

Tafsiran mendalam algoritma persepsi visual 3D untuk pemanduan autonomi

Untuk aplikasi pemanduan autonomi, adalah perlu untuk melihat pemandangan 3D. Alasannya mudah sahaja. Kenderaan tidak boleh memandu berdasarkan hasil persepsi yang diperolehi daripada sesuatu imej. Oleh kerana jarak objek dan maklumat kedalaman tempat kejadian tidak dapat dicerminkan dalam hasil persepsi 2D, maklumat ini adalah kunci untuk sistem pemanduan autonomi untuk membuat pertimbangan yang betul ke atas persekitaran sekeliling.
Secara umumnya, penderia visual (seperti kamera) kenderaan autonomi dipasang di atas badan kenderaan atau pada cermin pandang belakang dalaman. Tidak kira di mana ia berada, apa yang kamera dapat adalah unjuran dunia sebenar dalam pandangan perspektif (sistem koordinat dunia kepada sistem koordinat imej). Pandangan ini serupa dengan sistem visual manusia dan oleh itu mudah difahami oleh pemandu manusia. Tetapi masalah maut dengan pandangan perspektif ialah skala objek berubah mengikut jarak. Oleh itu, apabila sistem persepsi mengesan halangan di hadapan daripada imej, ia tidak mengetahui jarak halangan dari kenderaan, dan juga tidak mengetahui bentuk tiga dimensi dan saiz halangan yang sebenar.
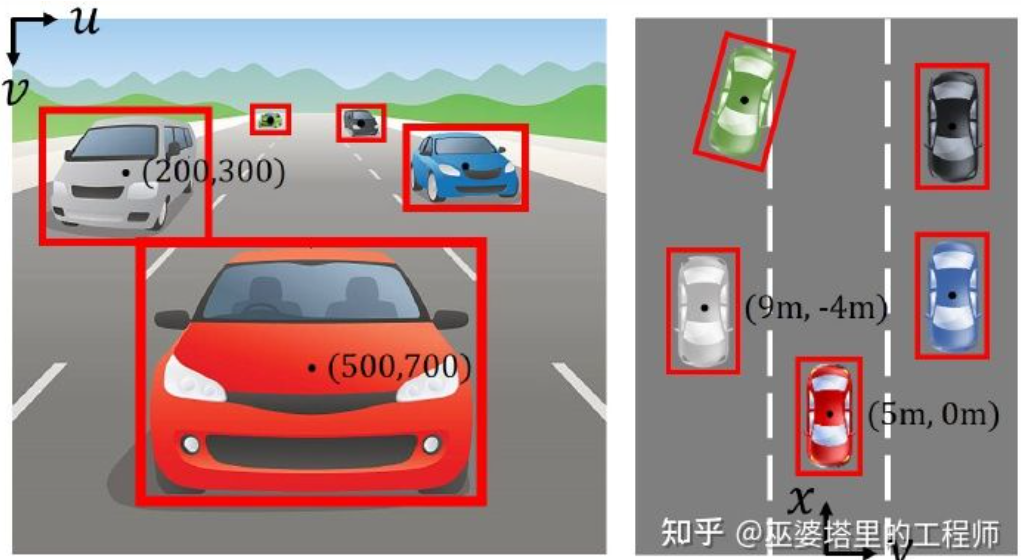
Sistem koordinat imej (pandangan perspektif) lwn sistem koordinat dunia (pandangan mata burung) [IPM- BEV ]
Untuk mendapatkan maklumat tentang ruang 3D, salah satu cara yang paling langsung ialah menggunakan LiDAR. Di satu pihak, output awan titik 3D oleh LiDAR boleh digunakan secara langsung untuk mendapatkan jarak dan saiz halangan (pengesanan objek 3D), serta kedalaman pemandangan (segmen semantik 3D). Sebaliknya, awan titik 3D juga boleh digabungkan dengan imej 2D untuk menggunakan sepenuhnya maklumat berbeza yang disediakan oleh kedua-duanya: kelebihan awan titik ialah persepsi jarak dan kedalaman yang tepat, manakala kelebihan imej adalah maklumat semantik yang lebih kaya.
Walau bagaimanapun, LiDAR juga mempunyai kelemahannya, seperti kos yang lebih tinggi, kesukaran dalam pengeluaran besar-besaran produk gred automotif, kesan yang lebih besar daripada cuaca, dsb. Oleh itu, persepsi 3D hanya berdasarkan kamera masih merupakan hala tuju penyelidikan yang sangat bermakna dan berharga. Bahagian berikut dalam artikel ini akan memperkenalkan secara terperinci algoritma persepsi 3D berdasarkan kamera tunggal dan dwi.
01
Persepsi 3D Monokular
Merasakan persekitaran 3D berdasarkan imej kamera tunggal adalah masalah yang teruk, tetapi ia boleh Menggunakan beberapa kekangan geometri dan pengetahuan terdahulu untuk membantu dalam menyelesaikan tugasan ini, rangkaian saraf dalam juga boleh digunakan untuk mempelajari cara meramal maklumat 3D daripada ciri imej secara menyeluruh.
Pengesanan objek

Pengesanan objek 3D kamera tunggal ( Gambar daripada M3D-RPN)
Transformasi songsang imej
Seperti yang dinyatakan sebelum ini, imej adalah daripada koordinat 3D di dunia nyata kepada Unjuran 2D koordinat satah, jadi idea yang sangat mudah untuk pengesanan objek 3D daripada imej adalah untuk menukar imej 2D secara songsang kepada koordinat dunia 3D, dan kemudian melakukan pengesanan objek dalam sistem koordinat dunia. Secara teorinya, ini adalah masalah yang tidak betul, tetapi ia boleh diselesaikan dengan beberapa maklumat tambahan (seperti anggaran kedalaman) atau andaian geometri (seperti piksel yang terletak di atas tanah).
BEV-IPM [1] mencadangkan untuk menukar imej daripada pandangan perspektif kepada pandangan mata burung (BEV). Terdapat dua andaian di sini: satu ialah permukaan jalan adalah selari dengan sistem koordinat dunia dan ketinggian adalah sifar, dan satu lagi ialah sistem koordinat kenderaan sendiri adalah selari dengan sistem koordinat dunia. Yang pertama tidak berpuas hati apabila permukaan jalan tidak rata, manakala yang kedua boleh diperbetulkan melalui parameter sikap kenderaan (Pitch and Roll), yang sebenarnya adalah Kalibrasi sistem koordinat kenderaan dan sistem koordinat dunia. Dengan mengandaikan bahawa semua piksel dalam imej mempunyai ketinggian sifar di dunia nyata, transformasi Homografi boleh digunakan untuk menukar imej kepada paparan BEV. Dalam paparan BEV, kaedah berdasarkan rangkaian YOLO digunakan untuk mengesan kotak bawah sasaran, iaitu segi empat tepat yang bersentuhan dengan permukaan jalan. Ketinggian Kotak Bawah adalah sifar, jadi ia boleh diunjurkan dengan tepat pada paparan BEV sebagai GroudTruth untuk melatih rangkaian saraf Pada masa yang sama, Kotak yang diramalkan oleh rangkaian saraf juga boleh menganggarkan jaraknya dengan tepat. Andaian di sini ialah sasaran perlu bersentuhan dengan permukaan jalan, yang secara amnya mencukupi untuk sasaran kenderaan dan pejalan kaki.
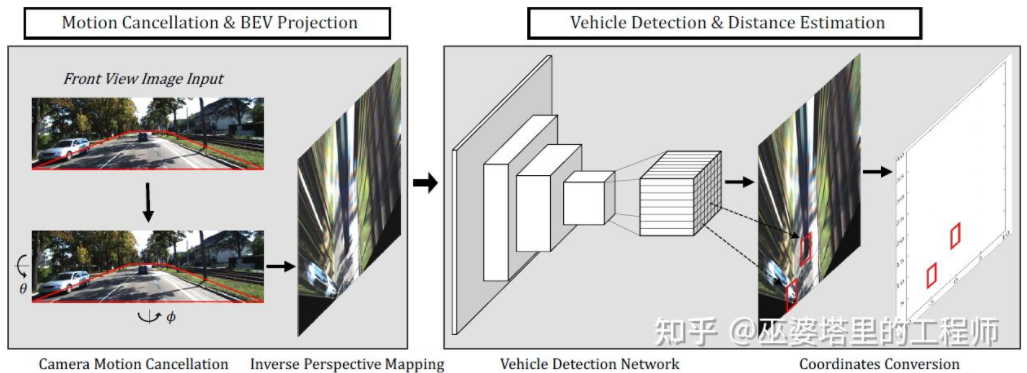
BEV-IPM
Kaedah transformasi songsang lain menggunakan Transformasi Ciri Ortografik (OFT) [2] . Ideanya ialah menggunakan CNN untuk mengekstrak ciri imej berbilang skala, kemudian mengubah ciri imej ini kepada paparan BEV, dan akhirnya melakukan pengesanan objek 3D pada ciri BEV. Pertama, adalah perlu untuk membina grid 3D dari perspektif BEV (julat grid eksperimen dalam artikel ini ialah 80 meter x 80 meter x 4 meter, dan saiz grid ialah 0.5m). Setiap grid sepadan dengan kawasan pada imej (ditakrifkan sebagai kawasan segi empat tepat untuk kesederhanaan) melalui transformasi perspektif, dan nilai min ciri imej dalam kawasan ini digunakan sebagai ciri grid, dengan itu memperoleh ciri grid 3D. Untuk mengurangkan jumlah pengiraan, ciri grid 3D dimampatkan (purata wajaran) dalam dimensi ketinggian untuk mendapatkan ciri grid 2D. Pengesanan objek akhir dilakukan pada ciri mesh 2D. Unjuran grid 3D kepada piksel imej 2D tidak sepadan dengan satu sama satu Grid berbilang akan sepadan dengan kawasan imej bersebelahan, mengakibatkan kekaburan dalam ciri grid. Oleh itu, adalah perlu juga untuk mengandaikan bahawa objek yang akan dikesan semuanya berada di atas jalan raya, dan julat ketinggian adalah sangat sempit. Oleh itu, grid 3D yang digunakan dalam eksperimen hanya 4 meter tinggi, yang cukup untuk menampung kenderaan dan pejalan kaki di atas tanah. Tetapi jika anda ingin mengesan tanda lalu lintas, kaedah mengandaikan bahawa objek berada dekat dengan tanah tidak boleh digunakan.
