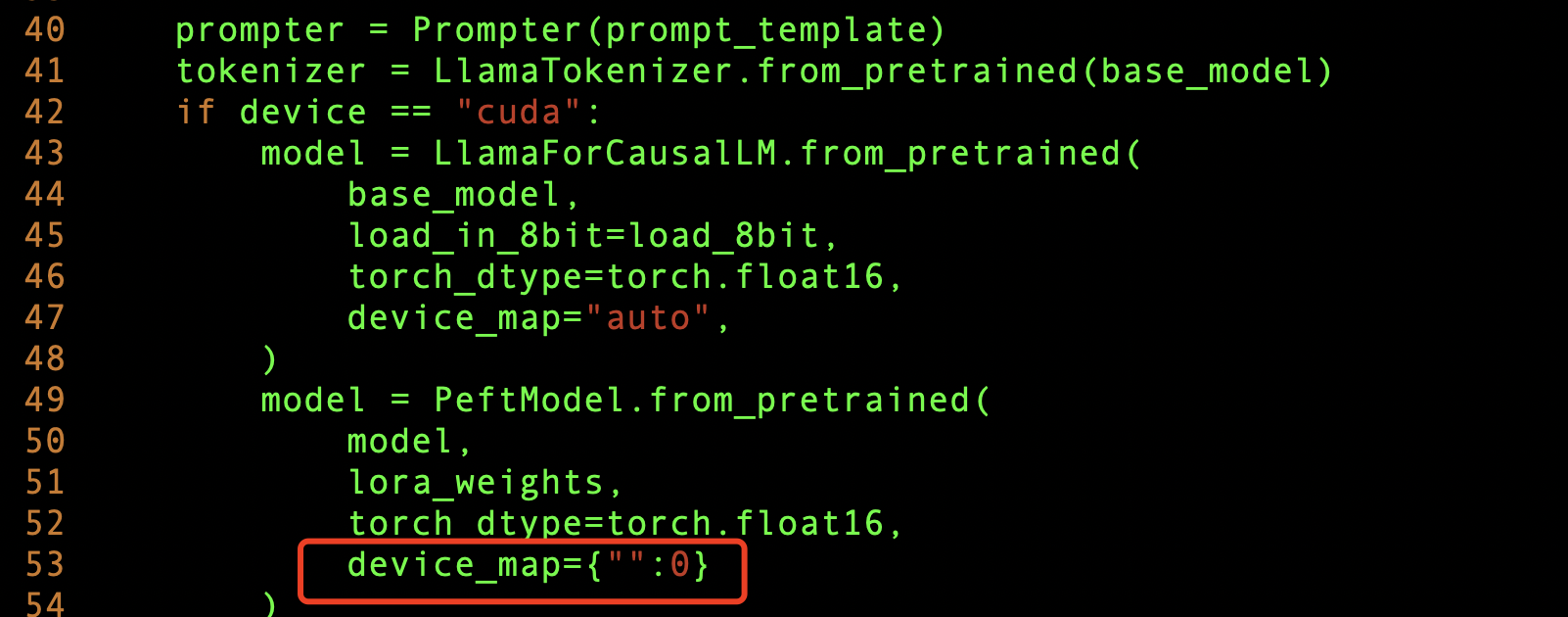
模型训练好后,我们就可以测试一下模型的训练效果了,由于我们是多个GPU显卡,所以想把模型参数加载到多个GPU上,这样会使模型推理的更快,需要修改
generate.py 文件,添加下面这样即可。
然后我们把服务启起来,看看效果,根目录执行:
python generate.py --base_model "decapoda-research/llama-7b-hf" \--lora_weights './lora-alpaca-zh' \--load_8bit