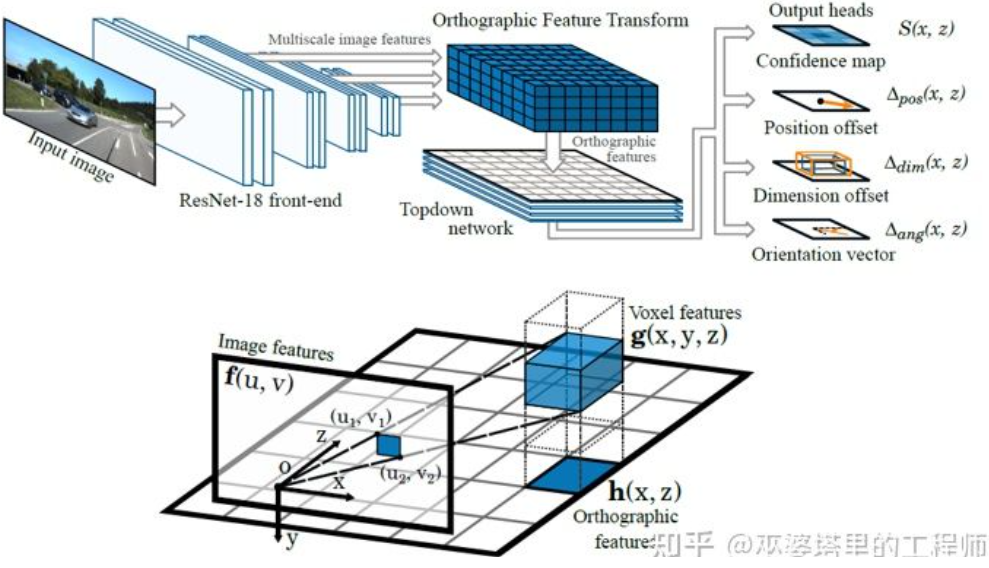
Transformasi Ciri Ortografik
Perkara di atas Kedua-dua kaedah adalah berdasarkan andaian bahawa objek itu terletak di atas tanah. Selain itu, idea lain ialah menggunakan hasil anggaran kedalaman untuk menjana data awan titik pseudo Satu kerja biasa ialah Pseudo-LiDAR [3]. Keputusan anggaran kedalaman biasanya dianggap sebagai saluran imej tambahan (serupa dengan data RGB-D), dan rangkaian pengesanan objek berasaskan imej digunakan secara langsung untuk menjana kotak sempadan objek 3D. Penulis menegaskan dalam artikel itu bahawa sebab utama mengapa ketepatan pengesanan objek 3D berdasarkan anggaran kedalaman adalah lebih teruk daripada kaedah berasaskan LiDAR bukanlah kerana ketepatan anggaran kedalaman tidak mencukupi, tetapi terdapat masalah dengan kaedah perwakilan data. Pertama, pada data imej, kawasan objek jauh adalah sangat kecil, yang menjadikan pengesanan objek jauh sangat tidak tepat. Kedua, perbezaan kedalaman antara piksel bersebelahan secara mendalam mungkin sangat besar (seperti di tepi objek. Dalam kes ini, akan terdapat masalah menggunakan operasi lilitan untuk mengekstrak ciri). Dengan mengambil kira dua perkara ini, penulis mencadangkan untuk menukar imej input kepada data awan titik yang serupa dengan yang dijana oleh LiDAR berdasarkan peta kedalaman, dan kemudian menggunakan awan titik dan algoritma gabungan imej (seperti AVOD dan F-PointNet) kepada mengesan objek 3D. Kaedah Pseudo-LiDAR tidak bergantung pada algoritma anggaran kedalaman tertentu, dan sebarang anggaran kedalaman daripada monokular atau binokular boleh digunakan secara langsung. Melalui kaedah perwakilan data khas ini, Pseudo-LiDAR boleh meningkatkan ketepatan pengesanan objek daripada 22% kepada 74% dalam lingkungan 30 meter.

Pseudo-LiDAR
Perbandingan dengan awan titik LiDAR sebenar, Kaedah Pseudo-LiDAR masih mempunyai jurang tertentu dalam ketepatan pengesanan objek 3D Ini terutamanya disebabkan oleh ketepatan anggaran kedalaman yang tidak mencukupi (teropong lebih baik daripada monokular), terutamanya ralat anggaran kedalaman di sekeliling objek pada pengesanan. Oleh itu, Pseudo-LiDAR juga telah mengalami banyak pengembangan sejak itu. Pseudo-LiDAR++ [4] menggunakan LiDAR wayar rendah untuk meningkatkan awan titik maya. Pseudo-Lidar End2End[5] menggunakan pembahagian contoh untuk menggantikan bingkai objek dalam F-PointNet. RefinedMPL [6] hanya menjana awan titik maya pada titik latar depan, mengurangkan bilangan awan titik kepada 10% daripada yang asal, yang boleh mengurangkan bilangan pengesanan palsu dan jumlah pengiraan algoritma dengan berkesan.
Isi penting dan model 3D
Dalam aplikasi pemanduan autonomi, saiz dan bentuk banyak sasaran (seperti kenderaan dan pejalan kaki) perlu dikesan Ia agak tetap dan diketahui. Pengetahuan terdahulu ini boleh digunakan untuk menganggarkan maklumat 3D sasaran.
DeepMANTA[7] ialah salah satu karya perintis ke arah ini. Pertama, algoritma pengesanan objek imej tradisional seperti Faster RNN digunakan untuk mendapatkan bingkai objek 2D dan juga mengesan titik utama pada kenderaan. Kemudian, bingkai objek 2D dan titik utama ini dipadankan dengan pelbagai model CAD kenderaan 3D dalam pangkalan data, dan model dengan persamaan tertinggi dipilih sebagai output pengesanan objek 3D.
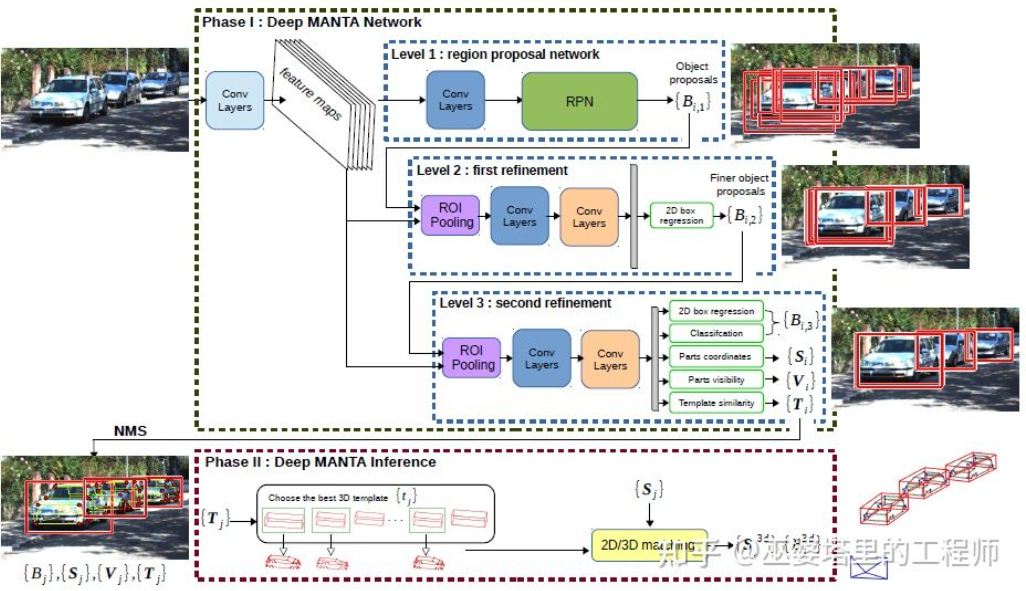
Deep MANTA
3D-RCNN[8] dicadangkan untuk digunakan Kaedah Songsang -Graphics, berdasarkan imej untuk memulihkan bentuk 3D dan pose setiap sasaran dalam pemandangan. Idea asas adalah untuk bermula dari model 3D sasaran dan mencari model yang paling sepadan dengan sasaran dalam imej melalui carian parameter. Model 3D ini biasanya mempunyai banyak parameter kawalan dan ruang carian yang besar Oleh itu, kaedah tradisional tidak mempunyai hasil yang baik dalam mencari hasil yang optimum dalam ruang parameter berdimensi tinggi. 3D-RCNN menggunakan PCA untuk mengurangkan dimensi ruang parameter (10-D), dan menggunakan rangkaian saraf dalam (R-CNN) untuk meramalkan parameter model dimensi rendah bagi setiap sasaran. Parameter model yang diramalkan boleh digunakan untuk menjana imej dua dimensi atau peta kedalaman setiap sasaran, dan Kehilangan yang diperoleh dengan membandingkannya dengan data GroudTruth boleh digunakan untuk membimbing pembelajaran rangkaian saraf. Kehilangan ini dipanggil Render-and-Compare Loss dan dilaksanakan berdasarkan OpenGL. Kaedah 3D-RCNN memerlukan banyak data input, dan reka bentuk Kehilangan adalah agak kompleks, menjadikannya sukar untuk dilaksanakan dalam kejuruteraan.
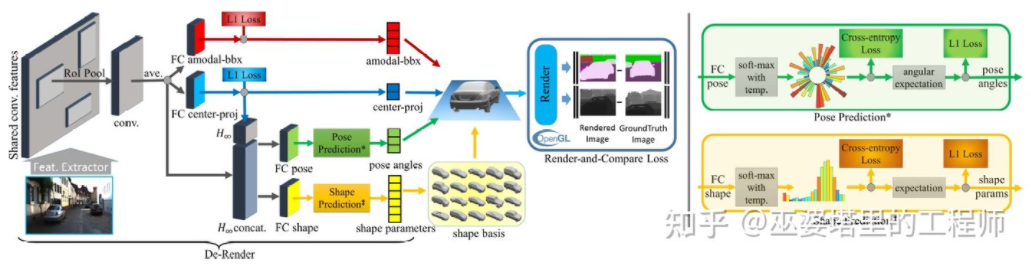
3D-RCNN
MonoGRNet[ 9] mencadangkan untuk membahagikan pengesanan objek 3D monokular kepada empat langkah, yang digunakan untuk meramalkan bingkai objek 2D, kedalaman pusat 3D objek, kedudukan unjuran 2D pusat 3D objek dan kedudukan 3D objek. lapan titik sudut. Pertama, kerangka objek 2D yang diramalkan dalam imej dikendalikan oleh ROIAlign untuk mendapatkan ciri visual objek. Ciri-ciri ini kemudiannya digunakan untuk meramalkan kedalaman pusat 3D objek dan kedudukan unjuran 2D pusat 3D. Dengan dua maklumat ini, kedudukan titik tengah 3D objek boleh diperolehi. Akhir sekali, kedudukan relatif lapan titik penjuru diramalkan berdasarkan kedudukan pusat 3D. MonoGRNet boleh dianggap sebagai hanya menggunakan pusat objek sebagai titik utama, dan pemadanan 2D dan 3D ialah pengiraan jarak titik. MonoGRNetV2 [10] memanjangkan titik tengah kepada berbilang titik utama dan menggunakan model objek CAD 3D untuk anggaran kedalaman, yang hampir sama dengan DeepMANTA dan 3D-RCNN yang diperkenalkan sebelum ini.
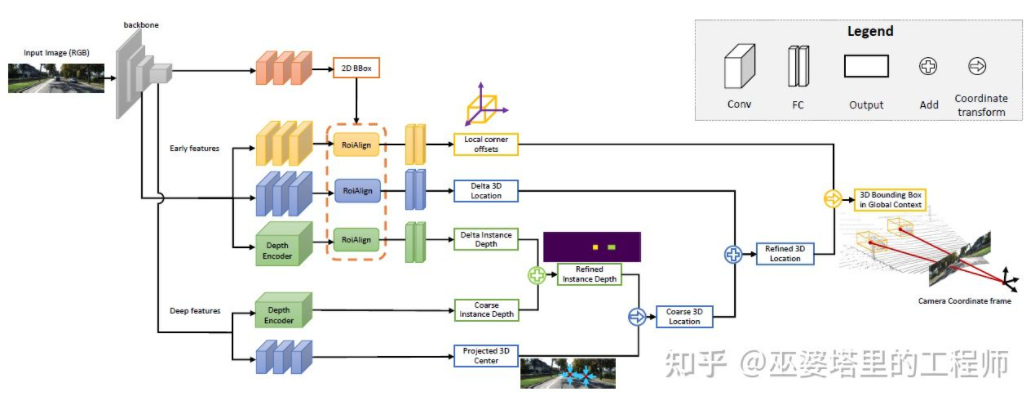
MonoGRNet
Monoloco[11] terutamanya menyelesaikan pengesanan 3D bagi soalan pejalan kaki. Pejalan kaki ialah objek tidak tegar dengan postur dan ubah bentuk yang lebih pelbagai, menjadikannya lebih mencabar daripada pengesanan kenderaan. Monoloco juga berdasarkan pengesanan titik utama, dan kedudukan 3D relatif titik utama a priori boleh digunakan untuk anggaran kedalaman. Sebagai contoh, jarak pejalan kaki dianggarkan berdasarkan panjang 50 sentimeter dari bahu pejalan kaki ke pinggul. Sebab untuk menggunakan panjang ini sebagai penanda aras ialah bahagian badan manusia ini boleh menghasilkan paling sedikit ubah bentuk dan boleh digunakan untuk anggaran kedalaman dengan ketepatan tertinggi. Sudah tentu, perkara penting lain juga boleh digunakan sebagai bantuan untuk menyelesaikan tugas anggaran yang mendalam. Monoloco menggunakan rangkaian bersambung penuh berbilang lapisan untuk meramalkan jarak pejalan kaki dari lokasi titik utama, sambil memberikan ketidakpastian ramalan.
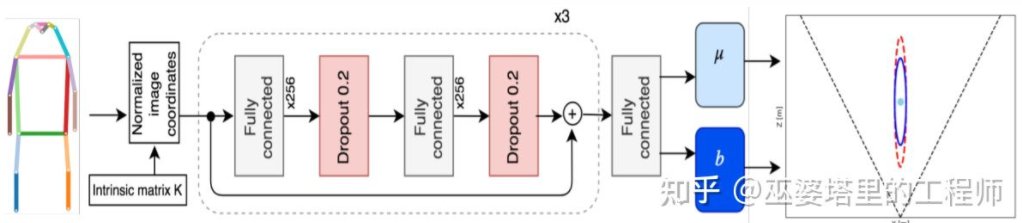
Monoloco
Untuk meringkaskan, kaedah di atas semuanya daripada 2D imej Perkara utama diekstrak dan dipadankan dengan model 3D untuk mendapatkan maklumat 3D sasaran. Kaedah jenis ini mengandaikan bahawa sasaran mempunyai model bentuk yang agak tetap, yang secara amnya memuaskan untuk kenderaan, tetapi agak sukar untuk pejalan kaki. Di samping itu, kaedah jenis ini memerlukan penandaan berbilang titik utama pada imej 2D, yang juga sangat memakan masa.
Kekangan geometri 2D/3D
Deep3DBox[12] ialah kerja awal dan mewakili ke arah ini. Bingkai objek 3D memerlukan pembolehubah 9 dimensi untuk diwakili, iaitu pusat, saiz dan orientasi (orientasi 3D boleh dipermudahkan kepada Yaw, jadi ia menjadi pembolehubah 7 dimensi). Pengesanan objek imej 2D boleh menyediakan bingkai objek 2D yang mengandungi 4 pembolehubah yang diketahui (pusat 2D dan saiz 2D), yang tidak mencukupi untuk menyelesaikan pembolehubah dengan 7 atau 9 darjah kebebasan. Di antara ketiga-tiga set pembolehubah ini, saiz dan orientasi secara relatifnya berkait rapat dengan ciri visual. Contohnya, saiz 3D sesuatu objek berkait rapat dengan kategorinya (pejalan kaki, basikal, kereta, bas, trak, dll.), dan kategori objek boleh diramal melalui ciri visual. Untuk kedudukan 3D titik tengah, sukar untuk diramalkan semata-mata melalui ciri visual disebabkan oleh kekaburan yang disebabkan oleh unjuran perspektif. Oleh itu, Deep3DBox bercadang untuk menggunakan ciri imej dahulu dalam kotak objek 2D untuk menganggar saiz dan orientasi objek. Kemudian, kekangan geometri 2D/3D digunakan untuk menyelesaikan kedudukan 3D titik tengah. Kekangan ini ialah unjuran bingkai objek 3D pada imej dikelilingi rapat oleh bingkai objek 2D, iaitu, sekurang-kurangnya satu titik sudut bingkai objek 3D boleh ditemui pada setiap sisi bingkai objek 2D. Melalui saiz dan orientasi yang diramalkan sebelum ini, digabungkan dengan parameter Kalibrasi kamera, kedudukan 3D titik tengah boleh diselesaikan.
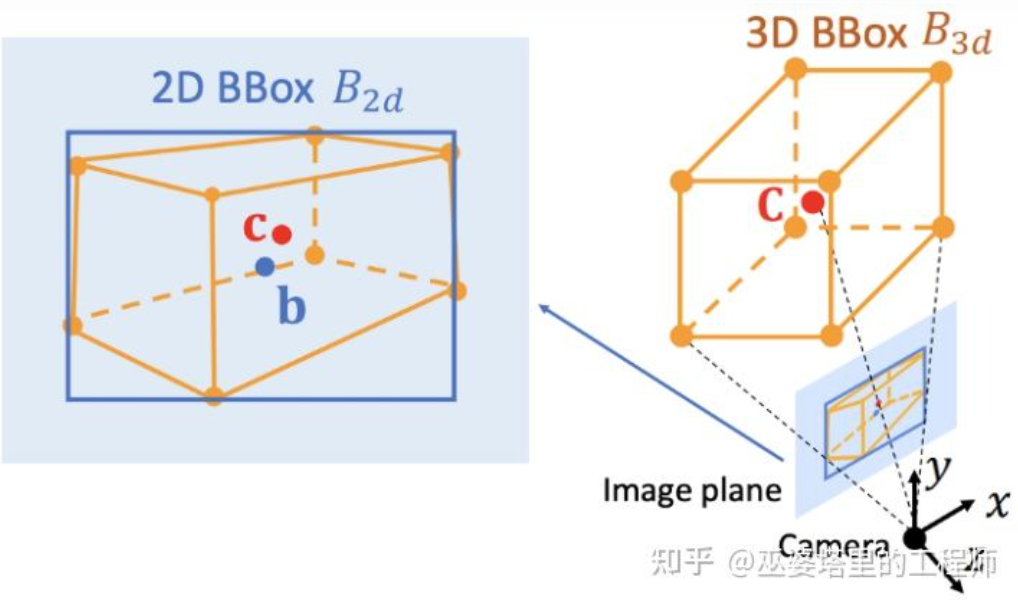
Kekangan geometri antara bingkai objek 2D dan 3D (gambar dari rujukan [9])
Kaedah menggunakan kekangan 2D/3D ini memerlukan pengesanan bingkai objek 2D yang sangat tepat. Di bawah rangka kerja Deep3DBox, ralat kecil pada bingkai objek 2D boleh menyebabkan kegagalan ramalan bingkai objek 3D. Dua peringkat pertama Shift R-CNN [13] sangat serupa dengan Deep3DBox Mereka meramalkan saiz dan orientasi 3D melalui kotak objek 2D dan ciri visual, dan kemudian menyelesaikan kedudukan 3D melalui kekangan geometri. Walau bagaimanapun, Shift R-CNN menambah peringkat ketiga, yang menggabungkan bingkai objek 2D, bingkai objek 3D dan parameter kamera yang diperoleh dalam dua peringkat pertama sebagai input, dan menggunakan rangkaian yang disambungkan sepenuhnya untuk meramalkan kedudukan 3D yang lebih tepat.
Shift R-CNN
Menggunakan kekangan geometri 2D/3D Di Pada masa itu, kaedah di atas semuanya memperoleh kedudukan 3D objek dengan menyelesaikan satu set persamaan super-kekangan, dan proses ini digunakan sebagai langkah pasca pemprosesan dan tidak berada dalam rangkaian saraf. Peringkat pertama dan ketiga Shift R-CNN juga dilatih secara berasingan. MVRA [14] membina proses penyelesaian persamaan super-kekangan ini ke dalam rangkaian, dan mereka bentuk Kehilangan IoU dalam koordinat imej dan Kehilangan L2 dalam koordinat BEV untuk mengukur ralat bingkai objek dan anggaran jarak masing-masing untuk membantu dalam menyelesaikan hujung ke- tamat latihan. Dengan cara ini, kualiti ramalan kedudukan 3D objek juga akan mempunyai kesan maklum balas pada ramalan saiz dan orientasi 3D sebelumnya.