其中./lora-alpaca-zh目录下的文件,就是我们刚刚fine tuning模型训练的参数所在位置,启动服务的时候把它加载到内存(这个内存指的是GPU内存)里面。
如果成功,那么最终会输出相应的IP和Port信息,如下图所示:

我们可以用浏览器访问一下看看,如果能看到页面,就说明服务已经启动成功啦。
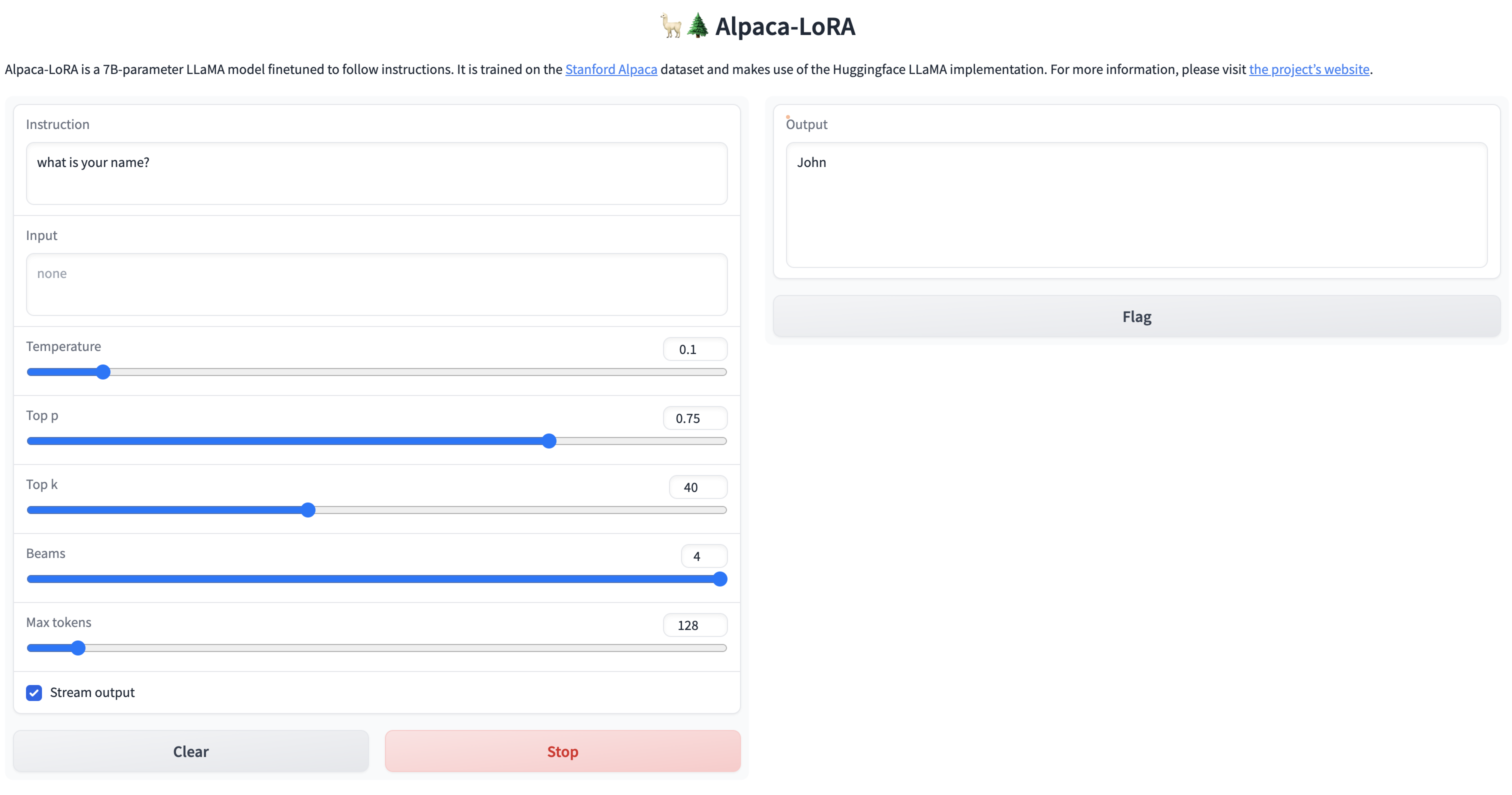
激动ing,费了九牛二虎之力,终于成功啦!!