Menjana bingkai objek 3D secara langsung
Tiga kaedah yang diperkenalkan sebelum semuanya bermula daripada imej 2D, dan sesetengahnya mengubah imej menjadi paparan BEV , sesetengahnya mengesan titik utama 2D dan memadankannya dengan model 3D, dan yang lain menggunakan kekangan geometri bingkai objek 2D dan 3D. Selain itu, terdapat satu lagi jenis kaedah yang bermula daripada calon objek 3D yang padat dan menjaringkan semua bingkai calon berdasarkan ciri-ciri pada imej 2D. Bingkai calon dengan skor yang tinggi adalah hasil akhir. Strategi ini agak serupa dengan kaedah Tetingkap Gelongsor tradisional dalam pengesanan objek.
Mono3D[15] ialah wakil kaedah jenis ini. Pertama, kotak calon 3D padat dijana berdasarkan kedudukan awal sasaran (koordinat z berada di atas tanah) dan saiz. Pada set data KITTI, kira-kira 40K (kenderaan) atau 70K (pejalan kaki dan basikal) kotak calon dijana setiap bingkai. Selepas kotak calon 3D ini diunjurkan kepada koordinat imej, ia dijaringkan oleh ciri pada imej 2D. Ciri ini datang daripada pembahagian semantik, pembahagian contoh, konteks, bentuk dan maklumat terdahulu lokasi. Semua ciri ini digabungkan untuk menjaringkan kotak calon, dan kemudian yang mempunyai markah yang lebih tinggi dipilih sebagai calon terakhir. Calon-calon ini kemudiannya melalui CNN untuk pusingan pemarkahan seterusnya untuk mendapatkan bingkai objek 3D terakhir.
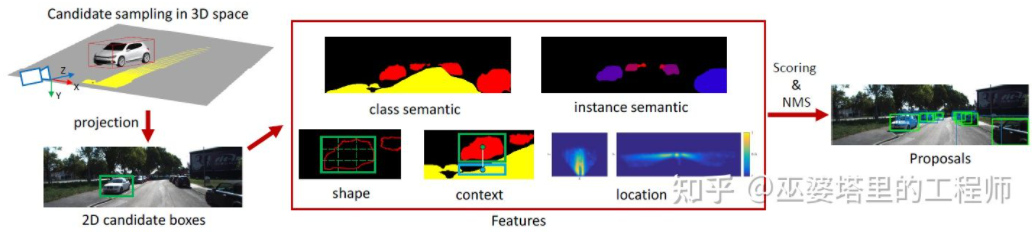
Mono3D
M3D-RPN [16] ialah kaedah berasaskan Anchor. Kaedah ini mentakrifkan Penambat 2D dan 3D, yang masing-masing mewakili bingkai objek 2D dan 3D. 2D Anchor diperoleh melalui pensampelan padat pada imej, manakala parameter 3D Anchor ditentukan berdasarkan pengetahuan terdahulu yang diperoleh daripada data set latihan. Khususnya, setiap 2D Anchor dipadankan dengan bingkai objek 2D yang ditandakan dalam imej mengikut IoU, dan nilai min bagi bingkai objek 3D yang sepadan digunakan untuk menentukan parameter 3D Anchor. Perlu dinyatakan bahawa kedua-dua operasi lilitan piawai (dengan invarian spatial) dan lilitan Depth-Aware digunakan dalam M3D-RPN. Yang terakhir membahagikan baris (koordinat Y) imej kepada berbilang kumpulan Setiap kumpulan sepadan dengan kedalaman pemandangan yang berbeza dan diproses oleh kernel lilitan yang berbeza.
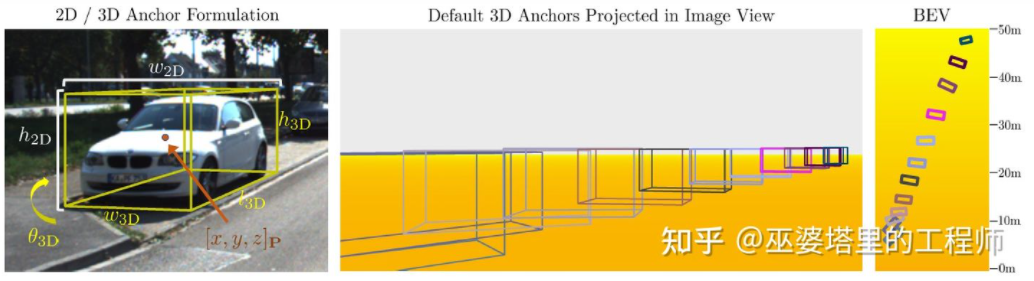
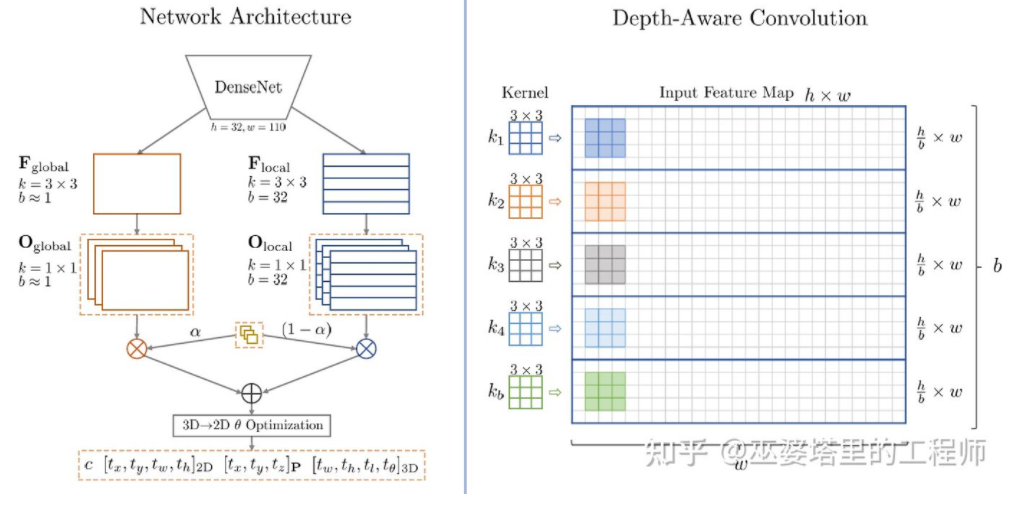
dalam M3D-RPN Anchor reka bentuk dan lilitan Depth-Aware
Walaupun beberapa pengetahuan terdahulu digunakan, Mono3D dan M3D-RPN masih berdasarkan pensampelan padat apabila menjana calon objek atau Anchor, jadi Jumlah pengiraan yang diperlukan adalah sangat besar, dan kepraktisan sangat terjejas. Beberapa kaedah seterusnya dicadangkan menggunakan hasil pengesanan pada imej dua dimensi untuk mengurangkan lagi ruang carian.
TLNet [17] meletakkan sauh padat dalam satah dua dimensi. Selang jangkar ialah 0.25 meter, orientasi ialah 0 darjah dan 90 darjah, dan saiz adalah purata sasaran. Hasil pengesanan dua dimensi pada imej membentuk berbilang kon tontonan dalam ruang tiga dimensi Melalui kon tontonan ini, sejumlah besar penambat pada latar belakang boleh ditapis, dengan itu meningkatkan kecekapan algoritma. Anchor yang ditapis ditayangkan pada imej, dan ciri yang diperoleh selepas ROI Pooling digunakan untuk memperhalusi lagi parameter bingkai objek 3D.
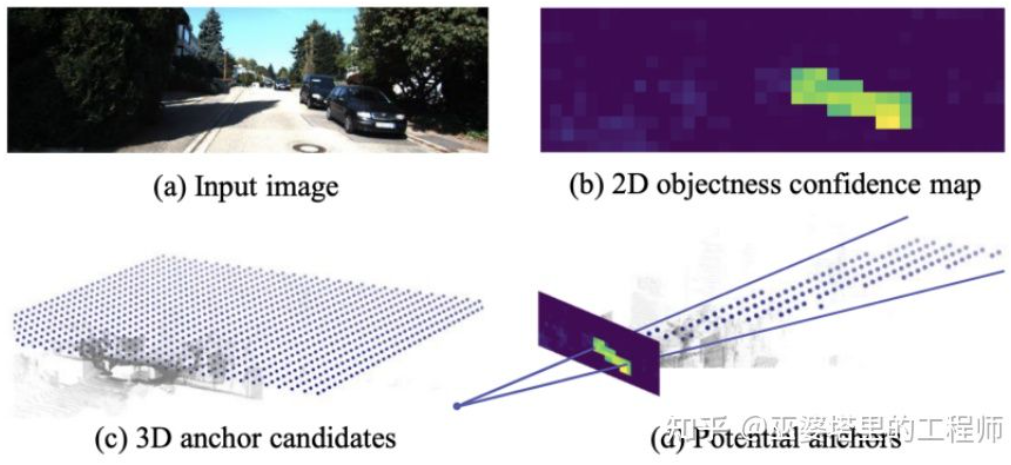
TLTNet
SS3D[18] Pengesanan satu peringkat yang lebih cekap digunakan, dan rangkaian yang serupa dengan struktur CenterNet digunakan untuk terus mengeluarkan pelbagai maklumat 2D dan 3D daripada imej, seperti kategori objek, bingkai objek 2D dan bingkai objek 3D. Perlu diingatkan bahawa bingkai objek 3D di sini bukanlah perwakilan 9D atau 7D umum (perwakilan ini sukar untuk diramal terus daripada imej), tetapi perwakilan 2D yang lebih mudah untuk diramal daripada imej dan mengandungi lebihan redundansi, termasuk jarak . (1-d), orientasi (2-d, sin dan cos), saiz (3-d), koordinat imej bagi 8 titik sudut (16-d). Ditambah dengan perwakilan 4-D kotak objek 2D, jumlahnya ialah ciri 26D. Semua ciri ini digunakan untuk meramalkan bingkai objek 3D Proses ramalan sebenarnya adalah untuk mencari bingkai objek 3D yang paling sepadan dengan ciri 26D. Perkara yang istimewa ialah proses penyelesaian ini dilakukan di dalam rangkaian saraf, jadi ia mesti boleh dibezakan Ini juga merupakan sorotan utama artikel ini. Mendapat manfaat daripada struktur dan pelaksanaan yang mudah, SS3D boleh berjalan pada kelajuan 20FPS.
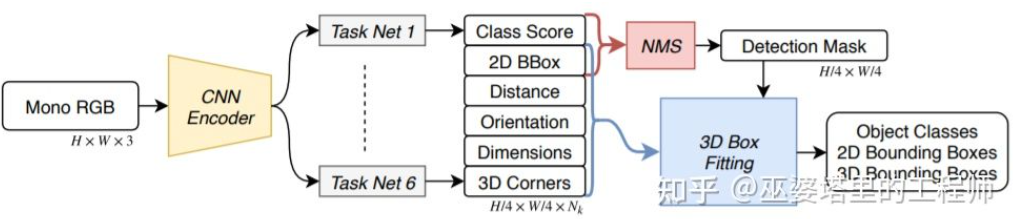
SS3D
FCOS3D[19] juga merupakan peringkat tunggal kaedah pengesanan, tetapi lebih ringkas daripada SS3D. Pusat bingkai objek 3D ditayangkan pada imej 2D untuk mendapatkan pusat 2.5D (X, Y, Kedalaman), yang digunakan sebagai salah satu matlamat regresi. Di samping itu, sasaran regresi juga termasuk saiz dan orientasi 3D. Orientasi di sini diwakili oleh gabungan sudut (0-pi) + tajuk.
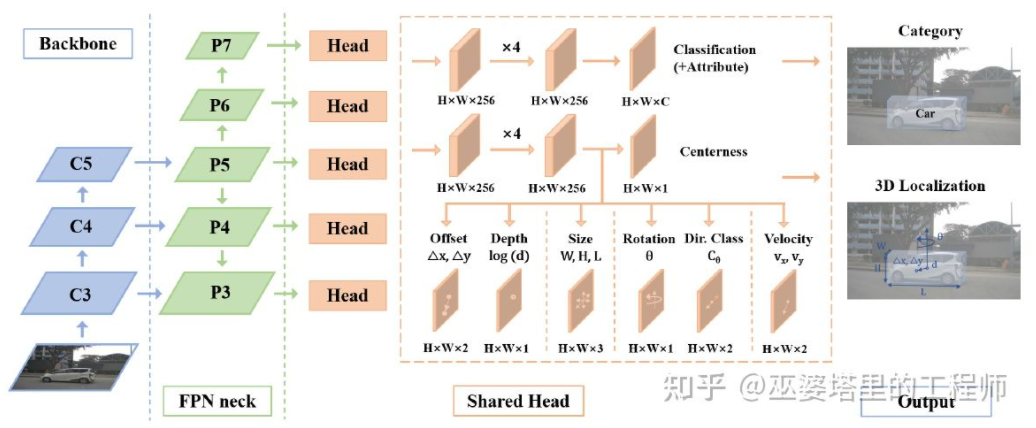
FCOS3D
ASAP[20] Idea yang sama juga dicadangkan untuk meramalkan maklumat 2D dan 3D secara langsung daripada imej melalui struktur seperti CenterNet. Maklumat 2D termasuk kedudukan unjuran titik utama objek (titik tengah dan titik sudut) pada imej, dan maklumat 3D termasuk kedalaman, saiz dan orientasi titik tengah. Melalui kedudukan imej dan kedalaman titik tengah, kedudukan 3D objek boleh dipulihkan. Kedudukan 3D setiap titik sudut kemudiannya boleh dipulihkan melalui saiz dan orientasi 3D.
Idea rangkaian satu peringkat yang diperkenalkan di atas adalah untuk mengembalikan maklumat 3D secara langsung daripada imej, tanpa memerlukan pra-pemprosesan yang kompleks (seperti transformasi songsang imej) dan pasca pemprosesan (seperti 3D padanan model), mahupun kekangan geometri yang tepat (contohnya, sekurang-kurangnya satu titik sudut bingkai objek 3D boleh ditemui pada setiap tepi bingkai objek 2D). Kaedah ini hanya menggunakan sedikit pengetahuan terdahulu, seperti min saiz sebenar pelbagai jenis objek, dan hasil koresponden antara saiz dan kedalaman objek 2D. Pengetahuan terdahulu ini mentakrifkan nilai awal parameter 3D objek, dan rangkaian saraf hanya perlu mengundurkan sisihan daripada nilai sebenar, yang sangat mengurangkan ruang carian dan oleh itu mengurangkan kesukaran pembelajaran rangkaian.
Anggaran Kedalaman
Bahagian sebelumnya memperkenalkan kaedah perwakilan pengesanan objek 3D monokular, dan ideanya diperoleh daripada transformasi imej awal, 3D padanan model dan kekangan geometri 2D/3D, kepada ramalan terkini maklumat 3D secara langsung daripada imej. Perubahan dalam pemikiran ini sebahagian besarnya berpunca daripada kemajuan rangkaian saraf konvolusi dalam anggaran mendalam. Kebanyakan rangkaian pengesanan objek 3D satu peringkat yang diperkenalkan sebelum ini termasuk cawangan anggaran kedalaman. Anggaran kedalaman di sini hanya pada tahap sasaran yang jarang dan bukannya tahap piksel padat, tetapi ia mencukupi untuk pengesanan objek.
Selain pengesanan objek, persepsi pemanduan autonomi juga mempunyai satu lagi tugas penting, iaitu segmentasi semantik. Cara paling langsung untuk memanjangkan pembahagian semantik daripada 2D kepada 3D ialah menggunakan peta kedalaman padat, supaya maklumat semantik dan kedalaman setiap piksel tersedia.
Berdasarkan dua perkara di atas, anggaran kedalaman monokular memainkan peranan yang sangat penting dalam tugas persepsi 3D. Dengan analogi daripada pengenalan kaedah pengesanan objek 3D dalam bahagian sebelumnya, rangkaian saraf konvolusi sepenuhnya juga boleh digunakan untuk anggaran kedalaman padat. Di bawah ini kami akan memperkenalkan status pembangunan semasa arah ini.
Input anggaran kedalaman monokular ialah imej, dan output juga adalah imej (biasanya saiz yang sama dengan input), dan setiap nilai piksel padanya sepadan dengan kedalaman pemandangan daripada imej input. Tugas ini agak serupa dengan segmentasi semantik imej, kecuali segmentasi semantik mengeluarkan klasifikasi semantik setiap piksel. Sudah tentu, input juga boleh menjadi urutan video, menggunakan maklumat tambahan yang dibawa oleh gerakan kamera atau objek untuk meningkatkan ketepatan anggaran kedalaman (sepadan dengan segmentasi semantik video).
Seperti yang dinyatakan sebelum ini, meramalkan maklumat 3D daripada imej 2D adalah masalah yang tidak jelas, jadi kaedah tradisional akan menggunakan maklumat geometri, maklumat gerakan dan petunjuk lain untuk meramal piksel melalui kedalaman ciri yang direka secara manual . Sama seperti pembahagian semantik, dua kaedah, superpixel (SuperPixel) dan medan rawak bersyarat (CRF), sering digunakan untuk meningkatkan ketepatan anggaran. Dalam tahun-tahun kebelakangan ini, rangkaian saraf dalam telah membuat kemajuan terobosan dalam pelbagai tugas persepsi imej, dan anggaran kedalaman pastinya tidak terkecuali. Sebilangan besar kerja telah menunjukkan bahawa rangkaian saraf dalam boleh mempelajari ciri unggul melalui data latihan daripada ciri rekaan tangan. Bahagian ini terutamanya memperkenalkan kaedah ini berdasarkan pembelajaran diselia. Beberapa idea pembelajaran tanpa pengawasan lain, seperti menggunakan maklumat jurang binokular, maklumat perbezaan piksel dwi bermata (Dual Pixel), maklumat gerakan video, dsb., akan diperkenalkan kemudian.
Kerja perwakilan awal ke arah ini ialah kaedah berdasarkan gabungan petunjuk global dan tempatan yang dicadangkan oleh Eigen et al. Kekaburan anggaran kedalaman monokular terutamanya berasal dari skala global. Sebagai contoh, artikel itu menyebut bahawa bilik sebenar dan bilik mainan mungkin kelihatan sangat berbeza dalam imej, tetapi kedalaman medan sebenar adalah sangat berbeza. Walaupun ini adalah contoh yang melampau, variasi dalam dimensi bilik dan perabot masih wujud dalam set data sebenar. Oleh itu, kaedah ini mencadangkan untuk melakukan konvolusi berbilang lapisan dan pensampelan rendah pada imej untuk mendapatkan ciri perihalan keseluruhan pemandangan, dan menggunakan ini untuk meramalkan kedalaman global. Kemudian, satu lagi cawangan tempatan (peleraian yang agak lebih tinggi) digunakan untuk meramalkan kedalaman imej setempat. Di sini kedalaman global akan digunakan sebagai input kepada cawangan tempatan untuk membantu dalam ramalan kedalaman tempatan.
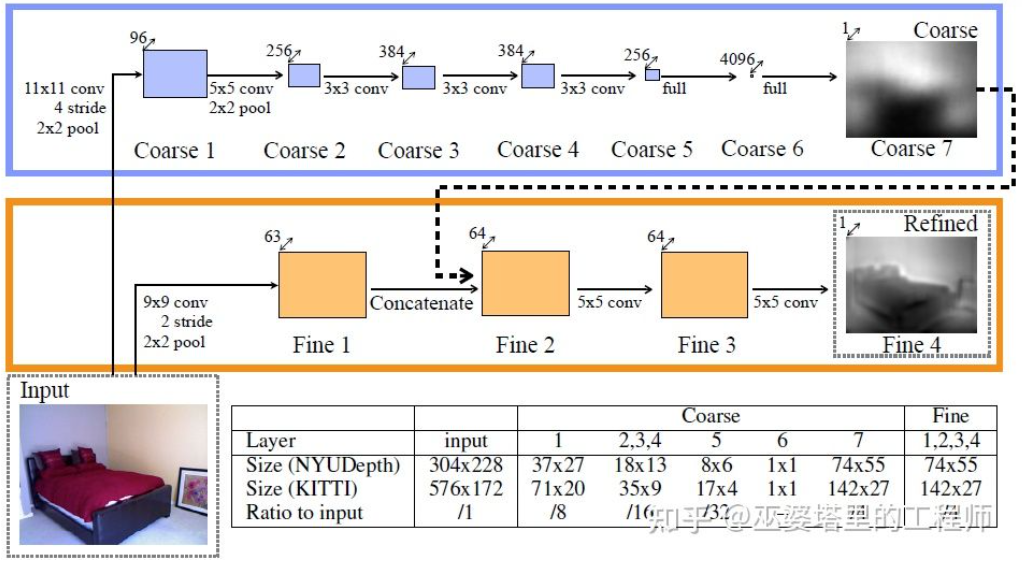
Gabungan maklumat global dan tempatan [21]
Sastera [22] seterusnya mencadangkan untuk menggunakan keluaran peta ciri berbilang skala oleh rangkaian saraf konvolusi untuk meramalkan peta kedalaman resolusi berbeza (hanya terdapat dua resolusi dalam [21]). Peta ciri dengan resolusi berbeza ini digabungkan melalui MRF berterusan untuk mendapatkan peta kedalaman yang sepadan dengan imej input.