因为我们目标是让模型说中文,所以我们测试一下对中文的理解,看看效果怎么样?
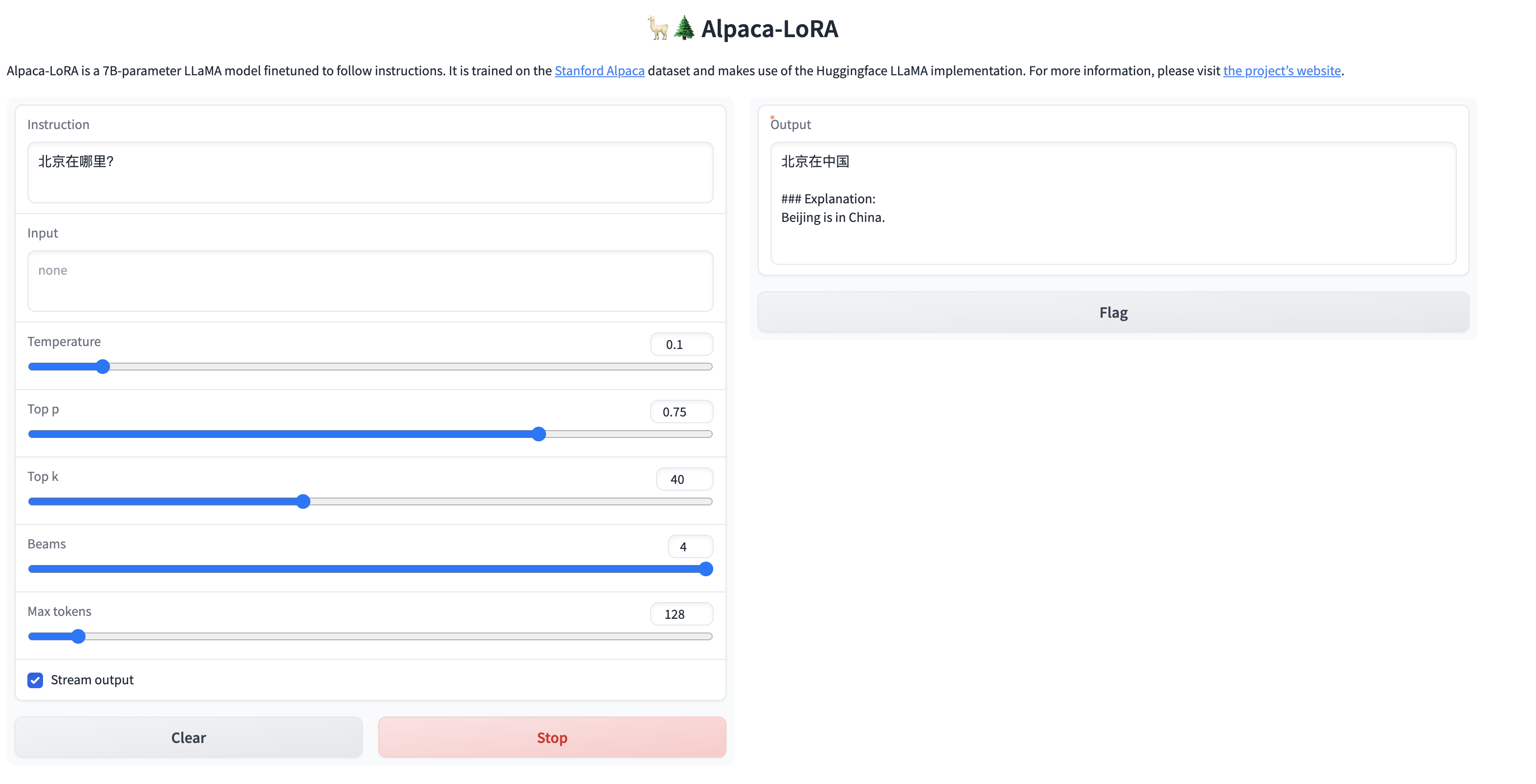
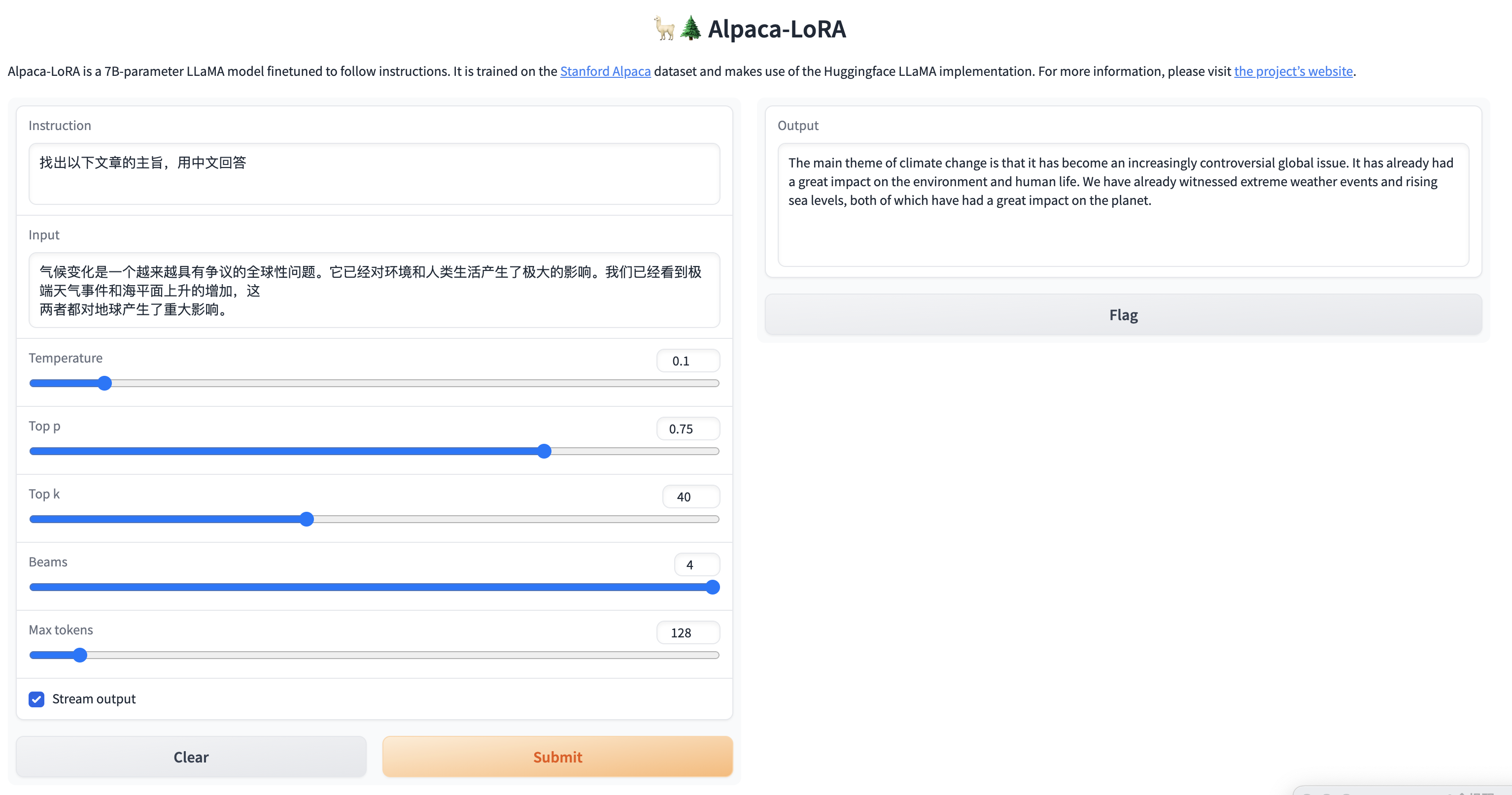
简单的问题,还是能给出答案的,但是针对稍微复杂一点的问题,虽然能够理解中文,但是并没有用中文进行回答,训练后的模型还是不太稳定啊。
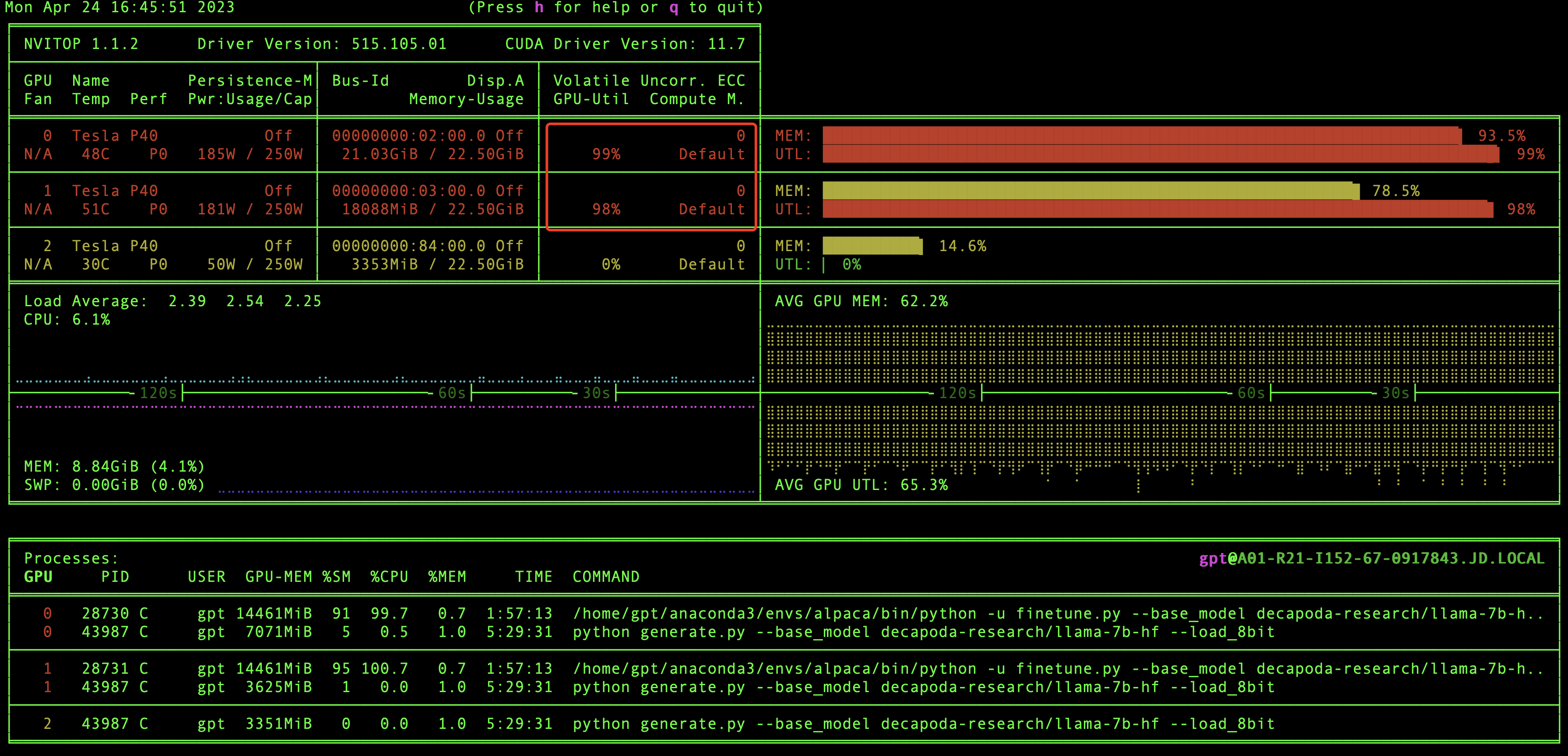
在推理的时候我们也可以监控一下GPU的变化,可以看到GPU负载是比较高的,说明GPU在进行大量的计算来完成推理。
总结
1.效果问题:由于语料库不够丰富,所以目前用社区提供的语料库训练的效果并不是很好,对中文的理解力有限,如果想训练出能够执行特定领域的任务,则需要大量的语料支持,同时训练时间也会更长;
2. Masalah masa inferens: Memandangkan pelayan GPU yang digunakan pada masa ini mempunyai 4 GPU, 3 daripadanya boleh dilaksanakan Berdasarkan 3 GPU, inferens masih agak sukar untuk melaksanakan interaksi kembali dalam masa nyata seperti chatGPT, ia akan memerlukan banyak kuasa pengkomputeran untuk menyokongnya Ia boleh disimpulkan bahawa