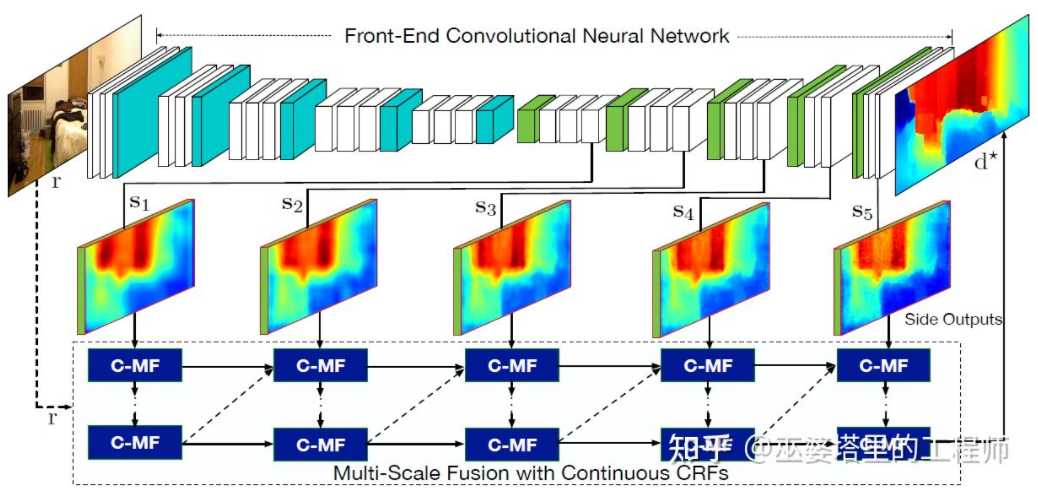
Penyatuan maklumat berbilang skala [22]
Dua di atas artikel Mereka semua menggunakan rangkaian saraf konvolusi untuk mengembalikan peta kedalaman Idea lain adalah untuk menukar masalah regresi kepada masalah klasifikasi, iaitu, untuk membahagikan nilai kedalaman berterusan ke dalam selang diskret, dan setiap selang dianggap sebagai kategori. Kerja perwakilan ke arah ini adalah DORN [23]. Rangkaian saraf dalam rangka kerja DORN juga merupakan struktur pengekodan dan penyahkodan, tetapi terdapat beberapa perbezaan dalam butiran, seperti menggunakan penyahkodan lapisan yang disambungkan sepenuhnya, lilitan diluaskan untuk pengekstrakan ciri, dsb.
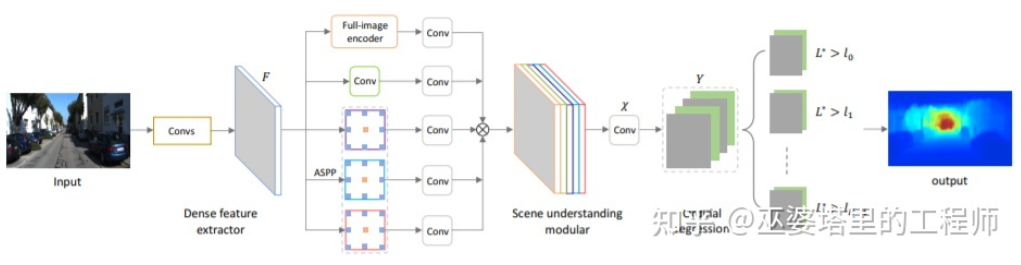
DORN Deep Classification
Sebutan sebelumnya Ambil perhatian bahawa anggaran kedalaman mempunyai persamaan dengan tugas pembahagian semantik, jadi saiz medan penerimaan juga sangat penting untuk anggaran kedalaman. Selain simpulan piramid dan lilitan diluaskan yang dinyatakan di atas, struktur Transformer yang popular baru-baru ini mempunyai medan penerimaan global dan oleh itu sangat sesuai untuk tugasan tersebut. Dalam literatur [24], adalah dicadangkan untuk menggunakan Transformer dan struktur berbilang skala untuk memastikan ketepatan tempatan dan ketekalan ramalan global secara serentak.
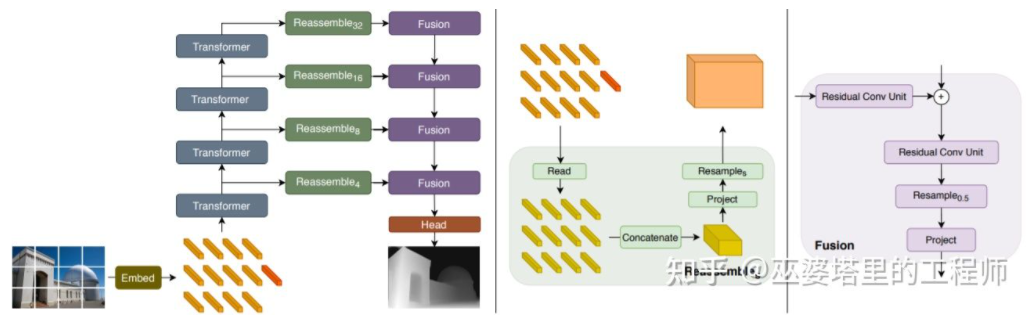
Pengubah untuk Ramalan Padat
02
Persepsi 3D Binokular
Walaupun pengetahuan sedia ada dan maklumat kontekstual dalam imej boleh digunakan, ketepatan berdasarkan persepsi 3D monokular tidak sepenuhnya memuaskan. Terutama apabila menggunakan strategi pembelajaran mendalam, ketepatan algoritma sangat bergantung pada saiz dan kualiti set data. Untuk adegan yang belum muncul dalam set data, algoritma akan mempunyai sisihan besar dalam anggaran kedalaman dan pengesanan objek.
Penglihatan binokular boleh menyelesaikan kekaburan yang disebabkan oleh transformasi perspektif, jadi secara teori ia boleh meningkatkan ketepatan persepsi 3D. Walau bagaimanapun, sistem binokular mempunyai keperluan yang agak tinggi dari segi perkakasan dan perisian. Dari segi perkakasan, dua kamera yang didaftarkan dengan tepat diperlukan, dan ketepatan pendaftaran mesti dipastikan semasa pengendalian kenderaan. Dari segi perisian, algoritma perlu memproses data daripada dua kamera pada masa yang sama Kerumitan pengiraan adalah tinggi, dan lebih sukar untuk memastikan prestasi masa nyata algoritma.
Secara umumnya, berbanding dengan persepsi visual bermata, terdapat sedikit karya mengenai persepsi visual binokular Beberapa artikel biasa akan dipilih untuk pengenalan di bawah. Di samping itu, terdapat beberapa karya berdasarkan pelbagai guna, tetapi berat sebelah terhadap tahap aplikasi sistem, seperti sistem persepsi 360° yang ditunjukkan oleh Tesla pada Hari AI.
Pengesanan objek
3DOP [25] mula-mula menggunakan imej daripada dwi kamera untuk menjana peta kedalaman, dan kemudian menukar peta kedalaman menjadi awan titik . Kuantitikannya ke dalam struktur data mesh dan gunakan ini sebagai input untuk menjana calon objek 3D. Beberapa intuisi dan pengetahuan sedia ada digunakan semasa menjana calon Contohnya, ketumpatan awan titik dalam kotak calon cukup besar, ketinggian adalah konsisten dengan objek sebenar dan perbezaan ketinggian dari awan titik di luar kotak cukup besar. , dan pertindihan antara kotak calon dan Ruang Bebas adalah mencukupi. Melalui syarat ini, kira-kira calon objek 3D 2K akhirnya diambil sampel dalam ruang 3D. Calon ini dipetakan kepada imej 2D dan pengekstrakan ciri dilakukan melalui Pengumpulan ROI untuk meramalkan kategori objek dan memperhalusi bingkai objek. Input imej di sini boleh menjadi imej RGB daripada kamera atau peta kedalaman.
Secara umum, ini ialah kaedah pengesanan dua peringkat. Peringkat pertama menggunakan maklumat kedalaman (awan titik) untuk menjana calon objek, dan peringkat kedua menggunakan maklumat imej (atau kedalaman) untuk penghalusan selanjutnya. Secara teorinya, peringkat pertama penjanaan awan titik juga boleh digantikan dengan LiDAR, jadi penulis menjalankan perbandingan eksperimen. Kelebihan LiDAR ialah pengukuran jarak adalah tepat, jadi ia berfungsi lebih baik untuk objek kecil, objek yang sebahagiannya tidak jelas dan objek yang jauh. Kelebihan penglihatan binokular ialah ketumpatan awan titik adalah tinggi, jadi ia berfungsi lebih baik apabila terdapat kurang halangan pada jarak dekat dan objek agak besar. Sudah tentu, tanpa mengambil kira kos dan kerumitan pengiraan, hasil terbaik akan diperoleh dengan menyepadukan kedua-duanya.
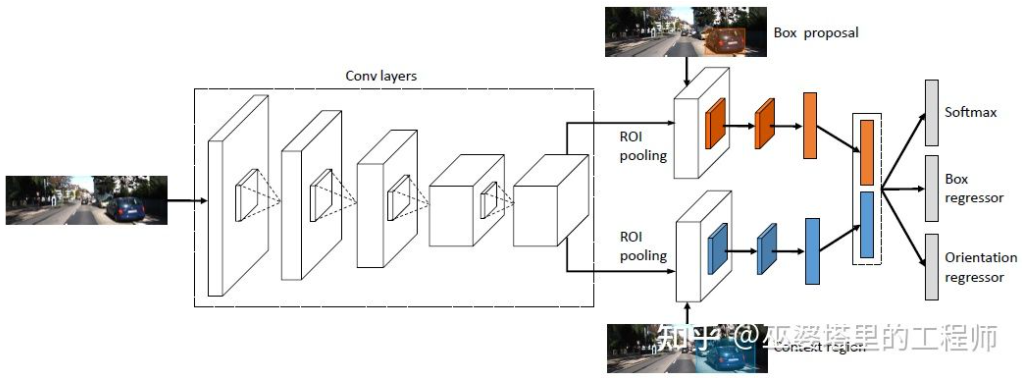
3DOP
3DOP dengan Pseudo yang diperkenalkan di bahagian sebelumnya- LiDAR [3] mempunyai idea yang sama, menukarkan peta kedalaman padat (daripada monokular, binokular atau LiDAR kiraan garisan rendah) kepada awan titik, dan kemudian menggunakan algoritma dalam bidang pengesanan objek awan titik.
Anggarkan peta kedalaman daripada imej, kemudian jana awan titik daripada peta kedalaman, dan akhirnya gunakan algoritma pengesanan objek awan titik Setiap langkah proses ini dilakukan secara berasingan dan tidak boleh dijalankan dari hujung ke hujung. DSGN [26] mencadangkan algoritma satu peringkat, bermula dari imej kiri dan kanan, menggunakan perwakilan perantaraan seperti Volum Plane-Sweep untuk menjana perwakilan 3D dalam paparan BEV, dan pada masa yang sama melakukan anggaran kedalaman dan pengesanan objek. Semua langkah proses ini boleh dibezakan dan oleh itu boleh dilatih dari hujung ke hujung.
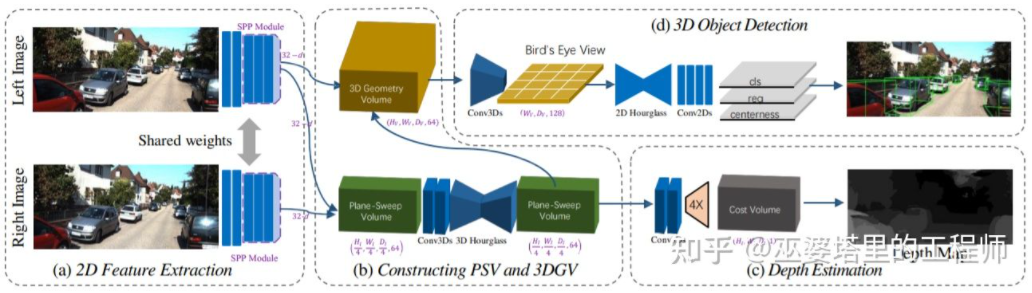
DSGN
Peta kedalaman ialah a Perwakilan yang padat, sebenarnya, untuk pembelajaran objek, tidak perlu mendapatkan maklumat mendalam pada semua kedudukan tempat kejadian, tetapi hanya perlu menganggarkan kedudukan objek yang diminati. Idea yang sama telah disebutkan sebelum ini semasa memperkenalkan algoritma monokular. Stereo R-CNN [27] tidak menganggarkan peta kedalaman, tetapi menyusun peta ciri daripada dua kamera bersama di bawah rangka kerja RPN untuk menjana calon objek. Kunci di sini untuk mengaitkan maklumat daripada kamera kiri dan kanan bersama-sama ialah perubahan dalam data anotasi. Seperti yang ditunjukkan dalam rajah di bawah, sebagai tambahan kepada kotak label kiri dan kanan, Kesatuan kotak label kiri dan kanan juga ditambah. Anchor yang IoUnya melebihi 0.7 dengan kotak kiri atau kanan digunakan sebagai sampel Positif, dan Anchor yang IoUnya kurang daripada 0.3 dengan kotak Union digunakan sebagai sampel Negatif. Positive's Anchor akan mengembalikan kedudukan dan saiz kotak label kiri dan kanan pada masa yang sama. Selain bingkai objek, kaedah ini juga menggunakan titik sudut sebagai alat bantuan. Dengan semua maklumat ini, bingkai objek 3D boleh dipulihkan.
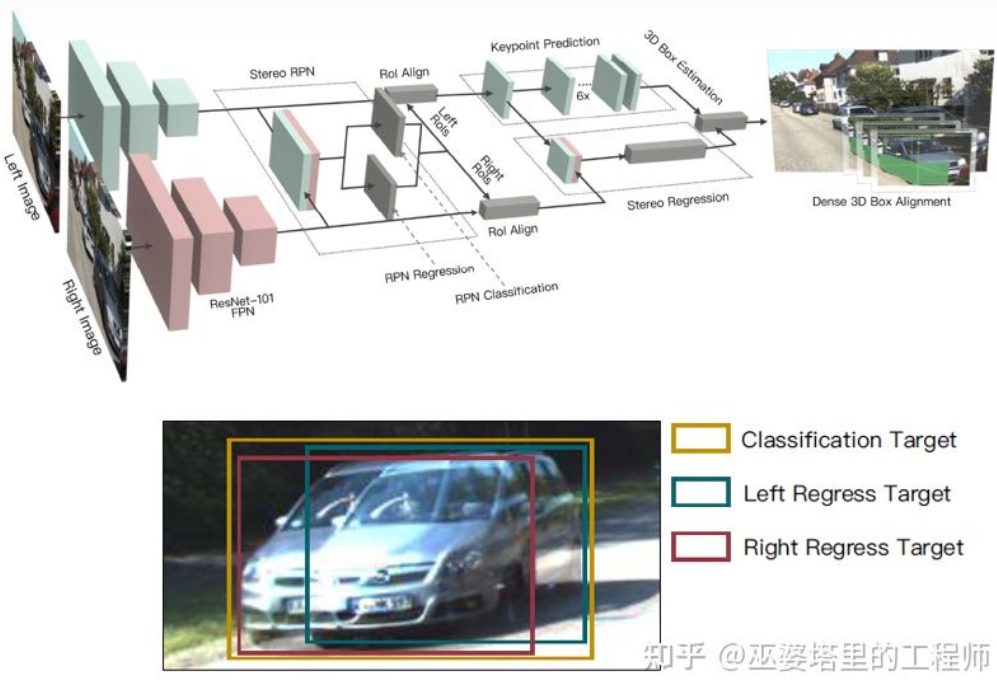
Stereo R-CNN
Ya Anggaran kedalaman padat bagi keseluruhan pemandangan malah boleh memberi kesan buruk pada pengesanan objek. Contohnya, disebabkan pertindihan tepi objek dengan latar belakang, sisihan anggaran kedalaman adalah besar, dan julat kedalaman yang besar bagi keseluruhan pemandangan juga akan mempengaruhi kelajuan algoritma. Oleh itu, sama dengan RCNN Stereo, ia juga dicadangkan dalam [28] untuk menganggarkan kedalaman hanya pada objek yang diminati dan hanya menjana awan titik pada objek. Awan titik berpusat objek ini akhirnya digunakan untuk meramalkan maklumat 3D objek.
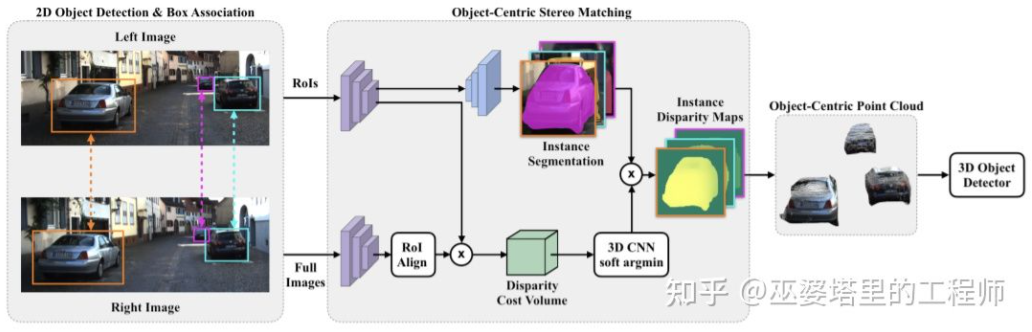
Padanan Stereo Berpusatkan Objek
Anggaran kedalaman
Sama seperti algoritma persepsi monokular, anggaran kedalaman juga merupakan langkah utama dalam persepsi binokular. Berdasarkan pengenalan kepada pengesanan objek binokular dalam bahagian sebelumnya, banyak algoritma menggunakan anggaran kedalaman, termasuk anggaran kedalaman peringkat pemandangan dan anggaran kedalaman peringkat objek. Berikut ialah ulasan ringkas tentang prinsip asas anggaran kedalaman binokular dan beberapa karya perwakilan.
Prinsip anggaran kedalaman binokular sebenarnya sangat mudah ia berdasarkan jarak d antara titik 3D yang sama pada imej kiri dan kanan (dengan mengandaikan bahawa kedua-dua kamera mengekalkan sama. ketinggian, jadi hanya Pertimbangkan jarak dalam arah mendatar), panjang fokus f kamera, dan jarak B (panjang garis dasar) antara kedua-dua kamera untuk menganggarkan kedalaman titik 3D.
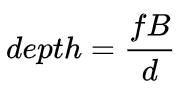
Dalam sistem binokular, f dan B adalah tetap, jadi hanya jarak d, iaitu paralaks, perlu dianggarkan. Untuk setiap piksel, anda hanya perlu mencari titik padanan dalam imej lain. Julat jarak d adalah terhad, jadi julat carian yang sepadan juga terhad. Untuk setiap kemungkinan d, ralat padanan pada setiap piksel boleh dikira, jadi data ralat tiga dimensi diperoleh, dipanggil Jumlah Kos. Apabila mengira ralat padanan, kawasan setempat berhampiran piksel biasanya dipertimbangkan Salah satu kaedah paling mudah ialah menjumlahkan perbezaan semua nilai piksel yang sepadan dalam kawasan setempat:
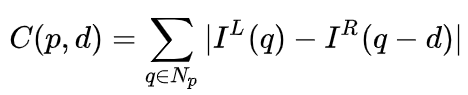

MC-CNN [29] memformalkan proses pemadanan sebagai mengira persamaan dua tampung imej, dan Ciri tampalan imej dipelajari melalui rangkaian saraf. Dengan melabelkan data, set latihan boleh dibina. Pada setiap piksel, sampel positif dan sampel negatif dijana, setiap sampel adalah sepasang tampalan imej. Sampel positif ialah dua blok imej dari titik 3D yang sama (kedalaman yang sama), dan sampel negatif ialah blok imej dari titik 3D yang berbeza (kedalaman yang berbeza). Terdapat banyak pilihan untuk sampel negatif Untuk mengekalkan keseimbangan antara sampel positif dan negatif, hanya satu sampel secara rawak. Dengan sampel positif dan negatif, rangkaian saraf boleh dilatih untuk meramalkan persamaan. Idea teras di sini ialah menggunakan isyarat penyeliaan untuk membimbing rangkaian saraf untuk mempelajari ciri imej yang sesuai untuk tugasan yang sepadan.