bahagian belakang chatGPT mesti disokong oleh sekumpulan besar kuasa pengkomputeran, jadi jika anda ingin menjadikannya perkhidmatan, kos. pelaburan adalah isu yang perlu dipertimbangkan;
3 Masalah kod bercelaru: Apabila input adalah bahasa Cina, kadangkala hasil yang dipulangkan akan disyaki berkaitan dengan pembahagian perkataan masalah pengekodan, bahasa Cina tidak dipisahkan oleh ruang seperti bahasa Inggeris, jadi mungkin terdapat ralat tertentu akan berlaku, dan ini juga akan berlaku apabila memanggil API AI terbuka Kami akan melihat jika komuniti mempunyai penyelesaian yang sepadan kemudian 🎜>4. Masalah pemilihan model: Memandangkan komuniti GPT pada masa ini agak aktif, penjanaan dan perubahan model Ia juga berubah setiap hari Disebabkan kesibukan masa, kami hanya menyiasat penggunaan setempat alpaca-. model lora. Perlu ada rancangan pelaksanaan yang lebih baik dan berkos rendah untuk pelaksanaan sebenar pada masa hadapan.
Untuk butiran tentang amalan [model bahasa ChatGLM] GPU model JD Cloud P40:
https://www.php.cn/link/f044bd02e4fe1aa3315ace7645f8597aSumber kandungan: JD Cloud Developer Community
Atas ialah kandungan terperinci Amalan penggunaan penyetempatan Alpaca-lora model bahasa besar GPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
Kertas kerja ini meneroka masalah mengesan objek dengan tepat dari sudut pandangan yang berbeza (seperti perspektif dan pandangan mata burung) dalam pemanduan autonomi, terutamanya cara mengubah ciri dari perspektif (PV) kepada ruang pandangan mata burung (BEV) dengan berkesan dilaksanakan melalui modul Transformasi Visual (VT). Kaedah sedia ada secara amnya dibahagikan kepada dua strategi: penukaran 2D kepada 3D dan 3D kepada 2D. Kaedah 2D-ke-3D meningkatkan ciri 2D yang padat dengan meramalkan kebarangkalian kedalaman, tetapi ketidakpastian yang wujud dalam ramalan kedalaman, terutamanya di kawasan yang jauh, mungkin menimbulkan ketidaktepatan. Manakala kaedah 3D ke 2D biasanya menggunakan pertanyaan 3D untuk mencuba ciri 2D dan mempelajari berat perhatian bagi kesesuaian antara ciri 3D dan 2D melalui Transformer, yang meningkatkan masa pengiraan dan penggunaan.