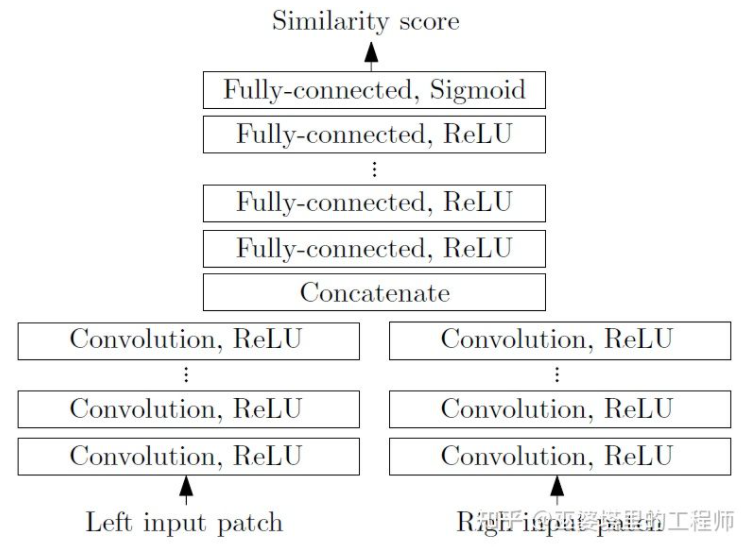
MC-CNN
MC- Net mempunyai dua kelemahan utama: 1) Pengiraan Jumlah Kos bergantung pada blok imej tempatan, yang akan menyebabkan ralat yang lebih besar di beberapa kawasan dengan tekstur yang kurang atau corak berulang 2) Langkah pasca pemprosesan bergantung pada reka bentuk manual masa dan sukar untuk menjamin optimum. GC-Net[30] telah bertambah baik pada dua perkara ini. Pertama, operasi lilitan dan pensampelan berbilang lapisan dilakukan pada imej kiri dan kanan untuk mengekstrak ciri semantik dengan lebih baik. Untuk setiap tahap perbezaan (dalam piksel), peta ciri kiri dan kanan dijajarkan (mengimbangi piksel) dan kemudian disambung untuk mendapatkan peta ciri tahap perbezaan tersebut. Peta ciri semua tahap ketaksamaan digabungkan bersama untuk mendapatkan Volum Kos 4D (tinggi, lebar, ketaksamaan, ciri). Jumlah Kos hanya mengandungi maklumat daripada satu imej dan tiada interaksi antara imej. Oleh itu, langkah seterusnya ialah menggunakan lilitan 3D untuk memproses Jumlah Kos, supaya maklumat yang berkaitan antara imej kiri dan kanan dan maklumat antara tahap perbezaan yang berbeza boleh diekstrak secara serentak. Output langkah ini ialah Volum Kos 3D (tinggi, lebar, paralaks). Akhir sekali, kita perlu mencari Argmin dalam dimensi ketaksamaan untuk mendapatkan nilai ketaksamaan yang optimum, tetapi Argmin piawai tidak boleh diperolehi. Argmin Lembut digunakan dalam GC-Net untuk menyelesaikan masalah derivasi, supaya keseluruhan rangkaian boleh dilatih hujung ke hujung.
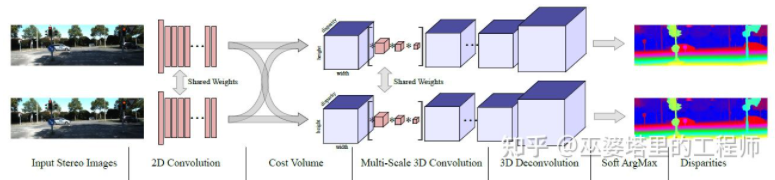
GC-Net
PSMNet[ 31] sangat serupa dengan struktur GC-Net, tetapi telah dipertingkatkan dalam dua aspek: 1) menggunakan struktur piramid dan lilitan atrous untuk mengekstrak maklumat berbilang resolusi dan mengembangkan medan penerimaan. Terima kasih kepada gabungan ciri global dan tempatan, anggaran Jumlah Kos juga lebih tepat. 2) Gunakan berbilang struktur Hour-Glass bertindih untuk meningkatkan lilitan 3D. Penggunaan maklumat global dipertingkatkan lagi. Secara amnya, PSMNet telah membuat penambahbaikan dalam penggunaan maklumat global, menjadikan anggaran jurang lebih bergantung kepada maklumat kontekstual pada skala yang berbeza dan bukannya maklumat tempatan peringkat piksel.
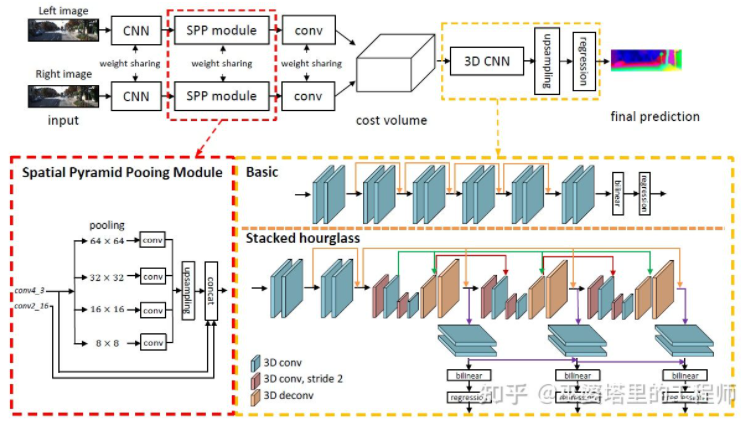
PSMNet
Dalam Volum Kos, tahap ketaksamaan adalah diskret (dalam piksel) Apa yang dipelajari oleh rangkaian saraf ialah taburan Kos pada titik diskret ini dan titik ekstrem taburan sepadan dengan nilai Paralaks. Walau bagaimanapun, nilai paralaks (kedalaman) sepatutnya berterusan, dan menggunakan titik diskret untuk menganggarkannya akan membawa ralat. Konsep anggaran berterusan dicadangkan dalam CDN [32]. Selain pengagihan titik diskret, offset pada setiap titik juga dianggarkan. Titik diskret dan ofset bersama-sama membentuk anggaran ketaksamaan berterusan.
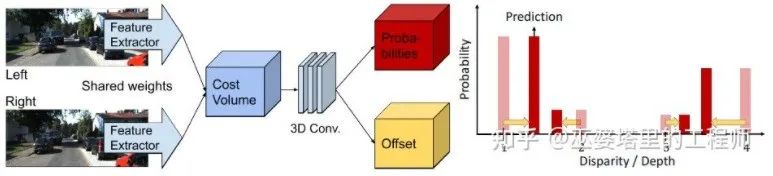
CDN
Atas ialah kandungan terperinci Tafsiran mendalam algoritma persepsi visual 3D untuk pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Lapisan bawah fungsi C++ sort menggunakan isihan gabungan, kerumitannya ialah O(nlogn), dan menyediakan pilihan algoritma pengisihan yang berbeza, termasuk isihan pantas, isihan timbunan dan isihan stabil.
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Konvergensi kecerdasan buatan (AI) dan penguatkuasaan undang-undang membuka kemungkinan baharu untuk pencegahan dan pengesanan jenayah. Keupayaan ramalan kecerdasan buatan digunakan secara meluas dalam sistem seperti CrimeGPT (Teknologi Ramalan Jenayah) untuk meramal aktiviti jenayah. Artikel ini meneroka potensi kecerdasan buatan dalam ramalan jenayah, aplikasi semasanya, cabaran yang dihadapinya dan kemungkinan implikasi etika teknologi tersebut. Kecerdasan Buatan dan Ramalan Jenayah: Asas CrimeGPT menggunakan algoritma pembelajaran mesin untuk menganalisis set data yang besar, mengenal pasti corak yang boleh meramalkan di mana dan bila jenayah mungkin berlaku. Set data ini termasuk statistik jenayah sejarah, maklumat demografi, penunjuk ekonomi, corak cuaca dan banyak lagi. Dengan mengenal pasti trend yang mungkin terlepas oleh penganalisis manusia, kecerdasan buatan boleh memperkasakan agensi penguatkuasaan undang-undang
 Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
01Garis prospek Pada masa ini, sukar untuk mencapai keseimbangan yang sesuai antara kecekapan pengesanan dan hasil pengesanan. Kami telah membangunkan algoritma YOLOv5 yang dipertingkatkan untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi, menggunakan piramid ciri berbilang lapisan, strategi kepala pengesanan berbilang dan modul perhatian hibrid untuk meningkatkan kesan rangkaian pengesanan sasaran dalam imej penderiaan jauh optik. Menurut set data SIMD, peta algoritma baharu adalah 2.2% lebih baik daripada YOLOv5 dan 8.48% lebih baik daripada YOLOX, mencapai keseimbangan yang lebih baik antara hasil pengesanan dan kelajuan. 02 Latar Belakang & Motivasi Dengan perkembangan pesat teknologi penderiaan jauh, imej penderiaan jauh optik resolusi tinggi telah digunakan untuk menggambarkan banyak objek di permukaan bumi, termasuk pesawat, kereta, bangunan, dll. Pengesanan objek dalam tafsiran imej penderiaan jauh
 Mempelajari pengetahuan penghunian rentas mod: RadOcc menggunakan teknologi penyulingan berbantukan pemaparan
Jan 25, 2024 am 11:36 AM
Mempelajari pengetahuan penghunian rentas mod: RadOcc menggunakan teknologi penyulingan berbantukan pemaparan
Jan 25, 2024 am 11:36 AM
Tajuk asal: Radocc: LearningCross-ModalityOccupancyKnowledge throughRenderingAssistedDistillation Paper pautan: https://arxiv.org/pdf/2312.11829.pdf Unit pengarang: FNii, CUHK-ShenzhenSSE, CUHK-Shenzhen Huawei Noah's Arkiv Paper 20 ialah Persidangan Precision AAAI2cy Paper 302:D tugas baru muncul yang bertujuan untuk menganggarkan keadaan penghunian dan semantik adegan 3D menggunakan imej berbilang paparan. Walau bagaimanapun, disebabkan kekurangan prior geometri, senario berasaskan imej
